
При разработке систем распознавания речи мы сталкиваемся с заблуждениями среди потребителей и разработчиков, в первую очередь связанными с разделением формы и сути. Одним из таких заблуждений является то, что в устной речи якобы "можно услышать" грамматически верные знаки препинания и пробелы между словами, когда по факту реальная устная речь и грамотная письменная речь очень сильно отличаются (устная речь скорее похожа на "поток" слегка разделенный паузами и интонацией, поэтому люди так не любят монотонно бубнящих докладчиков).
Понятно, что можно просто начинать каждое высказывание с большой буквы и ставить точку в конце. Но хотелось бы иметь какое-то относительно простое и универсальное средство расстановки знаков препинания и заглавных букв в предложениях, которые генерирует наша система распознавания речи. Совсем хорошо бы было, если бы такая система в принципе работала с любыми текстами.
По этой причине мы бы хотели поделиться с сообществом системой, которая:
- Расставляет заглавные буквы и основные знаки препинания (точка, запятая, дефис, вопросительный знак, восклицательный знак, тире для русского языка);
- Работает на 4 языках (русский, английский, немецкий, испанский);
- По построению должна работать максимально абстрактно на любом тексте и не основана на каких-то фиксированных правилах;
- Имеет минимальные нетривиальные метрики и выполняет задачу улучшения читабельности текста;
На всякий случай явно повторюсь — цель такой системы — лишь улучшать читабельность текста. Она не добавляет в текст информации, которой в нем изначально не было.
Постановка задачи и метод ее решения
На вход подается предложение, записанное строчными буквами и без какой-либо пунктуации — как мы обычно получаем на выходе системы распознавания речи. Требуется разработать модель, восстанавливающую его грамотную запись в смысле использования заглавных букв и знаков препинания. Набор знаков препинания .,—!?- был выбран исходя из оценки того, отсутствие каких символов наиболее бросается в глаза в предложениях, которые в среднем встречаются в речи в целевых доменах.
Кроме того, модель разрабатывалась из предположения, что после, и только после каждого токена сетке следует проставить только одну метку — знака препинания или просто пробела. Это автоматически исключает сложные случаи расстановки пунктуации в начале предложения или из нескольких символов (самый яркий пример — разнообразная прямая речь в литературе). Это упрощение сделано намеренно, т.к. нам показалось, что такое ограничение более конструктивно, чем учет всех малочисленных краевых случаев. И вообще главная задача, скорее, в улучшении читабельности, чем в идеальной записи составной прямой речи с обращениями и описаниями.
Задачу предполагалось сразу решать для нескольких основных языков. При этом модель по построению может быть легко расширена на произвольное количество языков, с которыми мы работаем, при наличии потребности и соответствующих корпусов данных.
Решение виделось прежде всего в виде какой-то малой бертоподобной модели с классифицирующими слоями поверх. В качестве данных для обучения использовались приватные корпуса, уже имевшиеся в наличии.
Мы ознакомились с недавним решением смежной задачи от коллег, однако, для наших целей требовалась:
- Более легкая модель с более общей специализацией;
- Реализация, не использующая напрямую внешние АПИ и не имеющая такое большое число зависимостей.
В результате у нашего решения из значительных зависимостей только сам PyTorch, никаких специализированных библиотек.
Поиск базовой модели
По возможности мы хотели взять небольшую предобученную языковую модель. Однако, поиск по списку готовых моделей, доступных на https://huggingface.co/, дает не самые обнадеживающие результаты: требование мультиязычности и уменьшения модели, например, дистилляции, по сути приводят нас к единственной доступной опции, и то с весом в полгигабайта.
Здесь, наверное можно сделать ремарку про степень полезности "революции трансформеров" в NLP, но напрашивающиеся выводы мы оставим на усмотрение читателя.
Итоговый размер модели и ее сжатие
Мы экспериментировали с разными архитектурами, но в итоге остановились на самой простой, и итоговый размер модели составил 520 мегабайт.
Такой размер дистилированного берта в основе нас не вполне устроил, и мы попробовали сжать обученную модель. Самый простой и эффективный способ — конечно, квантизация (причем сочетание статической и динамической как здесь) — и в результате модель была ужата до 130 мегабайт без значимой потери качества, потому всюду далее будут именно метрики финальной квантизованной модели.
Кроме того, мы сократили избыточный для нашей задачи словарь, выкинув токены для других языков, что позволило сжать эмбеддинг размера 120 тысяч токенов (размер токена — аж 768) до более приятных 75 тысяч. Наверняка можно было еще подрезать не самые часто используемые токены и применить оставшиеся более продвинутые методы сжатия моделей (факторизацию и замену механизма "внимания" на более простые аналоги), но мы решили остановиться, поскольку модель уже стала меньше 100 мегабайт.
Используемые метрики
Вопреки всеобщему тренду на сенсационализм и утрату рационального мышления, во всех наших статьях мы стараемся показывать максимально подробные, информативные и честные метрики на разных данных. В данном случае приведем метрики полученной модели на:
- Валидационных сабсетах наших приватных текстовых корпусов (
5,000предложений на каждый язык); - Текстах аудиокниг, будем использовать датасет caito, в котором как раз есть тексты на всех языках, на которых обучалась модель (
20,000случайных предложений на каждый язык);
В качестве метрик в этой задаче используем:
- WER (word error rate) в процентах, причем отдельно рассчитанный для пунктуации (оба предложения при этом приведены к строчному виду) —
WER_pи для расставления заглавных букв (а здесь выбрасываем всю пунктуацию) —WER_c; - Precision / recall / F1 для проверки качества классификации: между пробелом и упомянутыми выше знаками пунктуации
.,—!?-, а для расстановки заглавных букв — между классами токен из строчных букв / токен начинается с заглавной / токен из всех заглавных. Также для наглядности вы можете посмотреть на confusion матрицы;
Результаты
Для корректного и информативного расчета метрик из текстов были выброшены:
- Пунктуационные символы помимо
.,—!?-; - Пунктуация в начале предложения;
- Пунктуационные символы после первого в случае комбинации из нескольких пунктуационных знаков;
- Для испанского
¿¡из предсказаний модели были отброшены, т.к. в текстах книжек их тоже нет, но вообще модель их расставляет;
На вход модели подавались отдельные предложения, а не наборы предложений.
WER
В ячейках указан WER_p / WER_c, а наивный бейзлайн состоит в постановке заглавной буквы в начале предложения и точки в конце.
Домен — валидационные данные:
| Языки | ||||
|---|---|---|---|---|
| en | de | ru | es | |
| бейзлайн | 20 / 26 | 13 / 36 | 18 / 17 | 8 / 13 |
| модель | 8 / 8 | 7 / 7 | 13 / 6 | 6 / 5 |
Домен — книги:
| Языки | ||||
|---|---|---|---|---|
| en | de | ru | es | |
| бейзлайн | 14 / 13 | 13 / 22 | 20 / 11 | 14 / 7 |
| модель | 14 / 8 | 11 / 6 | 21 / 7 | 13 / 6 |
Precision / Recall / F1
Домен — валидационные данные:
| Metric | ' ' | . | , | - | ! | ? | — |
|---|---|---|---|---|---|---|---|
| en | |||||||
| precision | 0.98 | 0.97 | 0.78 | 0.91 | 0.80 | 0.89 | nan |
| recall | 0.99 | 0.98 | 0.64 | 0.75 | 0.67 | 0.78 | nan |
| f1 | 0.98 | 0.98 | 0.71 | 0.82 | 0.73 | 0.84 | nan |
| de | |||||||
| precision | 0.98 | 0.98 | 0.86 | 0.81 | 0.74 | 0.90 | nan |
| recall | 0.99 | 0.99 | 0.68 | 0.60 | 0.70 | 0.71 | nan |
| f1 | 0.99 | 0.98 | 0.76 | 0.69 | 0.72 | 0.79 | nan |
| ru | |||||||
| precision | 0.98 | 0.97 | 0.80 | 0.90 | 0.80 | 0.84 | 0 |
| recall | 0.98 | 0.99 | 0.74 | 0.70 | 0.58 | 0.78 | nan |
| f1 | 0.98 | 0.98 | 0.77 | 0.78 | 0.67 | 0.81 | nan |
| es | |||||||
| precision | 0.98 | 0.96 | 0.70 | 0.74 | 0.85 | 0.83 | 0 |
| recall | 0.99 | 0.98 | 0.60 | 0.29 | 0.60 | 0.70 | nan |
| f1 | 0.98 | 0.98 | 0.64 | 0.42 | 0.70 | 0.76 | nan |
| Metric | a | A | AAA |
|---|---|---|---|
| en | |||
| precision | 0.98 | 0.94 | 0.97 |
| recall | 0.99 | 0.91 | 0.70 |
| f1 | 0.98 | 0.92 | 0.81 |
| de | |||
| precision | 0.99 | 0.98 | 0.89 |
| recall | 0.99 | 0.98 | 0.53 |
| f1 | 0.99 | 0.98 | 0.66 |
| ru | |||
| precision | 0.99 | 0.96 | 0.99 |
| recall | 0.99 | 0.92 | 0.99 |
| f1 | 0.99 | 0.94 | 0.99 |
| es | |||
| precision | 0.99 | 0.95 | 0.98 |
| recall | 0.99 | 0.90 | 0.82 |
| f1 | 0.99 | 0.92 | 0.89 |
Домен — книги:
| Metric | ' ' | . | , | - | ! | ? | — |
|---|---|---|---|---|---|---|---|
| en | |||||||
| precision | 0.96 | 0.80 | 0.59 | 0.82 | 0.23 | 0.39 | nan |
| recall | 0.99 | 0.73 | 0.23 | 0.13 | 0.58 | 0.85 | 0 |
| f1 | 0.97 | 0.77 | 0.33 | 0.22 | 0.33 | 0.53 | nan |
| de | |||||||
| precision | 0.97 | 0.75 | 0.80 | 0.55 | 0.21 | 0.41 | nan |
| recall | 0.99 | 0.71 | 0.49 | 0.35 | 0.58 | 0.67 | 0 |
| f1 | 0.98 | 0.73 | 0.61 | 0.43 | 0.30 | 0.51 | nan |
| ru | |||||||
| precision | 0.97 | 0.77 | 0.69 | 0.90 | 0.17 | 0.49 | 0 |
| recall | 0.98 | 0.60 | 0.55 | 0.61 | 0.68 | 0.75 | nan |
| f1 | 0.98 | 0.68 | 0.61 | 0.72 | 0.28 | 0.60 | nan |
| es | |||||||
| precision | 0.96 | 0.57 | 0.59 | 0.96 | 0.30 | 0.24 | nan |
| recall | 0.98 | 0.70 | 0.29 | 0.02 | 0.40 | 0.68 | 0 |
| f1 | 0.97 | 0.63 | 0.38 | 0.04 | 0.34 | 0.36 | nan |
| Metric | a | A | AAA |
|---|---|---|---|
| en | |||
| precision | 0.99 | 0.80 | 0.94 |
| recall | 0.98 | 0.89 | 0.95 |
| f1 | 0.98 | 0.85 | 0.94 |
| de | |||
| precision | 0.99 | 0.90 | 0.77 |
| recall | 0.98 | 0.94 | 0.62 |
| f1 | 0.98 | 0.92 | 0.70 |
| ru | |||
| precision | 0.99 | 0.81 | 0.82 |
| recall | 0.99 | 0.87 | 0.96 |
| f1 | 0.99 | 0.84 | 0.89 |
| es | |||
| precision | 0.99 | 0.71 | 0.45 |
| recall | 0.98 | 0.82 | 0.91 |
| f1 | 0.98 | 0.76 | 0.60 |
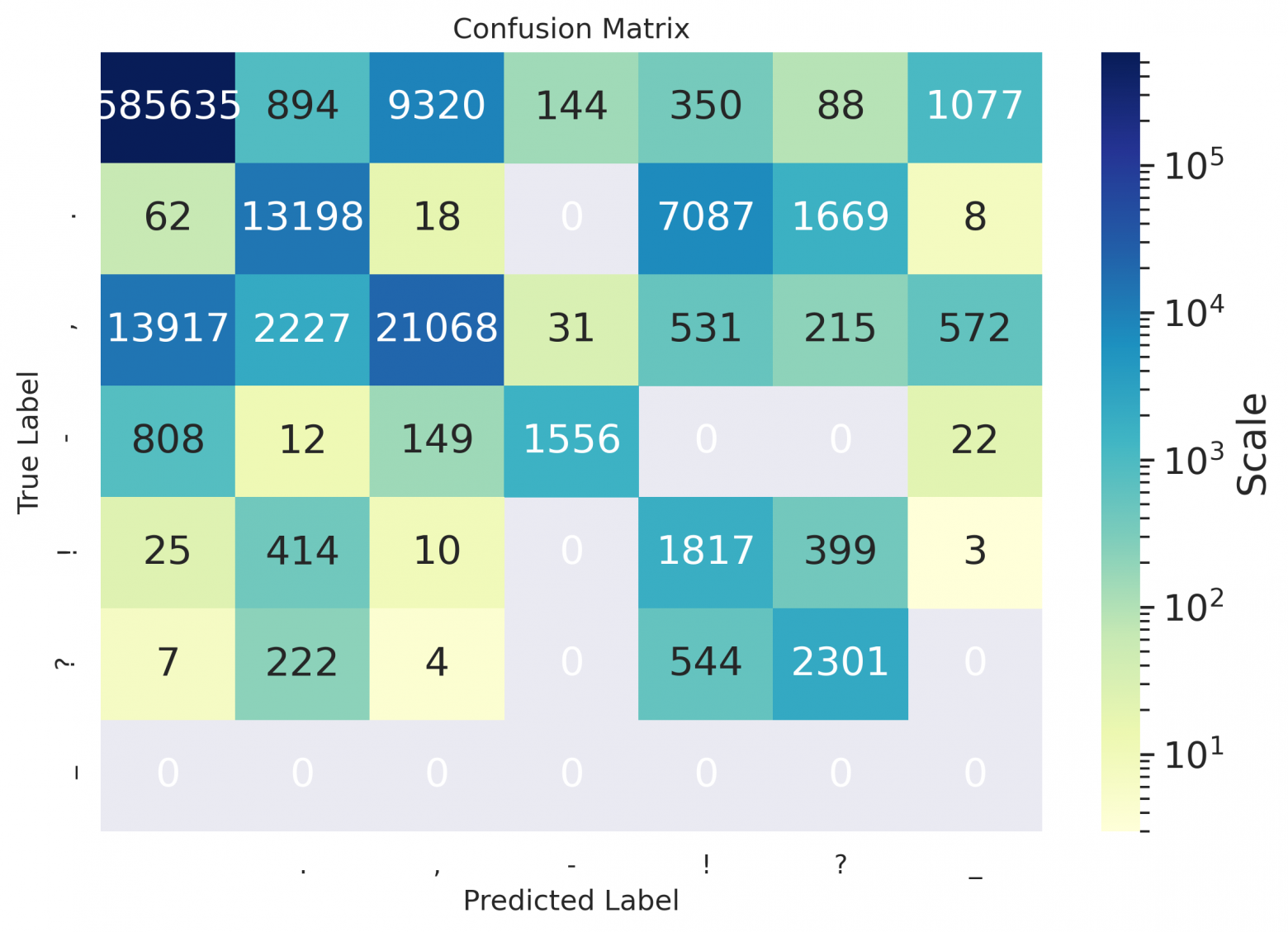
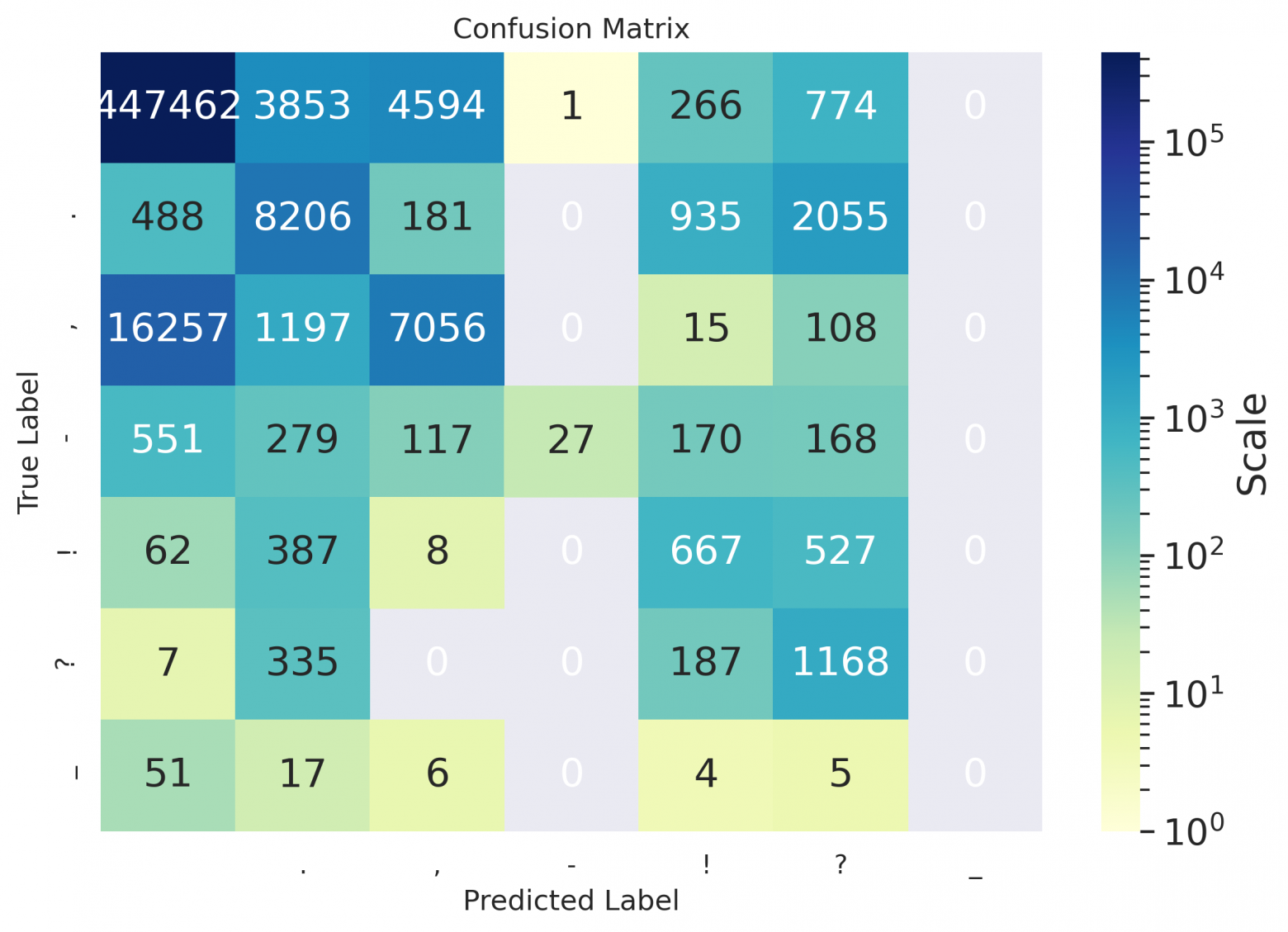
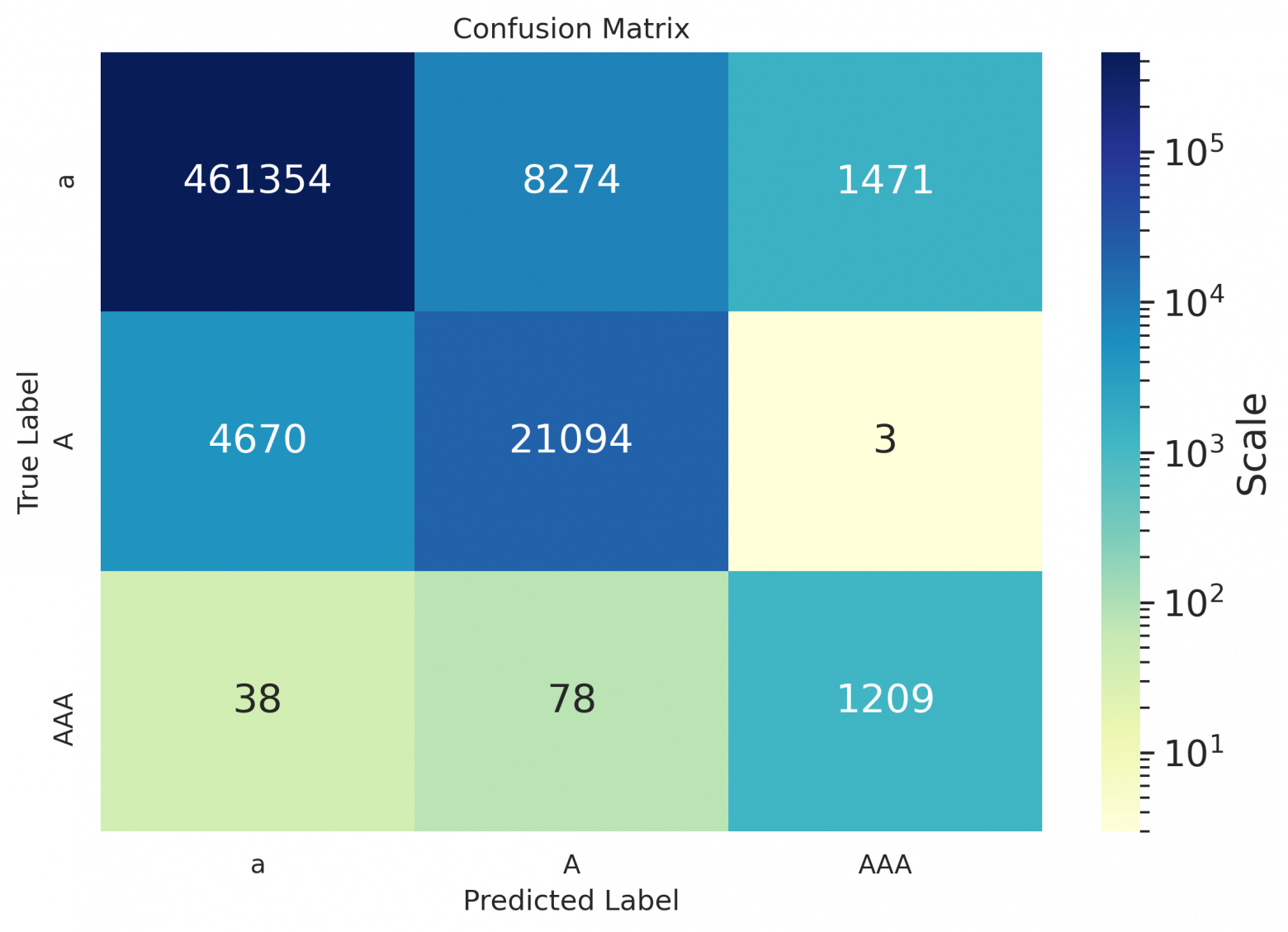
Как можно заметить из таблиц — даже для русского, значения дефиса остались пустыми, потому что на использовавшихся для расчета метрик данных модель предлагала его не проставлять вовсе, либо заменять дефис каким-нибудь иным символом (как видно в матрицах ниже); похоже, он лучше расставляется в случае предложений в форме определений (см. пример в конце статьи).
Для контекста
Приведем доступные F1 метрики из разных статей, где решались смежные задачи — здесь разные языки, разные валидационные данные, поэтому напрямую сравнить не удастся, но можно оценить порядок цифр. Cистема классов в таких работах тоже обычно иная — COMMA, PERIOD, QUESTION:
| Источник | COMMA | PERIOD | QUESTION |
|---|---|---|---|
| Статья 1 — en | 76.7 | 88.9 | 87.8 |
| Статья 2 — en | 71.8 | 84.2 | 85.7 |
| Статья 3 — es | 80.2 | 87.0 | 59.7 |
| Репозиторий 4 — fr | 67.9 | 72.9 | 57.6 |
Сonfusion matrices
Матрицы по книжкам:
en
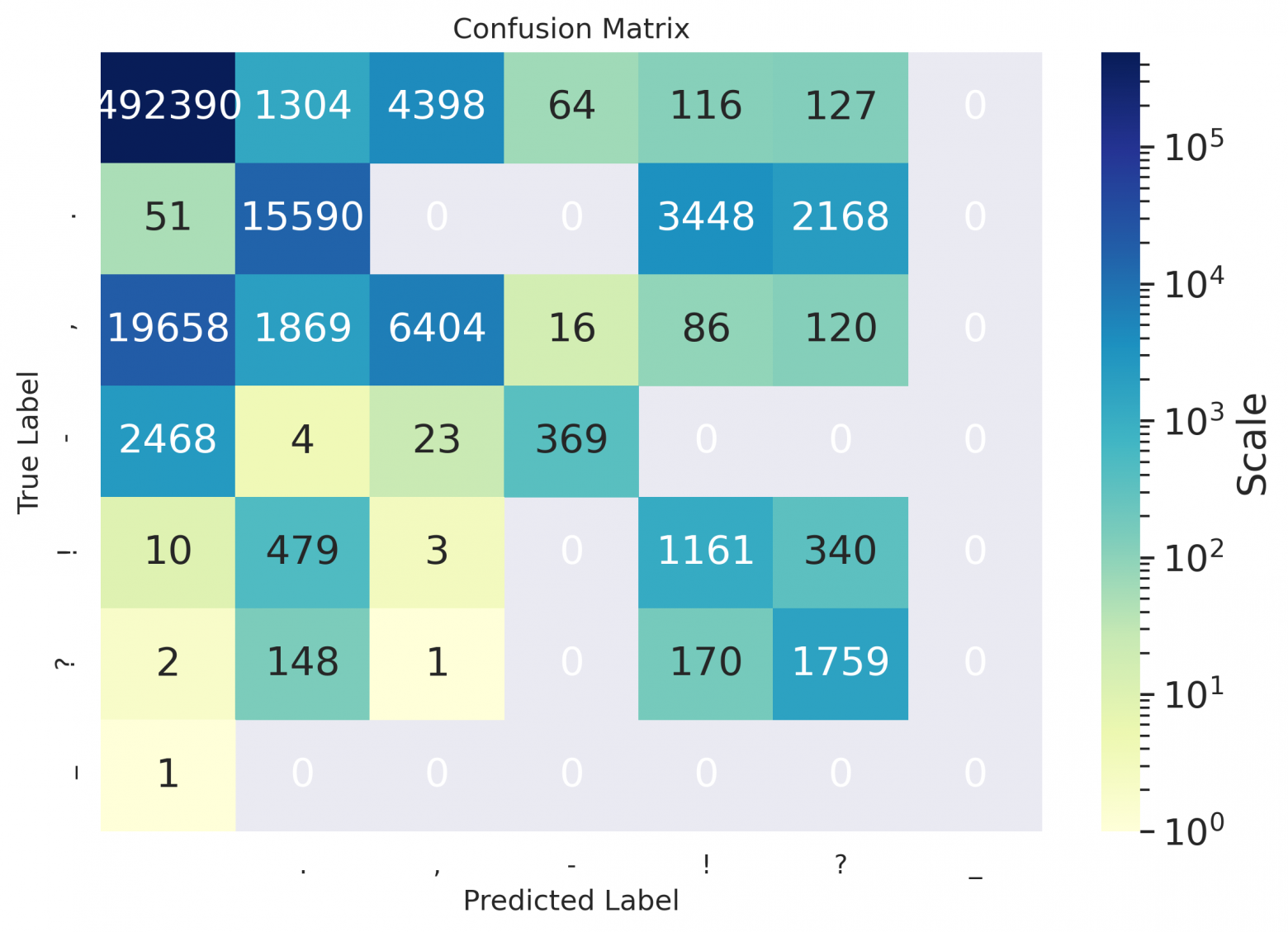
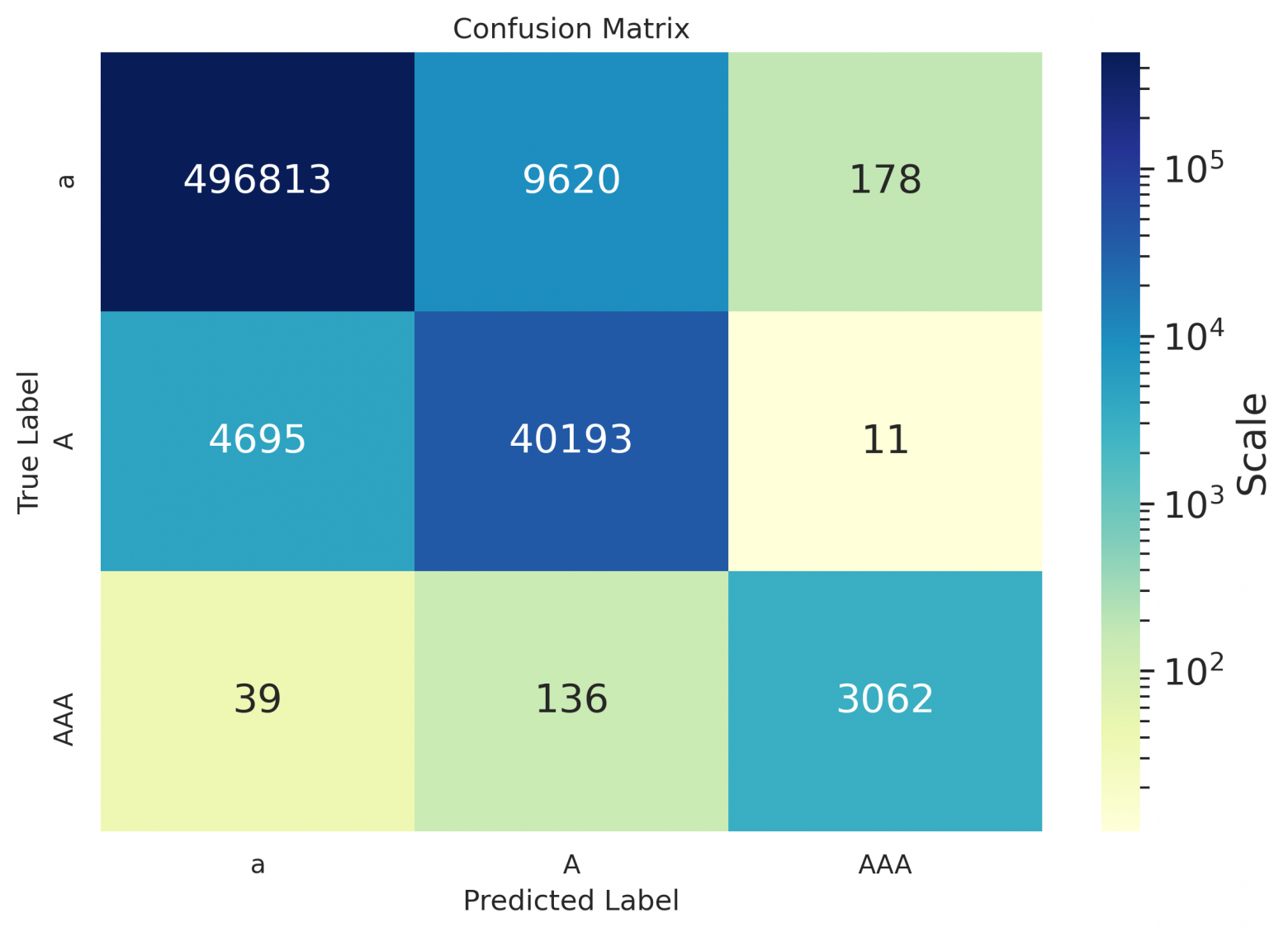
de
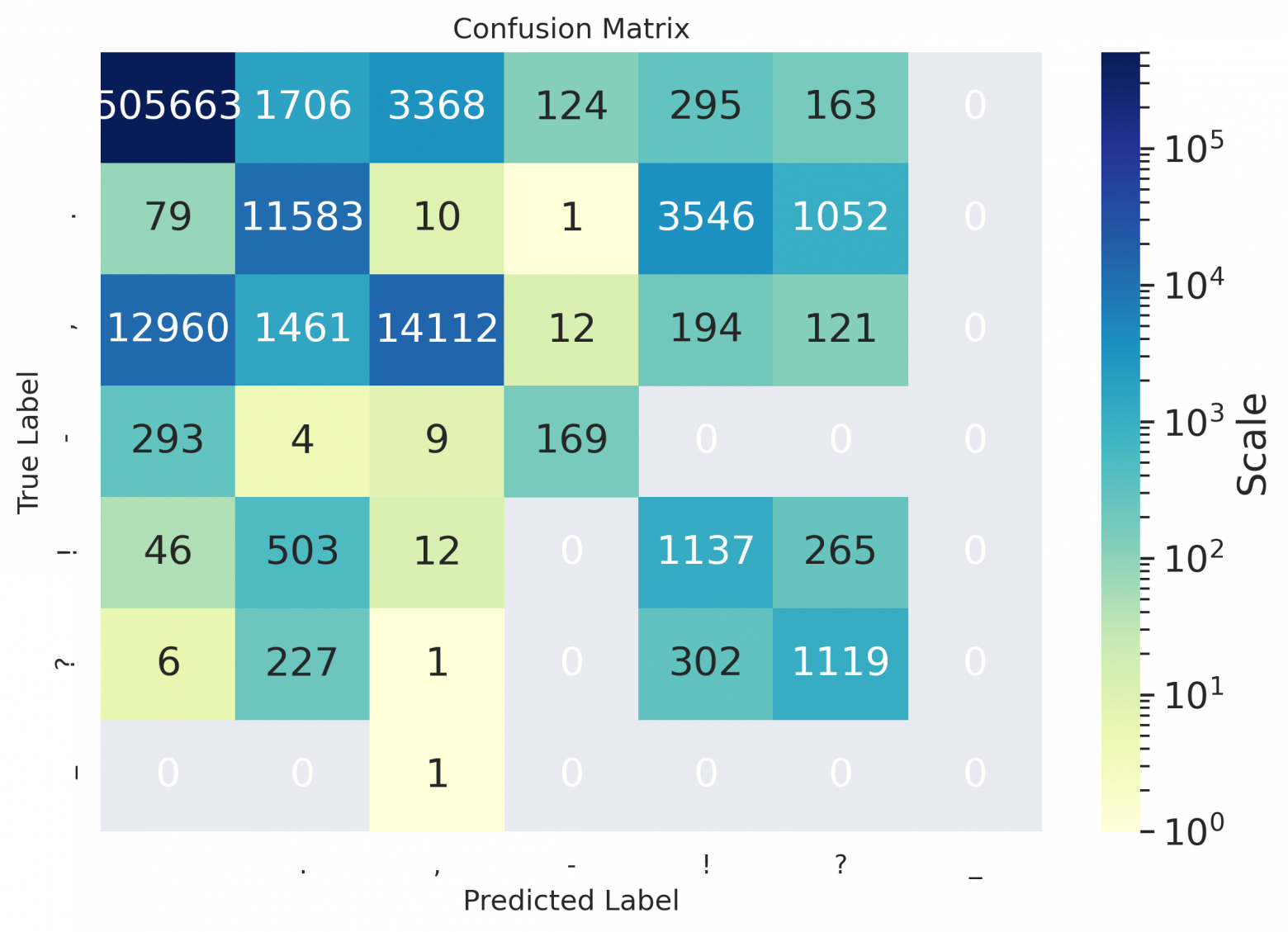
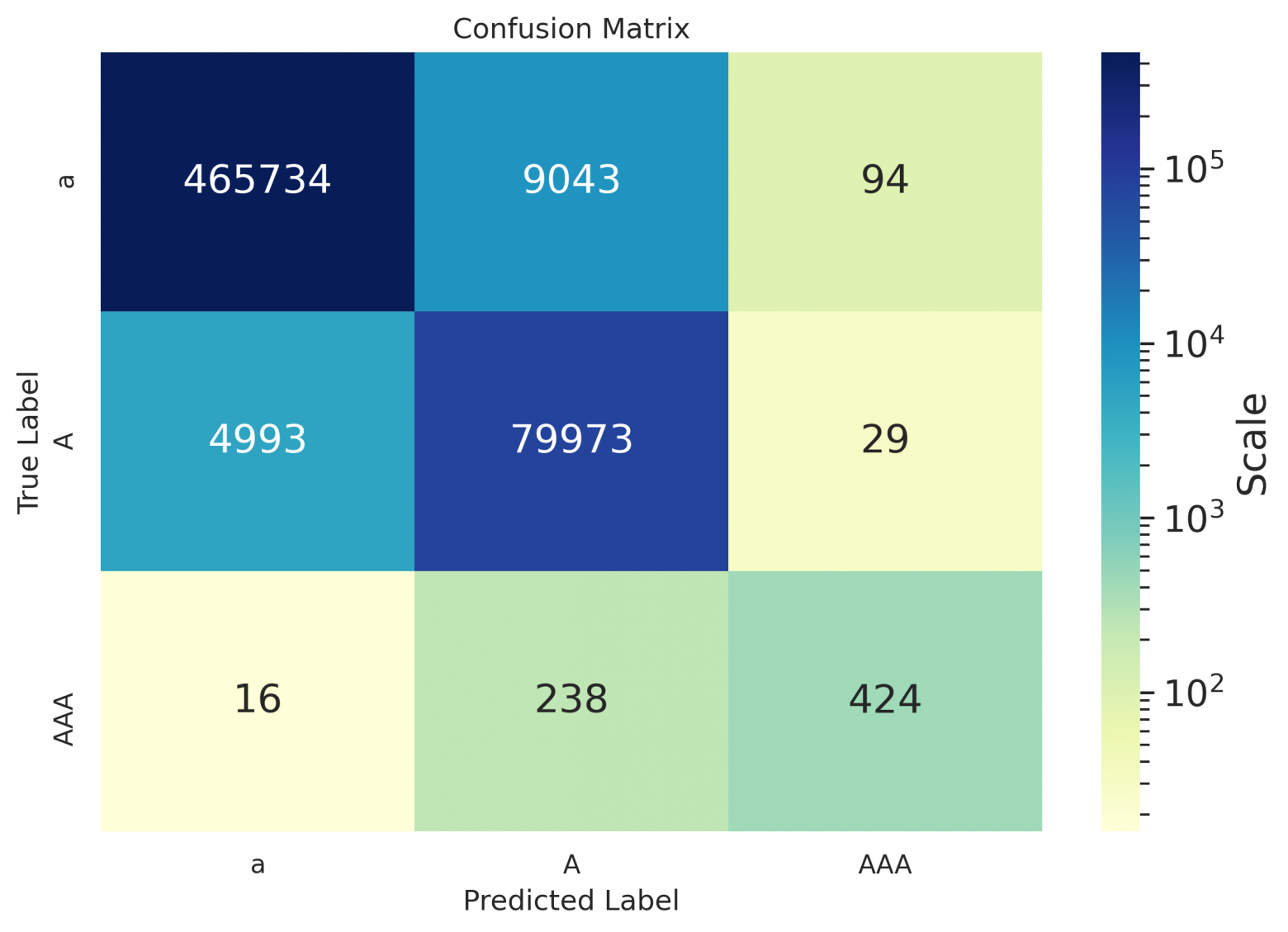
ru
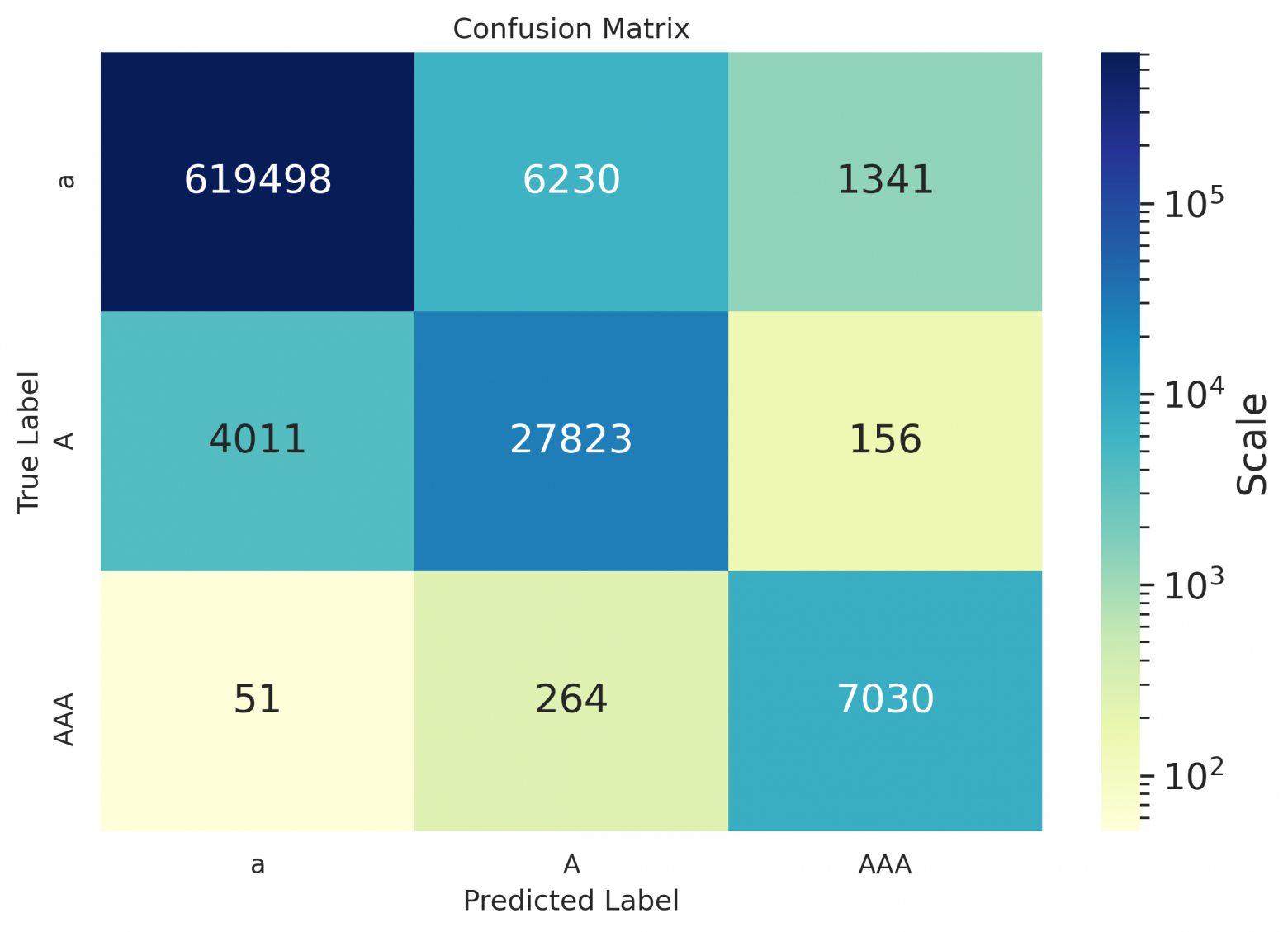
es
Примеры работы модели
Глядя на то, что для домена книг все же не везде метрики выглядят информативными и иногда совпадают с тривиальным решением, мы добавили и примеры именно текстов — для сравнения оригинальной расстановки пунктуации и заглавных букв с результатом работы модели.
Здесь более наглядны особенности работы модели:
- Где-то модель расставляет знаки препинания и заглавные буквы вполне неплохо, но не как в оригинальном тексте;
- Где-то пропускает или ошибается, а еще в книжках она выставляет вопросы и восклицания чересчур усердно;
Но тут нет ничего удивительного — новой информации модель не создает (никак неиссякаемая тугая струя желтых статей про "zoom and enhance" на Хабре удручает), мысли автора текста не читает и вообще по сути просто делает текст более привычным глазу.
| Оригинал | Модель |
|---|---|
| She heard Missis Gibson talking on in a sweet monotone, and wished to attend to what she was saying, but the Squires visible annoyance struck sharper on her mind. | She heard Missis Gibson talking on in a sweet monotone and wished to attend to what she was saying, but the squires visible annoyance struck sharper on her mind. |
| Yet she blushed, as if with guilt, when Cynthia, reading her thoughts, said to her one day, Molly, youre very glad to get rid of us, are not you? | Yet she blushed as if with guilt when Cynthia reading her thoughts said to her one day, Molly youre very glad to get rid of us, are not you? |
| And I dont think Lady Harriet took it as such. | And I dont think Lady Harriet took it as such. |
| -- | -- |
| Alles das in begrenztem Kreis, hingestellt wie zum Exempel und Experiment, im Herzen Deutschlands. | Alles das in begrenztem Kreis hingestellt, wie zum Exempel und Experiment im Herzen Deutschlands. |
| Sein Leben nahm die Gestalt an, wie es der Leser zu Beginn dieses Kapitels gesehen hat er verbrachte es im Liegen und im Müßiggang. | Sein Leben nahm die Gestalt an, wie es der Leser zu Beginn dieses Kapitels gesehen hat er verbrachte es im Liegen und im Müßiggang. |
| Die Flußpferde schwammen wütend gegen uns an und suchten uns zu töten. | Die Flußpferde schwammen wütend gegen uns an und suchten uns zu töten. |
| -- | -- |
| Пожалуйста, расскажите все это Бенедикту — послушаем, по крайней мере, что он на это ответит. | Пожалуйста, расскажите все это бенедикту, послушаем, по крайней мере, что он на это ответит. |
| Есть слух, что хороша также работа Пунка, но моя лучше. | Есть слух, что хороша также работа пунка, но моя лучше! |
| После восстания чехословацкого корпуса Россия зажглась от края до края. | После восстания Чехословацкого корпуса Россия зажглась от края до края. |
| -- | -- |
| En seguida se dirigió a cortar la línea por la popa del Trinidad, y como el Bucentauro, durante el fuego, se había estrechado contra este hasta el punto de tocarse los penoles, | En seguida se dirigió a cortar la línea por la popa del Trinidad y como el Bucentauro, durante el fuego se había estrechado contra este hasta el punto de tocarse los penoles. |
| Su propio padre Plutón, sus mismas tartáreas hermanas aborrecen a este monstruo Tantas y tan espantosas caras muda, tantas negras sierpes erizan su cuerpo! | Su propio padre, Plutón, sus mismas tartáreas hermanas, aborrecen a este monstruo tantas y tan espantosas caras muda tantas negras sierpes erizan su cuerpo. |
| Bien es verdad que quiero confesar ahora que, puesto que yo veía con cuán justas causas don Fernando a Luscinda alababa. | Bien, es verdad que quiero confesar ahora que puesto que yo veía con cuán justas causas, don Fernando a Luscinda Alababa? |
Как запустить
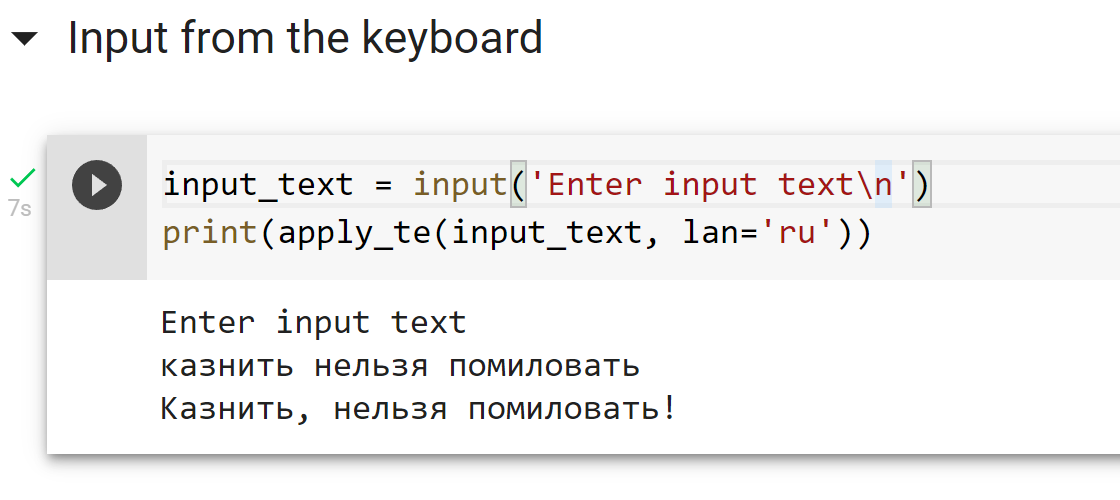
Модель выложена в репозитории проекта silero-models и, соответственно, будет поддерживаться, как и прочие наши решения оттуда. А вот простой запуск модели (с более подробными примерами можно ознакомиться в colab):
import torch model, example_texts, languages, punct, apply_te = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_te') input_text = input('Enter input text\n') apply_te(input_text, lan='en')
Ограничения
У данной работы есть ряд ограничений и очевидных вещей, которые мы решили пока не делать (так сказать нужно же было где-то поставить точку):
- На языках кроме английского модель сносно работает с длинными предложениями. Но разделять несколько предложений или целые параграфы текста на отдельные предложения она по построению пока не умеет;
- Не совсем понятно как делить на предложения целые "книги" и неясно нужно ли это вообще в принципе;
- Мы не применили факторизацию и структурированный прунинг к модели (например снижение числа голов в механизме внимания);
Нам более-менее очевидно, как сделать большую часть этих вещей, но только время и разведка боем покажет востребованность подобного рода инструментов.

