Код и данные — фундамент ИИ-системы. Оба эти компонента играют важную роль в разработке надёжной модели, но на каком из них следует сосредоточиться больше? В этой статье мы сравним методики, ставящие в центр данные, либо модель, и посмотрим, какая из них лучше; также мы поговорим о том, как внедрять датацентрическую инфраструктуру.
Моделецентрическая методика
При моделецентрической методике выполняются экспериментальные исследования для повышения качества модели ML. Из широкого спектра возможностей выбираются наилучшая архитектура модели и процесс обучения.
- При таком подходе данные остаются неизменными, совершенствуется код или архитектура модели.
- Работа над кодом — основная цель этой методики.
Моделецентрические тенденции в мире ИИ
На сегодняшний день большинство ИИ-приложений моделецентричны; вероятно, причина этого заключается в том, что сектор разработки ИИ внимательно следит за научными исследованиями моделей. По словам Эндрю Ына, более 90% исследовательских статей в этой предметной области моделецентрично, потому что сложно создать крупные массивы данных, которые могут стать общепринятыми стандартами. Из-за этого сообщество разработчиков ИИ полагает, что моделеценти��ное машинное обучение более перспективно. Основное внимание уделяется коду, а данные зачастую игнорируются и сбор данных считается единоразовым событием.
Датацентрическая методика
В эпоху, когда данные являются основой любого процесса принятия решений, датацентрическая (data-centric) компания может лучше соотносить свою стратегию с интересами партнёров, используя информацию, сгенерированную по итогам их работы. Благодаря этому результаты могут быть более точными, упорядоченными и прозрачными, что позволяет организации функционировать стабильнее.
- При таком подходе массивы данных систематически изменяются/совершенствуются для повышения точности ML-приложений.
- Работа над данными — основная цель такой методики.
Различия между data-driven и data-centric
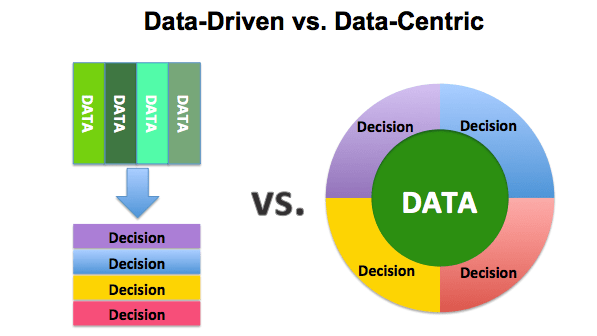
Data-driven и data-centric
Многие люди часто путают методики data-centric и data-driven. Подход data-driven — это методология сбора, анализа и понимания данных. Иногда его называют «аналитикой». Подход data-centric сосредоточен на использовании данных для определения того, что вообще нужно создавать.
- Датацентрическая архитектура — это система, в которой данные являются основным и неотъемлемым ресурсом, а способы их использования меняются.
- Data-driven-архитектура — это создание технологий, навыков и среды при помощи переработки больших объёмов данных.
Давайте теперь поговорим о том, как датацентрический подход отличается от моделецентрического и о том, зачем он вообще нужен.
Датацентрический и моделецентрический подходы
Дата-саентистам и инженерам машинного обучения моделецентрический подход может казаться более удобным. Это понятно, ведь практические специалисты могут использовать свои знания для решения конкретной задачи. С другой стороны, никто не захочет тратить весь день на разметку данных, потому что это считается скучной работой.
В современном машинном обучении данные критически важны, однако разработчики ИИ их часто игнорируют или относятся к ним неправильно. В результате этого сотни часов тратятся на настройку модели на основе ошибочных данных. Это вполне может быть фундаментальной причиной низкой точности вашей модели, и это никак не связано с оптимизацией модели.

Источник: A Chat with Andrew on MLOps: From Model-centric to Data-centric AI
Необязательно полностью переходить на датацентрический подход, иногда важно сосредоточиться на модели и коде. Стоит проводить исследования и совершенствовать модели, но и данные тоже важны. Мы склонны не замечать важность данных и основное внимание уделяем модели. Лучше всего использовать гибридный подход, учитывающий и данные, и модель. В зависимости от способа использования можно уделять больше внимания данным и меньше модели, но учитывать обязательно нужно оба аспекта.
Потребность в датацентрической архитектуре
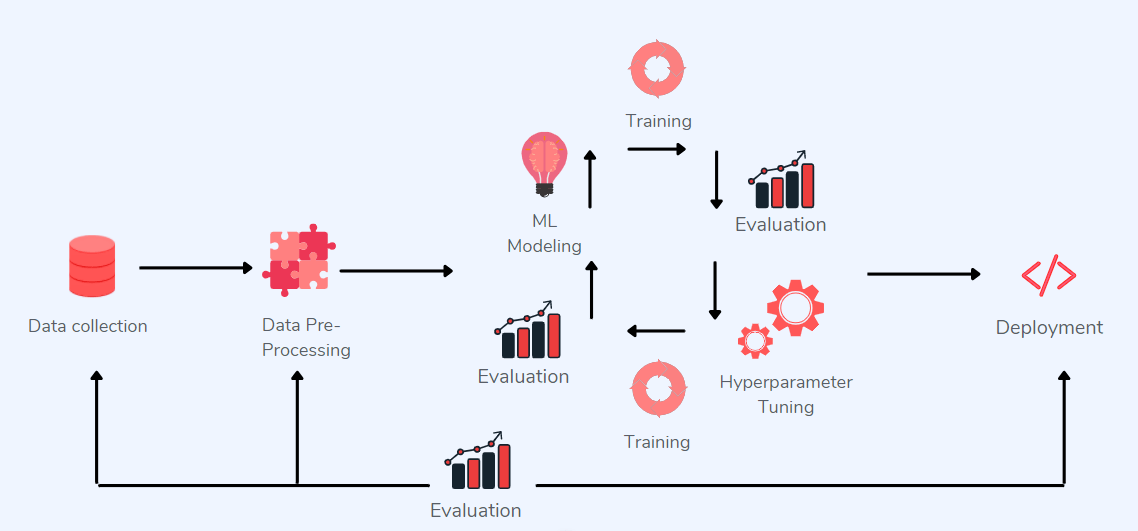
Моделецентрическое ML — это системы машинного обучения, в основном д��лающие упор на оптимизацию архитектур моделей и их параметров.
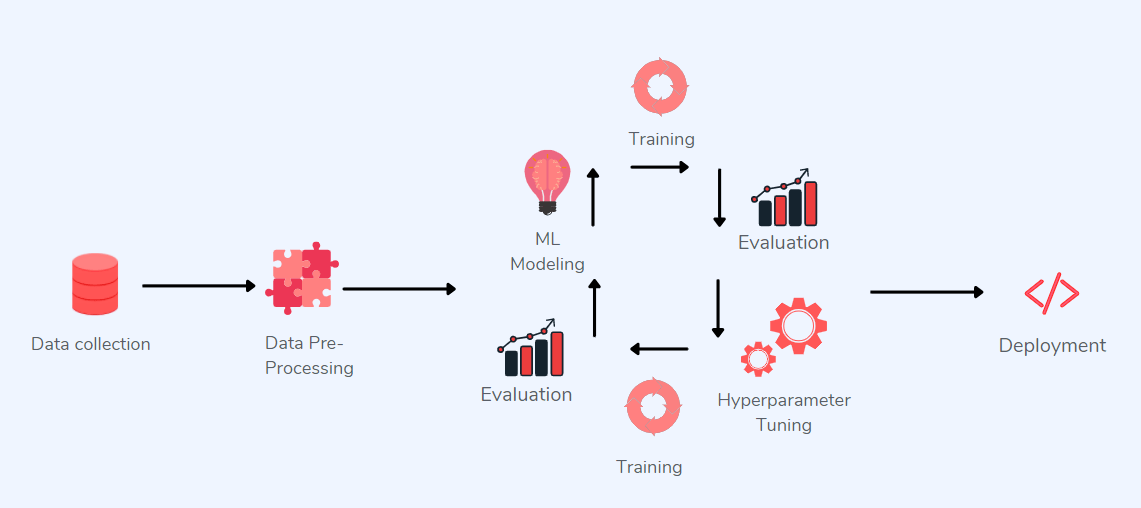
Моделецентрическое применение ML
Показанный на рисунке выше моделецентрический процесс подходит для некоторых отраслей, в частности, медиа и рекламного бизнеса, но ситуация меняется, когда дело касается здравоохранения или производства. В них можно столкнуться со следующими трудностями:
1. Потребность в высокоуровневой кастомизации
В отличие от медиа и рекламного бизнеса, производитель множества разных товаров не может использовать одну систему машинного обучения для распознавания брака во всём ассортименте продукции. Каждый изготавливаемый продукт требует отдельно обученной модели ML.
Медиа-компании могут позволить себе иметь свой собственный отдел ML, работающий над каждой задачей оптимизации, однако производственный бизнес, требующий множества ML-решений, не может пойти по тому же пути.
2. Важность больших массивов данных
В большинстве случаев у компаний нет большого количества размечанных данных, с которыми можно работать. Часто они вынуждены иметь дело с крошечными массивами данных, которые при моделецентрическом подходе обеспечивают неудовлетворительные результаты.
Эндрю Ын считает, что датацентрическое ML даёт бОльшую отдачу и продвигает идею революции в сообществе в сторону датацентричности. Он приводит пример задачи обнаружения дефектов в стали, в котором моделецентрическая методика не смогла повысить точность модели, а датацентрическая методика увеличила точность на 16%.
Данные чрезвычайно важны в исследованиях ИИ, а внедрение стратегии, отдающей приоритет получению высококачественных данных, критически необходимо — в конечном итоге, релевантные данные не только редки и шумны, но и процесс их получения очень дорог. Принцип заключается в том, что с ИИ нужно обращаться так же, как при подборе качественных материалов при строительстве дома. Данные нужно оценивать на каждом уровне, а не выбирать их один раз.
Датацентрический способ применения ML
Внедрение датацентрической инфраструктуры
При реализации датацентрической архитектуры данные необходимо рассматривать как фундаментальный ресурс, срок жизни которого будет больше, чем у приложений и инфраструктуры. При таком подходе требуется не единая база данных или репозиторий данных, а общее понимание данных и их единообразное описание. Датацентрическое ML упрощает обмен данными и их перемещение.
Так что же включает в себя датацентрическое машинное обучение? Какие существенные факторы следует учитывать при реализации датацентрического подхода?
1. Качество разметки данных
Разметка данных — это процесс присвоения данным одной или нескольких меток. Метки ассоциируются с конкретными значениями, присваиваемыми данным. Если неверно размечено существенное количество изображений, то результаты будут хуже, чем при использовании меньшего количества более точных данных.
В метках содержится подробная информация о содержимом и структуре массива данных, которая может включать в себя такие компоненты, как перечень типов данных, единиц измерения и временных интервалов, представленных в массиве. Наилучшим способом повышения качества данных является поиск несоответствий в метках и работа над инструкциями по разметке. Ниже мы подробнее расскажем о важности качества данных.
2. Аугментация данных
Аугментация данных — это задача анализа данных, включающая в себя создание обучающих примеров при помощи интерполяции, экстраполяции и других средств. Её можно использовать для добавления дополнительных данных обучения для ML или для создания синтетических изображений/кадров видео с различной степенью реализма. Она помогает увеличить количество релевантных данных, например, количества бракованных изделий, создавая данные, которые ваша модель в процессе обучения пока не видела.
Однако добавление данных не всегда является наилучшим вариантом. Устранение шумных данных, приводящих к высокой дисперсии, улучшает способность модели обобщать новые данные.
3. Конструирование признаков
Конструирование признаков (feature engineering) — процесс добавления в модель признаков при помощи изменения входящих данных, предшествующих знаний или алгоритмов. Оно используется в машинном обучении для повышения точности прогнозирующей модели.
Повышение качества данных включает в себя улучшение и входящих данных, и целевых/меток. Конструирование признаков критически важно для добавления признаков, которые могут и не существовать в «сыром» виде, но способны внести существенный вклад в обучение модели.
4. Контроль версий данных
В любом программном приложении важную роль играет контроль версий данных. Разработчикам необходимо устранять ошибки, сравнивая две версии и выявляя аспекты, которые больше не имеют ценности. Или же разработчики могут предотвратить появление бага, повторно внедрив конкретную версию данных. Управление доступом к массивам данных, а также к различным версиям каждого массива данных — это сложная и не защищённая от ошибок задача. Контроль версий данных — один из самых важных этапов в управлении данными, именно он позволяет отслеживать изменения (и добавление, и удаление) в массиве данных. Контроль версий упрощает совместную работу над кодом и управление массивами данных.
Также контроль версий упрощает управление конвейером ML от proof of concept до продакшена, на этом этапе на помощь приходят инструменты MLOps. Вы можете задаться вопросом, почему инструменты MLOps обсуждаются в контексте контроля версий данных? Потому что управление конвейерами данных — очень сложная задача в разработке приложений машинного обучения. Контроль версий обеспечивает воспроизводимость и надёжность. Вот лучшие платформы для контроля версий данных:
а) Neptune
Neptune — это хранилище метаданных для MLOps, разработанное для исследовательских и производственных групп. Оно создаёт общий центральный хаб для журналирования, хранения, отображения, упорядочивания, сравнения и запрашивания всех метаданных, сгенерированных на протяжении жизненного цикла машинного обучения. В контексте контроля версий данных при помощи Neptune можно выполнять следующие операции:
- Отслеживать версию массива данных в прогонах машинного обучения при помощи артефактов.
- Запрашивать версию массива данных из предыдущих прогонов, чтобы гарантировать, что вы выполняете обучение на одной версии массива данных.
- Упорядочивать метаданные версий массивов данных в Neptune UI.

Пример сравнения массивов данных в Neptune UI
Чтобы узнать больше о контроле версий данных в Neptune, см. примеры кода.
б) Weights & Biases
Weights & Biases (WandB) — это платформа, предоставляющая инструменты машинного обучения исследователям и командам, занимающимся глубоким обучением. WandB помогает в контроле экспериментов, контроле версий массивов данных и управлении моделями. При помощи WandB можно выполнять следующие операции:
- Использовать артефакты для контроля версий массивов данных и моделей, а также для отслеживания зависимостей и результатов в конвейерах машинного обучения.
- Хранить полные массивы данных непосредственно в артефактах или использовать ссылки на артефакты для указания на данные в других системах наподобие S3, GCP, или на локальной машине.
Чтобы узнать больше о контроле версий данных в WandB, см. примеры кода.
в) Data Version Control (DVC)
DVC — это open-source-платформа для проектов машинного обучения. DVC помогает дата-саентистам и разработчикам в контроле версий данных, управлении рабочим процессом и экспериментами. DVC позволяет выполнять следующие операции:
- Записывать версии данных и моделей в коммиты Git, параллельно с хранением их на машинах пользователей или в облачном хранилище.
- Переключаться между различным содержимым данных.
- Создавать метафайлы с описанием того, какие массивы данных и артефакты ML нужно отслеживать.
Чтобы узнать больше о контроле версий данных и моделей в DVC, см. примеры кода.
5. Знание предметной области
При датацентрическом подходе чрезвычайную ценность имеет знание предметной области. Специалисты в предметной области часто способны выявлять мелкие несоответствия, незаметные для инженеров ML, дата-саентистов или разметчиков. Труд специалистов в предметной области по-прежнему не используется в ML-системе. Производительность ML-систем можно улучшить, использовав дополнительные знания предметной области.
Преимущества датацентрического подхода
Переход к датацентрическим методикам имеет множество преимуществ, от повышения скорости и точности до более осознанного принятия решений. Датацентрическая инфраструктура обладает следующими преимуществами:
- Повышает точность; использование данных в качестве стратегического ресурса гарантирует более точные оценки, наблюдения и решения.
- Устраняет необходимость сложных преобразований данных.
- Уменьшает количество ошибок и несоответствий в данных.
- Предоставляет важную информацию о внутренних и внешних трендах, позволяющую принимать более оптимальные решения.
- Снижает расходы.
- Упрощает доступ к данным для руководства.
- Снижает избыточность данных.
- Повышает качество и надёжность данных.
Чему отдавать приоритет: количеству или качеству данных?
Прежде чем двигаться дальше, нам стоит подчеркнуть, что увеличение количества данных не означает автоматически повышение их качества. Разумеется, нейросеть невозможно обучить на малом количестве изображений, но упор нужно делать на качество, а не на количество.
Количество данных
Под этим понятием подразумевается объём доступных данных. Основная задача — собрать максимально возможное количество данных, а затем обучить нейросеть.
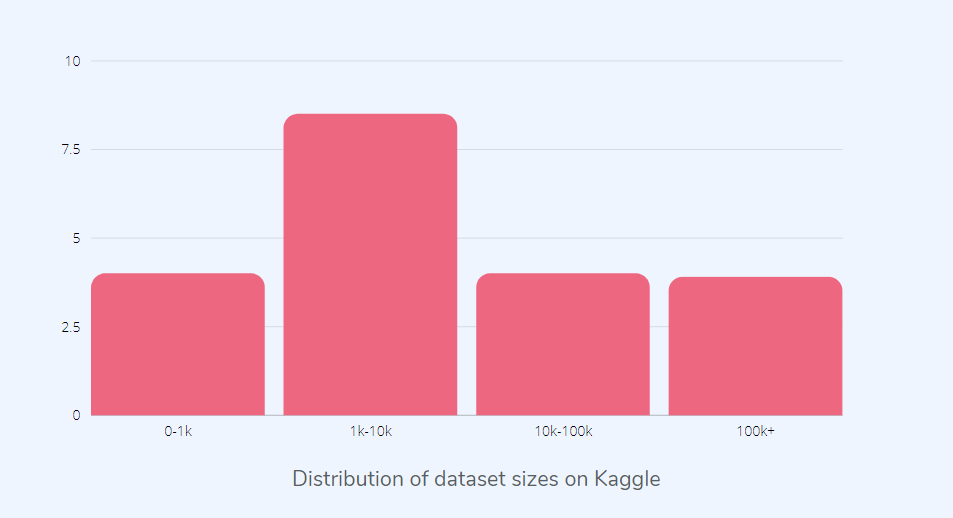
Данные | Источник
Как видно из рисунка выше, большинство массивов данных Kaggle не очень велико. При датацентрическом подходе размер массива данных не так важен, и многое можно сделать даже с небольшим качественным массивом данных.
Качество данных
Как понятно из названия, здесь важно качество данных. Не важно, есть ли у вас миллионы массивов данных; главное, чтобы они имели высокое качество и были правильно размечены.

Различные подходы к созданию ограничивающих прямоугольников
На рисунке выше показаны различные способы разметки данных; нет ничего плохого в разметке их по отдельности или вместе. Однако если дата-саентист 1 размечает каждый ананас отдельно, а дата-саентист 2 размечает их вместе, то данные будут несовместимыми, из-за чего алгоритм обучения запутается. Основная задача — обеспечение согласованности меток; если вы размечаете объекты по отдельности, сделайте так, чтобы все объекты размечались одинаково.
Согласованность аннотирования данных критически важна, потому что любые несоответствия могут сбить модель с толку и сделать её оценку неточной. Поэтому необходимо тщательно составлять инструкции по аннотированию, чтобы инженеры ML и дата-саентисты размечали данные согласованно. Согласно исследованию, приблизительно 3,4% сэмплов в часто используемых массивах данных имеют ошибочные метки, и ошибок больше в больших моделях.
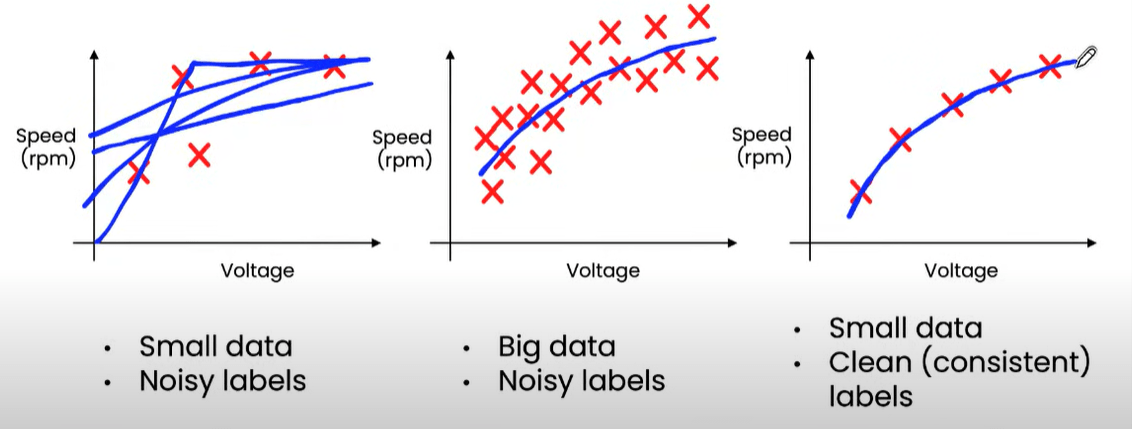
Важность согласованности в малых массивах данных | Источник
На приведённом выше рисунке Эндрю Ын объясняет важность согласованности малых массивов данных. График иллюстрирует соотношение между напряжением и скоростью дрона. Если ваши массивы данных малы, однако их метки согласованы, то вы сможете с большей уверенностью подобрать кривую и получить более высокую точность.
Из-за низкокачественных данных изъяны и неточности могут без каких-либо последствий постоянно оставаться необнаруженными. Точность моделей зависит от качества данных; если вы хотите принимать хорошие решения, то вам нужна точная информация. Данные с плохими атрибутами подвержены риску наличия ошибок и аномалий, которые при использовании предсказательной аналитики и техник моделирования могут стоить вам очень дорого.
Сколько данных достаточно?
Количество имеющихся данных критически важно; для решения задачи необходимо иметь достаточный объём данных. Глубокие нейросети — это компьютеры с малым смещением и высокой дисперсией, и мы полагаем, что решением проблемы дисперсии является увеличение объёма данных. Но какого количества данных достаточно? Ответить на этот вопрос не так уж просто. Yolov5 даёт следующие рекомендации:
- Минимум 1,5 тысяч изображений на каждый класс.
- Минимум 10 тысяч экземпляров (размеченных объектов) на класс в сумме.
Наличие большого количества данных — это преимущество, а не обязательное требование.
Рекомендации по датацентрическому подходу
При внедрении датацентрического подхода не забывайте о следующих аспектах:
- Обеспечивайте постоянно высокое качество данных на протяжении всего жизненного цикла ML-проекта.
- Поддерживайте согласованность меток.
- Используйте данные из продакшена, чтобы вовремя получать обратную связь.
- Применяйте анализ ошибок, чтобы сосредоточиться на подмножестве данных.
- Избавляйтесь от шумных сэмплов; как говорилось выше, «больше» не всегда означает «лучше».
Где искать качественные массивы данных?
Получение высококачественных массивов данных — важная задача. Такие массивы данных можно получить бесплатно в следующих местах:
Kaggle
Первый источник хорошо известен в сообществе дата-саентистов. В Kaggle вы найдёте весь код и данные для работы в data science. У него есть более 50 тысяч публичных массивов данных и 400 тысяч публичных ноутбуков, что позволяет быстро выполнить любой анализ.
Datahub.io
Datahub — это платформа массивов данных, в основном для сфер бизнеса и финансов. На DataHub доступно множество массивов данных, например, списки государств, населения и географических границ, и новые массивы продолжают разрабатываться.
Graviti Open Datasets
Graviti — это новая платформа данных, предоставляющая высококачественные массивы данных в основном для компьютерного зрения. Разработчики и организации могут получать удобный доступ к большим объёмам открытых данных, легко делиться и управлять ими.
Заключение
В этой статье мы узнали, как датацентрический подход отличается от моделецентрического, и как сделать процесс использования машинного обучения более датацентрическим. Мы не обязаны ограничивать развитие одним направлением, и код, и данные играют важную роль в разработке ИИ. Нет никаких жёстких и простых правил выбора между моделецентрическими и датацентрическими методиками, однако надёжность массива данных не стоит игнорировать.
Качество данных нужно поддерживать и совершенствовать на каждом этапе разработки ИИ, и каждый этап по определению требует различных фреймворков и инструментов. Если вам хочется изучить эту тему глубже, можете прочитать статьи по приведённым ниже ссылкам.
Ссылки и рекомендуемое чтение
- Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
- Data-centric Machine Learning: Making customized ML solutions production-ready
- The Significance of Data-centric AI
- Tips for Best Training Results
- Data-centric AI: Real World Approaches
Понравилась статья? Еще больше информации на тему данных, AI, ML, LLM вы можете найти в моем Telegram канале.
- Как подготовиться к сбору данных, чтобы не провалиться в процессе?
- Как работать с синтетическими данными в 2024 году?
- В чем специфика работы с ML проектами? И какие бенчмарки сравнения LLM есть на российском рынке?

