
Передо мной встала задача сбора логов с парка серверов на ОС Windows и ОС Linux. Для того чтобы решить её я воспользовался стэком OpenSearch. Во время настройки OpenSearch мне не хватало в открытых источниках наглядных примеров, а информация на официальных сайтах ElasticSearch и OpenSearch мне показалась обрывочной, слабо привязанной к реальным ситуациям. Поэтому я решил поделиться своим опытом и описать основные моменты установки и некоторые сценарии настройки и применения стэка OpenSearch, которые я применил в своей практике.
Содержание
1. Введение
1.1. Коротко о том, что такое OpenSearch
1.2. Коротко о форках Elasticsearch
1.3. Что и зачем будем настраивать
1.4. Настраиваемая схема
2. Установка стэка OpenSearch
2.1. Подготовка Linux машины Node OpenSearch
2.2. Установка OpenSearch (аналог ElasticSearch)
2.3. Настройки производительности
2.4. Первый запуск OpenSearch
2.5. Смена пароля учетной записи OpenSearch
2.6. Переводим OpenSearch в режим кластера
2.7. Установка OpenSearch-Dashboards (аналог Kibana)
2.8. Установка NGINX и настройка переадресации порта OpenSearch-Dashboards
2.9. Настройка файрволла на запрет доступа по порту 5601
2.10. Установка Logstash-oss-with-OpenSearch-output-plugin
3. Установка Beat’ов
3.1. Установка Filebeat на Linux
3.2. Установка Filebeat на Windows
3.3. Установка Winlogbeat на Windows
4. Настройка на примере нескольких кейсов
4.1. Сценарий сбора данных в формате json
4.1.1. Исходные данные
4.1.2. Процесс сбора данных через Filebeat
4.1.3. Процесс обработки данных в Logstash
4.2. Сценарий сбора однострочных данных в текстовом формате
4.2.1. Исходные данные
4.2.2. Процесс сбора данных через Filebeat
4.2.3. Процесс обработки данных в Logstash
4.3. Сценарий сбора Логов IIS
4.3.1. Процесс сбора данных через Filebeat
4.3.2. Процесс обработки данных в Logstash
4.4. Сценарий сбора системных Логов Windows
4.4.1. Процесс сбора данных через Winlogbeat
4.4.2. Процесс обработки данных в Logstash
4.5. Сценарий сбора системных Логов Linux
4.5.1. Процесс сбора данных через Filebeat
4.5.2. Процесс обработки данных в Logstash
5. Итоговые файлы конфигураций
6. Эксплуатация
6.1. Создание шаблона индексов с помощью OpenSearch-Dashboards
6.2. Отображение данных в OpenSearch-Dashboards
6.3. Поиск в OpenSearch-Dashboards
6.4. Работа с OpenSearch через консоль (без OpenSearch-Dashboards)
7. Актуальные проблемы
7.1. Имена Topic’ов Kafka не должны содержать большие буквы
7.2. Filebeat некорректно создает Topic’и Kafka
7.3. Требуется переход на следующую строку после json сообщения
7.4. Необходимо обращать внимание на кодировку log-файлов
8. Послесловие
1.1. Коротко о том, что такое OpenSearch
1.2. Коротко о форках Elasticsearch
1.3. Что и зачем будем настраивать
1.4. Настраиваемая схема
2. Установка стэка OpenSearch
2.1. Подготовка Linux машины Node OpenSearch
2.2. Установка OpenSearch (аналог ElasticSearch)
2.3. Настройки производительности
2.4. Первый запуск OpenSearch
2.5. Смена пароля учетной записи OpenSearch
2.6. Переводим OpenSearch в режим кластера
2.7. Установка OpenSearch-Dashboards (аналог Kibana)
2.8. Установка NGINX и настройка переадресации порта OpenSearch-Dashboards
2.9. Настройка файрволла на запрет доступа по порту 5601
2.10. Установка Logstash-oss-with-OpenSearch-output-plugin
3. Установка Beat’ов
3.1. Установка Filebeat на Linux
3.2. Установка Filebeat на Windows
3.3. Установка Winlogbeat на Windows
4. Настройка на примере нескольких кейсов
4.1. Сценарий сбора данных в формате json
4.1.1. Исходные данные
4.1.2. Процесс сбора данных через Filebeat
4.1.3. Процесс обработки данных в Logstash
4.2. Сценарий сбора однострочных данных в текстовом формате
4.2.1. Исходные данные
4.2.2. Процесс сбора данных через Filebeat
4.2.3. Процесс обработки данных в Logstash
4.3. Сценарий сбора Логов IIS
4.3.1. Процесс сбора данных через Filebeat
4.3.2. Процесс обработки данных в Logstash
4.4. Сценарий сбора системных Логов Windows
4.4.1. Процесс сбора данных через Winlogbeat
4.4.2. Процесс обработки данных в Logstash
4.5. Сценарий сбора системных Логов Linux
4.5.1. Процесс сбора данных через Filebeat
4.5.2. Процесс обработки данных в Logstash
5. Итоговые файлы конфигураций
6. Эксплуатация
6.1. Создание шаблона индексов с помощью OpenSearch-Dashboards
6.2. Отображение данных в OpenSearch-Dashboards
6.3. Поиск в OpenSearch-Dashboards
6.4. Работа с OpenSearch через консоль (без OpenSearch-Dashboards)
7. Актуальные проблемы
7.1. Имена Topic’ов Kafka не должны содержать большие буквы
7.2. Filebeat некорректно создает Topic’и Kafka
7.3. Требуется переход на следующую строку после json сообщения
7.4. Необходимо обращать внимание на кодировку log-файлов
8. Послесловие
1. Введение
1.1. Коротко о том, что такое OpenSearch
OpenSearch – система полнотекстового поиска. Является форком Elasticsearch. Разработана компанией A9.com, дочерней компанией Amazon.com.
Стэк OpenSearch (OpenSearch + Logstash-oss-with-OpenSearch-output-plugin + OpenSearch–Dashboards) является бесплатным аналогом с отрытым исходным кодом стэку ELK (Elasticsearch + Logstash + Kibana). В совокупности с Beat’ами (Filebeat, Winlogbeat, и т.д.) образуют полный цикл управления логами: сбор, систематизация, поиск.
Можно найти и множество других применений этому стэку, но в этой статье речь пойдет главным образом именно о логах.
1.2. Коротко о форках Elasticsearch
Elasticsearch развивается под этим названием с 2010 года. С 2018 года, с версии 6.3 лицензия на ELK меняется, появляется платная и бесплатная версия. Позже Amazon создает форк Elasticsearch и называет его «Open Distro for Elasticsearch». А в 2021 году Amazon создает новый форк и называет его «OpenSearch». Немного позже Российская компания Arenadata становится официальным партнёром OpenSearch в России и выпускает отечественный форк под названием «Arenadata LogSearch (ADLS)» под платной лицензией.
1.3. Что и зачем будем настраивать
Стэк OpenSearch мы будем разворачивать из архивов, это особенно актуально в закрытых средах. Кроме того, мы не будем использовать Kubernetes и Docker, то есть будем производить установку в классической среде.
В качестве ОС под OpenSearch будем использовать Linux Ubuntu 20.04.
Логи будут транспортироваться с серверов, на которых они возникли на сервер OpenSearch в виде сообщений. Для того, чтобы гарантировать доставку сообщений, в качестве транспорта мы будем использовать сервис Apache Kafka.
Apache Kafka – это распределённый программный брокер сообщений, который гарантирует доставку сообщений.
Мы введем OpenSearch в кластер, но будет описан ввод только основной ноды.
Кластер OpenSearch позволяет решать сразу несколько задач. Во-первых, традиционно, кластер решает задачу масштабирования, распределения нагрузки и отказоустойчивости. Во-вторых, данные накопленные в OpenSearch, можно распределять по их значимости на «Горячие» («Hot»), «Теплые» («Warm») и «Холодные» («Cold»). А ноды кластера можно настроить так чтобы они принимали только «Горячие» данные, или «Теплые» данные, или только «Холодные». И если на ноду под «Холодные» данные выделять менее производительные мощности, то это позволит сэкономить ресурсы.
1.4. Настраиваемая схема
На серверы, с которых нужно собирать логи, мы установим Beat’ы. На серверы под управлением ОС Windows мы установим Filebeat и Winlogbeat. На серверы под управлением Linux мы установим только Filebeat. Beat’ы будут отправлять сообщения с логами в Kafk’у. Logstash будет брать эти сообщения из Kafka, обрабатывать их и отправлять в OpenSearch. Пользователь будет осуществлять просмотр и поиск по логам через OpenSearch-Dashboards. Схема взаимодействия представлена на Рис.1.

Рис.1
Договоримся, что машина Node OpenSearch будет иметь:
1. Имя «server-elk01»;
2. Ip адрес «10.0.0.70».
Машина с Kafka будет иметь:
1. Ip адрес «10.0.0.60».
2. Установка стэка OpenSearch
2.1. Подготовка Linux машины Node OpenSearch
Перед началом установки основных пакетов установим Java и Unzip, а также создадим пользователей для OpenSearch и Logstash.
1. Установка Java:
apt install openjdk-11-jdk
2. Установка unzip:
apt install unzip
3. Создание пользователя opensearch:
groupadd opensearch useradd opensearch -g opensearch -M -s /bin/bash passwd opensearch
4. Создание пользователя logstash:
groupadd logstash useradd logstash -g logstash -M -s /bin/bash passwd logstash
2.2. Установка OpenSearch (аналог ElasticSearch)
OpenSearch, как можно было заметить, является ядром всего стэка. OpenSearch содержит базу данных, в которой будут храниться логи. Кроме того, OpenSearch имеет API для обработки запросов как на ввод данных, так и на вывод. Так же OpenSearch индексирует поступившие в неё данные и осуществляет поиск по этим данным.
Приступаем к установке.
1. Переходим на официальный сайт OpenSearch (https://opensearch.org/downloads.html) и скачиваем архив tar.gz нужной версии. В этой статье я буду использовать OpenSearch версии 1.2.4 (https://artifacts.opensearch.org/releases/bundle/opensearch/1.2.4/opensearch-1.2.4-linux-x64.tar.gz). После скачивания перенесите архив на сервер «server-elk01» в удобный для вас каталог и перейдите в него в консоли.
2. Даем права на выполнение для архива:
chmod +x opensearch-1.2.4-linux-x64.tar.gz
3. Распаковываем архив:
tar -xf opensearch-1.2.4-linux-x64.tar.gz
4. Будем устанавливать OpenSearch в каталог «/opt/opensearch», поэтому создаем рабочий каталог для OpenSearch:
mkdir /opt/opensearch
5. Переносим распакованные данные в рабочий каталог:
mv ./opensearch-1.2.4/* /opt/opensearch
6. Удаляем каталог, оставшийся от распаковки:
rmdir ./opensearch-1.2.4
7. Делаем пользователя opensearch владельцем рабочего каталога OpenSearch:
chown -R opensearch:opensearch /opt/opensearch
8. Запускает установочный скрипт от имени пользователя opensearch:
sudo -u opensearch /opt/opensearch/opensearch-tar-install.sh
Дожидаемся сообщения «Node 'server-elk01' initialized» и нажимаем «Ctrl+C».
9. Создаем файл демона для работы OpenSearch:
nano /lib/systemd/system/opensearch.service
/lib/systemd/system/opensearch.service
[Unit] Description=Opensearch Documentation=https://opensearch.org/docs/latest Wants=network-online.target After=network-online.target [Service] Type=simple RuntimeDirectory=opensearch PrivateTmp=true Restart=on-failure RestartSec=60s WorkingDirectory=/opt/opensearch User=opensearch Group=opensearch ExecStart=/opt/opensearch/bin/opensearch StandardOutput=journal StandardError=inherit # Specifies the maximum file descriptor number that can be opened by this process LimitNOFILE=65535 # Specifies the maximum number of processes LimitNPROC=4096 # Specifies the maximum size of virtual memory LimitAS=infinity # Specifies the maximum file size LimitFSIZE=infinity # Not use SWAP LimitMEMLOCK=infinity # Disable timeout logic and wait until process is stopped TimeoutStopSec=0 # Allow a slow startup before the systemd notifier module kicks in to extend the timeout TimeoutStartSec=75 [Install] WantedBy=multi-user.target
За основу файла демона я взял файл оригинального демона Elasticsearch и переработал его.
10. Делаем пользователя root владельцем файла демона:
chown -R root:root /lib/systemd/system/opensearch.service
11. Перечитаем конфигурацию systemd, чтобы система обнаружила вновь созданный демон:
systemctl daemon-reload
12. Создаем каталог для логов opensearch:
mkdir /var/log/opensearch
13. Делаем пользователя opensearch владельцем каталога логов:
chown -R opensearch /var/log/opensearch
2.3. Настройки производительности
Для того чтобы получить высокую производительность недостаточно иметь хорошее железо, нужно еще и правильно настроить систему. Попробуем оптимизировать несколько параметров.
1. Настройки Java:
Производятся в файле «/opt/opensearch/config/jvm.options». Необходимо настроить два параметра: «Xmx» и «Xms».
Оба параметра рекомендуется установить в значение равное 50% от имеющейся физической памяти узла. Чем больше доступно памяти, тем лучше, но есть ограничения. Значения параметров «Xmx» и «Xms» не должны превышать значение параметра JVM «compressed object pointers» (по умолчанию равен 32 Gb). И, значения параметров «Xmx» и «Xms» не должны превышать значение параметра JVM «zero-based compressed oops» (по умолчанию равен 26 Gb).
У меня на машине «server-elk01» установлено 8 Gb оперативной памяти поэтому настройки получились такие:
nano /opt/opensearch/config/jvm.options
/opt/opensearch/config/jvm.options
... -Xms4g -Xmx4g ...
2. Настройка виртуальной памяти:
nano /etc/sysctl.conf
/etc/sysctl.conf
... # Добавить в конце файла vm.max_map_count=262144
Для того, чтобы изменения вступили в силу без перезагрузки хоста можно выполнить следующую команду в консоли:
sysctl -w vm.max_map_count=262144
2.4. Первый запуск OpenSearch
На этом этапе уже все готово к тому, чтобы запустить OpenSearch. Глубокой настройкой займемся позже, а сейчас просто запустим OpenSearch.
1. Запустим настроенный нами демон OpenSearch:
systemctl start opensearch
2. Проверим статус запуска демона OpenSearch:
systemctl status opensearch
3. Настроим автозапуск демона OpenSearch:
systemctl enable opensearch
4. Проверим работоспособность демона OpenSearch:
curl -X GET https://localhost:9200 -u 'admin:admin' --insecure
Если вы устанавливаете OpenSearch в ознакомительных целях, то можете считать установку законченной и приступать к использованию OpenSearch, правда только в консольном режиме, Web-интерфейс (OpenSearch-Dashboards) мы еще не устанавливали.
2.5. Смена пароля учетной записи OpenSearch
По умолчанию в OpenSearch предустановлена админская учетная запись «admin» с паролем «admin», поэтому для повышения уровня безопасности сменим пароль этой учетной записи. Для этого выполним следующие шаги.
1. Остановим демон OpenSearch:
systemctl stop opensearch
2. Дадим права на выполнение скрипта получения хэша пароля:
chmod +x /opt/opensearch/plugins/opensearch-security/tools/hash.sh
3. Запускаем скрипт и вводим новый пароль «yN-3L(GMmAAw»:
/opt/opensearch/plugins/opensearch-security/tools/hash.sh
Запоминаем полученный хэш, например:
$2y$12$OCvWNlMu8VbOarfdXdcjPOnHarqktJIcTYjwoykXdaJJfjcCTmfXO
К слову, я указал реальный хэш к описанному паролю, в тестах можно их использовать.
4. Заменим хэш пароля пользователя admin:
nano /opt/opensearch/plugins/opensearch-security/securityconfig/internal_users.yml
/opt/opensearch/plugins/opensearch-security/securityconfig/internal_users.yml
... admin: hash: "$2y$12$OCvWNlMu8VbOarfdXdcjPOnHarqktJIcTYjwoykXdaJJfjcCTmfXO" ...
5. Дадим права на выполнение скрипта для создания новых сертификатов:
chmod +x /opt/opensearch/plugins/opensearch-security/tools/securityadmin.sh
6. Перейдём в каталог со скриптом:
cd /opt/opensearch/plugins/opensearch-security/tools
7. Запустим демон OpenSearch:
systemctl start opensearch
8. Запускаем скрипт для создания новых сертификатов:
./securityadmin.sh -cd ../securityconfig/ -icl -nhnv \ -cacert ../../../config/root-ca.pem \ -cert ../../../config/kirk.pem \ -key ../../../config/kirk-key.pem
9. Проверяем работоспособность OpenSearch с новым паролем:
curl -X GET https://localhost:9200 -u 'admin:yN-3L(GMmAAw' --insecure
Аналогичным образом можно сменить пароль и у других учетных записей, которые можно обнаружить в «/opt/opensearch/plugins/opensearch-security/securityconfig/internal_users.yml», если вам это необходимо.
2.6. Переводим OpenSearch в режим кластера
Как я писал выше в реализуемой схеме мы введем OpenSearch в кластер, но введем только одну ноду. Потому как задачи перед кластером можно поставить разные то и настройки, и схемы могут сильно отличаться. Если вам потребуется только одна машина с OpenSearch, то можно и не вводить её в кластер, тогда этот шаг можно пропустить. А мы приступим.
1. Остановим демон OpenSearch:
systemctl stop opensearch
2. Добавляем параметры в настройки OpenSearch:
nano /opt/opensearch/config/opensearch.yml
/opt/opensearch/config/opensearch.yml
# ------------------------------------ Node ------------------------------------ # Имя ноды: node.name: os-node01-server-elk01 # Роли узла: node.roles: [ master, data ] # # ---------------------------------- Network ----------------------------------- # Адрес узла - принимать на любых адресах: network.host: 0.0.0.0 # Порт: http.port: 9200 # # ---------------------------------- Cluster ----------------------------------- # Имя кластера: cluster.name: os_cluster # Список узлов в голосовании по выбору master узла: cluster.initial_master_nodes: ["os-node01"] # # --------------------------------- Discovery ---------------------------------- # Список master узлов кластера: discovery.seed_hosts: ["10.0.0.70"] # # ----------------------------------- Paths ------------------------------------ # Директория с данными: path.data: /opt/opensearch/data # Директория с логами: path.logs: /var/log/opensearch # ######## Start OpenSearch Security Demo Configuration ######## # WARNING: revise all the lines below before you go into production plugins.security.ssl.transport.pemcert_filepath: esnode.pem plugins.security.ssl.transport.pemkey_filepath: esnode-key.pem plugins.security.ssl.transport.pemtrustedcas_filepath: root-ca.pem plugins.security.ssl.transport.enforce_hostname_verification: false plugins.security.ssl.http.enabled: true plugins.security.ssl.http.pemcert_filepath: esnode.pem plugins.security.ssl.http.pemkey_filepath: esnode-key.pem plugins.security.ssl.http.pemtrustedcas_filepath: root-ca.pem plugins.security.allow_unsafe_democertificates: true plugins.security.allow_default_init_securityindex: true plugins.security.authcz.admin_dn: - CN=kirk,OU=client,O=client,L=test, C=de plugins.security.authcz.type: internal_opensearch plugins.security.enable_snapshot_restore_privileges: true plugins.security.check_snapshot_restore_write_privileges: true plugins.security.restapi.roles_enabled: ["all_access", "security_rest_api_access"] plugins.security.system_indices.enabled: true plugins.security.system_indices.indices: [".opendistro-alerting-config", ".opendistro-alerting-alert*", ".opendistro-anomaly-results*", ".opendistro-anomaly-detector*", ".opendistro-anomaly-checkpoints", ".opendistro-anomaly-detection-state", ".opendistro-reports-*", ".opendistro-notifications-*", ".opendistro-notebooks", ".opendistro-observability", ".opendistro-asynchronous-search-response*", ".opendistro-metadata-store"] node.max_local_storage_node: 3 ######## End OpenSearch Security Demo Configuration ########
Обращаем внимание на роль ноды (master, data). Роль «master» — означает, что нода управляет кластером. Роль «data» — означает, что нода содержит базу данных.
3. Запускаем демон OpenSearch:
systemctl start opensearch
4. Проверим работоспособность OpenSearch:
curl -X GET https://localhost:9200 -u 'admin:yN-3L(GMmAAw' --insecure
5. Проверим состояние кластера:
curl -X GET https://localhost:9200/_cluster/health?pretty -u 'admin:yN-3L(GMmAAw' --insecure
6. Выясним кто мастер в кластере:
curl -X GET https://localhost:9200/_cat/master?pretty -u 'admin:yN-3L(GMmAAw' --insecure
2.7. Установка OpenSearch-Dashboards (аналог Kibana)
OpenSearch-Dashboards является Web-интерфейсом для OpenSearch. Для тех кто собирается работать с OpenSearch из консоли этот шаг можно и пропустить. Так же вместо OpenSearch-Dashboards в качестве Web-интерфейса можно установить и другие утилиты, например, «Grafana».
Приступим к установке OpenSearch-Dashboards.
1. Переходим на официальный сайт OpenSearch (https://opensearch.org/downloads.html) и скачиваем архив tar.gz нужной версии. В этой статье я буду использовать OpenSearch-Dashboards версии 1.2.0 (https://artifacts.opensearch.org/releases/bundle/opensearch-dashboards/1.2.0/opensearch-dashboards-1.2.0-linux-x64.tar.gz). После скачивания перенесите архив на сервер «server-elk01» в удобный для вас каталог и перейдите в него в консоли.
2. Даем права на выполнение для архива:
chmod +x opensearch-dashboards-1.2.0-linux-x64.tar.gz
3. Распаковываем архив:
tar -xf opensearch-dashboards-1.2.0-linux-x64.tar.gz
4. Будем устанавливать OpenSearch-Dashboards в каталог «/opt/opensearch-dashboards», поэтому создаем рабочий каталог для OpenSearch-Dashboards:
mkdir /opt/opensearch-dashboards
5. Переносим распакованные данные в рабочий каталог:
mv ./opensearch-dashboards-1.2.0-linux-x64/* ./opensearch-dashboards-1.2.0-linux-x64/.* /opt/opensearch-dashboards/
6. Удаляем каталог, оставшийся от распаковки:
rmdir ./opensearch-dashboards-1.2.0-linux-x64
7. Делаем пользователя opensearch владельцем рабочего каталога OpenSearch-Dashboards:
chown -R opensearch:opensearch /opt/opensearch-dashboards
По умолчанию OpenSearch-Dashboards доступен по порту 5601. Можно изменить порт в настройках OpenSearch-Dashboards, однако тогда придется запускать сервис под учетной записью root.
Поэтому оставим порт по умолчанию и позже настроим переадресацию через NGINX.
Для информации, для смены порта по умолчанию необходимо внести следующие изменения:
/opt/opensearch-dashboards/config/opensearch_dashboards.yml
nano /opt/opensearch-dashboards/config/opensearch_dashboards.yml
... # Добавить в конец файла server.port: 80 server.host: 10.0.0.70
8. Создаем файл демона для работы OpenSearch-Dashboards:
nano /lib/systemd/system/opensearch_dashboards.service
/lib/systemd/system/opensearch_dashboards.service
[Unit] Description=Opensearch_dashboards Documentation=https://opensearch.org/docs/latest Wants=network-online.target After=network-online.target [Service] Type=simple RuntimeDirectory=opensearch_dashboards PrivateTmp=true WorkingDirectory=/opt/opensearch-dashboards User=opensearch Group=opensearch ExecStart=/opt/opensearch-dashboards/bin/opensearch-dashboards StandardOutput=journal StandardError=inherit # Specifies the maximum file descriptor number that can be opened by this process LimitNOFILE=65535 # Specifies the maximum number of processes LimitNPROC=4096 # Specifies the maximum size of virtual memory LimitAS=infinity # Specifies the maximum file size LimitFSIZE=infinity # Disable timeout logic and wait until process is stopped TimeoutStopSec=0 # Allow a slow startup before the systemd notifier module kicks in to extend the timeout TimeoutStartSec=75 [Install] WantedBy=multi-user.target
9. Делаем пользователя root владельцем файла демона:
chown -R root:root /lib/systemd/system/opensearch_dashboards.service
10. Перечитаем конфигурацию systemd, чтобы система обнаружила вновь созданный демон:
systemctl daemon-reload
11. Запустим настроенный нами демон OpenSearch-Dashboards:
systemctl start opensearch_dashboards
12. Проверим статус запуска демона OpenSearch-Dashboards:
systemctl status opensearch_dashboards
13. Настроим автозапуск демона OpenSearch-Dashboards:
systemctl enable opensearch_dashboards
2.8. Установка NGINX и настройка переадресации порта OpenSearch-Dashboards
OpenSearch-Dashboards работает на порту 5601, но это неудобно, так как портом для Web-ресурсов по умолчанию является порт 80. Мы установим NGINX и настроим его так, чтобы он слушал 80 порт и перенаправлял с него все запросы на порт 5601. То есть NGINX будет работать в режиме прокси. Приступаем.
1. Установим Nginx на хост:
apt install nginx
2. Настроим автозапуск Nginx:
systemctl enable nginx
3. Не будем удалять, а сделаем резервную копию настроек Nginx по умолчанию:
cp /etc/nginx/sites-enabled/default /etc/nginx/sites-enabled/default.sav
4. Настроим переадресацию OpenSearch-Dashboards с порта 5601 на 80:
nano /etc/nginx/sites-enabled/default
/etc/nginx/sites-enabled/default
map $http_upgrade $connection_upgrade { # WebSocket support default upgrade; '' ''; } server { listen 80; server_name server-elk01 server-elk01.domain.ad 10.0.0.70; location / { proxy_pass http://127.0.0.1:5601; # full internal address proxy_http_version 1.1; proxy_set_header Host $server_name:$server_port; proxy_set_header X-Forwarded-Host $http_host; # necessary for proper absolute redirects and TeamCity CSRF check proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-For $remote_addr; proxy_set_header Upgrade $http_upgrade; # WebSocket support proxy_set_header Connection $connection_upgrade; # WebSocket support } }
5. Активируем новые настройки Nginx без перезагрузки демона:
nginx -s reload
В случае неудачи перезагрузим Nginx:
service nginx reload
2.9. Настройка файрволла на запрет доступа по порту 5601
После того как мы настроили на NGINX переадресацию с 80 порта на порт 5601 сам порт 5601 продолжит принимать запросы. На этом шаге мы закроем порт 5601 файерволлом. Это, конечно, не обязательно, но, я считаю, что так будет больше порядка.
Само правило для файрволла не сложное, а вариантов как сделать так, чтобы после перезагрузки системы правило активировалось вновь можно придумать много. Я пойду по пути создания демона, который будет запускать bash-скрипт «/etc/rc.local». А сам скрипт будет содержать команду добавления правила в файрволл. Приступим.
1. Правило привяжем к сетевому интерфейсу, поэтому сначала необходимо узнать название сетевого интерфейса, для этого воспользуемся командой:
ip link show
или командой:
ifconfig
В моей системе сетевой интерфейс имеет имя «ens160».
2. Создадим Bash-скрипт с правилом файрволла:
nano /etc/rc.local
/etc/rc.local
#!/bin/bash iptables -A INPUT -i ens160 -p tcp --dport 5601 -j DROP exit 0
Соответственно имя интерфейса нужно изменить на имя своего интерфейса.
3. Дадим скрипту права на выполнение:
chmod +x /etc/rc.local
4. Делаем пользователя root владельцем скрипта:
chown -R root:root /etc/rc.local
5. Создадим файл демона для запуска скрипта:
nano /etc/systemd/system/rc-local.service
/etc/systemd/system/rc-local.service
[Unit] Description=/etc/rc.local Compatibility ConditionPathExists=/etc/rc.local [Service] Type=forking ExecStart=/etc/rc.local start TimeoutSec=0 StandardOutput=tty RemainAfterExit=yes SysVStartPriority=99 [Install] WantedBy=multi-user.target
6. Зададим права на файл демона:
chmod 644 /etc/systemd/system/rc-local.service
7. Делаем пользователя root владельцем файла демона:
chown -R root:root /etc/systemd/system/rc-local.service
8. Перечитаем конфигурацию systemd, чтобы система обнаружила вновь созданный демон:
systemctl daemon-reload
9. Запустим настроенный нами демон rc-local:
systemctl start rc-local
10. Проверим статус запуска демона rc-local:
systemctl status rc-local
11. Настроим автозапуск демона rc-local:
systemctl enable rc-local
2.10. Установка Logstash-oss-with-OpenSearch-output-plugin
Logstash в реализуемой схеме выполняет несколько задач. Во-первых, он как насос будет постоянно обращаться к Kafka и втягивать все новые сообщения, которые будут накапливаться в Kafka. Во-вторых, получаемые сообщения он будет преобразовывать правилами, которые мы в него позже заложим. И в-третьих, он будет раскладывать преобразованные сообщения по разным индексам в OpenSearch. Приступим к установке.
1. Переходим на официальный сайт OpenSearch (https://opensearch.org/downloads.html) и скачиваем архив tar.gz нужной версии. В этой статье я буду использовать Logstash-oss-with-OpenSearch-output-plugin версии 7.16.2 (https://artifacts.opensearch.org/logstash/logstash-oss-with-opensearch-output-plugin-7.16.2-linux-x64.tar.gz). После скачивания перенесите архив на сервер «server-elk01» в удобный для вас каталог и перейдите в него в консоли.
2. Даем права на выполнение для архива:
chmod +x logstash-oss-with-opensearch-output-plugin-7.16.2-linux-x64.tar.gz
3. Распаковываем архив:
tar -xf logstash-oss-with-opensearch-output-plugin-7.16.2-linux-x64.tar.gz
4. Будем устанавливать Logstash-oss-with-OpenSearch-output-plugin в каталог «/opt/logstash», поэтому создаем рабочий каталог для Logstash-oss-with-OpenSearch-output-plugin:
mkdir /opt/logstash
5. Переносим распакованные данные в рабочий каталог:
mv ./logstash-7.16.2/* /opt/logstash/
6. Удаляем каталог, оставшийся от распаковки:
rmdir ./logstash-7.16.2
7. Делаем пользователя logstash владельцем рабочего каталога Logstash-oss-with-OpenSearch-output-plugin:
chown -R logstash:logstash /opt/logstash
8. Создаем файл демона для работы Logstash-oss-with-OpenSearch-output-plugin:
nano /etc/systemd/system/logstash.service
/etc/systemd/system/logstash.service
[Unit] Description=logstash [Service] Type=simple User=logstash Group=logstash ExecStart=/opt/logstash/bin/logstash "--path.settings" "/opt/logstash/config" Restart=always WorkingDirectory=/opt/logstash Nice=19 LimitNOFILE=16384 # When stopping, how long to wait before giving up and sending SIGKILL? # Keep in mind that SIGKILL on a process can cause data loss. TimeoutStopSec=75 [Install] WantedBy=multi-user.target
Отмечу, что в файле демона оригинального Logstash от Elastic отсутствует параметр «TimeoutStopSec=75». И у меня были случаи, когда при остановке демон Logstash зависал, и приходилось искать java-процесс и убивать его. Параметр «TimeoutStopSec=75» принудительно завершит выполнение демона, если через 75 секунд после команды «stop» процесс не завершится.
9. Зададим права на файл демона:
chmod 644 /etc/systemd/system/logstash.service
10. Делаем пользователя root владельцем файла демона:
chown -R root:root /etc/systemd/system/logstash.service
11. Перечитаем конфигурацию systemd, чтобы система обнаружила вновь созданный демон:
systemctl daemon-reload
12. Зададим путь к базе данных и логам Logstash-oss-with-OpenSearch-output-plugin:
nano /opt/logstash/config/logstash.yml
/opt/logstash/config/logstash.yml
path.data: /opt/logstash/data pipeline.ordered: auto path.logs: /var/log/logstash
13. Зададим путь для чтения файлов pipelines:
nano /opt/logstash/config/pipelines.yml
/opt/logstash/config/pipelines.yml
- pipeline.id: man path.config: "/opt/logstash/config/conf.d/*.conf"
14. Создадим каталог для файлов pipelines:
mkdir /opt/logstash/config/conf.d
15. Создадим каталог для логов:
mkdir /var/log/logstash
16. Делаем пользователя logstash владельцем каталога логов:
chown -R logstash /var/log/logstash
17. На этом этапе следовало бы сконфигурировать файлы pipelines для обработки данных поступающих из kafka и уходящих в OpenSearch, но я опишу это позже в нескольких кейсах и предоставлю итоговые файлы конфигураций.
18. После окончания настройки еще раз делаем пользователя logstash владельцем всех файлов в рабочем каталоге Logstash-oss-with-OpenSearch-output-plugin:
chown -R logstash:logstash /opt/logstash
19. Запустим настроенный нами демон Logstash-oss-with-OpenSearch-output-plugin:
systemctl start logstash
20. Проверим статус запуска демона Logstash-oss-with-OpenSearch-output-plugin:
systemctl status logstash
21. Настроим автозапуск демона Logstash-oss-with-OpenSearch-output-plugin:
systemctl enable logstash
3. Установка Beat’ов
Beat’ы это своего рода агенты, которые устанавливаются на каждом сервер. Они следят за определенными объектами, в нашем случае за файлами с логами, и когда заметят, что в файле произошли изменения они (Beat’ы) сформируют сообщение, которое будет содержать эти изменения, и отправят их (сообщения), в нашем случае, в Kafka.
Сразу стоит отметить, что Elastic выпускает две версии beat’ов: (условно) «платные» (Filebeat, Winlogbeat и т.д.) и (условно) «бесплатные» (Filebeat-OSS-only, Winlogbeat-OSS-only и т.д.). На сколько я понял «платные» работают так же, как и «бесплатные», за исключением того, что в «платных» можно подключить платный функционал «X-Pack». То есть «платные» обладают расширенными возможностями, которые можно и не покупать, и при этом не обладают временным ограничением действия. Поэтому далее я буду использовать Filebeat и Winlogbeat, но без платного функционала «X-Pack».
3.1. Установка Filebeat на Linux
1. Переходим на официальный сайт Elastic в раздел Filebeat (https://www.elastic.co/downloads/beats/filebeat) и скачиваем архив deb нужной версии. В этой статье я буду использовать Filebeat версии 7.12.1 (https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.12.1-amd64.deb).
Я буду настраивать Filebeat на той же машине, где развернут OpenSearch, поэтому после скачивания перенесите архив на сервер «server-elk01» в удобный для вас каталог и перейдите в него в консоли.
2. Даем права на выполнение для архива:
chmod +x ./filebeat-7.12.1-amd64.deb
3. Установим Filebeat:
dpkg -i ./filebeat-7.12.1-amd64.deb
4. На этом этапе следовало бы сконфигурировать файл «/etc/filebeat/filebeat.yml», но я опишу это позже в нескольких кейсах и предоставлю итоговый файл конфигурации.
5. Подключаем модуль system в filebeat:
filebeat modules enable system
6. Подключаем модуль kafka в filebeat:
filebeat modules enable kafka
7. Проверим список подключенных модулей:
filebeat modules list
8. Запустим демон Filebeat:
systemctl start filebeat
9. Проверим статус запуска демона Filebeat:
systemctl status filebeat
10. Настроим автозапуск демона Filebeat:
systemctl enable filebeat
3.2. Установка Filebeat на Windows
1. Переходим на официальный сайт Elastic в раздел Filebeat (https://www.elastic.co/downloads/beats/filebeat) и скачиваем архив zip нужной версии. В этой статье я буду использовать Filebeat версии 7.12.1 (https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.12.1-windows-x86_64.zip).
2. Будем устанавливать Filebeat в каталог «C:\filebeat», поэтому после скачивания перенесите архив на сервер «server-windows01» и распакуйте его в каталог «C:\filebeat».
3. На этом этапе следовало бы сконфигурировать файл «C:\filebeat\filebeat.yml», но я опишу это позже в нескольких кейсах и предоставлю итоговый файл конфигурации.
4. Для создания службы нужно выполнить следующий скрипт с правами администратора:
powershell "C:\filebeat\install-service-filebeat.ps1"
5. Для запуска Filebeat без службы можно использовать команды:
cd C:\filebeat\ filebeat -e -c filebeat.yml
3.3. Установка Winlogbeat на Windows
1. Переходим на официальный сайт Elastic в раздел Winlogbeat (https://www.elastic.co/downloads/beats/winlogbeat) и скачиваем архив zip нужной версии. В этой статье я буду использовать Winlogbeat версии 7.12.1 (https://artifacts.elastic.co/downloads/beats/winlogbeat/winlogbeat-7.12.1-windows-x86_64.zip).
2. Будем устанавливать Winlogbeat в каталог «C:\winlogbeat», поэтому после скачивания перенесите архив на сервер «server-windows01» и распакуйте его в каталог «C:\winlogbeat».
3. На этом этапе следовало бы сконфигурировать файл «C:\winlogbeat\winlogbeat.yml», но я опишу это позже в нескольких кейсах и предоставлю итоговый файл конфигурации.
4. Для создания службы нужно выполнить следующий скрипт с правами администратора:
powershell "C:\winlogbeat\install-service-winlogbeat.ps1"
5. Для запуска Winlogbeat без службы можно использовать команды:
cd C:\winlogbeat\ winlogbeat -e -c winlogbeat.yml
4. Настройка на примере нескольких кейсов
Рассмотрим несколько ситуаций, в разрезе разных форматов собираемых данных и в разрезе разных Beat’ов, которые будут собирать данные. Посмотрим, как выглядят данные, которые нам предстоит собрать. Какой Beat их будет собирать. Как следует настроить Beat в каждой ситуации. И как следует настроить Logstash в каждой ситуации.
4.1. Сценарий сбора данных в формате json
4.1.1. Исходные данные
Файл (файлы) логов содержит сообщения в виде списка json объектов. Формат самого файла текстовый (не json), то есть квадратные скобки в начале и в конце файла не нужны.
Файл дописывается новыми сообщениями по мере необходимости.
Пример:
«C:\Temp\test_log_json2\2022-03-15.log»
{ "logId": "ID_1", "uniqueSubId": "001", "mess": "test_text" } { "logId": "ID_2", "uniqueSubId": "002", "mess": "test_text2" } { "logId": "ID_3", "uniqueSubId": "003", "mess": "test_text3" }
Зачем нужно добавлять пустые строки после каждого json-объекта я опишу далее в разделе «Актуальные проблемы».
4.1.2. Процесс сбора данных через Filebeat
Служба Filebeat будет периодически проверять файл на наличие изменений. При обнаружении изменений эти изменения будут отправлены в Topic Kafka. На выходе в начало сообщения добавим метку времени отправки данных с сервера. Во входящее сообщение добавим тэг «test-json», а на выходе будем отправлять в Topic Kafka только те сообщения, которые содержат этот тэг. Так мы промаркируем сообщения. Маркировка сообщений становится актуальна, когда входящих и исходящих потоков несколько. Я добавил маркировку сообщения в этом кейсе для полноты конфигурации.
Отдельного внимания заслуживает параметр «codec.format». Если его не указывать, то, по умолчанию, отправляемое сообщение будет в формате json и будет содержать целый набор полей, которые содержат в основном техническую (справочную) информацию (имя и версию ОС, имя и версию Beat’а и т.д.). Меня же интересует только основное сообщение, которое содержится в поле «message», остальные данные я буду считать объективно известными, за счет того, что все потоки данных разделены на отдельные Topic’и Kafka.
Полный список полей, отправляемых в сообщении с настройками по умолчанию: «event», «log», «message», «@timestamp», «@metadata», «ecs», «agent», «host», «service», «input», «fileset».
Пример конфигурации Filebeat:
«C:\filebeat\filebeat.yml»
filebeat.inputs: - type: log enabled: true paths: - C:\Temp\test_log_json2\* multiline.pattern: '^{' multiline.negate: true multiline.match: after processors: - decode_json_fields: fields: ["message"] target: "json" tags: ["test-json"] filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false setup.template.settings: index.number_of_shards: 1 setup.kibana: processors: - add_host_metadata: when.not.contains.tags: forwarded - add_cloud_metadata: ~ - add_docker_metadata: ~ - add_kubernetes_metadata: ~ output.kafka: hosts: ["10.0.0.60:9092"] topics: - topic: "server-windows01-test-json" when.contains: tags: "test-json" codec.format: string: '%{[@timestamp]} %{[message]}' partition.round_robin: reachable_only: false required_acks: 1 compression: gzip max_message_bytes: 1000000 close_inactive: 10m
4.1.3. Процесс обработки данных в Logstash
Демон Logstash при обнаружении новых данных в Topic'е Kafka начинает их прием и обработку. Данные внутри Logstash поступают сначала в модуль input, потом поступают в модуль filter и затем поступают в модуль output.
В модуле input примем данные из Topic'а Kafka и добавим в сообщение поле «type», которое будет содержать название Topic'а.
Пример конфигурации Logstash модуля input:
«/opt/logstash/config/conf.d/server-windows01-input.conf»
input { kafka { type => "server-windows01-test-json" bootstrap_servers => "10.0.0.60:9092" topics => "server-windows01-test-json" } }
В модуле filter обрабатываются только те сообщения, в которых есть поле «type», значение которого равно имени Topic'а Kafka. Из начала сообщения вырежем метку времени и добавим её в новое поле «timestamp_filebeat». Декодируем основное сообщение из формата json, при этом все заголовки ключей станут одноименными полями, а значения ключей перейдут в значения полей. Добавим поле «timestamp_logstash», для фиксирования времени, в которое проводилась обработка сообщения.
Пример конфигурации Logstash модуля filter:
«/opt/logstash/config/conf.d/server-windows01-filter.conf»
filter { if [type] == "server-windows01-test-json" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_filebeat} %{GREEDYDATA:message}" } overwrite => [ "message" ] } json { source => "message" } mutate { add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } }
В модуле output обрабатываются только те сообщения, в которых есть поле «type», значение которого равно имени Topic'а Kafka. Каждое сообщение отправляется в OpenSearch в индекс, соответствующий текущей дате, имени Topic’а и префикса «Kafka».
Пример конфигурации Logstash модуля output:
«/opt/logstash/config/conf.d/server-windows01-output.conf»
output { if [type] == "server-windows01-test-json" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-windows01-test-json-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } }
4.2. Сценарий сбора однострочных данных в текстовом формате
4.2.1. Исходные данные
Каждая строка файла будет извлекаться как новое сообщение и всё содержимое строки будет помещено в поле «message» как текст. В Filebeat такой сценарий работает по умолчанию. Нам остается только промаркировать сообщения и отправить их в нужный Topic Kafka.
Если содержание всех строк стандартизировано, то в Logstash на этапе Filter можно разложить сообщение на заранее известные поля. В этом примере мы этого делать не будем.
Пример:
«C:\Temp\log\2022-03-16.log»
[2022.03.16 13:01:09] Info | Just text Next text [2022.03.16 13:02:01] Info | New text
4.2.2. Процесс сбора данных через Filebeat
Процесс сбора данных аналогичен ситуации сбора данных в формате json за исключением того, что нам не нужно парсить json, так же изменим тэг для маркировки входящих сообщений, и изменим Topic Kafka.
Пример конфигурации Filebeat:
«C:\filebeat\filebeat.yml»
filebeat.inputs: - type: filestream paths: - C:\Temp\log\*.log tags: ["simple-logs"] filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false setup.template.settings: index.number_of_shards: 1 setup.kibana: processors: - add_host_metadata: when.not.contains.tags: forwarded - add_cloud_metadata: ~ - add_docker_metadata: ~ - add_kubernetes_metadata: ~ output.kafka: hosts: ["10.0.0.60:9092"] topics: - topic: "server-windows01-simple-logs" when.contains: tags: "simple-logs" codec.format: string: '%{[@timestamp]} %{[message]}' partition.round_robin: reachable_only: false required_acks: 1 compression: gzip max_message_bytes: 1000000 close_inactive: 10m
4.2.3. Процесс обработки данных в Logstash
Процесс обработки данных в Logstash будет незначительно отличаться от сценария для ситуации с json-объектами, поэтому я приведу только примеры конфигураций.
Пример конфигурации Logstash модуля input:
«/opt/logstash/config/conf.d/server-windows01-input.conf»
input { kafka { type => "server-windows01-simple-logs" bootstrap_servers => "10.0.0.60:9092" topics => "server-windows01-simple-logs" } }
Пример конфигурации Logstash модуля filter:
«/opt/logstash/config/conf.d/server-windows01-filter.conf»
filter { if [type] == "server-windows01-simple-logs" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_filebeat} %{GREEDYDATA:message}" } overwrite => [ "message" ] } mutate { add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } }
Пример конфигурации Logstash модуля output:
«/opt/logstash/config/conf.d/server-windows01-output.conf»
output { if [type] == "server-windows01-simple-logs" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-windows01-simple-logs-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } }
4.3. Сценарий сбора Логов IIS
Для сбора логов IIS в Filebeat предусмотрен отдельный модуль, который так и называется IIS. В IIS логи делятся на две категории: «ACCESS» и «ERROR». У меня пути к этим логам настроены по умолчанию.
4.3.1. Процесс сбора данных через Filebeat
Для того, чтобы промаркировать эти две категории («ACCESS» и «ERROR») и направить их в разные Topic’и Kafka я использовал параметр «@metadata.pipeline».
Так же стоит обратить внимание на параметры «var.paths», по какой-то причине в путях необходимо использовать обратные слэши.
Пример конфигурации Filebeat:
«C:\filebeat\filebeat.yml»
filebeat.inputs: filebeat.modules: - module: iis access: enabled: true var.paths: ["C:/inetpub/logs/LogFiles/*/*.log"] error: enabled: true var.paths: ["C:/Windows/System32/LogFiles/HTTPERR/*.log"] filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false setup.template.settings: index.number_of_shards: 1 setup.kibana: processors: - add_host_metadata: when.not.contains.tags: forwarded - add_cloud_metadata: ~ - add_docker_metadata: ~ - add_kubernetes_metadata: ~ output.kafka: hosts: ["10.0.0.60:9092"] topics: - topic: "rgmtpaydox39-iis-access" when.contains: "@metadata.pipeline": "iis-access" - topic: "rgmtpaydox39-iis-error" when.contains: "@metadata.pipeline": "iis-error" codec.format: string: '%{[@timestamp]} %{[message]}' partition.round_robin: reachable_only: false required_acks: 1 compression: gzip max_message_bytes: 1000000 close_inactive: 10m
4.3.2. Процесс обработки данных в Logstash
Пример конфигурации Logstash модуля input:
«/opt/logstash/config/conf.d/server-windows01-input.conf»
input { kafka { type => "server-windows01-iis-access" bootstrap_servers => "10.0.0.60:9092" topics => "server-windows01-iis-access" } kafka { type => "server-windows01-iis-error" bootstrap_servers => "10.0.0.60:9092" topics => "server-windows01-iis-error" } }
Во время обработки «iis-access» из начала сообщения вырежем метку времени и добавим её в новое поле «timestamp_filebeat». Затем из полученного сообщения снова вырежем метку времени из начала сообщения и добавим её в новое поле «timestamp_windows». Затем преобразуем тип поля «timestamp_windows» из строкового в тип «дата». Это позволит в дальнейшем в OpenSearch-Dashboards создавать шаблоны индексов с фильтрацией по этому полю. Затем добавим еще одно поле «timestamp_logstash».
За счет наличия трех меток времени мы сможем точно отследить, когда событие возникло в windows, когда попало в обработку Filebeat и когда попало в обработку Logstash.
Обработка «iis-error» осуществляется аналогичным образом.
Пример конфигурации Logstash модуля filter:
«/opt/logstash/config/conf.d/server-windows01-filter.conf»
filter { if [type] == "server-windows01-iis-access" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_filebeat} %{GREEDYDATA:message}" } overwrite => [ "message" ] } grok { match => [ "message", "%{TIMESTAMP_ISO8601:timestamp_windows} %{GREEDYDATA:message}" ] overwrite => [ "message" ] } date { match => ["timestamp_windows", "ISO8601", "YYYY-MM-dd HH:mm:ss", "MMM dd, YYYY @ HH:mm:ss.ZZZ"] target => "timestamp_windows" locale => "en" } mutate { add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } if [type] == "server-windows01-iis-error" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_filebeat} %{GREEDYDATA:message}" } overwrite => [ "message" ] } grok { match => [ "message", "%{TIMESTAMP_ISO8601:timestamp_windows} %{GREEDYDATA:message}" ] overwrite => [ "message" ] } date { match => ["timestamp_windows", "ISO8601", "YYYY-MM-dd HH:mm:ss", "MMM dd, YYYY @ HH:mm:ss.ZZZ"] target => "timestamp_windows" locale => "en" } mutate { add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } }
Пример конфигурации Logstash модуля output:
«/opt/logstash/config/conf.d/server-windows01-output.conf»
output { if [type] == "server-windows01-iis-access" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-windows01-iis-access-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } if [type] == "server-windows01-iis-error" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-windows01-iis-error-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } }
4.4. Сценарий сбора системных Логов Windows
4.4.1. Процесс сбора данных через Winlogbeat
Системные логи Windows будем собирать с помощью Winlogbeat. Доступны 3 вида логов: «Application», «Security» и «System».
Winlogbeat имеет особенность в отличие от Filebeat. Подставляемый на выходе параметр «timestamp» будет содержать не время отправки с сервера, а время события (из лога), произошедшего в Windows. Временная метка отправки с сервера будет содержаться в поле «event» в параметре «created» («event.created»). Кроме того, я посчитал еще несколько полей информативными. В итоге на выходе отправляются следующие поля: «@timestamp», «message», «event», «log», «winlog». При этом «@timestamp» расположен в начале сообщения и отделен пробелом. Все остальные поля я разделил символом «|».
Полный список полей, отправляемых в сообщении с настройками по умолчанию: «event», «log», «message», «winlog», «@timestamp», «@metadata», «ecs», «agent», «host».
Так же как и в Filebeat вы можете убрать параметр «codec.format» и посмотреть полный список полей и их значений, которые попадут в Logstash в формате json.
К каждому виду логов можно добавить параметр «ignore_older», чтобы игнорировать слишком старые логи. Я добавил этот параметр к «Application» со значением «72h», чтобы игнорировать логи старше 72 часов.
Пример конфигурации Winlogbeat:
«C:\winlogbeat\winlogbeat.yml»
winlogbeat.event_logs: - name: Application ignore_older: 72h tags: ["server-windows01-application"] - name: Security tags: ["server-windows01-security"] - name: System tags: ["server-windows01-system"] output.kafka: hosts: ["10.0.0.60:9092"] topics: - topic: "server-windows01-application" when.contains: tags: "server-windows01-application" - topic: "server-windows01-security" when.contains: tags: "server-windows01-security" - topic: "server-windows01-system" when.contains: tags: "server-windows01-system" codec.format: string: '%{[@timestamp]} %{[message]}|%{[event]}|%{[log]}|%{[winlog]}' partition.round_robin: reachable_only: false required_acks: 1 compression: gzip max_message_bytes: 1000000 logging.level: info logging.to_files: true logging.files: path: C:\winlogbeat name: winlogbeat.log keepfiles: 7
4.4.2. Процесс обработки данных в Logstash
Пример конфигурации Logstash модуля input:
«/opt/logstash/config/conf.d/server-windows01-input.conf»
input { kafka { type => "server-windows01-application" bootstrap_servers => "10.0.0.60:9092" topics => "server-windows01-application" } kafka { type => "server-windows01-security" bootstrap_servers => "10.0.0.60:9092" topics => "server-windows01-security" } kafka { type => "server-windows01-system" bootstrap_servers => "10.0.0.60:9092" topics => "server-windows01-system" } }
Во время обработки «application» из начала сообщения вырежем метку времени и добавим её в новое поле «timestamp_windows». Установим, что остальные поля разделены символом «|», в соответствии с конфигурацией Winlogbeat. Символ «|» необходимо экранировать символом «\».
Названия полей обозначим с таким же именем и в таком же порядке, как и в конфигурации Winlogbeat. Зная, что поле «event» находится в формате json распарсим его как json и поместим в то же поле. С полями «log» и «winlog» поступим аналогично. Так как время обработки сообщения в Winlogbeat находится в поле «event» в параметре «created», то создадим поле «timestamp_winlogbeat» и поместим туда значение из «event.created». После этого создадим поле «timestamp_logstash» с меткой времени обработки сообщения в Logstash.
Сообщения «security» и «system» обрабатываются аналогичным образом.
Пример конфигурации Logstash модуля filter:
«/opt/logstash/config/conf.d/server-windows01-filter.conf»
filter { if [type] == "server-windows01-application" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_windows} %{DATA:message}\|%{DATA:event}\|%{DATA:log}\|%{GREEDYDATA:winlog}" } overwrite => [ "message" ] } json { source => "event" target => "event" } json { source => "log" target => "log" } json { source => "winlog" target => "winlog" } mutate { add_field => { "timestamp_winlogbeat" => "%{[event][created]}" } add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } if [type] == "server-windows01-security" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_windows} %{DATA:message}\|%{DATA:event}\|%{DATA:log}\|%{GREEDYDATA:winlog}" } overwrite => [ "message" ] } json { source => "event" target => "event" } json { source => "log" target => "log" } json { source => "winlog" target => "winlog" } mutate { add_field => { "timestamp_winlogbeat" => "%{[event][created]}" } add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } if [type] == "server-windows01-system" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_windows} %{DATA:message}\|%{DATA:event}\|%{DATA:log}\|%{GREEDYDATA:winlog}" } overwrite => [ "message" ] } json { source => "event" target => "event" } json { source => "log" target => "log" } json { source => "winlog" target => "winlog" } mutate { add_field => { "timestamp_winlogbeat" => "%{[event][created]}" } add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } }
Пример конфигурации Logstash модуля output:
«/opt/logstash/config/conf.d/server-windows01-output.conf»
output { if [type] == "server-windows01-application" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-windows01-application-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } if [type] == "server-windows01-security" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-windows01-security-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } if [type] == "server-windows01-system" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-windows01-system-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } }
4.5. Сценарий сбора системных Логов Linux
4.5.1. Процесс сбора данных через Filebeat
Системные логи Linux будем собирать с помощью Filebeat. Конфигурирование Filebeat в Linux практически идентично конфигурированию Filebeat в Windows. За счет того, что при установке Filebeat на Linux мы включили модуль system, можно настроить только вывод данных, сменив его с elasticsearch на kafka, остальные настройки можно оставить по умолчанию и данные пойдут в формате json.
Поскольку системные логи Linux хранятся в одном файле «/var/log/syslog» (архивные не берем в расчет) и формат логов однострочный, то есть каждое сообщение хранится в отдельной строке, то в этой ситуации можно так же применить «Сценарий сбора однострочных данных в текстовом формате». Именно этот вариант я и представлю.
Пример конфигурации Filebeat:
«/etc/filebeat/filebeat.yml»
filebeat.inputs: - type: log enabled: true paths: - /var/log/syslog filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false setup.template.settings: index.number_of_shards: 1 setup.kibana: output.kafka: hosts: ["10.0.0.60:9092"] topic: "server-elk01-syslog" codec.format: string: '%{[@timestamp]} %{[message]}' partition.round_robin: reachable_only: false required_acks: 1 compression: gzip max_message_bytes: 1000000 close_inactive: 10m processors: - add_host_metadata: when.not.contains.tags: forwarded - add_cloud_metadata: ~ - add_docker_metadata: ~ - add_kubernetes_metadata: ~ logging.level: info logging.to_files: true logging.files: path: /var/log/filebeat name: filebeat.log keepfiles: 7
4.5.2. Процесс обработки данных в Logstash
Пример конфигурации Logstash модуля input:
«/opt/logstash/config/conf.d/server-elk01-input.conf»
input { kafka { type => "server-elk01-syslog" bootstrap_servers => "10.0.0.60:9092" topics => "server-elk01-syslog" } }
Пример конфигурации Logstash модуля filter:
«/opt/logstash/config/conf.d/server-elk01-filter.conf»
filter { if [type] == "server-elk01-syslog" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_filebeat} %{GREEDYDATA:message}" } overwrite => [ "message" ] } mutate { add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } }
Пример конфигурации Logstash модуля output:
«/opt/logstash/config/conf.d/server-elk01-output.conf»
output { if [type] == "server-elk01-syslog" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-elk01-syslog-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } }
5. Итоговые файлы конфигураций
С учетом всех сценариев у меня получились следующие файлы конфигураций.
Пример конфигурации Filebeat на Linux:
«/etc/filebeat/filebeat.yml»
filebeat.inputs: - type: log enabled: true paths: - /var/log/syslog filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false setup.template.settings: index.number_of_shards: 1 setup.kibana: output.kafka: hosts: ["10.0.0.60:9092"] topic: "server-elk01-syslog" codec.format: string: '%{[@timestamp]} %{[message]}' partition.round_robin: reachable_only: false required_acks: 1 compression: gzip max_message_bytes: 1000000 close_inactive: 10m processors: - add_host_metadata: when.not.contains.tags: forwarded - add_cloud_metadata: ~ - add_docker_metadata: ~ - add_kubernetes_metadata: ~ logging.level: info logging.to_files: true logging.files: path: /var/log/filebeat name: filebeat.log keepfiles: 7
Пример конфигурации Filebeat на Windows:
«C:\filebeat\filebeat.yml»
filebeat.inputs: - type: filestream paths: - C:\Temp\log\*.log tags: ["simple-logs"] - type: log enabled: true paths: - C:\Temp\test_log_json2\* multiline.pattern: '^{' multiline.negate: true multiline.match: after processors: - decode_json_fields: fields: ["message"] target: "json" tags: ["test-json"] filebeat.modules: - module: iis access: enabled: true var.paths: ["C:/inetpub/logs/LogFiles/*/*.log"] error: enabled: true var.paths: ["C:/Windows/System32/LogFiles/HTTPERR/*.log"] filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false setup.template.settings: index.number_of_shards: 1 setup.kibana: processors: - add_host_metadata: when.not.contains.tags: forwarded - add_cloud_metadata: ~ - add_docker_metadata: ~ - add_kubernetes_metadata: ~ output.kafka: hosts: ["10.0.0.60:9092"] topics: - topic: "server-windows01-simple-logs" when.contains: tags: "simple-logs" - topic: "server-windows01-test-json" when.contains: tags: "test-json" - topic: "server-windows01-iis-access" when.contains: "@metadata.pipeline": "iis-access" - topic: "server-windows01-iis-error" when.contains: "@metadata.pipeline": "iis-error" codec.format: string: '%{[@timestamp]} %{[message]}' partition.round_robin: reachable_only: false required_acks: 1 compression: gzip max_message_bytes: 1000000 close_inactive: 10m
Пример конфигурации Winlogbeat:
«C:\winlogbeat\winlogbeat.yml»
winlogbeat.event_logs: - name: Application ignore_older: 72h tags: ["server-windows01-application"] - name: Security tags: ["server-windows01-security"] - name: System tags: ["server-windows01-system"] output.kafka: hosts: ["10.0.0.60:9092"] topics: - topic: "server-windows01-application" when.contains: tags: "server-windows01-application" - topic: "server-windows01-security" when.contains: tags: "server-windows01-security" - topic: "server-windows01-system" when.contains: tags: "server-windows01-system" codec.format: string: '%{[@timestamp]} %{[message]}|%{[event]}|%{[log]}|%{[winlog]}' partition.round_robin: reachable_only: false required_acks: 1 compression: gzip max_message_bytes: 1000000 logging.level: info logging.to_files: true logging.files: path: C:\winlogbeat name: winlogbeat.log keepfiles: 7
Пример конфигурации Logstash модуля input для сервера «server-elk01»:
«/opt/logstash/config/conf.d/server-elk01-input.conf»
input { kafka { type => "server-elk01-syslog" bootstrap_servers => "10.0.0.60:9092" topics => "server-elk01-syslog" } }
Пример конфигурации Logstash модуля filter для сервера «server-elk01»:
«/opt/logstash/config/conf.d/server-elk01-filter.conf»
filter { if [type] == "server-elk01-syslog" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_filebeat} %{GREEDYDATA:message}" } overwrite => [ "message" ] } mutate { add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } }
Пример конфигурации Logstash модуля output для сервера «server-elk01»:
«/opt/logstash/config/conf.d/server-elk01-output.conf»
output { if [type] == "server-elk01-syslog" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-elk01-syslog-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } }
Пример конфигурации Logstash модуля input для сервера «server-windows01»:
«/opt/logstash/config/conf.d/server-windows01-input.conf»
input { kafka { type => "server-windows01-simple-logs" bootstrap_servers => "10.0.0.60:9092" topics => "server-windows01-simple-logs" } kafka { type => "server-windows01-test-json" bootstrap_servers => "10.0.0.60:9092" topics => "server-windows01-test-json" } kafka { type => "server-windows01-application" bootstrap_servers => "10.0.0.60:9092" topics => "server-windows01-application" } kafka { type => "server-windows01-security" bootstrap_servers => "10.0.0.60:9092" topics => "server-windows01-security" } kafka { type => "server-windows01-system" bootstrap_servers => "10.0.0.60:9092" topics => "server-windows01-system" } kafka { type => "server-windows01-iis-access" bootstrap_servers => "10.0.0.60:9092" topics => "server-windows01-iis-access" } kafka { type => "server-windows01-iis-error" bootstrap_servers => "10.0.0.60:9092" topics => "server-windows01-iis-error" } }
Пример конфигурации Logstash модуля filter для сервера «server-windows01»:
«/opt/logstash/config/conf.d/server-windows01-filter.conf»
filter { if [type] == "server-windows01-simple-logs" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_filebeat} %{GREEDYDATA:message}" } overwrite => [ "message" ] } mutate { add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } if [type] == "server-windows01-test-json" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_filebeat} %{GREEDYDATA:message}" } overwrite => [ "message" ] } json { source => "message" } mutate { add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } if [type] == "server-windows01-application" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_windows} %{DATA:message}\|%{DATA:event}\|%{DATA:log}\|%{GREEDYDATA:winlog}" } overwrite => [ "message" ] } json { source => "event" target => "event" } json { source => "log" target => "log" } json { source => "winlog" target => "winlog" } mutate { add_field => { "timestamp_winlogbeat" => "%{[event][created]}" } add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } if [type] == "server-windows01-security" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_windows} %{DATA:message}\|%{DATA:event}\|%{DATA:log}\|%{GREEDYDATA:winlog}" } overwrite => [ "message" ] } json { source => "event" target => "event" } json { source => "log" target => "log" } json { source => "winlog" target => "winlog" } mutate { add_field => { "timestamp_winlogbeat" => "%{[event][created]}" } add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } if [type] == "server-windows01-system" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_windows} %{DATA:message}\|%{DATA:event}\|%{DATA:log}\|%{GREEDYDATA:winlog}" } overwrite => [ "message" ] } json { source => "event" target => "event" } json { source => "log" target => "log" } json { source => "winlog" target => "winlog" } mutate { add_field => { "timestamp_winlogbeat" => "%{[event][created]}" } add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } if [type] == "server-windows01-iis-access" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_filebeat} %{GREEDYDATA:message}" } overwrite => [ "message" ] } grok { match => [ "message", "%{TIMESTAMP_ISO8601:timestamp_windows} %{GREEDYDATA:message}" ] overwrite => [ "message" ] } date { match => ["timestamp_windows", "ISO8601", "YYYY-MM-dd HH:mm:ss", "MMM dd, YYYY @ HH:mm:ss.ZZZ"] target => "timestamp_windows" locale => "en" } mutate { add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } if [type] == "server-windows01-iis-error" { grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp_filebeat} %{GREEDYDATA:message}" } overwrite => [ "message" ] } grok { match => [ "message", "%{TIMESTAMP_ISO8601:timestamp_windows} %{GREEDYDATA:message}" ] overwrite => [ "message" ] } date { match => ["timestamp_windows", "ISO8601", "YYYY-MM-dd HH:mm:ss", "MMM dd, YYYY @ HH:mm:ss.ZZZ"] target => "timestamp_windows" locale => "en" } mutate { add_field => { "timestamp_logstash" => "%{[@timestamp]}" } } } }
Пример конфигурации Logstash модуля output для сервера «server-windows01»:
«/opt/logstash/config/conf.d/server-windows01-output.conf»
output { if [type] == "server-windows01-simple-logs" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-windows01-simple-logs-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } if [type] == "server-windows01-test-json" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-windows01-test-json-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } if [type] == "server-windows01-application" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-windows01-application-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } if [type] == "server-windows01-security" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-windows01-security-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } if [type] == "server-windows01-system" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-windows01-system-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } if [type] == "server-windows01-iis-access" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-windows01-iis-access-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } if [type] == "server-windows01-iis-error" { opensearch { hosts => "https://localhost:9200" user => "admin" password => "yN-3L(GMmAAw" index => "kafka-server-windows01-iis-error-%{+YYYY.MM.dd}" ssl_certificate_verification => false } } }
6. Эксплуатация
Следующие шаги я разберу на примере сбора данных в формате json.
6.1. Создание шаблона индексов с помощью OpenSearch-Dashboards
Шаблон индексов позволяет просматривать сообщения одного или нескольких индексов сортируя их по дате. В качестве даты может выступать любое поле в формате «дата». Для того чтобы можно было осуществлять поиск с помощью OpenSearch-Dashboards необходимо создать шаблон индексов. Для этого перейдем в раздел «Stack Management», далее в раздел «Index Pattern» и нажмем кнопку «Create index pattern» (Рис.2).
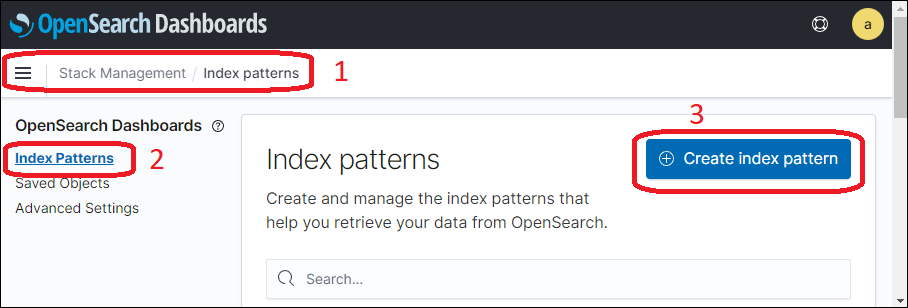
Рис.2
Создадим шаблон индексов для данных из Topic'а Kafka без учета даты. Для этого введем в строке имени шаблона название индекса, но в конце, вместо даты введем символ «*» (Рис.3).
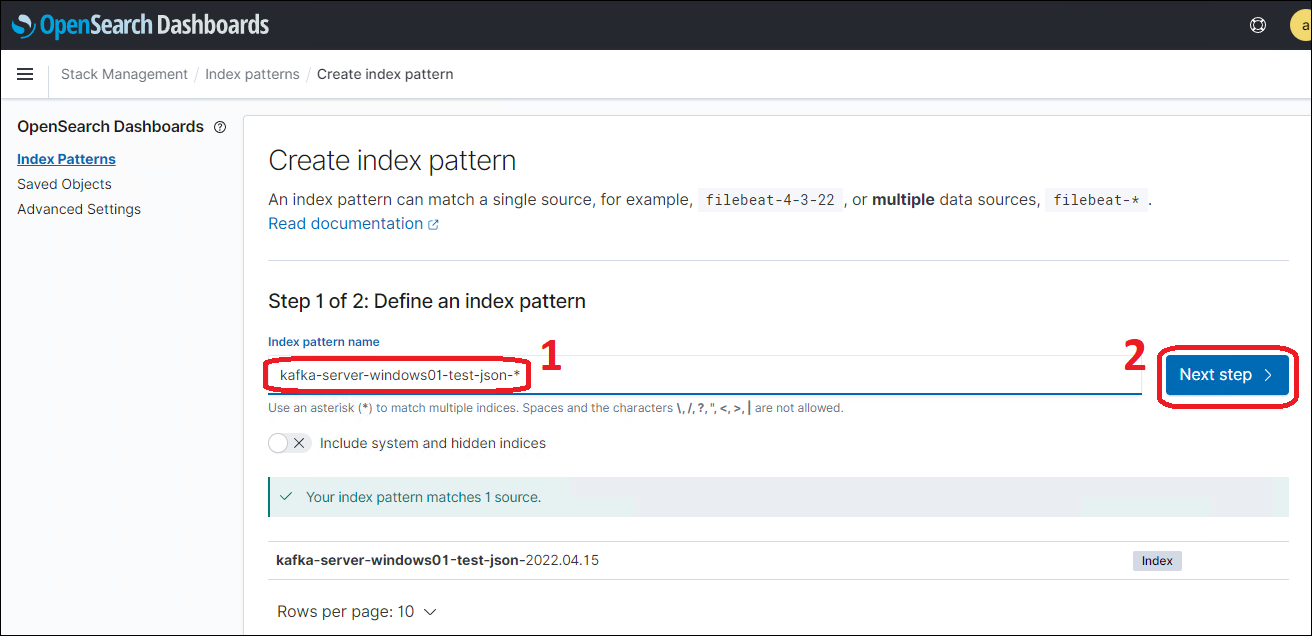
Рис.3
Параметром сортировки данных в шаблоне выберем «@timestamp», он совпадает с «timestamp_logstash» (Рис.4).

Рис.4
6.2. Отображение данных в OpenSearch-Dashboards
При переходе в раздел «Discover» в соответствующий шаблон индексов там отобразятся доступные сообщения. Можно раскрыть подробное содержание сообщения и увидеть, что все заголовки ключей json-сообщения стали одноименными полями, а значения ключей перешли в значения полей. Так же осталось поле «message», которое содержит изначальное json-сообщение (Рис.5). На этапе фильтрации сообщения в Logstash это поле («message») можно удалять, если в нем нет необходимости.
Если в json-сообщении содержится поле «message», то оригинальное поле «message», которое содержит изначальное json-сообщение, будет перезаписано на поле из json-сообщения.
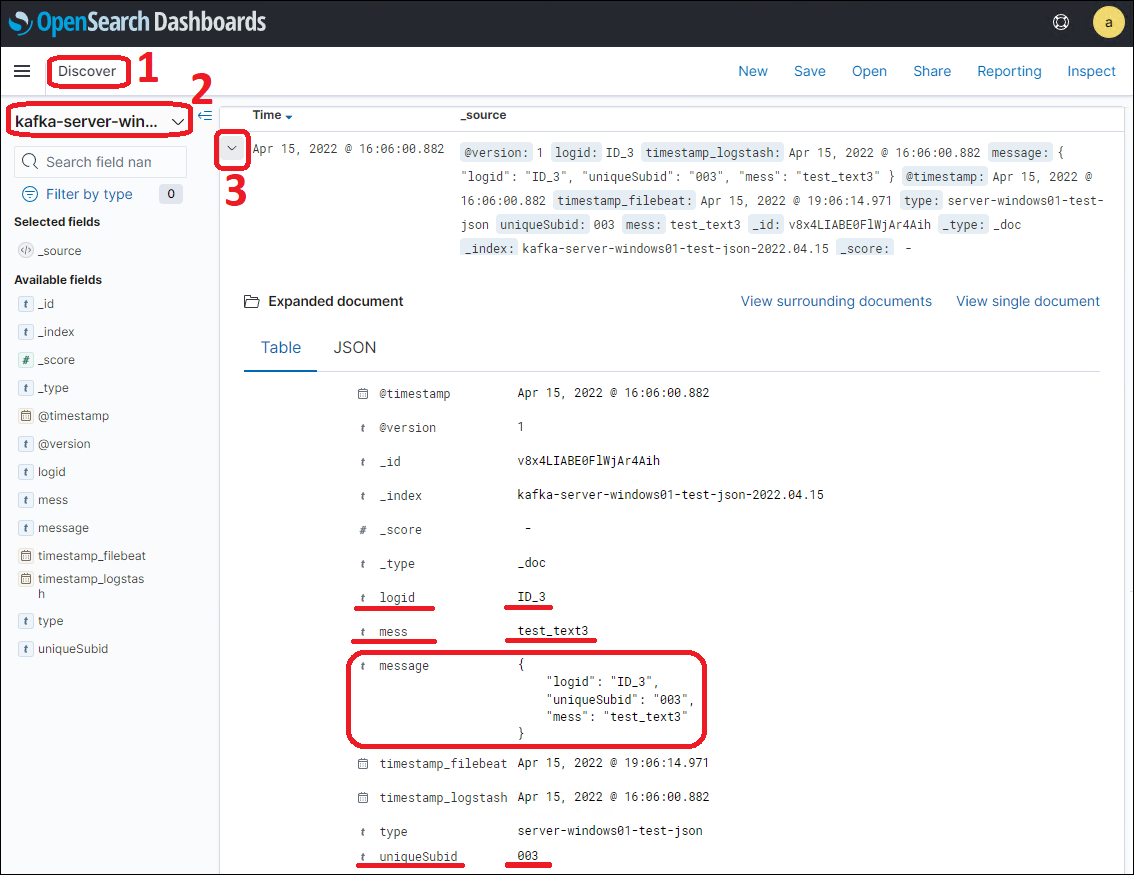
Рис.5
6.3. Поиск в OpenSearch-Dashboards
Я рассмотрю совсем немного вариантов поиска, исключительно с целью обзора. Поиск будет только в формате «DQL» (формат по умолчанию).
Поиск осуществляется в разделе «Discover» в соответствующем шаблоне индексов.
1. Для поиска по всем доступным сообщениям во всех полях достаточно ввести нужную фразу в строке поиска (Рис.6).
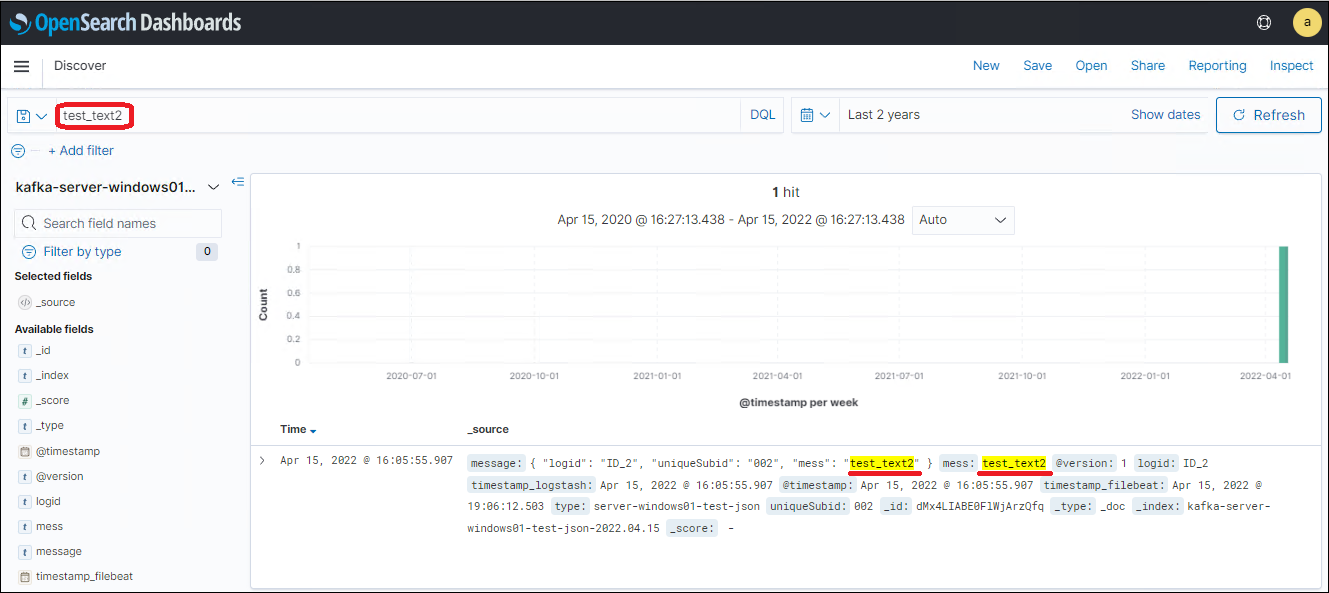
Рис.6
2. Для поиска фраз по определенным полям в поисковой строке указывается имя нужного поля, затем, в качестве разделителя, идет символ двоеточия «:» и затем искомая фраза. Искомая фраза может содержать специальные символы «*», «?» и т.д. для формирования шаблона (Рис.7).
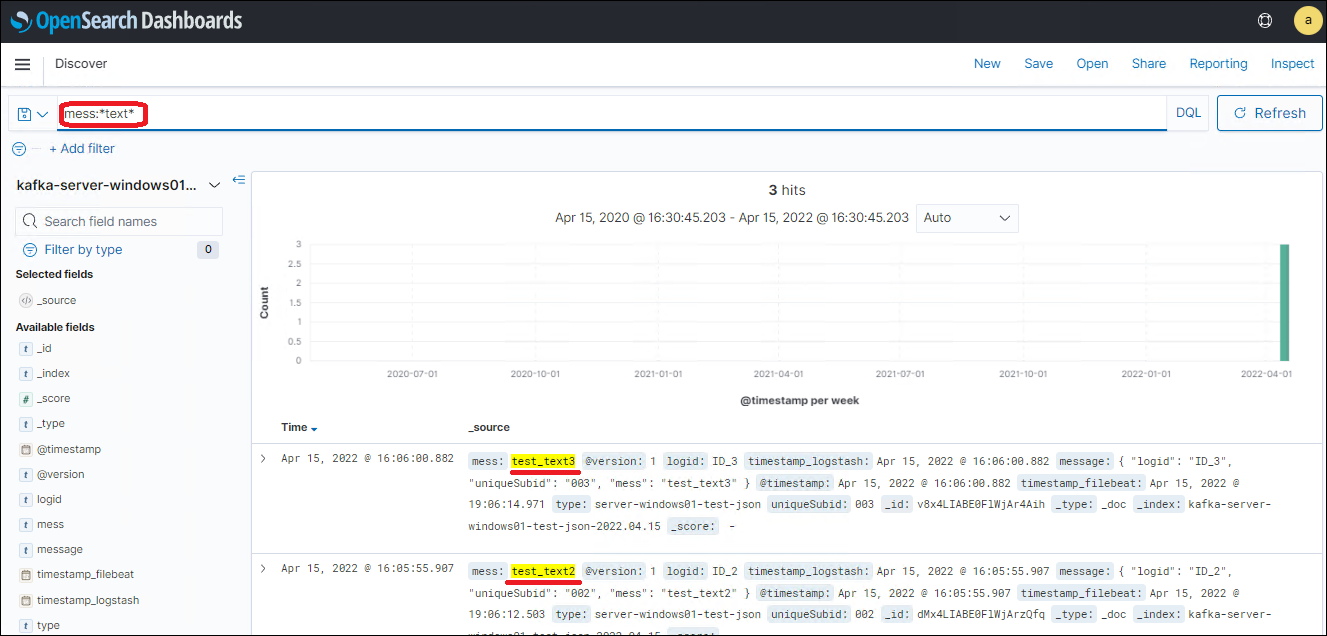
Рис.7
3. В поисковом запросе можно применять логические операции «or», «and», «not» (Рис.8).

Рис.8
6.4. Работа с OpenSearch через консоль (без OpenSearch-Dashboards)
Я приведу не большой список запросов для того, чтобы показать, как выглядит работа из консоли.
Запросить список индексов:
curl 'https://10.0.0.70:9200/_cat/indices?v&pretty' -u 'admin:yN-3L(GMmAAw' –insecure
Запросить структуру индекса:
curl 'https://10.0.0.70:9200/kafka-server-windows01-test-json-2022.03.30/_mapping?pretty' -u 'admin:yN-3L(GMmAAw' --insecure
Удалить индекс:
curl -XDELETE 'https://10.0.0.70:9200/kafka-server-windows01-test-json-2022.03.30?pretty' -u 'admin:yN-3L(GMmAAw' –insecure
Вывести первые 10 сообщений из индекса (10 по умолчанию):
curl -XGET 'https://10.0.0.70:9200/kafka-server-windows01-test-json-2022.03.30/_search?pretty' -u 'admin:yN-3L(GMmAAw' --insecure
Вывести первые 20 сообщений из индекса:
curl -XGET 'https://10.0.0.70:9200/kafka-server-windows01-test-json-2022.03.30/_search?size=20&pretty' -u 'admin:yN-3L(GMmAAw' --insecure
Вывести первые 20 сообщений из шаблона индексов:
curl -XGET 'https://10.0.0.70:9200/kafka-server-windows01-test-json-*/_search?size=20&pretty' -u 'admin:yN-3L(GMmAAw' --insecure
Осуществить поиск в индексе по запросу «*text*» через параметр «q»:
curl -XGET 'https://10.0.0.70:9200/kafka-server-windows01-test-json-2022.03.30/_search?q=*text*&pretty' -u 'admin:yN-3L(GMmAAw' --insecure
Для поиска по составным запросам существуют несколько типов поиска:
term — точное совпадение искомой строки со строкой в индексе или термом;
match — все слова должны входить в строку, в любом порядке;
match_phrase — вся фраза должна входить в строку;
query_string — все слова входят в строку в любом порядке, можно искать по нескольким полям, используя регулярные выражения.
Осуществим поиск в индексе по полю «mess», искать будем точное совпадение фразы «test_text»:
curl -XGET 'https://10.0.0.70:9200/kafka-server-windows01-test-json-2022.03.30/_search?pretty ' -u 'admin:yN-3L(GMmAAw' --insecure -H 'Content-Type: application/json' -d '{"query" : {"term" : {"mess" : "test_text"}}}'
7. Актуальные проблемы
В этом разделе я опишу проблемы, с которыми я встретился.
7.1. Имена Topic’ов Kafka не должны содержать большие буквы
Logstash не может читать Topic'и Kafka, если они (Topic’и) содержат большие буквы. Поэтому имена Topic'ов Kafka не должны содержать большие буквы.
7.2. Filebeat некорректно создает Topic’и Kafka
При старте как Filebeat, так и Logstash создают Topic в Kafka, если в конфигурации соответствующего сервиса Topic имеется, а в Kafka он еще отсутствует. Но если Topic создает Filebeat, то Logstash не может читать этот топик. Если же Topic создает Logstash, то все сервисы могут читать этот Topic. Поэтому при создании/изменении конфигурации обеих служб сначала необходимо запустить Logstash и дождаться пока Topic в Kafka будет создан. И только после этого можно запускать Filebeat.
7.3. Требуется переход на следующую строку после json сообщения
При считывании сообщений из логов в формате json, после закрывающей фигурной скобки «}», которая закрывает json, в том случае, когда это последнее сообщение в файле, необходимо добавить переход на следующую строку. Иначе эта фигурная скобка «}» не попадет в обработку json и последнее json-сообщение в файле обрабатывается не корректно (не читается как json).
7.4. Необходимо обращать внимание на кодировку log-файлов
По умолчанию корректно обрабатываются log-файлы только в формате «UTF-8». Поэтому необходимо либо создавать log-файл в формате «UTF-8», либо явно указываться кодировку в Logstash и/или в Filebeat.
Например, я столкнулся с тем, что PowerShell по умолчанию формирует файлы в формате «UTF-16». Пришлось сменить кодировку по умолчанию в скрипте на «UTF-8»:
$PSDefaultParameterValues['*:Encoding'] = 'utf8'
8. Послесловие
Что мне хотелось бы добавить в эту статью, но по какой-то причине этого не произошло:
1. Настройка времени жизни индексов в OpenSearch;
2. Настройка Apache Kafka;
3. Настройка аутентификации Active Directory в OpenSearch-Dashboards по протоколу LDAP;
4. Создание визуализаций в OpenSearch-Dashboards;
5. Создание Dashboard’ов в OpenSearch-Dashboards.
На этом я заканчиваю. Всем спасибо за внимание к статье, надеюсь она окажется для кого-то полезной. И оставляйте ваши рецепты настройки OpenSearch в комментариях, думаю это так же будет интересно.

