Привет!
В этой статье я бы хотел поделиться с теми, кто использует Apache Zeppelin в сочетании со Spark на Scala, возможностями по визуализации полученных данных.

На нынешней работе я занимаюсь вопросами замера производительности конвеера данных, а эта работа включает в себя, как правило, следующие шаги:
найти каким образом померить время от получения данных на одном конце конвеера до другого конца;
визуализировать;
проанализировать, когда появляются задержки и с чем могут быть связаны.
Кроме того, иногда бывает необходимо разобраться с полнотой данных, нет ли в них пропусков, не снижается ли на некоторых временных участках плотность данных в единицу времени.
Данные у нас хранятся в базе временных рядов Timescale, а еще их обрабатывает Apache Spark (в нашей организации джобы написаны на Scala), поэтому некоторые промежуточные результаты вычислений хранятся и в Hadoop. Поверх всей этой инфраструктуры анализ данных удобно производить в Apache Zeppelin, ведь в нем можно применить те же навыки, которые используются и для написания джоб по обработке данных.
Однако, если делать выборки данных и подсчитывать промежуточные и окончательные значения для Scala-разработчиков не страшит, то вот с визуализацией, как оказалось, без использования Python и библиотеки Bokeh ничего в Zeppelin не получилось. Пришлось поразбираться в этом процессе, а заодно освоить новый для себя вид вузализации.
Итак, представьте, что мы при помощи привычного для Scala-разработчиков spark-интерпретатора Zeppelin получили некий датасет - вытащили данные из базы или из файлов Parquet в Hadoop, преобразовали его как хотим, например, избавились от ненужных колонок, или определили свои новые и пересчитали значения в них. Теперь наv нужно построить график зависимости содержимого, например, второй колонки, от первой колонки. Что нужно для этого сделать?
Для начала нужно датасет зарегистрировать как таблицу, доступную не только из текущего интерпретатора. Для этого завершим преобразования примерно так:
ourDataframe.show(100, false) //в веб-интерфейс цепеллина будет выведено первые 100 строчек println(ourDataframe.count()) //а еще общее количество данных в датасете ourDataframe.registerTempTable("tableexample") //зарегистрировали таблицу, к которой обратимся в другом интерпретаторе
Итак, какой простейший способ визуализации? Это интерпретатор %sql, который позволяет сделать запрос к зарегистрированной в контексте "цепеллина" таблице. Например:
%sql select hour, max from tableexample
При отработке запроса, будет построена визуализация:

Минус ее в том, что очень большое количество точек не позволит строить ее на очень больших выборках. Для этого попробуем построить обычный двумерный график при помощи библиотеки Bokeh.
Предварительно, она должна быть установлена на машину (или в контейнер) с Zeppelin.
RUN pip install -q numpy==1.17.3
RUN pip install -q pandas==0.25.0
RUN pip3 install -q bokeh==2.4.2
RUN pip3 install -q bkzep
Вот так у нас при формировании образа ставится всё питоновское (помимо остального, необходимого для трансформации данных в pyspark и т.п.), что понадобится нам именно для визуализации.
Итак, для начала нам нужно инициализировать все объекты, которые нам потребуются в отдельных "главах" Zeppelin для работы с разными датасетами и графиками. Создаем "главу" с интерпретатором %spark.pyspark
%spark.pyspark import bkzep import numpy as np from bokeh.io import output_notebook, show from bokeh.plotting import figure from bokeh.models import ColumnDataSource from bokeh.layouts import gridplot from pyspark.sql.functions import col, coalesce, lit, monotonically_increasing_id from pyspark.sql import DataFrame from pyspark.sql.functions import * output_notebook(notebook_type='zeppelin')
Если запустить ее, то появится значок загрузки библиотеки BokehJS, значит все идет как надо:

Теперь можно непосредственно приступать к созданию "глав", в которых код на питоне займется прорисовкой нужной нам визуализации из сохраненных в контекст "цепеллина" таблиц, в примере ниже - таблица "pivoted".
%pyspark from pyspark.sql.functions import * def plot_summaries(sensor, dfName): df = sqlContext.table(dfName) #определили таблицу PySpark обратно из контекста Zeppeling pdf = df.toPandas() #преобразовали в dataFrame Pandas source = ColumnDataSource(pdf) #преобразовали в объект-источник для колонок с данными fig = figure(title="Mean and Standard deviation of '{}'".format(sensor)) #задали объект графика, тут же параметризованный заголовок fig.line(x='index', y=sensor+'_mean', source=source, color="orange") fig.line(x='index', y=sensor+'_stddev', source=source, color="blue") show(gridplot([fig], ncols=1, plot_width=1000, plot_height=400)) #добавили линий и отправили на отрисовку sensors = [ "Water_Level_Sensor", "Water_Temperature_Sensor", ] for sensor in sensors: plot_summaries(sensor, "pivoted")
И получили такие вот простенькие графики со средним значением и среднеквардратичным отклонением, которые мы посчитали еще до визуализации в "спарке" и уложили в таблицу "pivoted", как и колонку index:
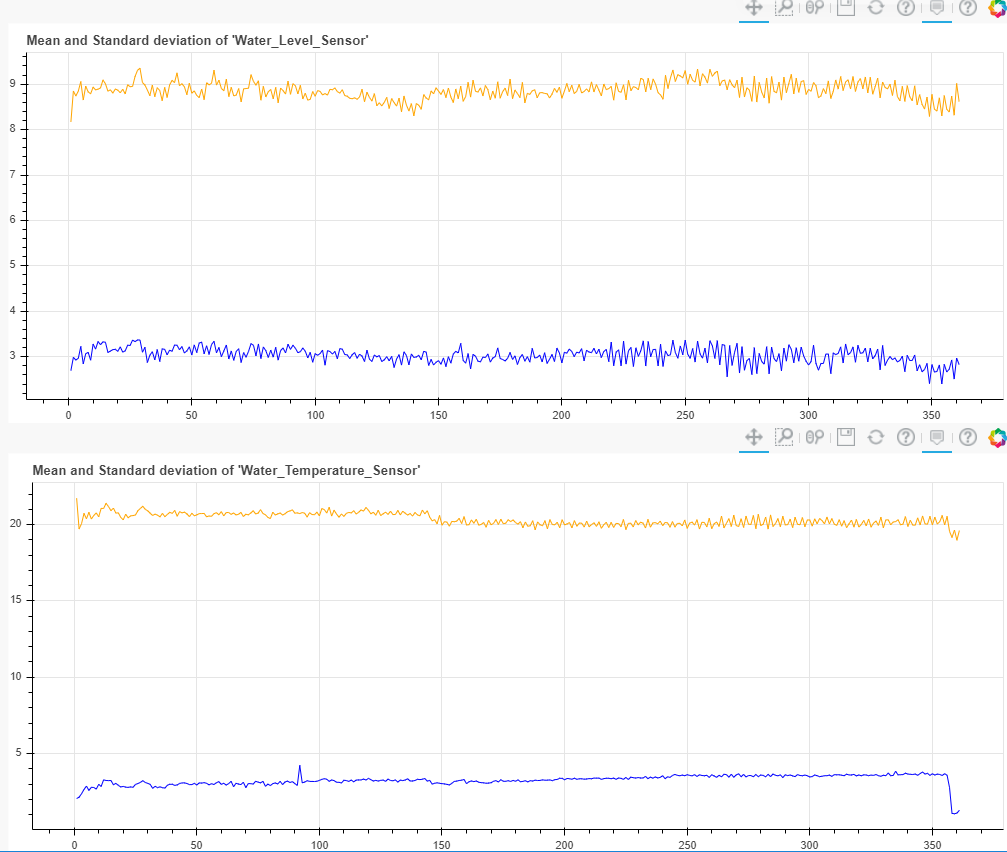
Когда речь идет о значениях телеметрии, то, казалось бы, можно и правда обойтись четырьмя линиями - построив значения среднего, минимального, максимального и среднеквадратичного на временном окне. Но куда нагляднее будет график, на котором это распределение можно явно увидеть самим. Сделать окна не только по оси x (временные), но и по оси y (значения), посчитать сколько значений от общего количества попало в "окна" по вертикали, а потом построить на плоскости 3х-мерный массив, где точка с координатами x и y будет иметь цвет в зависимости от количества попавшего в "ведро" (ограниченного конкретным "окном" по x и y). Так получится тепловая карта, которая позволит видеть и анализировать как процессы распределения во времени, так и распределения значений изменяющегося во времени параметра. Например, сколько значений легло вдоль "центра распределений", а сколько ушло в "выбросы", при этом будет четко понятно, если "выбросы" происходят не равномерно, а по какому-то временному закону, например с регулярым повторением во времени. Это позволит предположить причину таких событий.
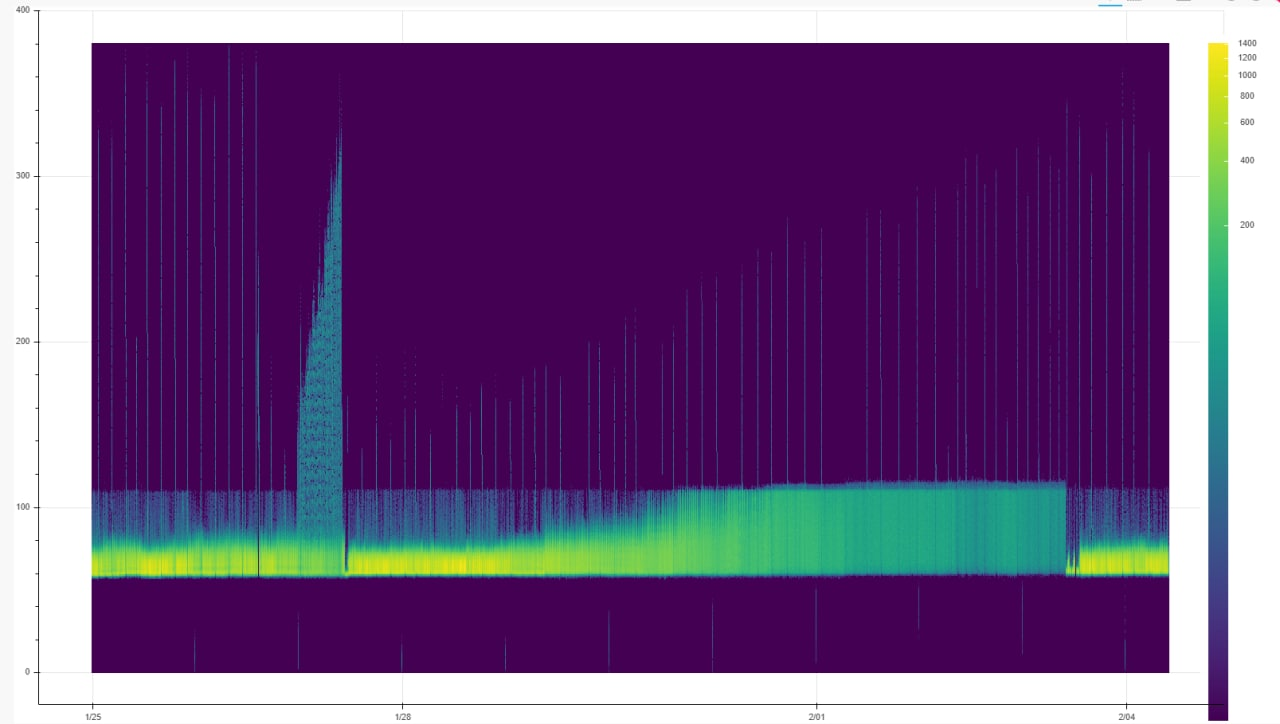
Например, на этой тепловой карте мы видим, что время обработки сообщений в конвеере по каким-то причинам не попадало в целый диапазон промежуточных значений, концентрируясь или около более малых или около более больших значений (это видно из темной области от 150 до 400 по оси y). Графики максимума, минимума, среднего и среднеквадратичного отклонения не смогли бы донести до нас эту информацию. Плюс видно, что в определенный момент времени количество сообщений, доставленных за определенное время, резко уменьшалось для всех времен задержки.

А на этой тепловой карте видно, что основная масса сообщений обрабатывается в пределах какого-то верхнего лимита по времени, но:
распределение внутри лимита в начале работы более неравномерное, со временем происходит перераспределение и общее число обработанных сообщений явно падает, система деградирует, вплоть до ее рестарта;
есть регулярные выбросы-задержки существенно больше этого лимита, что видно как "забор из жердей", торчащих выше этого лимита;
и что была какая-то аномалия, когда это были не регулярные единичные выбросы, а почти все сообщения вдруг получили задержку в обработке.
Интересно, как же построить такую карту?
Для этого вам придется на этапе подготовки датасета в Spark заготовить 2 колонки (например, время суток, таймстемп, и время отклика/обработки сообщения в миллисекундах), которые будут содержать значения (или кортежи начала и конца значений "окна"), а третья, по которой будет делаться визуализация, будет построена как количество событий, попавших в конкретное окно по обоим колонкам. В API Spark за такую группировку отвечают методы.. groupBy() и window(). Посмотрим на Scala код примера:
import org.apache.spark.sql.expressions.Window import org.apache.spark.sql.types.TimestampType def getDFFromJdbcSource(spark: SparkSession, query: String): DataFrame = { val timescaledbLogin = "postgres" val timescaledbPassword = "password" val timescaledbJdbc = s"jdbc:postgresql://timescaledb:5432/db" //подключение к БД spark .read .format("jdbc") .option("url", timescaledbJdbc) .option("driver", "org.postgresql.Driver") .option("user", timescaledbLogin) .option("password", timescaledbPassword) .option("query", query) .option("fetchsize", "2000000") .load() } import spark.sqlContext.implicits._ import org.apache.spark.sql.functions._ import org.apache.spark.sql.types._ val ourDataframe = getDFFromJdbcSource(SparkSession.builder().appName("test").master("local").getOrCreate(), s"""SELECT * FROM sensor_data WHERE (timestamp > '2022-02-09 00:00:00.000' and timestamp < '2022-02-11 00:00:00.000')""") //тут вручную задали диапазон по времени .withColumn("DelayColumn", (col("acceptTimestamp")).cast(LongType).divide(1000) - to_timestamp(date_format(col("timestamp"), "HH:mm:ss.SSS")).cast(LongType).divide(1000)) // получили время задержки вычитанием одного таймстемпа из другого // плюс приводим к подходящи для попадания в "окна" по оси y единицам // иногда для такого надо округлять, но здесь повезло .groupBy( window("window_time".desc) //для визуализации текстом еще и отсортировали по времени ourDataframe. show(100, false) println(dailySummariesDf.count()) ourDataframe.registerTempTable("heatmap")
Вывод текстом примерно будет такой:
+-------------------+--------------------+-----+ |window_time |DelayColumn |count| +-------------------+--------------------+-----+ |2022-02-10 18:50:00|1.6428744912879999E9|1 | |2022-02-10 18:50:00|1.642874507993E9 |2 |
Вот содержимое count-то мы и будем переводить в цвет. Итак, внизу манипуляции над датасетом в %pyspark интерпретаторе, необходимые для этого.
%pyspark from pyspark.sql.functions import * def plot_summaries(sensor, dfName): dft = sqlContext.table(dfName) pdf = dft.toPandas() import pandas as pd import numpy as np from bokeh.transform import log_cmap #преобразование значений в цвет по логарифмической шкале A = pdf.pivot_table('count', sensor, 'window_time', fill_value=0) #вот важнейшее действие! #без явного проброса значений колонки count по колонкам window_time и визуализируемому показателя #через функцию pivot_table() нужный трехмерный массив не сформируется source = ColumnDataSource(data={'x':[pdf['window_time'].min()] #самое лево ,'y':[0] #самый низ ,'dw':[pdf['window_time'].max()-pdf['window_time'].min()] #ширина изображения ,'dh':[pdf[sensor].max()] #высота изображения, #считается проще, так как минимум 0 ,'im':[A.to_numpy()] #теперь нужно сделать 2D массив numpy через to_numpy() }) color_mapper = LogColorMapper(palette="Viridis256", low=0, high=pdf['count'].max()) #именно тут задается цветовая шкала а-ля "северное сияние" plot = figure(toolbar_location=None,x_axis_type='datetime') #зададим тип оси х как временной plot.image(x='x', y='y', source=source, image='im',dw='dw',dh='dh', color_mapper=color_mapper) #само построение color_bar = ColorBar(color_mapper=color_mapper, label_standoff=12) #легенда для цветовой шкалы и ее размещение plot.add_layout(color_bar, 'right') show(gridplot([plot], ncols=1, plot_width=1600, plot_height=900)) #строим все вместе, задав размеры sensors = [ "DelayColumn"] for sensor in sensors: plot_summaries_heatmap(sensor, "heatmap") #вызов функции

Ну а дальше, дальше понадобится мастерство интерпретации. Такой вот "линейчатый спектр", например, харатерен для равновесных процессов, когда несколько потоков источника данных оказывются в равновесном состоянии с несколькими потоками потребителя данных, и распределение начинает меняться, "дрейфовать" когда производительность системы деградирует. К умению понять и интерпретировать следует развить и умение объяснить увиденное нетехническим и нематематическим руководителям, а именно, почему, глядя на эти картинки, вы видите проблему. По моему опыту, это было даже сложнее, чем построить и проанализировать такой график :)

