Добрый день, меня зовут Евгений Кузаков.
В силу рода деятельности (я руководитель DevOps-практики) периодически встают задачи сайзинга оборудования для новых кластеров Заказчиков.
Обычно разработка начинается на кластерах разработки в недрах компании.
Все выкатки, естественно, происходят с ограничением ресурсов по ядрам и оперативной памяти. Это необходимо делать всегда - как для некритичных кластеров, так и продуктивных.
В противном случае будут наблюдаться как минимум следующие проблемы:
будет некорректно работать kube-scheduler (очень сложно выбрать ноду для pod, который неизвестно сколько ресурсов потребует)
с учётом того, что на нодах нет swap, а у pod отсутствуют ограничения, то ноды кластера могут просто повисать раньше, чем сработает OOM
Но это я немного отвлёкся.
Когда работа комплекта микросервисов проекта более менее стабилизируется, пройдёт нагрузочное тестирование, оптимизируются resource limits/requests на стадии нагрузочного тестирвоания, limits/requests станут в равными (для продуктива burstable в большинстве случаев не применим), то можно подходить сайзингу серверов.
На просторах интернета я не нашёл более менее готового инструмента, который ответит на простой вопрос - а сколько ядер/памяти потребуется на рабочих нодах?
Вот и пришлось пару часов потренировать клавиатуру.
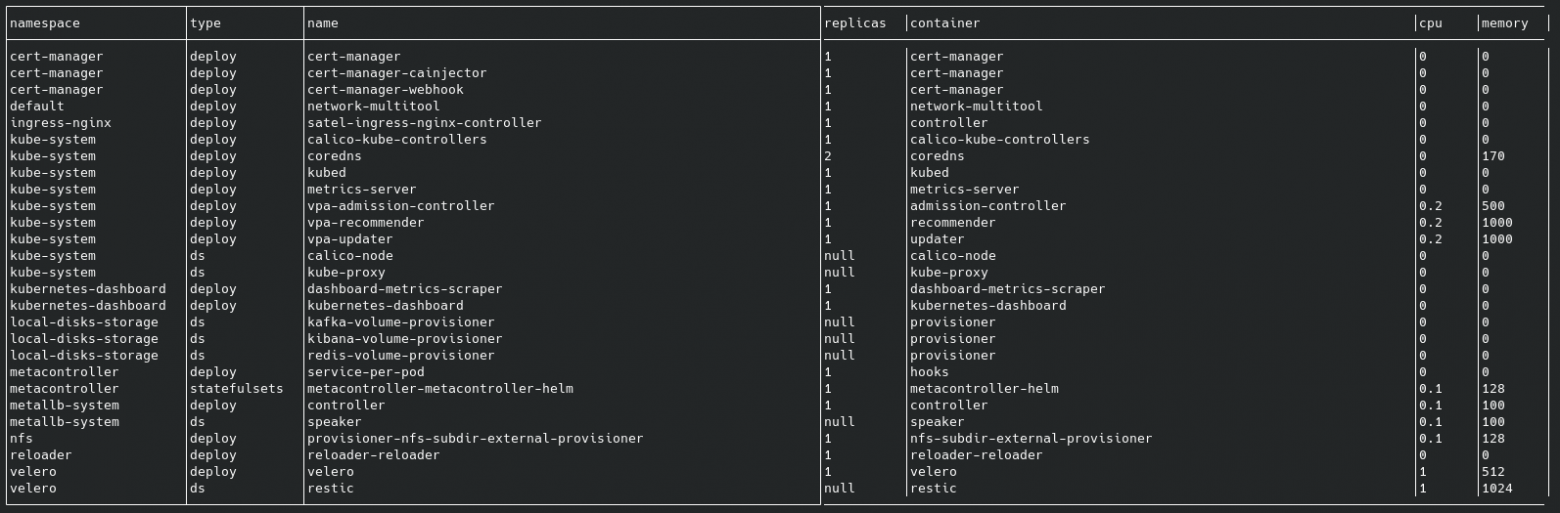
Скрипт позволяет визуализировать фактические limits, за одно проконтролировать - вдруг где-то не установлены лимиты.
Пример работы скрипта:
Инсталляция и запуск тривиальные:
git clone --recurse-submodules
./kube-limits-cals.sh
Огромное спасибо автору prettytable (https://github.com/jakobwesthoff/prettytable.sh)
Комментарии:
Скрипт совершенно безопасен. Он в текущем кластерном контексте запускает kubectl get ns/deploy/sts/etc
При запуске ключом --tabbed вместо красивой таблицы выведутся данные с разделителями, которые удобно вставлять в Excel/LibreOffice.
Если коммунити поддержит, то не сложно будет добавить как минимум следующий функционал:
уменьшение количества запусков kubectl (перенести больше логики в части парсинга JSON)
Ключ -n namespace
Указание кластерного контекста
Сделать поддержку kube-state-metrics
Запрашивать исторические данные у Prometheus

