
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Всё здорово, спасибо, но что делать-то тем, у кого память как у дрозофилы?
у меня Obsidian. Для каких-то частых кейсов.
Оффлайн документация в одном месте - реально круто, потому что я часто летаю, мне пригодится :)
Obsidian это интересно, но как туда подтянуть документацию автоматически? Я тоже использую его, поделитесь?
Obsidian крут, но для записок сумасшедшего, которые ты сам ведёшь, например какие-то логи по отдельным задачам. Но что делать-то тем, у кого память как у дрозофилы? И проблемы с концентрацией... особенно последние 2.5 года... даже при том, что большинство отвлекающих ресурсов в /etc/hosts уже прописаны как 127.0.0.1. И нужно постоянно учить что-то новое или оставлять заметки на полях, желательно так, чтобы не продолбать их в файлопомойке которой десятки лет.
К тому же нужно мордовать настройки по умолчанию, иначе сторонний софт немножечко обломается об ссылки и картинки. Я, например, конфигурил
Default location for new files: Same folder as current file
New link format: Relative path to file
Use [[Wikilinks]]: off - ввод [[ всё равно работает, он сам заменяет их на MD и сам дописывает relative path если он включен
Default location for new attachments: In subfolder under current folder
Subfolder name: плагин Custom Attachment Location переписывает на ./${filename}.files чтобы ресурсы можно было с MD переносить куда угодно из FM
Теперь можно вести какие-то записи в приемлемом формате просто через Ctrl+O project/date_issue
Можно завести template для выставления таймстампа и в daily notes трекать, над чем ты начал работу, чтобы в конце месяца не взрывать себе мозг вопросом "как затрекать то, что прошло мимо git".
Отчёт по git прописать в .gitconfig можно, например, так
[pretty]
time = %C(auto,brightyellow)%ad%C(auto,reset)\t%w(0,0,24)%s
[alias]
report = "!me=$(git config user.email); git log --all --since=1 --author-date-order --reverse --no-merges --pretty=time --date=format:'%Y-%m-%d %H:%M:%S' --author=\"$me\""остальное брать из obsidian, номер таски оформлять как ссылку, ссылку [[issue_num]] обсидиан заменяет на полный путь (включая поддиректории)
В поддиректории я в таску накидываю: заголовок таски, номер в трекере (оформлен как ссылка на трекер), основной мессадж и, если нужно, картинки. Затем по ходу работы дописываю всё что пришлось ковырять (куски логов, SQL-запросы, бекап записей БД перед их изменением, скрины и даже REST-запросы ...). Получается по каждой задаче директория в которой есть основной файл с контекстом и его ресурсы.
Так же по мере работы я могу этот Markdown открыть в DataGrip/Rider/VSCode и он заиграет вообще новыми красками, потому что DataGrip умеет выполнять запросы прямо из вставок в MD-файл, получается своеобразный аналог Jupyter Book, когда у тебя есть история, примеры кода и сразу же можно его выполнить. Цветастые логи подсвечивающие ошибки и ворнинги (ideolog), HTTP Client (для VSCode лучше httpyac) для REST/GraphQL. Вообще у VSCode вроде есть Foam как "аналог" Obsidian, но я не добрался посмотреть.
С учётом того, что у инструментов JetBrains тоже прослеживается стиль "Нажмите хоткей и получите быстрый поиск по всему", выглядит сильно похоже. Нужно посмотреть, какие там у JB есть интеграции с Dash, Velocity or Zeal. Но это про внешние какие-то хорошо задокументированные штуки, а не про внутренние проекты, к которым документации почти нет, либо она размазана по всяким упоротым конфлюенсам, либо протухла. И всё ещё непонятно как тут прикрутить всякий swagger.
Ну и хочется, конечно, чтобы у JB был более фичастый Markdown и пока не все плагины поддерживают раскрашивание синтаксиса в превью, но, думаю, с ростом сложности всего этого айтизоопарка это будут вынуждены пофиксить.
Спасибо за советы! Использую обсидиан, казалось бы, простые советы по настройкам, но очень помогли!
Всегда пожалуйста. Обсидианом я пользуюсь сравнительно недавно, ещё пробую покрутить и плагины. Интеграция с Jira, например, пока глючновата, но фиксят очень быстро. Вообще с плагинами там всё сильно лучше, чем с самим обсидианом, у которого ответят может и быстро, но менять "дефолты" на чуть более человеческие и менее деструктивные (с точки зрения классического Markdown, чтобы файлы мог процессить любой софт и не спотыкался об wikilinks, ссылки без путей...) как-то не спешат. Опять же, в отличие от Foam разработка у обсидиана закрыта.
По сабжу, я попробовал потыкать интеграцию в JB, разумеется сразу пролетел мимо Dash (т.к. у меня никсы и Windows), поставил Zeal и Velocity. Выяснилось что плагин нифига не интегрирует, а просто по хоткею запускает одну из программ. Так себе интеграция. Наборы документации примерно одинаковы. Но локально Zeal документацию как-то распаковывает, в итоге у него файлов в хранилище больше и весит всё примерно вдвое больше. Но зато шевелится чуть получше, открытый и не падал при скачивании документации. Кажется из Docsets всё-таки Zeal (для себя) и DevDocs (который можно поднять как локально, так и как сайт) всё-таки лучший выбор. ЕСЛИ Docsets всё-таки вам понравится и вы вообще будете этим пользоваться. Потому что сейчас это выглядит как просто локальная помойка веб-фарша. У каждого автора свой стиль ведения документации, а поиск довольно топорный из-за чего некоторые темы всё же проще проще нагуглить, особенно если темы чуть сложнее вызова одной функции из API, нет единого стиля оформления, нельзя найденную функцию as is воткнуть обратно в IDE, нужно прям мышковозить... сам софт настраивается так себе и пока не очень понятно, как нормально с этим жить с клавиатуры
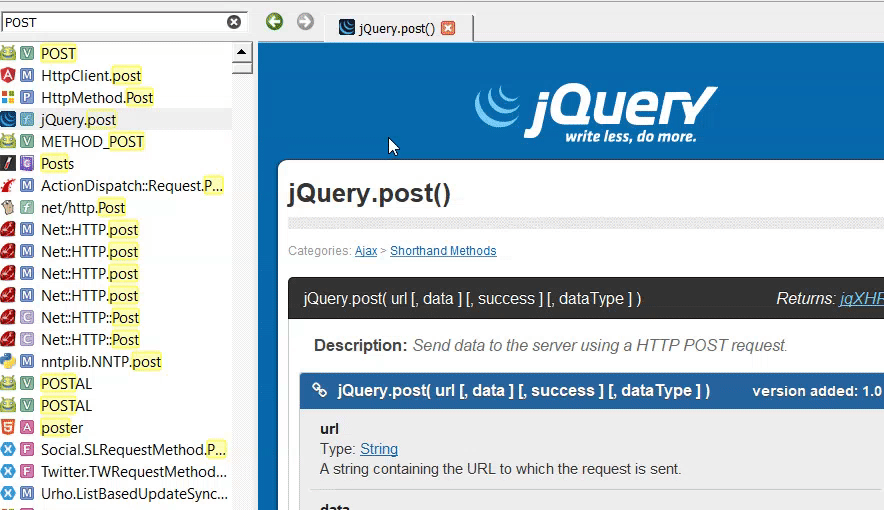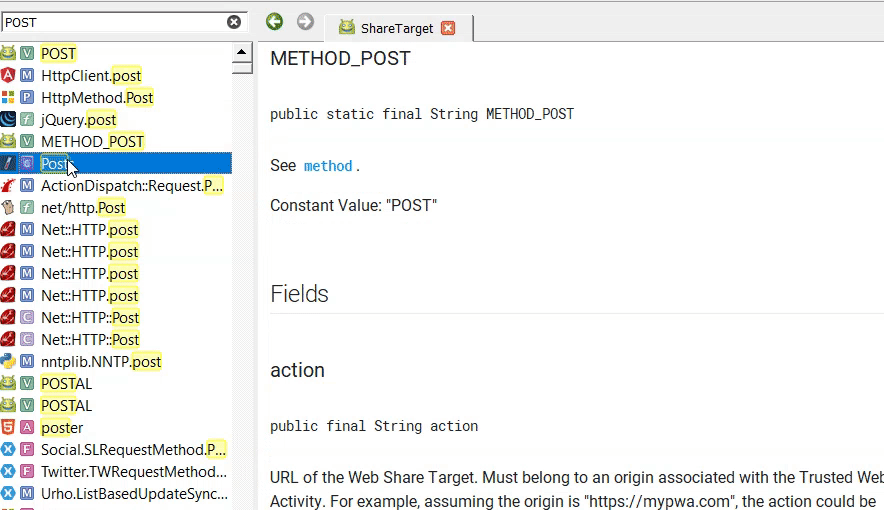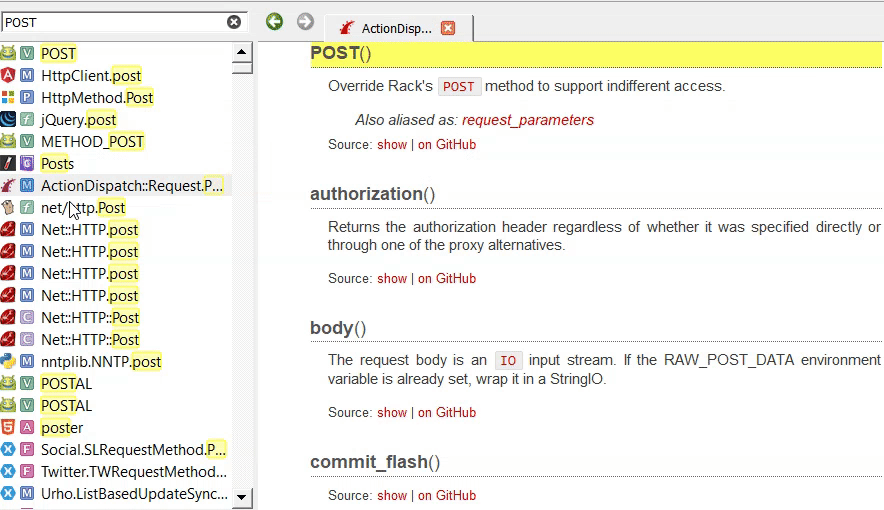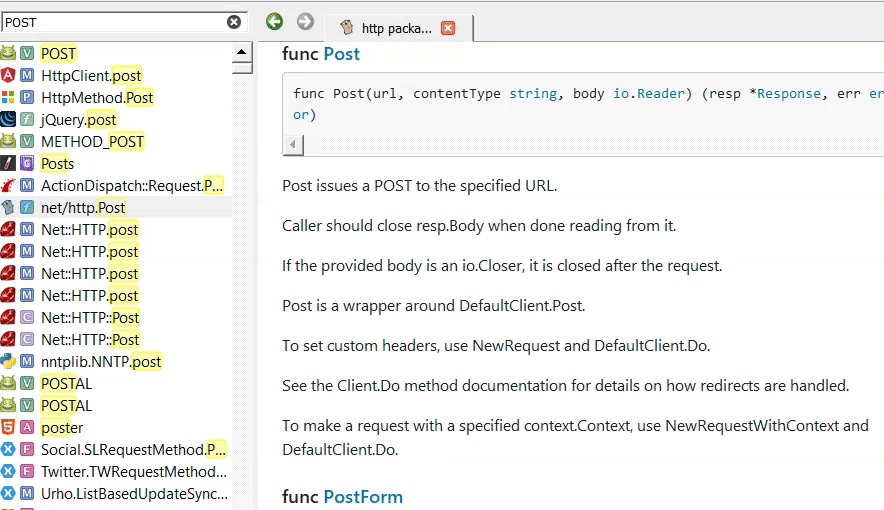
Да и в общем совершенно непонятно, как автору не хватило родной документации к тем же модулям на python, которую подтягивает любая приличная IDE и отобразит НОРМАЛЬНО, без цирка с понями. И уж тем более непонятно, зачем натягивать сову на глобус и конвертить всякий нормальный Markdown по которому в рамках проекта IDE может делать текстовый поиск в веб-портянку требующую прям отдельного браузера. Тогда уж уместнее был бы параметр меню FM "открыть директорию в Obsidian" и не теребить людям мозг. А ещё лучше было бы затянуть аналогичный обсидиану функционал в JB и VSCode и забыть про эти костыли как страшный сон
Теперь все здорово. Спасибо огромное Вам!
А сниппеты тоже там или где-то ещё?
Хотел написать, но уже забыл
Кроме того, закончив эту статью, я стал надеяться, что Zeal удастся оживить. Говорят, он давно застопорился, и последнему релизу уже четыре года
ну, он неплох по дизайну, работает, документация обновляется, да и всё-таки коммиты есть свежие. Полагаю, что он будет жить ещё долго и счастливо)
Прикольно, но к концу чтения я уже все позабыл, наверное у меня память как у этой... не помню. Можно эту статью оформить в виде подробной документации?
НЕ туда копаем, коллеги - компьютерные хитрости не превзойдут возможностей заложенных в нас.
В основном, мы визуальные мыслители образами - мы хорошо запоминаем интересные фильмы.
Информацию в виде слов, символов, чтобы запомнить, придётся преобразовывать в интересные запоминающие фильмы, не всех не обучили этому.
Некоторые помнят, раньше было - прочитал главу учебника и понял и запомнил.
А теперь не так.
Обилие БЕЗобразной, полезной, но в виде НЕ удобном для запоминая, без Образа, вынудила организмы не создавать живые картинки, экономить силы и запоминать "фотографически", но этот способ не для нас.
Меньшая часть из нас умеет выполнять преобразования в фоне - на вход много слов и символов, а внутри интересные кины.
Они хорошо вспоминают и доминируют над нами (не преобразовывающими информацию в удобрение для "памяти").
И учебники такие же пишут: хорошие, но бесполезные для большинства.
После изучения книг, типа "Эйнштейн гуляет по Луне", про визуальное мышление, мнемотехники, успокоился и иду по пути - полезнее заново восстанавливать фоновые способности запоминать ярко, интересно, легко, творчески - если не запомнил, значил запоминал не творчески.
Мне вот интересно, если я плохо запоминаю даже интересные фильмы, то что мне делать?
Если есть интерес, то шансы восстановить природные способности высоки.
У Вас есть навыки интеграции библиотек в свои проекты?
Есть "библиотеки", восстанавливающие способности памяти, осталось узнать Ваш интерфейс.
"Восстановить" можно что-то, что было раньше. Но в моей жизни не было периода (ну или я его не помню, вот ирония), когда я легко что-то запоминал.
Опишите как у Вас происходит "плохо запоминаю" и "легко что-то запоминал", а то может Ваше "плохо" для меня "хорошо".
Опишите как у Вас происходит "плохо запоминаю"
Ну вот вы говорите: "мы хорошо запоминаем интересные фильмы". Я не знаю, я из интересного фильма помню в лучшем случае общий замысел и какие-то повороты сюжета. Пару реплик, может быть. Один-два кадра иногда. Через год — и того меньше. Через пять — ничего, кроме названия. Имена актеров? Исключительно редко. Имена режиссеров? Почти никогда. Год выпуска — никогда.
"легко что-то запоминал"
Ну вот пароли я нормально запоминаю: удачный пароль (восемь алфавитно-цифровых символов) я обычно могу ввести без подсказки со второго дня рутинного использования. Это, возможно, единственное, что я запоминаю без усилий.
Давайте улучшим "плохо запоминаю даже интересные фильмы":
В подходящем ли состоянии Вы приступаете к просмотру?
Может вы отвлекаетесь во время просмотра?
Попробуйте запоминать не весь фильм целиком, а меньшими частями.
Какой фильм Вам будет интересно и полезно запомнить?
Теперь Ваша жизнь не будет прежней :-)
В подходящем ли состоянии Вы приступаете к просмотру?
Когда как, но чаще — да.
Может вы отвлекаетесь во время просмотра?
Да, отвлекаюсь.
Попробуйте запоминать не весь фильм целиком, а меньшими частями.
Для этого придется его пересматривать, причем пересматривать частями. Мне кажется, даже если бы у меня было время на пересматривание, пересматривание частями противоречит авторскому замыслу.
Какой фильм Вам будет интересно и полезно запомнить?
Интересно — где-то половину просмотренных. Полезно — все просмотренные.
Теперь Ваша жизнь не будет прежней
Неа. Ничего не изменилось.
Может быть Вы делаете, что-то лишнее, что мешает запуску встроенного механизма создания образов?
Проверьте статью.
Там утверждается:
"Язык мозга – это зрительные образы.
Ваш мозг не сможет запоминать знаковую информацию, пока вы не научитесь преобразовывать их в понятные мозгу зрительные образы. "
Вы же программист?
Хоть немного можете запоминать знаковую информацию?
Значит есть что улучшать.
Рефлексируйте себя, покройте себя юнит-тестами.
Изменяйте методы просмотров фильма: скорость, позу и т.д.
Вы пишите:
"Для этого придется его пересматривать, причем пересматривать частями."
Ну да - не можете поднять 50 кг за раз, начинаете работать с меньшими весами - разделяй и властвуй. Несколько раз.
"противоречит авторскому замыслу."
Что там мыслил автор, сейчас не учитываем.
Он может и не знал, что его фильм будет лишь гантелей.
Отнеситесь к себе как к сервису, который Вы учите воспроизводить просмотренное.
Может быть Вы делаете, что-то лишнее, что мешает запуску встроенного механизма создания образов?
Может быть. А может быть, я ничего лишнего не делаю, и "встроенный механизм" — работает.
Проверьте статью.
Там утверждается:
"Язык мозга – это зрительные образы.
Ваш мозг не сможет запоминать знаковую информацию, пока вы не научитесь преобразовывать их в понятные мозгу зрительные образы. "
Я не могу проверить эту статью. Для этого нужен эксперимент, для которого у меня нет ни ресурсов ни навыков.
Но, что важнее, я не могу поверить этой статье. В ней нет ни одной ссылки на другую литературу или исследования, кто ее автор — тоже неизвестно. Так почему я должен ей доверять?
(При этом написана она в том стиле, который у меня ассоциируется с лженаукой, и поэтому доверия не вызывает. Но это так, предрассудки.)
Вы же программист?
Хоть немного можете запоминать знаковую информацию?
В этом-то и дело. Статья, на которую вы ссылаетесь, утверждает, что я не мог бы этого делать, не преобразовывая эту информацию в зрительные образы — но это не так. Та информация о программировании, которую я помню, содержится в моей голове в виде смысла. "Свойство от поля отличается вот тем-то". Никаких зрительных образов, только понимание (даже не определение, определение я как раз не помню, и вывожу из понимания).
Или, пример из другой моей области знаний: "сонатная форма (точнее, форма сонатного аллегро) — это форма, характеризующаяся следующим устройством ...". Аналогично, у меня нет в голове зрительных образов, соответствующих главной или побочной партии, их тональным соотношениям и так далее. Это все абстрактные понятия, и их сила именно в том, что они абстрактны.
Или вот я помню, как звучит валторна, а как — кларнет, а как — гобой. Я узнаю эти звуки на слух, но визуальные образы с этим связаны только потому, что я знаю, как выглядит валторна, кларнет или гобой. "Что это звучит? Явно не медь, но яркое и округлое — кларнет" — и только потом, как ответ на слово кларнет, будет картинка инструмента. А вот как выглядит челеста, я не знаю вовсе, но звук узнаю.
Так что статья, на которую вы ссылаетесь, еще и противоречит моему жизненному опыту. Так почему я должен ей доверять?
Значит есть что улучшать.
Да, но что? Я запоминаю, как вы выражаетесь, "знаковую информацию" лучше, чем визуальную. Так почему я должен привязываться к неэффектикному для меня способу запоминания?
Рефлексируйте себя, покройте себя юнит-тестами.
Вы знаете, да, какая самая важная характеристика юнит-теста? Воспроизводимость. А то, что вы мне предлагаете, не является воспроизводимым объективным экспериментом.
Он может и не знал, что его фильм будет лишь гантелей.
Ваша метафора предполагает, что если один (или несколько) фильмов запомнить по частям, то дальше фильмы будут запоминаться целиком. Но совершенно не понятно, из чего делается такой вывод.
Отнеситесь к себе как к сервису, который Вы учите воспроизводить просмотренное.
Вам, возможно, это покажется странным, но я не хочу и не планирую относиться к себе, как к сервису, единственная задача которого — воспроизводить просмотренное. Фильмы для меня — развлечение, а не профессия.
я из интересного фильма помню в лучшем случае общий замысел и какие-то повороты сюжета. Пару реплик, может быть. Один-два кадра иногда.
Этого вполне достаточно, фильмы — для развлечения, а не для запоминания.
Имена актеров? Исключительно редко. Имена режиссеров? Почти никогда. Год выпуска — никогда.
Кому эта информация нужна, кроме киноведов и фанатов? Я даже не читаю эти данные, а имена выдающихся актеров/режиссёров сами запомнятся, ибо их будут повторять из каждого утюга.
если я плохо запоминаю даже интересные фильмы, то что мне делать?
Если забывание фильмов не угрожает вашему благосостоянию и счастью, то расслабиться и получать удовольствие :)
Вот только это несколько противоречит стартовому утверждению "в основном, мы визуальные мыслители образами — мы хорошо запоминаем интересные фильмы".
Удобно, можно их снова пересматривать через несколько лет
В основном, мы визуальные мыслители образами - мы хорошо запоминаем интересные фильмы.
Это опасный стереотип. Во-первых, у любого человека, не обладающего нарушениями умственного развития, функционируют все типы мышления, но да -- развиты они в разной степени у разных людей. Во-вторых, даже если полагать, что визуальное мышление доминирует в среднем по больнице, то в среде учёных/инженеров есть сильный перекос в сторону людей с аналитическим мышлением, оперирующим абстрактными образами в виде правил, слов и других лексических единиц (например, математических символов). И таким людям запомнить суть хорошо структурированного текста гораздо проще, чем набор картинок или информацию, поданную в виде, прости-господи, видео-клипа. В третьих, художественные фильмы несут совершенно другой тип информации, нежели тот, который обычно представлен в документации или учебнике. Фильмы, они про эмоции, и интересный фильм должен, в первую очередь, "цеплять". Этим он, собственно, и может запомниться. А какие там были кадры, сцены и т.п., у меня, например, выпадает из головы в течение пары дней после просмотра (сюжет и, иногда даже, имена главных актёров, могут продержаться намного дольше).
А опасен этот стереотип как раз тем, что люди с реально хорошо развитым визуальным мышлением, считают, что такие вокруг все, и вместо понятных чётких объяснений в текстовой форме (максимум с диаграммами и графиками) пропихивают везде дурацкие видео-туториалы, видео-описания и прочий информационный мусор, среди которого трудно найти то, что нужно.
Статья не для тех, кто хорошо запоминает символы - они хорошо, сами себе, в фоне создают образы, поэтому им явные образы не нужны.
А для тех кто, заметил, что символьная информация стала хуже запоминаться.
Им поможет обращение внимания на создание образов - фоновый процесс создания образов у них ухудшился.
Информацию в виде слов, символов, чтобы запомнить, придётся преобразовывать в интересные запоминающие фильмы, не всех не обучили этому.
О, нет! Не нужно то, что понятно объяснимо несколькими абзацами текста - текста, читаемого с удобной для читателя скоростью, иногда со схематическими иллюстрациями, превращать в получасовый треп в ютубе, который идет с удобной для диктора, а не слушателя скоростью, где практически невозможно притормозить на непонятном или требующем обдумывания месте, равно как и практически невозможно ускорить понятные или уже известные фрагменты, на которые не нужно тратить время слушателя. Техническая возможность перемотать, поставить на паузу или изменить скорость воспроизведения практически почти бесполезна против возможности читать текст с субъективно удобной скоростью. А иллюстрации - отдельный ад, когда вместо разглядывания иллюстрации и сверки с описанием в тексте так долго, как требуется конкретному читателю, приходится судорожно жать на паузу, чтобы разглядеть хоть что-то.
Нет, спасибо, не надо. Видео бесспорно хорошо для иллюстрации некоторых процессов, но таких - абсолютное меньшинство. Глобально видео "рулит" в таких областях, как киноискусство, тогда как в околотехнических вопросах видео чаще зло, бессмысленное и беспощадное.
Ответил в предыдущем комментарии
Прямо ностальгией накрыло :)
Вспомнился Norton Guide из начала-середины девяностых. Он сидел в памяти под DOS как резидентная программа, всплывал и убирался по горячим клавишам, и показывал документацию в своем простом формате. Я тогда всю имеющуюся доку в его формат перевел.
Потом, уже году в 98-м, когда на линукс пересел, настроил в fvwm2 горячие клавиши и управление окнами и рабочими столами, чтобы от окна с кодом мгновенно переключаться на окна с разной документацией и обратно. Тот конфиг fvwm2 до сих пор со мной, под ним и живу.
Мне лично повеяло концом 90х, когда я только начинал писать в Visual Studio и ставил гигантские пакеты справочной информации. Инет был через модем еще (или уже ADSL, не помню).
Если серьезно, то разве не для этого нужна нормальная IDE? Чтобы сразу иметь и подсказки, и подсветки, и проверку синтаксиса, и всю основную документацию сразу и практически для любого языка/формата. Тот же vscode даёт всю необходимую справку из коробки, а с дополнениями - и примеры с github'а подтянет тут же, и intellicode попробует подсказать целый кусок кода (не говоря уж о copilot), и тот же Zeal/Dash можно подключить, если уж такая потребность именно в них. А хочется Ansible - да пожалуйста, да и докер туда же, и compose, и подключение к удалённому хосту для разработки сразу на нём. И не нужно отдельное приложение только для справки, не нужно ничего специально качать, конвертировать. Достаточно вбить примерно название функции - и IDE всё подскажет и расскажет. Возможно я что-то упустил, но как раз проблемы со справочной информацией еще ни разу не видел.
Как оставаться программистом, если у тебя память как у дрозофилы