Наблюдая выводы таких команд, как top, htop, uptime, w и, возможно, других, пользователь наверняка обращал внимание на строку load average:
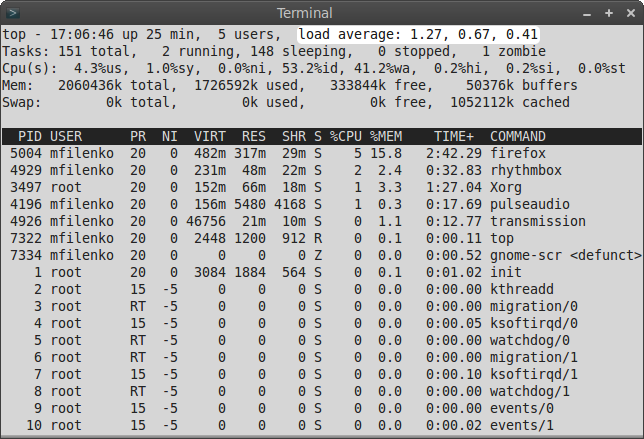
Расширяя обсуждение в «Общем обзоре стандартных средств наблюдений за системой», попробуем разобрать смысл этих чисел. Итак, проще говоря, числа отражают число блокирующих процессов в очереди на исполнение в определенный временной интервал, а именно 1 минута, 5 минут и 15 минут, соответственно. Понятие блокирующих процессов обычно хорошо освещают в последнее время, когда рассказывают о nginx. :) В данном случае, блокирующий процесс — это процесс, который ожидает ресурсов для продолжения работы. Как правило, происходит ожидание таких ресурсов, как центральный процессор, дисковая подсистема ввода/вывода или сетевая подсистема ввода/вывода.
Высокие значения показателей load average говорят о том, что система не справляется с нагрузкой. Если речь идет о целевом сервере, работающем под высокой нагрузкой, то обычно полезно провести тонкую настройку операционной системы (сетевая подсистема, ограничение на количество одновременно открытых файлов и тому подобное). Высокая загрузка также может быть вызвана аппаратными проблемами, например, выходом из строя накопителя.
Для диагностики обратимся к другим полезным данным, предоставляемым выводом top. Строка Cpu(s) содержит информацию о распределении процессорного времени. Первые два значения непосредственно отражают работу CPU по обработке процессов:
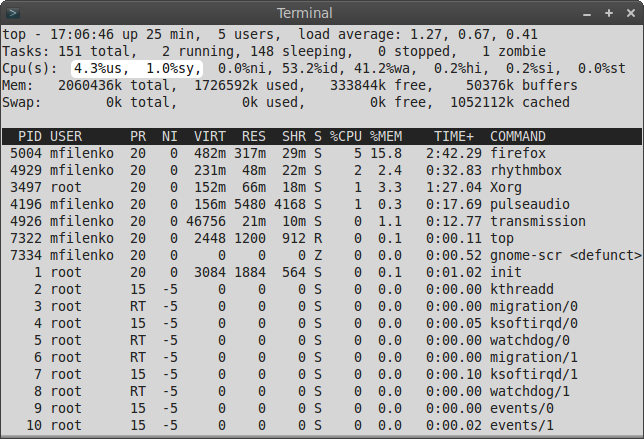
Затяжные высокие (99-100%) показатели указывают на ЦП как на узкое место.
Параметр wa говорит о простое, связанным с вводом/выводом:
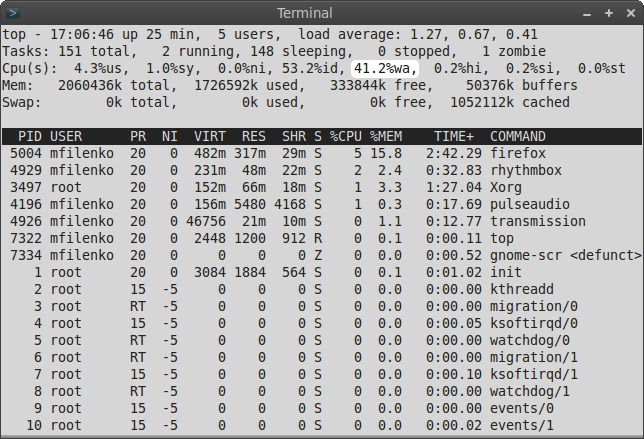
Выше 80% считается не совсем нормальным и явно указывает нам на то, что процессор проводит очень много времени в ожидании ввода/вывода (обычно это означает, что выходит из строя HDD или NIC).
Если же оборудование в порядке и ЦП быстр, скорее всего, проблема в ПО. Проблемное приложение можно отловить с помощью ps axfu. Полученный вывод предоставит список процессов, а также нужную информацию: потребление процессора, памяти, состояние, ну и непосредственно информацию, идентифицирующую процесс (PID и команду). К слову о состояниях процессов. Типичными состояниями процессов являются следующие три (полный список доступен на странице руководства man ps — спасибо, onix74):
Последнее как раз то, что мы ищем. Дальнейшую отладку можно производить вооружившись iostat, systat (FreeBSD), strace, iperf, но это уже тема другой статьи.
Высоких uptime, низких load average, ну и конечно же удачи! :)
Расширяя обсуждение в «Общем обзоре стандартных средств наблюдений за системой», попробуем разобрать смысл этих чисел. Итак, проще говоря, числа отражают число блокирующих процессов в очереди на исполнение в определенный временной интервал, а именно 1 минута, 5 минут и 15 минут, соответственно. Понятие блокирующих процессов обычно хорошо освещают в последнее время, когда рассказывают о nginx. :) В данном случае, блокирующий процесс — это процесс, который ожидает ресурсов для продолжения работы. Как правило, происходит ожидание таких ресурсов, как центральный процессор, дисковая подсистема ввода/вывода или сетевая подсистема ввода/вывода.
Высокие значения показателей load average говорят о том, что система не справляется с нагрузкой. Если речь идет о целевом сервере, работающем под высокой нагрузкой, то обычно полезно провести тонкую настройку операционной системы (сетевая подсистема, ограничение на количество одновременно открытых файлов и тому подобное). Высокая загрузка также может быть вызвана аппаратными проблемами, например, выходом из строя накопителя.
Для диагностики обратимся к другим полезным данным, предоставляемым выводом top. Строка Cpu(s) содержит информацию о распределении процессорного времени. Первые два значения непосредственно отражают работу CPU по обработке процессов:
Затяжные высокие (99-100%) показатели указывают на ЦП как на узкое место.
Параметр wa говорит о простое, связанным с вводом/выводом:
Выше 80% считается не совсем нормальным и явно указывает нам на то, что процессор проводит очень много времени в ожидании ввода/вывода (обычно это означает, что выходит из строя HDD или NIC).
Если же оборудование в порядке и ЦП быстр, скорее всего, проблема в ПО. Проблемное приложение можно отловить с помощью ps axfu. Полученный вывод предоставит список процессов, а также нужную информацию: потребление процессора, памяти, состояние, ну и непосредственно информацию, идентифицирующую процесс (PID и команду). К слову о состояниях процессов. Типичными состояниями процессов являются следующие три (полный список доступен на странице руководства man ps — спасибо, onix74):
- S — так называемое состояние сна;
- R — состояние выполнения;
- D — состояние ожидания.
Последнее как раз то, что мы ищем. Дальнейшую отладку можно производить вооружившись iostat, systat (FreeBSD), strace, iperf, но это уже тема другой статьи.
Высоких uptime, низких load average, ну и конечно же удачи! :)

