
Международная система здравоохранения ежедневно генерирует множество медицинских данных, которые (по крайней мере, теоретически) можно использовать для машинного обучения. В любой отрасли данные считаются ценным ресурсом, который помогает компаниям обгонять конкурентов, и здравоохранение не является исключением.
В этом посте мы вкратце рассмотрим сложности, с которыми приходится сталкиваться при работе с медицинскими данными, и сделаем обзор публичных медицинских датасетов, а также практических задач, которые они помогают выполнять.
Медицинские данные: что следует учитывать при работе с информацией здравоохранения
Основная проблема данных здравоохранения заключается в их уязвимости. Они содержат конфиденциальную информацию, защищённую Health Insurance Portability and Accountability Act (HIPAA), и не могут использоваться без явно выраженного согласия. В сфере медицины чувствительные подробности называются защищаемой информацией о здоровье (protected health information, PHI).
Protected Health Information и идентификаторы HIPAA
Protected Health Information (PHI) содержится в различных медицинских документах: электронных письмах, клинических заметках, результатах тестов или сканах КТ. Хотя диагнозы или медицинские предписания сами по себе не считаются чувствительной информацией, они становятся предметом HIPAA, когда сопоставляются с так называемыми идентификаторами: именами, датами, контактами, номерами социального страхования или счетов, фотографиями лиц или другими элементами, при помощи которых можно находить или идентифицировать конкретного пациента, а также связываться с ним.
Существует 18 идентификаторов HIPAA, и даже одного из них достаточно, чтобы весь документ превратился в PHI, которую нельзя раскрывать сторонним лицам. Чтобы избежать распространённых ошибок и связанной с ними юридической ответственности, прочитайте нашу статью о нарушениях HIPAA.
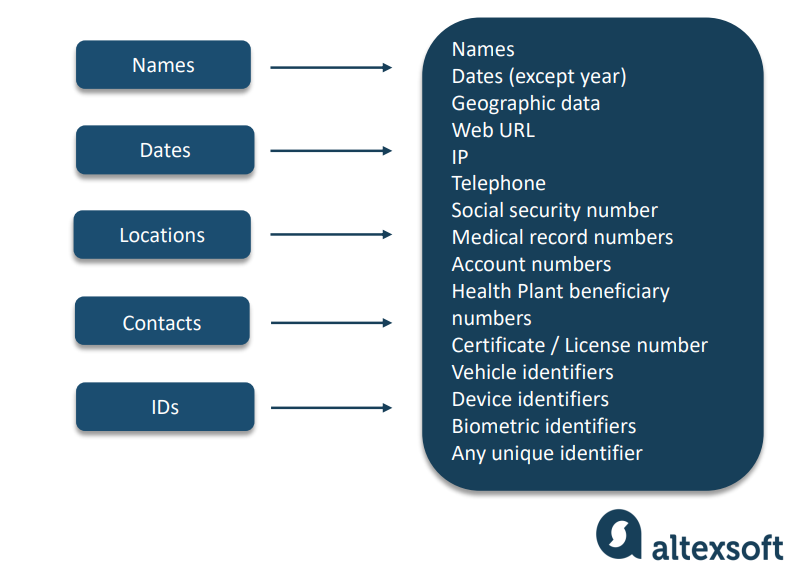
Все категории идентификаторов PHI с примерами
Анонимизация медицинских данных и удаление из них персональной информации
То есть прежде чем использовать медицинские данные для исследовательских или деловых целей, необходимо избавиться от идентификаторов личности и даже от их частей (например, инициалов). Существует два способа это сделать — анонимизация и удаление личной информации.
Анонимизация — это безвозвратное устранение всех чувствительных данных. Удаление персональной информации (de-identification) только шифрует личные сведения и скрывает их в отдельных датасетах. Позже идентификаторы можно повторно связать с информацией о здоровье. Вторая методика требует больше усилий, чем первая. Как бы то ни было, в обоих случаях потребность соответствия требованиям нормативов добавляет ещё один этап к подготовке датасетов для машинного обучения.
Разметка медицинских данных
Любые неструктурированные данные, будь то тексты, изображения или аудиофайлы, для обучения моделей машинного обучения требуют разметки или аннотирования. Это процесс добавления к блокам данных описательных элементов (меток или тэгов), чтобы компьютер мог понимать, что находится в изображении или тексте. Чтобы узнать об инструментах аннотирования и рекомендациях, прочитайте нашу статью о том, как организовать разметку данных.
При работе с данными здравоохранения разметку должны выполнять медицинские специалисты. Почасовая стоимость их услуг гораздо выше, чем у аннотаторов, не имеющих знаний в предметной области. Это создаёт ещё один барьер перед генерацией качественных медицинских датасетов.
Подведём итог: хотя существует избыток медицинских данных, их подготовка для машинного обучения обычно требует больше денег и времени, чем в среднем в других отраслях из-за строгого регулирования и участия высокооплачиваемых специалистов в предметной области. Неудивительно, что публичные медицинские датасеты относительно редки и привлекают серьёзное внимание исследователей, дата-саентистов и компаний, работающих над ИИ-решениями в сфере медицины. Ниже мы расскажем о том, какие коллекции данных есть в Интернете, и о том, какие практические задачи можно решать с их помощью.
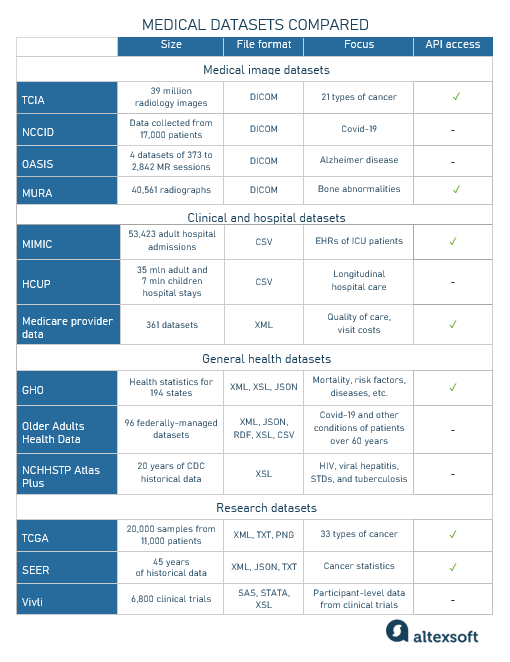
Таблица сравнения медицинских датасетов
Датасеты медицинских снимков
Изображения составляют подавляющее большинство (почти 90%) всех данных здравоохранения. Это даёт много возможностей по обучению алгоритмов computer vision для потребностей здравоохранения. Стоит заметить, что данные медицинских снимков в основном генерируются в отделах радиологии в виде рентгенограмм, сканов КТ и МРТ. Международным стандартом здравоохранения для хранения и передачи диагностических снимков является DICOM (Digital Imaging and Communication in Medicine).
DICOM гарантирует, что всё оборудование для создания снимков, изготовленное разными компаниями, может общаться на одном языке и свободно обмениваться данными. Обычно один файл DICOM содержит множество изображений, технические сведения и заголовок с именем и анкетными данными пациента. Разумеется, для соответствия требованиям HIPAA из датасетов для машинного обучения все личные данные удаляются.

Файл DICOM со снимками и метаданными
Теперь давайте перейдём к рассмотрению крупнейших источников готовых датасетов снимков, лежащих в основе ИИ-проектов и представляющих большую ценность для сообщества исследователей, разработчиков машинного обучения и медицинских специалистов.
The Cancer Imaging Archive (TCIA)
The Cancer Imaging Archive (TCIA), финансируемый Национальным институтом онкологии США (NCI) — это место хранения в открытом доступе радиологических и гистопатологических снимков, в основном в формате DICOM, представляющих 21 тип рака. Коллекции данных разделены по заболеваниям (рак груди и так далее), модальности снимков (КТ, МРТ и так далее) и задачам исследований. Архив также дополняет снимки имеющимися вспомогательными данными, такими как подробности лечения, результаты лечения и геномика.
Получить доступ к данным TCIA можно четырьмя способами:
- просмотреть список всех коллекций;
- через порталы данных радиологии и патологической гистологии с расширенными функциями поиска и фильтрации
- при помощи программных интерфейсов TCIA (REST API) разработчики могут интегрировать в свои приложения прямой доступ к данным.
Находящиеся в архиве данные снимков активно используются в научных исследованиях. Например, в недавнем исследовании, нацеленном на оценку точности алгоритмов глубокого обучения в диагностировании вируса папилломы человека (ВПЧ) на снимках КТ поздних стадий рака ротоглотки.
Подробный список научных исследований, выполненных на основе архива TCIA, можно найти на официальном веб-сайте.
Выборка снимков МРТ из архива TCIA
Национальная база данных снимков органов грудной клетки на Covid-19 (NCCID)
National Covid-19 Chest Imaging Database (NCCID), являющаяся частью AI Lab Государственной службы здравоохранения Великобритании (NHS), содержит рентгенограммы, снимки МРТ и КТ органов грудной клетки пациентов больниц по всей Великобритании. Это один из крупнейших архивов такого типа, вклад в который вносят 27 больниц и фондов.
Обучающие данные, собранные у более чем 17 тысяч пациентов, можно использовать для разработки ПО обработки снимков, математического моделирования и валидации ИИ-продуктов. Например, они позволяют создать модель, прогнозирующую оценку риска COVID-19 по рентгенограммам грудной полости или создать систему поддержки принятия решений на основе ИИ для помощи в выявлении коронавируса на конкретном снимке.
Open Access Series of Imaging Studies (OASIS)
Задача базы данных OASIS Brains заключается в обеспечении свободного доступа научного сообщества к данным нейровизуализаций. Этот обширный архив данных существует благодаря исследовательским группам и центрам в Вашингтонском и Гарвардском университетах, а также сети Biomedical Informatics Research Network (BIRN).

Выборка снимков из датасета OASIS
OASIS содержит четыре датасета: снимков МРТ, КТ и ПЭТ (позитронно‐эмиссионной томографии) пациентов в возрасте от 18 до 96 лет. Эти коллекции помогают в создании инструментов диагностики болезни Альцгеймера. Однако для доступа к снимкам нужно объяснить команде OASIS, как вы будете их использовать.
Скелетно-мышечные рентгенограммы (MURA)
MURA (Musculoskeletal Radiographs) — один из крупнейших публичных датасетов рентгенограмм. Он содержит 40 561 рентгенограмму верхних конечностей (предплечий, локтей, плеч и так далее) из 14 863 исследований, в которых участвовало 12 173 пациента. Каждый снимок вручную размечали как нормальный или паталогический радиологи высшей категории из Стэнфордского госпиталя.
Все данные MURA становятся доступными для скачивания после регистрации на веб-странице.
Сегодня более 1,7 миллиарда людей по всему миру страдают от серьёзных скелетно-мышечных заболеваний, поэтому такая коллекция позволяет упростить использование глубокого обучения в медицинской диагностике, что, в свою очередь, позволяет выявлять заболевания на ранних стадиях и помогает решить проблему нехватки радиологов.
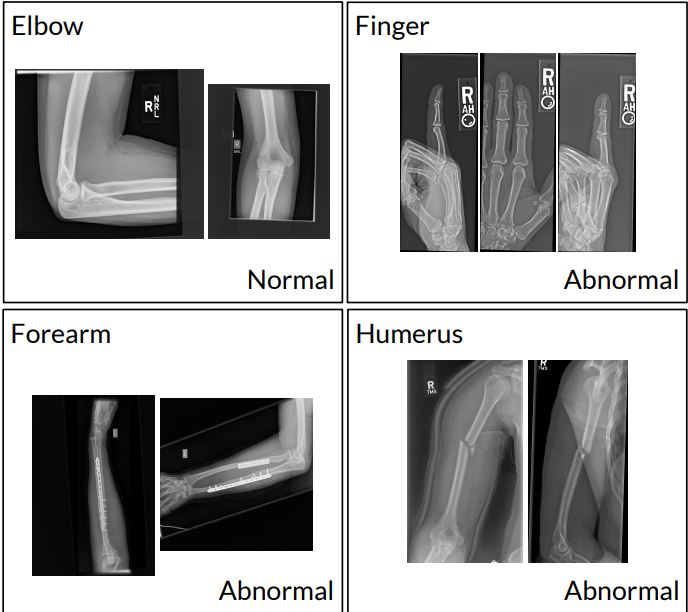
Рентгенограммы верхних конечностей, размеченные как нормальные или патологические
Датасеты клиник и больниц
Больницы генерируют огромный объём медицинской информации и в частности информации о пациентах, от показателей жизнедеятельности и планов лечения до платежей и повторной госпитализации. Основная часть этих данных находится во внутренних системах учреждений здравоохранения, а именно в системах EHR (Electronic Health Record), системах управления медицинскими практиками, системах лабораторной информации, порталах для пациентов и других.
Другими источниками информации, связанной с уходом за пациентами, являются инструменты страховых отделов и базы данных государственных органов здравоохранения. При правильном структурировании и организации эти огромные коллекции могут стать основой для проектов машинного обучения. Давайте узнаем, где искать крупнейшие готовые к использованию больничные датасеты, охватывающие различные аспекты здравоохранения.
Medical Information Mart for Intensive Care (MIMIC)
MIMIC — это крупнейшая публичная коллекция очищенных от личных данных электронных медицинских карт (electronic health record, EHR), связанных с пациентами реанимационных отделений. Эта база данных, управляемая MIT Laboratory for Computational Physiology, содержит информацию о госпитализации, выписанных лекарствах, показателях жизнедеятельности, лабораторных измерения и так далее.
MIMIC привлекла к себе большой интерес со стороны сообщества разработчиков ML, работающих над решением различных медицинских задач. В недавнем исследовании, основанном на MIMIC, описывается обучение модели обучения с подкреплением, помогающей выбрать терапию при сепсисе. Другое исследование посвящено разработке системы поддержки принятия решений для выявления готовых к выписке пациентов реанимации.
Healthcare Cost and Utilization Project (HCUP)
HCUP, которым управляет Agency for Healthcare Research and Quality (AHRQ), содержит базы данных США и отдельных штатов, которые можно использовать для выявления и исследования тенденций в доступности, использовании и результатах работы системы здравоохранения.
Этот проект включает в себя крупнейшую в США публичную коллекцию данных стационарного лечения. Он охватывает более 35 миллионов госпитализаций взрослых и более 7 миллионов госпитализаций несовершеннолетних. Эти данные можно использовать для обучения моделей прогнозированию риска заболеваний, длительности пребывания в больнице, затрат на лечение и многого другого. Также это ценный инструмент для изучения редких заболеваний.
Данные поставщиков услуг Medicare
Medicare Provider Catalog собирает официальные данные центров услуг Medicare и Medicaid (CMS). Он охватывает множество различных тем, от качества ухода в разных больницах, центрах реабилитации, хосписах и других учреждениях здравоохранения, до стоимости посещения и информации о врачах и клиницистах. Данные можно просматривать в браузере, скачивать конкретные датасеты в формате CSV или подключать собственные приложения к веб-сайту при помощи API.
Лечебно-профилактические датасеты
Лечебно-профилактическими датасетами обычно управляют государственные органы и международные организации. Эти данные могут быть полезными при изучении трендов в здравоохранении, исследовании заболеваний для понимания и предотвращения эпидемий и для других задач.
Датасеты Global Health Observatory (GHO)
Global Health Observatory (GHO) — это коллекция Всемирной организации здравоохранения по статистике о здравоохранении в 194 её странах-участниках. Она содержит датасеты, структурированные на основе различных тем (например, здоровья несовершеннолетних, ВИЧ, туберкулёза, иммунизации, ментального здоровья, питания). Заинтересовавшие вас датасеты можно свободно скачать с веб-сайта, выбрав один из имеющихся форматов — таблицы CVS и Excel, файлы XML и JSON. Также всё содержимое доступно через Athena API, основанный на современной архитектуре REST.
Целевая аудитория GHO — законодатели и профессионалы общественного здравоохранения стран-участников и различных международных организаций. Данные из этого хранилища часто приводятся в научных исследованиях, посвящённых мировым проблемам здравоохранения.
Older Adults Health Data Collection
Older Adults Health Data Collection на Data.gov состоит из 96 датасетов, управляемых федеральным правительством США. Его основное предназначение — сбор информации о здоровье людей старше 60 лет в контексте пандемии Covid-19 и вне его. Среди организаций, занимающихся поддержанием коллекции, Департамент здравоохранения и социального обеспечения США, Департамент по делам ветеранов, центры по контролю и профилактике заболеваний (CDC) и другие. Датасеты можно скачивать в различных форматах: HTML, CSV, XSL, JSON, XML и RDF.
NCHHSTP AtlasPlus
NCHHSTP AtlasPlus предоставляет доступ к историческим данным за 20 лет по иммунодефициту человека (ВИЧ), вирусному гепатиту, заболеваниям, передаваемым половым путём, и туберкулёзу. Коллекция поддерживается центрами по контролю и профилактике заболеваний США: по большей части в них используются данные из American Community Survey. AtlasPLus, в частности, использует пятилетние прогнозы, охватывающий все округа США. Информацию доступна в виде скачиваемых графиков, картограмм и таблиц Excel.
Исследовательские датасеты
Исследовательские датасеты предназначены для научного сообщества, фармакологических компаний, лабораторий и других организаций, участвующих в лечении и разработке лекарств. Они накапливают информацию из прошлых работ для дальнейшего развития медицинских исследований.
The Cancer Genome Atlas (TCGA)
The Cancer Genome Atlas (TCGA) — это важнейшая база данных геномики, охватывающая 33 типа заболеваний, в том числе 10 редких. TCGA был основан в 2006 году в результате совместной работы Национального института онкологии США и Национального института исследований генома человека (NHGRI).
С момента своего основания программа накопила более 2,5 петабайтов геномной, эпигеномной, транскриптомной и протеомной информации 11 тысяч пациентов, что равно по объёму 212 тысячам DVD.
Доступ к данным TCGA можно получить через портал Genomic Data Commons Data Portal, на котором также есть инструменты для визуализации и анализа данных. Для разработчиков существует REST API, предоставляющий программный доступ ко всем данным и функциональности, в том числе к поиску, просмотру, скачиванию и загрузке файлов данных, метаданных и аннотаций.
TCGA уже внёс свой вклад в совершенствование диагностики, лечения и профилактики рака. Например, исследование на основе данных TCGA позволило идентифицировать подтипы опухолей с собственным множеством геномных изменений. Потенциально это может помочь найти идеальное персонализированное лечение на основании специфических геномных изменений конкретного пациента. (Подробнее об этой теме можно прочитать в нашей статье, посвящённой прецизионной медицине.)
Датасеты программы Surveillance, Epidemiology, and End Results (SEER)
Программа Surveillance, Epidemiology, and End Results (SEER) — самый надёжный источник онкологической статистики в США, предназначенный для снижения доли раковых заболеваний в популяции. Её база данных поддерживается Surveillance Research Program (SRP), которая является частью Division of Cancer Control and Population Sciences (DCCPS) Национального института онкологии.
Данные SEER применимы во множестве ситуаций, например:
- при исследовании стадии во время диагностики с учётом расы или этнической принадлежности;
- при вычислении выживаемости по стадии или возрасту по диагностике, размеру опухоли
- при определении частоты заболеваний и тенденций появления других очагов опухолей со временем.
Для анализа SEER и других баз данных, связанных с раком, можно использовать SEER Stat Software.
Датасеты клинических исследований Vivli
Vivli — это некоммерческая организация, координирующая, упрощающая и продвигающая научное исследование данных клинических исследований и обмен ими. В настоящее время Vivli содержит 6,8 тысяч клинических испытаний; её поддерживают 44 члена-участника (известные мировые компании наподобие AstraZeneca, Bayer, Pfizer, Roche и другие). Её ресурсы привлекли 3 миллионов участников из 115 стран.
Vivli управляет платформой обмена данными и аналитики, на которой можно искать информацию об имеющихся исследованиях. Найдя необходимое, нужно заполнить форму запроса данных. После проверки нужно подписать соглашение об использовании данных, и затем вы получите доступ к защищённой исследовательской среде и инструментам аналитики Vivli. По запросу также можно использовать собственное ПО и алгоритмы для анализа данных. Для скачивания конкретного датасета необходимо получить одобрение платформы.
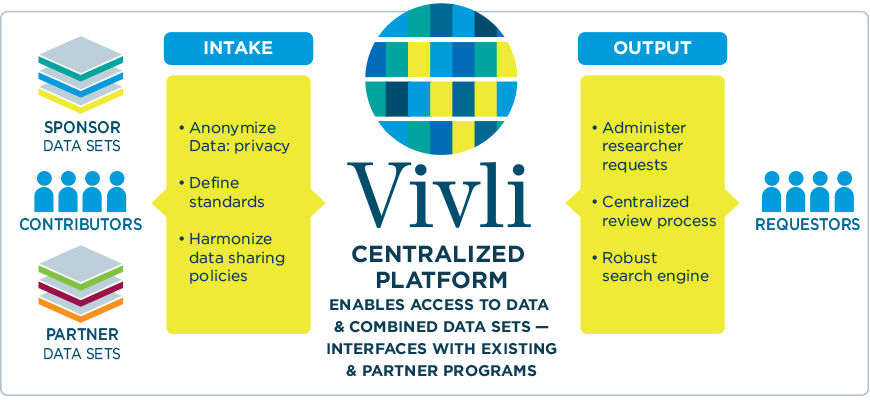
Визуализация работы централизованной платформы Vivli
Где ещё можно найти медицинские датасеты
Наряду с перечисленными выше специализированными хранилищами существуют и другие источники медицинских датасетов для проектов машинного обучения. Например, data.world — облачный каталог данных, накопивший почти 3,5 тысяч связанных со здоровьем коллекций. Ещё одна стоящая внимания платформа — Papers With Code: в ней хранится 6 964 датасета для ML, и 244 из них относится к области медицины. Датасеты можно фильтровать по модальности (изображения или текст), задаче (классификация, сегментация, диагностика и так далее) и языку.
На Kaggle, который называют «Airbnb для data science», тоже есть кое-что интересное. Среди его 50 тысяч публичных датасетов 953 имеют тэги medical, а более 14,3 тысяч в той или иной мере связаны со здоровьем. AltexSoft использовала датасеты Kaggle с рентгенограммами органов грудной клетки для создания инструмента диагностики лёгких на основе ИИ, поддерживающего принятие решения по пневмотораксу, пневмонии и фиброзу. Хотя всегда лучше иметь большие датасеты, предназначенные для конкретной цели, публичные ресурсы всё равно могут идеально подходить для небольших проектов и исследований.
Понравилась статья? Еще больше информации на тему данных, AI, ML, LLM вы можете найти в моем Telegram канале.
- Как подготовиться к сбору данных, чтобы не провалиться в процессе?
- Как работать с синтетическими данными в 2024 году?
- В чем специфика работы с ML проектами? И какие бенчмарки сравнения LLM есть на российском рынке?

