Мы с командой разрабатываем FractalGPT - проект самообучающегося ИИ на базе больших языковых моделей(LLM) и логического вывода (reasoning). В этой статье мы расскажем о разработанном нами новом подходе, который называется fractal answer synthesis. Фрактальный синтез ответа позволяет существенно уменьшить уровень «галлюционирования» LLM и, как следствие, является важным шагом к решению проблемы фактологии г енеративных нейросетей. По сути подход позволяет перейти от простого векторного представления текста(базы знаний) к его фрактальному представлению — более сложной структуре, инкапсулирующей внутри себя дополнительные «смыслы», которые содержатся в тексте. В статье мы кратко описали преимущества и недостатки подхода, показали алгоритм построения «фрактального графа», представили принципиальную схему алгоритма и результаты тестирования на нашей базе знаний — статьях и книгах.

Большие языковые модели (по-русски БЯМ, а в англоязычной литературе LLM - large language models) последнее время стали очень популярными в области обработки естественного языка. Они используются для автоматического перевода, генерации текстов и ответов на вопросы. Эти модели обучаются на больших наборах данных и способны генерировать тексты, которые сложно отличить от текстов, написанных человеком. Одними из наиболее известных LLM(БЯМ) являются ChatGPT и GPT-4 от компании OpenAI.
Но, несмотря на огромную популярность, такие модели довольно сильно страдают от т.н. «галлюцинаций» и отсутствия доступа к актуальной информации, т.к. знания модели ограничены датой ее обучения.
Галлюцинациями, в данном контексте называют ситуацию, когда LLM генерирует текст, который не соответствует реальности, т.е. текст с сильными нарушениями фактологии. Например, нейросеть может придумать детали, факты, имена или события которые не имеют отношения к реальности.
Эта проблема связана с тем, что LLM генерирует текст на основе моделирования вероятности появления следующего токена в последовательности (подробнее о способах генерации в туториале от Huggingface). Но, если контекст не содержит достаточно информации, нейросеть может придумывать несуществующие факты.
Обзор методов решения
Давайте кратко рассмотрим несколько подходов к решению проблемы, которые сейчас активно предлагаются.
Для решения данной проблемы и уменьшения вероятности галлюцинаций, исследователи предлагают несколько методов:
Использование дополнительной модели для поиска информации в документах, с последующей передачей этой информации в генеративную нейросеть.
Обучение моделей на бОльшем количестве данных, а также создание специальных (фактологических) наборов данных.
Использование обучения с подкреплением, на основе оценок поставленных людьми, как это делают в OpenAI (RLHF).
Соединение LLM с моделью мира (это наиболее сложный и перспективный подход, но в данной статье мы его не будем рассматривать из-за объемности).
Мы в нашем проекте FractalGPT используем комбинацию методов: 1-й метод, а также 3-й и 4-й методы, а в данной статье будет рассмотрен первый метод, а именно использование дополнительной поисковой модели. Сам по себе метод совмещения поисковой и генеративной моделей хорошо известен, однако именно он позволяет малыми усилиями добиваться хорошего качества.
Обычно для поиска используются поисковые движки (например Elasticsearch), которые извлекают большое число сниппетов (несколько предложений/слов подряд). После чего используется алгоритм ранжирования, как, например, в этой работе Explain Anything Like I'm Five: A Model for Open Domain Long Form Question Answering - он основан на модели RetriBert, а это по сути сиамская нейросеть основанная на архитектуре BERT. Эта нейросеть обучена так, что косинус между вектором вопроса и вектором ответа на этот вопрос больше, чем вектора этого вопроса и ответа на другой вопрос. После такого ранжирования оставляют только первые N сниппетов, и передают в генеративную сеть вместе с вопросом. В этом подробном туториале по построению ретривал QA системы Explain Anything Like I'm Five: A Model for Open Domain Long Form Question Answering в качестве генеративной сети используется BART, но можно использовать и ChatGPT, недавно утекшую в интернет LLaMA и многие другие.
Рис 1. Сниппеты из Википедии, полученные с помощью модели Retribert, содержащие внутри себя элементы правильного ответа на научный вопрос по физике (статья Explain Anything Like I'm Five: A Model for Open Domain Long Form Question Answering)
Другим популярным подходом является использование векторных баз данных, они позволяют сразу искать небольшое число сниппетов, которые позже передаются в генеративную модель. Работа с векторной базой, обычно, состоит из следующих шагов:
Предварительная обработка текста: документы преобразуются в набор векторов (вектор - сниппет) с помощью модуля векторизации, ядро такого модуля может реализовано на базе одного методов, которых на данный момент довольно много: TF-IDF, word2vec, Glove, FastText, lda2vec, doc2vec(он же paragraph2vec), LaBSE, BERT, RoBERTa, DeBERTa, SBERT и проч.. Важно отметить, что нейросеть должна быть дообучена как сиамская, так, чтобы косинус между вектором вопроса и вектором ответа на этот вопрос был больше, чем косинус вектора того же вопроса и ответа на любой другой вопрос.
Индексация документов: векторы документов индексируются в базе данных, обеспечивая быстрый доступ к ним во время поиска.
Поиск: при поступлении запроса он также преобразуется в вектор, который сравнивается с векторами документов в базе данных. Результатом является ранжированный список сниппетов, отсортированных по степени соответствия запросу.
В конечном итоге ранжированный список сниппетов передается в генеративную модель, которая и генерирует ответ на вопрос.
Одним из примеров имплементации такого подхода является проект LlamaIndex, а недавно на Хабр вышел перевод статьи Обучаем с помощью LlamaIndex и OpenAI GPT-3 отвечать по вашей базе знаний в которой описан процесс создания индекса из ваших документов и затем ответов на вопросы по нему.
Но и у этого подхода есть ряд недостатков, основными являются:
1. то, что не учитывается внутренняя структура текстового документа
2. генерация в конечном итоге производится по ограниченному числу сниппетов.
Например, в статье про обучение Лама индекс как раз и видны эти недостатки – принципиальная неполнота и несвязность в данных, и это сильно повышает вероятность галлюцинаций.
Фрактальный синтез ответа
Для решения этих проблем неполноты и несвязности мы используем новое представление текста — в виде фрактального графа.
Фрактальный граф — это обычный направленный граф, в котором вершина является другим графом, похожим на весь этот граф. В этом смысле фрактальный граф обладает свойством самоподобия, если графы изоморфны.
Графовое представление предложений может быть использовано для самого широкого спектра, множества задач, таких как классификация текстов, анализ тональности, автоматические ответы на вопросы, а также для задач машинного перевода.
Для создания графового представления теста каждый структурный элемент представляется вершиной графа, а ребра представляют связи между этими элементами. Связи при этом могут иметь разные роли: быть семантическими, структурными и т.п.
В нашей работе минимальный элемент — это предложение, предложения объединены в направленный граф (в сниппет).

Сниппеты в свою очередь объединяются в блоки сниппетов, а то есть в “документ”.



Итоговая задача заключается в том, чтобы выполнить такое преобразование над этим графом, чтобы он превратился в граф ответа на вопрос.
Функция, выполняющая данное преобразование в нашей работе называется функцией фрактального синтеза ответа (англ. fractal answer synthesis), графически работа по преобразованию текста документа в ответ показана на рисунке. (Кстати, в случае, когда сниппеты состоят из 3х элементов итоговый фрактал похож на треугольник Серпинского.
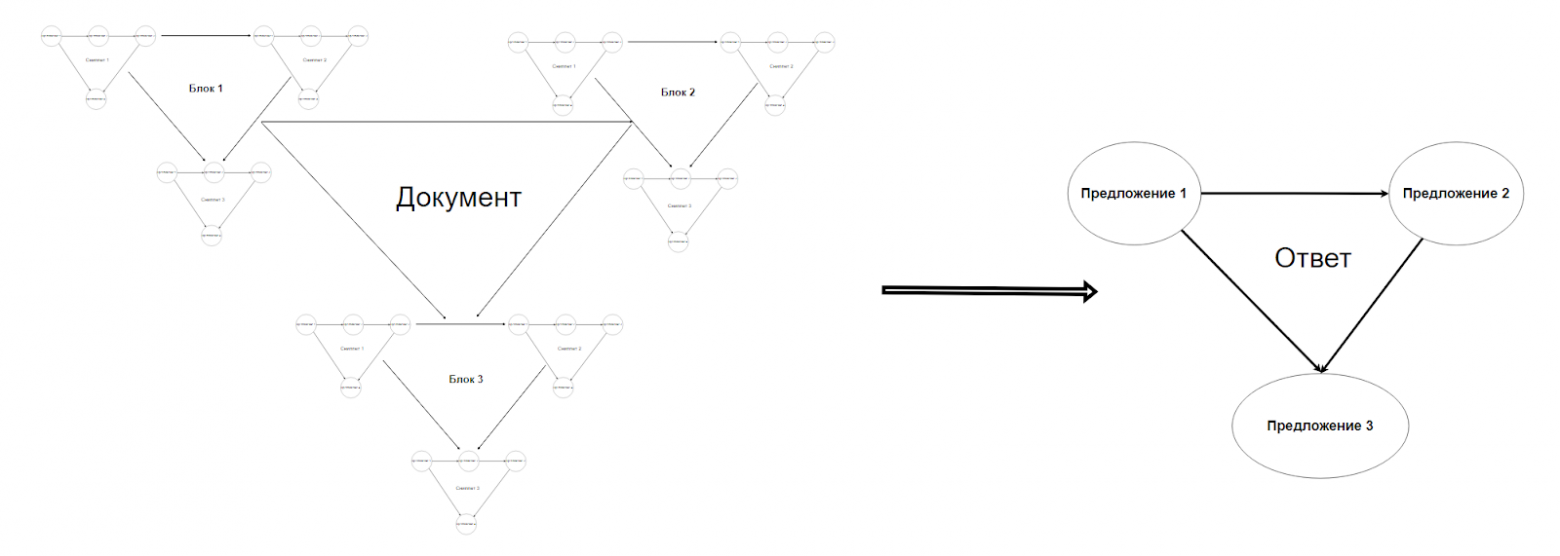
Схема алгоритма
На рисунке ниже представлена блок-схема алгоритма, создания фрактального графа и синтеза ответа. В данной статье мы не затрагиваем часть алгоритма в блоке Генерация ответа - это заслуживает отдельной статьи, ведь теперь LLM сможет генерировать намного более когерентный текст, однако она должна быть обучена делать это.

Подход | Retrieval | Fractal answer synthesis |
1 | Ограниченный размер контекста для сниппетов (2048 токенов, или 32k токенов GPT-4) | Любой размер контекста, не ограничен |
2 | Текст в виде сниппетов, несвязный текст, ответ на вопрос “разбросан” по сниппетам | Текст в виде фрактального графа с разными типами связей. Связный ответ уже получен. |
3 | LLM генерирует текст из сниппетов, высокая вероятность генерации “фантазий” | LLM решает задачу изменения стилистики ответа - а это значит намного меньшую вероятность галлюцинаций |
Таблица 1. Сравнение подходов. В Fractal answer synthesis решается принципиально другая задача, чем в стандартных подходах к генерации.
Примеры синтеза ответов
Мы протестировали алгоритм Fractal answer synthesis в ответах на вопросы по нашим же статьям на Хабре. Результат тестирования приведены ниже (в данных примерах ответы генерируются без использования LLM, вроде ChatGPT или LLaMA).




Заключение
В данной статье мы кратко рассмотрели основные принципы работы алгоритма Фрактальной генерации ответа. Мы не коснулись следующего элемента пайплайна - генерации ответа с помощью LLM, эта часть исследования находится в состоянии work in progress.
Графовое (фрактальное) представление и векторная база данных — это разные способы представления текстов. Они имеют свои преимущества и недостатки, а эффективность каждого метода зависит от конкретной задачи.
Векторная база данных использует векторы для представления структурных элементов текстовых документов. Это позволяет быстро находить схожие элементы. Однако, векторная база данных имеет ограничения в представлении семантических связей между элементами.
В то же время, с помощью графов можно лучше отображать семантические связи внутри текстовых документов, что позволяет получить более точные ответы на вопросы.
Из недостатков использования графов можно отметить то, что такой подход пока требует больших вычислительных ресурсов для синтеза структуры документа и структуры ответа. Кроме того, построение графа часто работает на правилах и его сложно автоматизировать.
Если необходимо моделировать семантические связи в тексте, то фрактальное представление может быть более эффективным методом, в то время как векторная база эффективнее для быстрого поиска схожих документов и сниппетов.
Таким образом нам представляется очень важным отметить, что для решения проблемы фактологии необходимо использовать именно фрактальное представление, поскольку оно позволяет формулировать задачу получения ответа и получения нужного “образа” ответа точнее, при этом без обучения специальной нейросети или адаптера (такого как например Lora). А при обновлении информации в документе каждый раз придется переучивать модель, и это очевидный и неустранимый недостаток.
Особенно важно это для отраслей, где документы имеют сложную связность, вложенность, зависимость одних элементов документа от других: в науке, юриспруденции, медицине.
Следить за развитием исследований можно в Телеграм
Авторы
Понимаш Захар
Руководитель проекта «FractalGPT».
Специалист в области машинного обучения и глубоких нейронных сетей. Разработчик собственного ИИ фреймворка AIFramework, а также системы логического вывода с мотивацией. Один из разработчиков: первого в РФ ИИ психолога Сабина и библиотеки для интерпретации генеративных нейросетей Transformer.
Носко Виктор
Продвижение и развитие проекта «FractalGPT».
Генеральный директор, ООО «Аватар Машина». Специалист в области генеративных нейросетей трансформер, интерпретируемого ИИ. Визионер открытого и этичного ИИ. Докладчик конференций по искусственному интеллекту: Conversations.ai, OpenTalks.ai, AGIconf, DataStart, AiMen. Активный участник сообщества AGIRussia. Один из разработчиков: первого в РФ ИИ психолога Сабина, библиотеки для интерпретации генеративных нейросетей transformer.

