
Разберем популярные паттерны проектирования ML-систем для ответов на следующие вопросы:
Какой способ выбрать для деплоя модели в production?
Как затащить сложный ML-пайплайн в real-time сервис?
Каким способом тестировать новую версию модели?
Почему внедрение модели - самая важная часть машинного обучения?
В 2010-х произошел значительный прорыв в области Data Science и машинного обучения. В то же время вопросам внедрения моделей в продакшен уделялось куда меньше внимания.
Проекты могли тянуться годами из-за отсутствия стратегии внедрения. Некоторые проекты отменялись после нескольких лет разработки - становилось ясно, что модели плохо работают в реальных условиях или их функциональность неприменима на практике.
Сейчас деплой моделей стал неотъемлемой частью процесса разработки и применения алгоритмов машинного обучения.
Любая, даже самая точная и сложная модель бесполезна, если она не интегрируется и не работает надежно в продакшен среде.
Деплой модели в продакшен
Не начинайте разрабатывать модель, пока не знаете, как будете ее деплоить.
Способ деплоя модели зависит от конкретной задачи и определяется бизнес-требованиями. Разберем основные.
1. Batch deployment

Предсказания модели рассчитываются с определенной периодичностью (например, ежедневно). Результат сохраняется в базу данных и легко предоставляется при необходимости.
Из недостатков - мы не можем использовать более свежие данные, и прогнозы могут очень быстро устареть.
Когда получение предсказаний на свежих данных становится критичным, имеет смысл уходить от пакетной обработки. Например, в этой статье AirBnB рассказывают, как постепенно перешли от batch-обработки к real-time предсказаниям.
2. Real-time
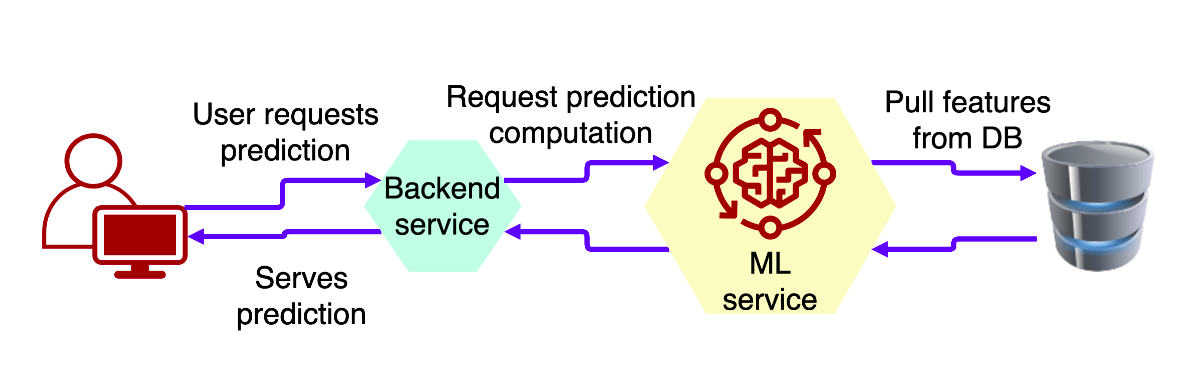
Real-time означает синхронный процесс, при котором пользователь запрашивает прогноз, запрос передается на бэкэнд-сервис посредством вызовов HTTP API, а затем передается в ML-сервис.
Этот способ отлично подходит, если вам нужны персонализированные предсказания, учитывающие недавнюю контекстную информацию, например, время суток или недавние поисковые запросы пользователя.
Узкое горлышко такого подхода в том, что пока пользователь не получит свой прогноз, бэкэнд-сервис и ML-сервис находятся в ожидании возвращения прогноза. Чтобы обрабатывать дополнительные параллельные запросы от других пользователей, вам необходимо полагаться на многопоточные процессы и вертикальное масштабирование путем добавления дополнительных серверов.
Примеры развертывания ML-сервиса в real-time: с использованием Flask и Django.
3. Streaming deployment
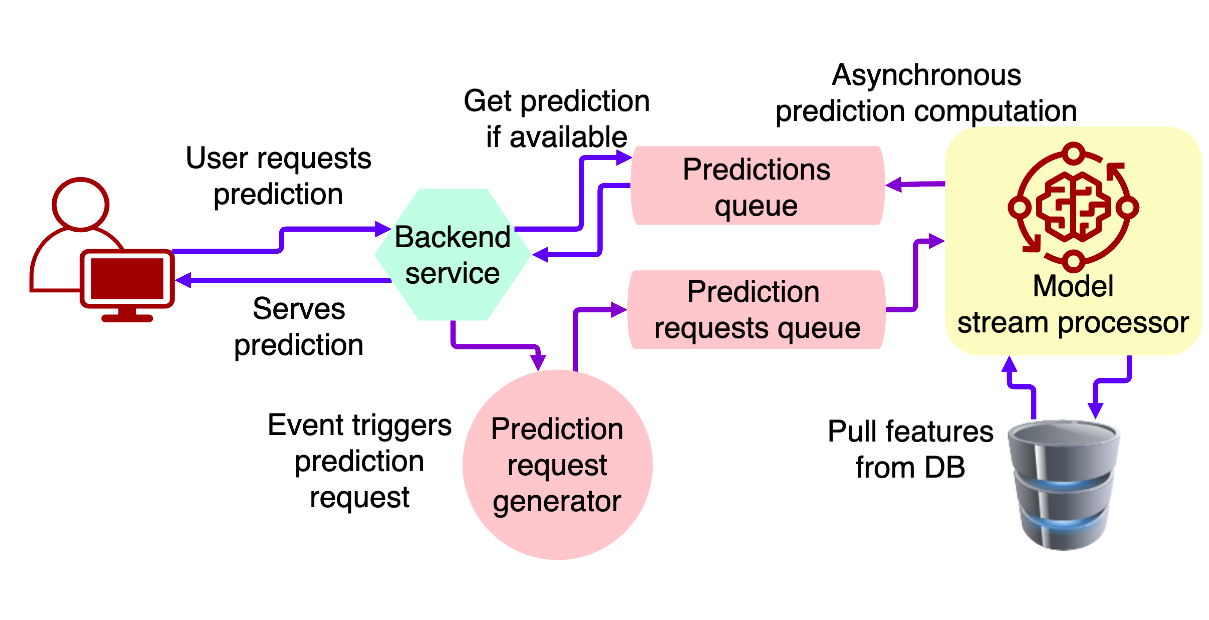
Этот подход позволяет использовать более асинхронный процесс. Действие пользователя может запустить расчет предсказаний. Например, как только вы заходите на страницу Facebook, начинается процесс ранжирования ленты. К моменту, когда вы будете скролить, лента будет готова к показу.
Процесс помещается в брокер сообщений, например, Kafka. Модель машинного обучения обрабатывает запрос, когда готова к этому.
Освобождает серверную часть и позволяет экономить вычислительные ресурсы благодаря эффективному процессу очереди. Результаты прогнозов также могут быть помещены в очередь и использоваться серверной частью при необходимости.
Туториал по Kafka: “A Streaming ML Model Deployment“.
4. Edge deployment

Модель напрямую развертывается на клиентском устройстве. Это может быть, например, смартфон или IoT.
Такой подход позволяет получать результаты модели быстрее, а также предсказывать офлайн - без подключения к интернету.
Для этого модели обычно должны быть достаточно компактными, чтобы поместиться на маленьком устройстве.
Например, вот туториал по развертыванию YOLO на iOS.
Архитектуры внедрения ML-пайплайна в real-time сервисы
Подробнее остановимся на особенностях внедрения моделей в случае real-time предсказаний.
1. Монолит
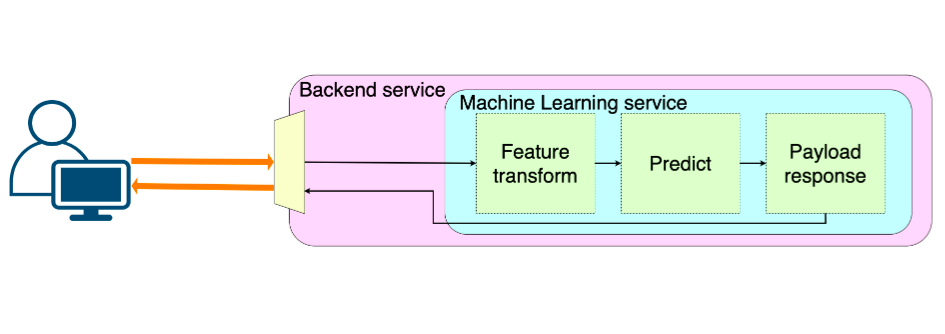
Кодовая база ML интегрирована в кодовую базу бэкэнда. Это требует тесного сотрудничества между ML-специалистами и владельцами кодовой базы бэкэнда. Процесс CI/CD замедляется из-за юнит-тестов сервиса машинного обучения, а размер модели и требования к вычислениям создают дополнительную нагрузку на серверы бэкэнда.
Такой тип развертывания следует рассматривать только в том случае, если инференс модели очень легкий для запуска.
2. ML как один сервис

Модель машинного обучения разворачивается на отдельном сервере, возможно, с использованием балансирования нагрузки в случае необходимости масштабирования.
Этот подход позволяет ML-инженерам деплоить модель независимо от команд, ответственных за бизнес-сервис. Создание систем мониторинга и логирования будет намного проще. Структура кодовой базы будет более понятной. Модель может быть сложной, не нагружая остальную инфраструктуру.
Обычно это самый простой способ развернуть модель с обеспечением масштабируемости, поддерживаемости и надежности.
3. Микросервисный подход
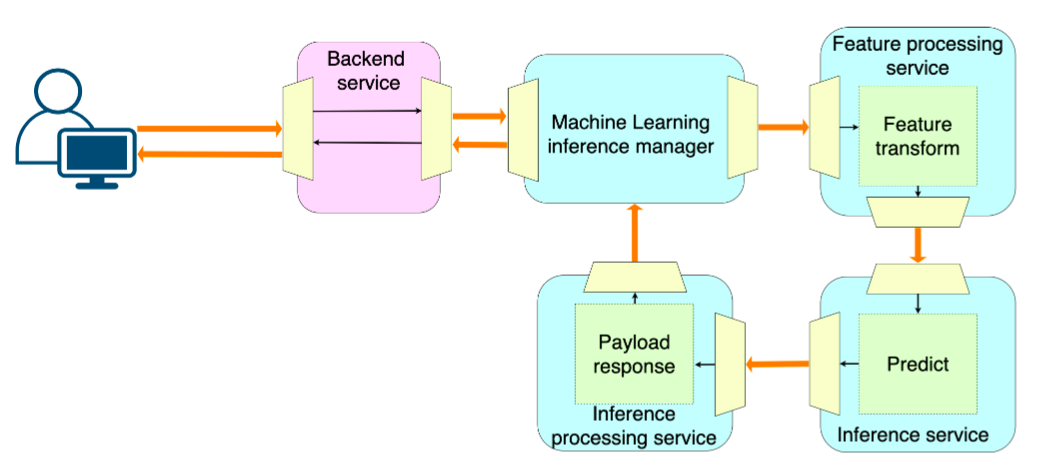
Каждая часть пайплайна получает свой собственный сервис. Этот подход требует высокий уровень зрелости в области ML и MLOps.
Такой подход может быть полезен, например, если компонент обработки данных используется несколькими моделями. Например, у нас может быть несколько моделей, которые ранжируют рекламу в разных поддоменах (реклама на Facebook, реклама в Instagram и т. д.). При этом они должны следовать одному и тому же процессу аукциона. Тогда эта часть пайплайна может быть обработна отдельным сервисом, отвечающим за аукцион.
Важно использовать сервис для оркестрации, например, Kubernetes, для обработки возникающей сложности микросервисов. “Dependency Hell in Microservices and How to Avoid It“
Тестирование модели в продакшене

Как можно скорее запускайте ваши модели машинного обучения в продакшен. Во-первых, модель, которую не задеплоили, не приносит дохода. Во-вторых, только на проде можно действительно протестировать модель.
Когда дело доходит до тестирования модели в продакшене, не стоит выбирать один метод, чем больше, тем лучше!
1. Shadow deployment
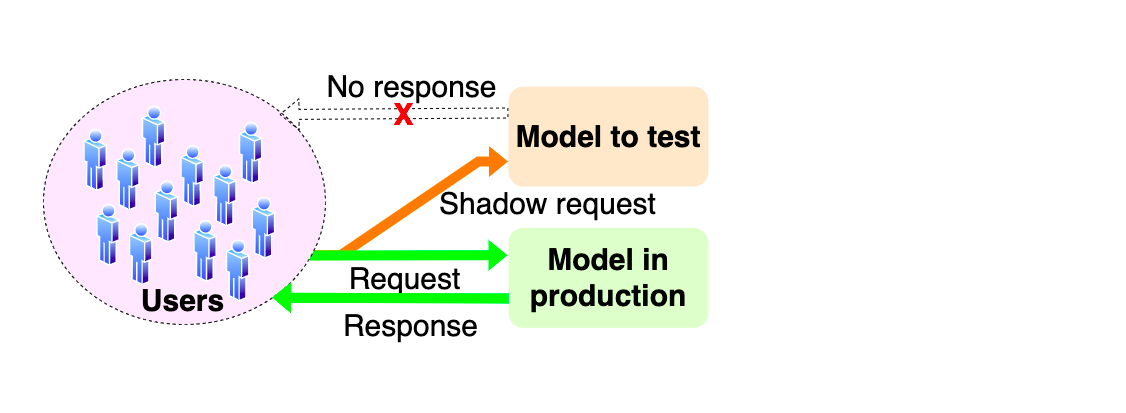
Shadow-режим используется для проверки того, насколько правильно отрабатывает новая модель в продакшене.
Когда пользователи запрашивают предсказания модели, запросы отправляются и на модель в продакшене, и на новую модель-кандидата. Но пользователи видят только ответы модели в продакшене.
Shadow-режим - это способ тестирования запросов модели и проверки, что распределение предсказаний схоже с тем, что было на этапе обучения. Он помогает проверить сервисную часть перед релизом модели на пользователей.
Не позволяет полноценно оценить работу новой модели в проде из-за влияния работающей модели.
2. Canary deployment
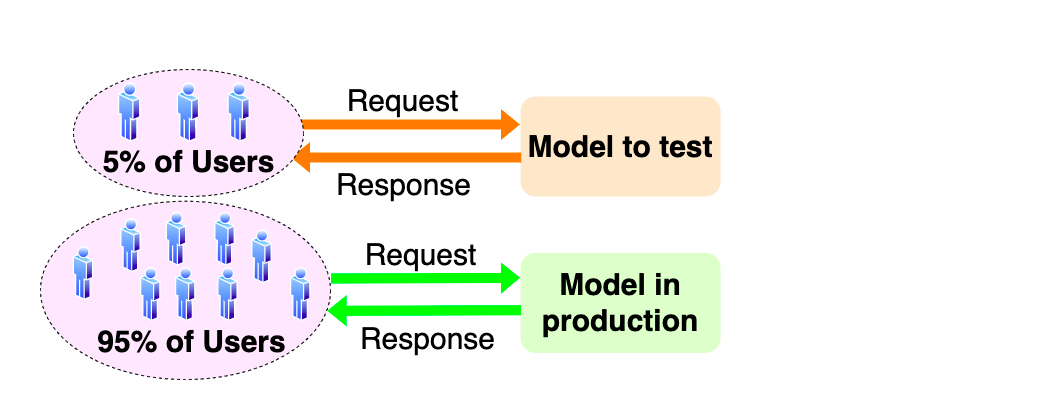
Canary deployment - это следующий шаг: end-to-end тестирование рабочего пайплайна.
Ответы модели выводятся только на небольшую группу пользователей или только на внутренних сотрудников компании.
Это похоже на интеграционное тестирование в продакшене.
Не говорит нам ничего о качестве модели.
3. А/В тестирование
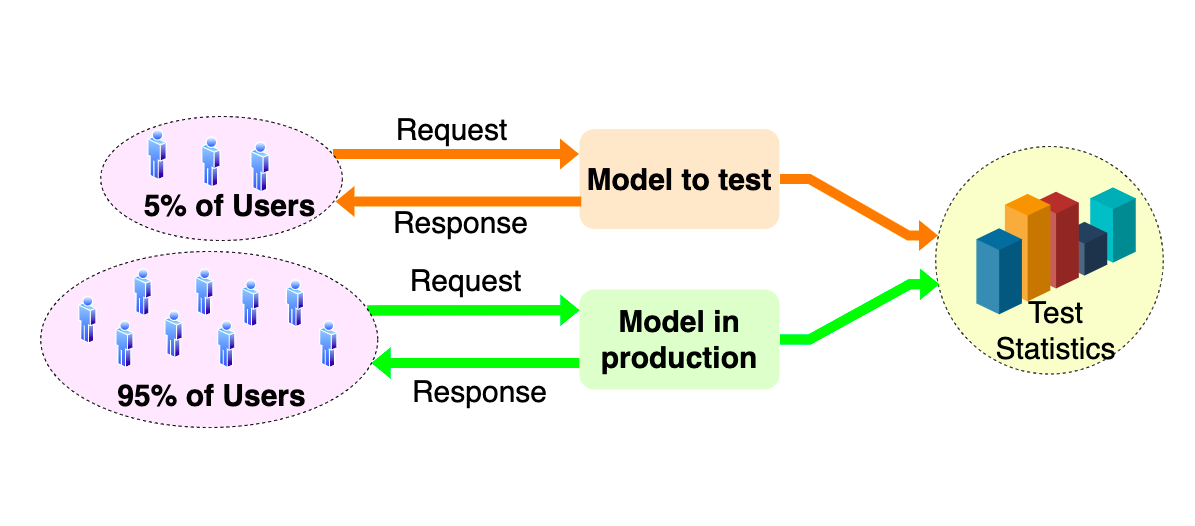
На этом шаге идет проверка качества модели. Обычно используются бизнес-метрики, которые сложно измерить в оффлайн-экспериментах, например, выручка или пользовательский опыт.
Небольшой процент пользователей получает предсказания новой моделью.
Метрики пользователей с новой моделью сравниваются с метрикам пользователей с основной моделью. Для строгой проверки гипотез используется мат статистика.
4. Многорукие бандиты

Размер группы пользователей адаптируется на основе фидбека о работе модели.
Это типичный подход в обучении с подкреплением: вы исследуете различные варианты и выбираете тот, у которого лучше результаты. Если акция в вашем портфеле приносит больше дохода, не хотели бы вы купить больше этих акций? Идея в том, что качество работы разных моделей может меняться со временем и вам может потребоваться больше или меньше полагаться на ту или иную модель.
Не обязательно ограничиваться двумя моделями - можно использовать сотни моделей одновременно.
Многорукие бандиты могут быть более эффективным решением с точки зрения использования данных, чем традиционное A/B-тестирование: “ML Platform Meetup: Infra for Contextual Bandits and Reinforcement Learning“.
5. Interleaving - Объединение моделей

Показываем пользователям предсказания обоих моделей и смотрим, что выберет пользователь. Например, в один список объединяются результаты работы двух поисковых систем или систем рекомендаций товаров. Пользователь сам выбирает.
Недостаток заключается в том, что вы оцениваете только предпочтения пользователя, не имея возможность оценить другие, потенциально более важные показатели KPI: “Innovating Faster on Personalization Algorithms at Netflix Using Interleaving”.
Больше о тестировании можно почитать в книге "Designing Machine Learning Systems".
Заключение
Сегодня мы разобрали важную составляющую работы с моделями машинного обучения: как довести модель до реальных пользователей.
Рассмотрели 4 подхода по деплою модели в продакшен в зависимости от бизнес-требований и технических ограничений.
Разобрали 3 разные практики внедрения пайплайнов машинного обучения.
Рассмотрели 5 разных способов тестирования новых версий модели в продакшене. В частности, мы разобрали "безопасное" тестирование модели в проде перед раскаткой на пользователей и альтернативы A/B-тестированию.
Мой телеграм‑канал о машинном обучении.

