public WriteGitFlowProcessArticle() { Console.WriteLine("Author: https://github.com/paulbuzakov"); Console.WriteLine("Hi, There!!!");
В этой статье я хотел бы затронуть тему хранения кода в Git, контроля версий, релизов и в целом как этим всем управлять в команде.
Существует множество моделей хранения кода, но многие из них не имели место на существование заранее, так как решали довольно конкретные задачи, или не масштабировались, или были слишком неудобными, или вообще состояли из одной ветки. Судя из названия статьи, я хочу рассмотреть GitFlow модель в контексте того, как мы применяем ее на практике в нашем проекте.
GitFlow Workflow подробно описал еще в 2010 году Vincent Driessen в своем блоге. С тех пор прошло много времени, созданы более модные «магистральные» модели доставки. Их принято считать более простыми с точки зрения простоты доставки на прод, но я уверен — они подойдут не для всех проектов.
Что бы не быть просто «диванным специалистом» из интернета немного расскажу о себе. Я.Net программист, немного касающийся React, TypeScript (сейчас фронтовая разработка мне нравится больше), а так же тим лид команды в одной из федеральных фармацевтических компаний. У меня 14 лет коммерческого опыта разработки, в том числе создание облачных сервисов и программных продуктов для федеральных банков, фарм компаний, фондового рынка, иностранных компаний, гос органов и тд.
На этапе проектирования абсолютно нового проекта у нас, как раз, возник вопрос хранения кода. В такие моменты хочется сделать все идеально и поэтому мы погрузились в этот вопрос. Входные данные были не очень — в других проектах компании был Svn, мы были первой командой которая перетащит всю кодовую базу в Git (пора бы, как никак 2020 год был уже =)) и по началу мы решили сами выдумать модель версионирования (ее я рисовал в этой статье), но выдумка была сложной.
Почему GitFlow?
… выдумка была сложной!!!» — поэтому мы обратились к интернету — он все знает и ведает. GitFlow Workflow стал для нас оптимальной моделью.
У нас было 12 разработчиков и мы часто пересекались в задачах друг с другом. Одной большой задачей могли заниматься до 3х человек, и без комита от каждого из них мы не могли заливать задачу в целом на тестирование — это попросту не имело смысла.
У нас была не потоковая сдача функционала, а итеративная — двух‑трех недельная.
У нас были задачи очень привязанные к сроку релиза в гос органах, то есть фича ветки могли просто лежать по месяцу без движения в прод.
У нас попросту не была реализована эта потоковая доставка функционала на последующих этапах.
Что же такое GitFlow?
GitFlow — это определенная надстройка над моделью ветвления Git, которая включает в себя использование фича веток и несколько основных веток. По сравнению с разработкой на основе «магистрали», GitFlow имеет многочисленные, более долгоживущие ветки и более крупные фиксации. В рамках этой модели разработчики создают фича ветку и откладывают ее слияние с основной веткой до тех пор, пока функционал не будет завершен. Эти долгоживущие фича ветки требуют большего сотрудничества для слияния и имеют более высокий риск отклонения от ветви магистрали. Они также могут вводить противоречивые обновления.
Давайте рассмотрим схему веток и их взаимодействие между друг другом из самого первоисточника, как это представлял сам автор.
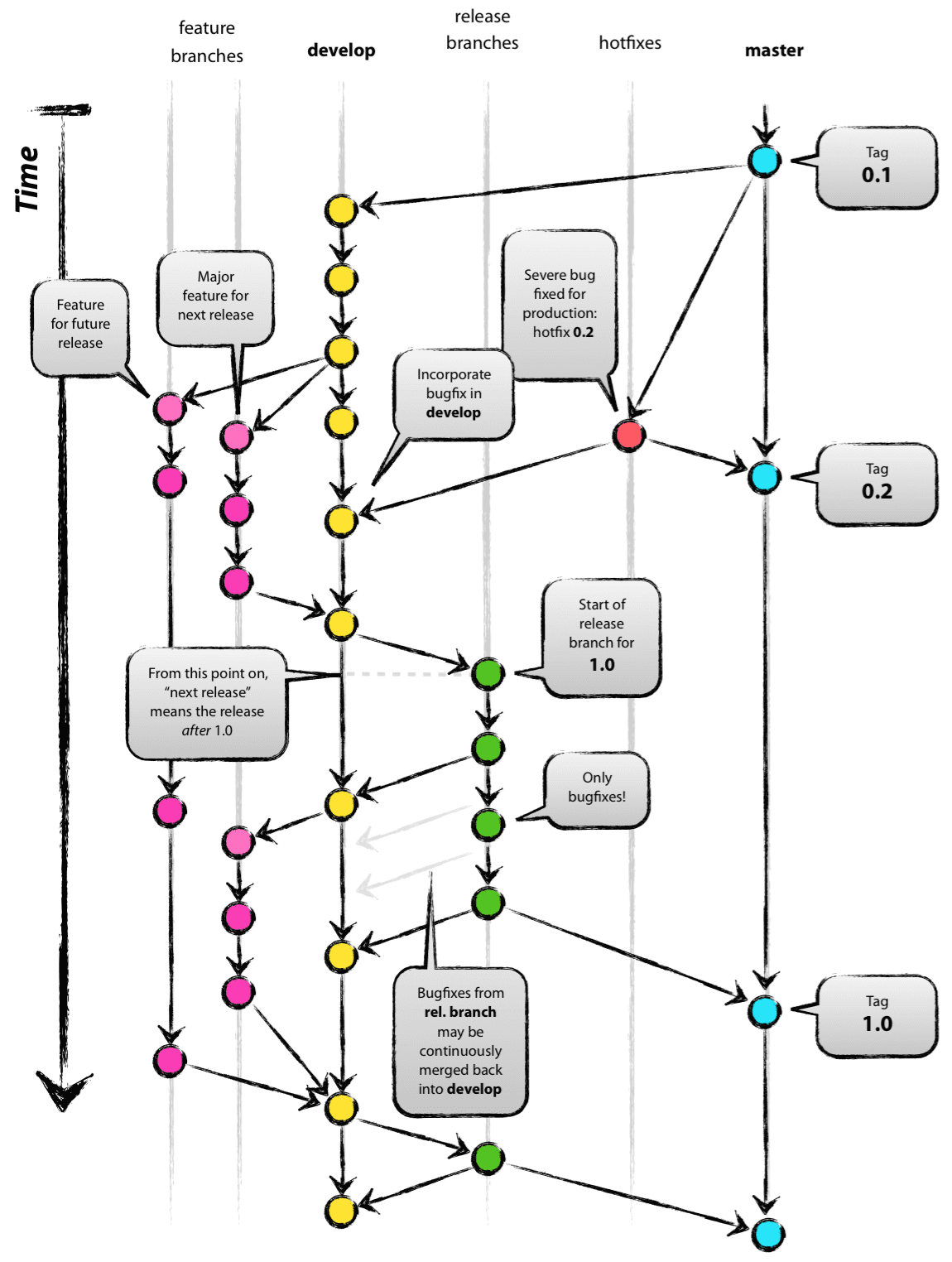
В нашей версии модели начинают фигурировать еще и разработческие ветки, созданные от фича веток, то есть у фича веток может быть много разработческих ветвлений и существовать они будут до тех пор пока фича не сольется куда-то дальше по процессу.
feature/task-1 => dev/task-1/buzakov
Но по сути, если отбросить все условности, то модель разработки GitFlow заключается между 2х постоянных веток:
master (стабильно работающая или продакшен версия кода)
develop (последняя или «nightly»-версия кода)
master branch (main branch)
После определенных событий в мире - ветку master переименовали в main.
main — это основная ветка кода, продакшен версия кода, то есть все сборки для реальных клиентов собирают как раз из этой ветки. Ветка может быть помечена тегами, в которых есть информация о версии и часто к тегу еще привязываются релизы. Любая новая задача взятая в работу начинается с мастер ветки. Немного позже, я раскрою наши поведенческие паттерны работы с веткой main.
Суть этой ветки хранить самую последнюю работоспособную версию кода.
develop branch
Я бы назвал эту ветку, как основная ветка кода для тестировщиков, но меня закидают камнями.
Исходя из практического опыта программисты не часто работают с этой веткой, а большую часть времени с ней проводят, как раз тестировщики анализируют функционал на работоспособность и наличие багов, а программеры просто сливают в нее новый код.
Суть этой ветки просто хранить в себе самую последнюю кодовую базу проекта.
Работа с ветками
Сейчас я бы хотел рассмотреть некоторые стандартные кейсы в GitFlow процессе разработки:
Разработка нового функционала
Исправление ошибки в новом функционале после тестирования
Создание новой версии релиза
Исправление критической ошибки на продакшене
Разработка нового функционала
Допустим у нас на проекте есть некая новая задача (MW-1234). Давайте рассмотрим этапы работы с этой задачей от взятия в работу и до релиза.
Создаем фича ветку из main (main ⇒ feature/MW-1234). Если над этой задачей работают еще программисты, то я бы посоветовал от фича ветки создать еще разработческие ветки на каждого разраба (main ⇒ feature/MW-1234 ⇒ dev/MW-1234/buzakov). Это важно особенно в тех случая, когда ваш комит в фича ветку бесполезен без комитов других разработчиков.
Разрабатываем функционал и заливаем комиты в фича ветку или разработческую ветку, созданную от фича ветки.
Проверяем код и тестируем функционал в фича ветке.
Создаем pull‑request в develop ветку.
Когда тестировщики проверили функционал в дев ветке создаем релиз и мержим в мастер
Выпускаем новую версию кода
Бранч менеджмент:
main(tag: 0.1.0) => feature/mw-1234 => dev/mw-1234/buzakov => feature/mw-1234 => dev => release/0.1.1 => master(tag: 0.1.1)
Исправление ошибки
Если тестировщик в процессе проверки задачи находит ошибки, то программист исправляет их в dev/mw-1234/buzakov ветке и заливает дальше по веткам, как при мерже веток в предыдущем варианте, то есть бранч менеджмент у нас такой:
dev/feature/mw-1234/buzakov => feature/mw-1234 => develop => дальше по процессу...
Исправление критической ошибки
Ну вот мы и выпустили новую версию, посидели порадовались и поехали домой, но звонит начальник и говорит, что нашли критичную ошибку, а последний код уже в main ветке.
Что делать?
Мы создаем из main ветки hotfix («быстрофикс») ветку, то есть main ⇒ hotfix/error-123. Исправляем ее и заливаем комит в эту «быстрофикс ветку», тестируем еще раз, что не наломали еще больше дров и сливаем в main. Получается следующая схема:
main(tag: 0.1.1) => hotfix/error-123 => main (tag: 0.1.2)
Хотфикс — залит в мастер.
Прод — работает.
Все хорошо.
Выводы
«GitFlow процесс очень трудоемкий и местами запутанный» — я соглашусь с многочисленными хейтерами оного, но он позволяет закрыть 2 пунка стабильности: 1. продакшен версия кода более стабильна, чем при водопадных слитиях; 2. тестовый стенд работает стабильнее, так как программисты сливают свой код в фича ветки, и случаев типа «Ой, я думал ты слил, а Я думал ты не слил уже» практически не бывает. При магистральных поставках осознанность и компетентность команды должна быть на высоком уровне, что в текущих реалиях вообще не возможно. За последний год у меня было 90 собеседований с программистами разного уровня паршивости — и я уже давно не встречал трушных программистов, которые имеют знания на высоком уровне.
В заключении этой статьи еще хочется напомнить поговорку «научи дурака молиться — он себе лоб расшибет». К чему это я? GitFlow, или магистралая доставка, или GitHub Flow, или еще тысяча другая подобных схем разработки и доставки кода на прод — все хорошо работают, не надо усложнять там где можно сделать проще и всегда думайте перед началом работы над новой задачей, но не упарывайтесь в бессоные ночи и поиски идеала.
В любой из перечисленных моделей разработки есть, как плюсы, так и минусы. Идеальная модель для большого проекта может совсем на подойти маленькому стартапу.
return 1; }

