
Бэклог багов: делаем понятную организацию и держим всегда актуальным
Всем привет, я Глеб, работаю хедом QA в Mayflower.
Сегодня поговорим про такую важную штуку как бэклог багов. Представьте: вы выходите на новую работу (тестлидом, менеджером тестирования, а, может тестировщиком или даже продактом/проджектом), начинаете знакомиться с людьми и процессами, открываете Jira, а там бэклог из 300 открытых багов! Ваша реакция логична: недоумение, отчаяние и боль от увиденного.
«Ну ничего, – думаете вы, – это же как раз то, зачем я нужен этой компании, сейчас я им всё пофикшу!»
Вы начинаете разбор полётов и выясняется, что:
самый древний открытый баг имеет срок давности 3 года;
из всех багов большинство medium, 100+ high и остальные – low приоритета;
никто не понимает, какие баги в этом в бэклоге, причем в первую очередь, не понимают продакты;
проджект, готовящий спринты, говорит, что обычно место в спринтах находится только под 3-4 high бага, а до всего остального руки не доходят;
тестировщик в шоке от того, что заведённый им high баг уже полгода не фиксится.
Следом рождаются закономерные вопросы:
Стоит ли разгребать бэклог или лучше закрыть его целиком и заводить баги с нуля, если они будут снова обнаружены?
Какое количество открытых багов в бэклоге – нормальное состояние, а какое уже нет?
Как информировать продактов о состоянии бэклога и надо ли это вообще делать?
Моя статья ровно про эту ситуацию: как навести порядок в бэклоге багов, превратив его в понятное и организованное пространство.
Дисклеймер №1: Данная статья не про Zero Bug Policy, но про начало пути к ней, про переход к ментальности «не делаем, значит, не нужно».
Дисклеймер №2: В данной статье мы не говорим про критические баги, блокирующие пользователей от использования продукта. Их надо фиксить асап без занесения в бэклог.
Пара слов про Zero Bug Policy: когда хочется, но колется
Идея ZBP изящна: если мы что-то не хотим чинить прямо здесь и сейчас, значит, эта проблема для нас не важна. Этот подход может быть достаточно ультимативным: если мы решили не фиксить баг сейчас — мы его закрываем. Самый очевидный бонус такого подхода — это отсутствие бэклога багов как такового.
Стоит признать, что далеко не каждый продакт-оунер согласится перейти на такой флоу работы сразу после привычного флоу с большим бэклогом багов. Ведь в таком случае, как в моем примере выше, сначала придётся что-то сделать с 300 багами. А потом постоянно учитывать реальные данные пользователей, грамотно анализировать зааффекченных пользователей и так далее.
Держа в уме идею ZBP, продолжим размышления на тему чистоты бэклога и как к ней прийти.
Что не так с бэклогом в 300 багов? Резюмируем проблему
А плохо ли на самом деле иметь 300 открытых багов? Давайте порассуждаем.
Плюсы:
Тестировщики и другие участники команды нашли баги и честно зарепортили – и это круто! Команда находит проблемы и фиксирует их.
Минусы:
Большая Unknown Territory. Никто не знает, что в этих 300 тикетах (если, конечно, у вас нет постоянного ревью бэклога багов). Есть шанс, что в бэклоге есть мега-важные проблемы, которые при обнаружении и создании тикета затрагивали пару юзеров, а теперь стали чем-то более массовым, но не уровня critical.
Неоднородность бэклога. Всё лежит в одной куче внутри каждого из приоритетов (попробуйте отсортировать по важности 100 high багов). Сложно принять решение, что из этого фиксить сейчас, а что потом. Не мне вам рассказывать, что ресурс на починку багов в спринтах не резиновый, поэтому всегда надо выбирать, на что его расходовать.
Прирост популяции бэклога. Сейчас у вас 300 багов в бэклоге, а через год-два будет 1000 и больше. А потом? Это очень серьезный масштаб, на котором вообще непонятно как действовать.
Дополнительные ресурсы на перепроверку багов. Чтобы гарантировать валидность багов в бэклоге, их приходится периодически актуализировать. А это дополнительное время на их воспроизведение и закрытие воспроизводимого.
Можно было бы проводить технические спринты и растаскивать весь этот бэклог пару раз в году. Но даже в этом случае просто представьте себе, сколько ресурса понадобится и каким количеством бизнесовых задач придется пожертвовать.
Автоматизированный бэклог багов: фокус на важном, в топку неважное
Статичный бэклог багов не устраивал нашу команду. Мы принялись искать автоматическое решение, которое позволит фокусироваться на действительно важных багах и поможет постепенно избавиться от неважных (всё ещё помните про идею ZBP?).
Четыре элемента автоматической системы:
Приоритизация. Система приоритизации багов, позволяющая учитывать priority, severity и сравнивать баги друг с другом.
Учёт. Система, учитывающая обратную связь от пользователей.
Автоматизация жизненного цикла бага. Автоматическое понижение приоритета бага через определенный срок и последующее закрытие.
Информирование. Автоматическое информирование участников процесса о статусах багов.
Первый элемент. Приоритизация
Priority, severity
Если вы хотите автоматическую чистку бэклога, вам надо придумать систему понижения приоритета багов. И сначала хочется поговорить про само понятие приоритета.
На моем проекте, когда тестировщик или саппорт создает баг, он обязательно указывает ему priority. У нас это поле комбинирует в себе приоритетность починки проблемы с точки зрения бизнеса (по теории тестирования ПО, priority) и то, как эта проблема затрагивает функциональность (по теории тестирования ПО, severity).
Для нас, приоритет – гибридное поле, подразумевающее оба показателя сразу. Для того чтобы уточнять важность конкретного бага в сравнении с другими мы переиспользовали показатель RICE. Он выставляется продактом для багов, и учитывает в себе реальное воздействие на пользователя и важность проблемы в цифровом виде. Это и позволяет сравнивать по важности два бага между собой, но об этом позже, в блоке про RICE.
Разумеется, у вас может быть другой процесс и вы можете работать с severity и priority иначе.
RICE для багов
Для приоритизации продуктового и технического бэклога мы используем фреймворк RICE, который решили применить и к бэклогу багов. Наша вариация RICE имеет несколько изменений для нашего удобства, но смысл остается прежним – это единое мерило важности тикета относительно других, упрощающее приоритизацию бэклога.
В нашей интерпретации RICE для багов:
R – Reach, охват – как много пользователей затрагивает проблема;
I – Impact, насколько с функциональной точки зрения проблема серьезна для опыта пользования продуктом;
C – Confidence, уровень уверенности в том, что оценка масштаба проблемы для пользователей (Impact) и сложности (Ease) корректна;
E – Ease, простота – насколько просто починить проблему.
Каждый из показателей, кроме Ease, имеет диапазон от 1 до 5, где 1 – наименьшее значение показателя (наименьший охват пользователей, наименьшее влияние на опыт использования продукта и тд), а 5 – максимальное. Ease определяется иначе, для него нужно посчитать временной эстимейт на фикс – чем больше времени надо на правку, тем меньше Ease:
Шкала | Время в часах |
5 | 1-4 |
4 | 5-16 |
3 | 17-32 |
2 | 33-64 |
1 | 64+ |
Перемножаем коэффициенты между собой и получаем финальный RICE бага.
Рассмотрим два бага:
Баг 1: Reach(1) x Impact (5) x Confidence (5) x Ease (3) = 75
Баг 2: Reach(1) x Impact (4) x Confidence (5) x Ease (5) = 100
В примере выше фикс бага №2 для нас важнее, чем фикс бага №1. Таким образом, продакт и проджект точно знают, какой баг стоит взять в текущий спринт.
Процесс проставления RICE
Процесс проставления RICE для багов выглядит так:
QA/саппорт создают баг с high/medium/low приоритетом (у нас есть описанная классификация и договоренность о том, какие баги мы считаем high/medium/low приоритетом в зависимости от затронутой функциональности, платформе воспроизведения бага и тд);
Баги с high приоритетом попадают на продактов, которые проставляют таким багам RICE;
Багам с medium или low приоритетами RICE не проставляется. Мы фокусируем своё внимание на растаскивании high багов и, пока есть поток high багов, будем разгребать и чинить именно их. Но в дальнейшем планируем применить эту систему и к остальным багам.
Второй элемент. Учёт обратной связи от пользователей
Мы разрабатываем высоконагруженный стриминг-сервис с миллиардом посещений в месяц и более чем 100 миллионами зарегистрированных пользователей. Чтобы лучше понимать масштаб проблемы, стоящей за багом, нам важно собирать количественный фидбек от пользователей.
Для этого мы ввели поле number of reports, которое показывает количество обращений по конкретному багу и помогает продакту выставить правильный RICE для него. Поле актуализирует наш саппорт на основе данных из Zendesk.
Итак, продакт видит конкретное значение обращений в high баге и учитывает это при выставлении RICE (это отобразится на выставляемых Reach и Impact).
Но что делать, если на момент создания бага ещё нет обращений, но они появились потом? Мы ведь должны пересмотреть RICE с учетом актуального количества обращений?
Конечно, должны. И вот как мы это делаем:
Внутри проекта мы договорились о порогах для количества обращений – например, первый порог в 10 и более (но меньше 30) обращений, а второй в 30 и более обращений;
Как только для любого бага достигается порог, продакт соответствующей области функционала автоматически информируется о количестве обращений и в этот момент он может пересмотреть RICE для бага или решить ничего не менять.
Отмечу, что для нас 10 и 30 обращений как пороги были выбраны эмпирическим путём. Если мы поймём, что такие пороги в большинстве случаев не влияют на изменение приоритета проблемы продактом, мы будем их пересматривать.
А что делать, если обращений добавлено менее 10, или если продакт забыл проставить RICE с учетом количества обращений выше порогов? Для этого мы сделали автоматический сброс RICE у high бага раз в 3 месяца. Продакт увидит, что у него в выборке есть high баг без RICE, и актуализирует его. В противном случае, ему это подсветит проджект или я, как холдер всего процесса.
Таким образом, мы учитываем реальную информацию от пользователей, и она влияет на то, какой баг мы возьмем в спринт, а какой спокойно поедет по флоу понижения приоритета, о котором я сейчас и расскажу.
Третий элемент. Автоматизация жизненного цикла бага
Мы для себя определили так: если баг не фиксится в течение года, значит, его либо потеряли, либо он неважен для продактов и пользователей и чинить его не нужно.
Развиваем тему дальше:
Если high баг 6 месяцев не фиксится, значит он не настолько уж high, и его можно понизить до medium (в случае, если продакт не считает иначе);
Если medium баг 3 месяца не фиксится, маловероятно, что мы его пофиксим позже (если продакт не считает иначе и нет обращений от пользователей), и мы понижаем его до low;
Если low баг 3 месяца не фиксится, маловероятно, что мы его пофиксим позже, ведь есть важные high, а потом medium – ну вы поняли – если продакт не считает иначе и нет обращений от пользователей, закрываем баг.
Весь процесс понижения и закрытия мы автоматизировали через самописное решение Automaton, которое мы интегрировали в наш slack. Automaton – наш внутренний инструмент для любых автоматизаций, он держит в себе всю необходимую логику, с Jira работает через api и отображается как бот в истории тикета.
Суммируем все сроки выше и получаем годовой жизненный цикл бага. Правила выше – это наш флоу автоматизации ЖЦ багов (напомню, кроме critical багов). Исключения, когда продакт по какой-то причине не согласен с понижением приоритета и ЖЦ может быть увеличен, тоже необходимо учесть, о них ниже.
Сценарий №1
Продакт ревьюит список планируемых к понижению приоритета medium или закрываемых low багов (за неделю до понижения)
Если продакт хочет задержать баг в текущем приоритете, он выставляет ему RICE. Подчеркну, что у нас также есть цифровая граница по RICE для приоритетов medium и high. Механику расскажу в блоке про границу приоритетов.
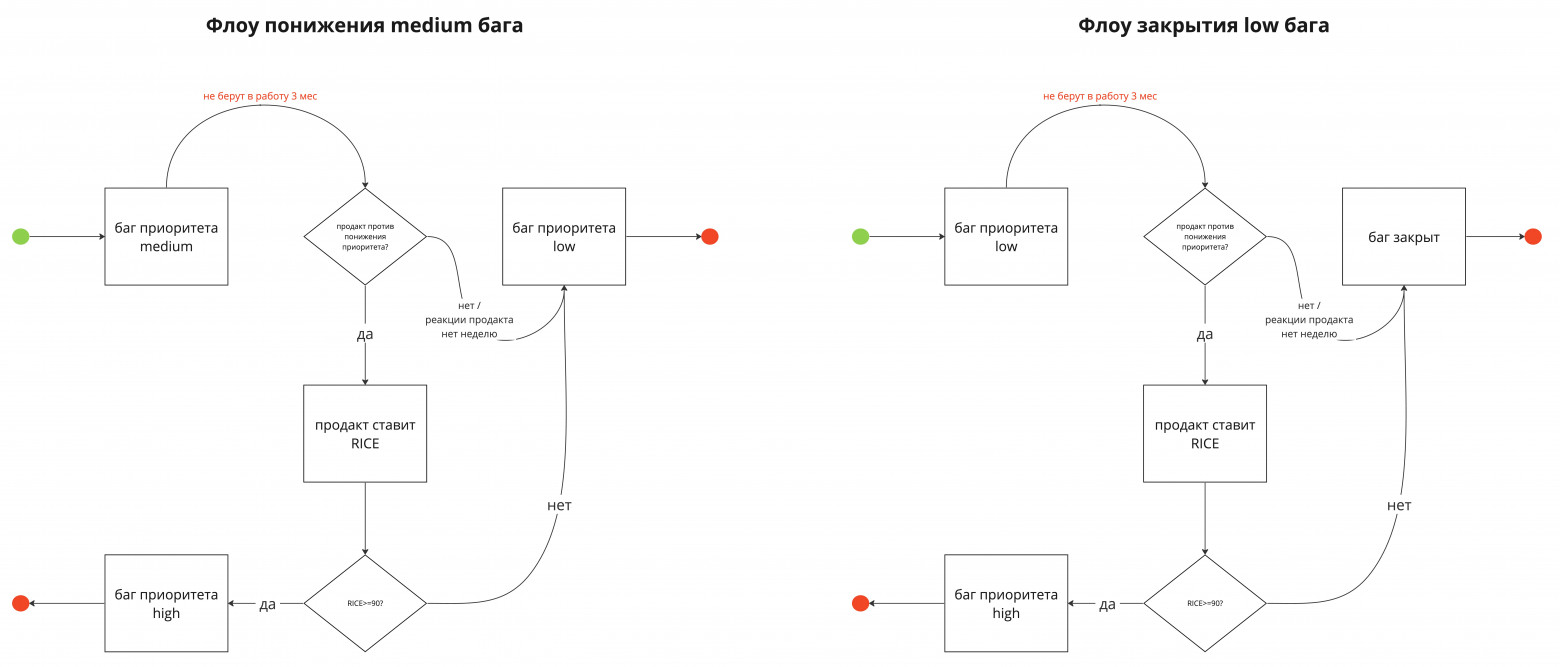
Если выставленный RICE попадает выше или по границе RICE для high приоритета, то баг переводится в приоритет high и попадет на флоу понижения high багов через 6 месяцев.
Если выставленный RICE оказывается ниже границы RICE для high приоритета, то у бага остается текущий приоритет, и он либо будучи medium понижается до low, либо будучи low, закрывается.
Сценарий №2
Продакт ревьюит список планируемых к понижению приоритета high багов

Если продакт хочет задержать баг в high приоритете, он должен проставить ему запрет на понижение приоритета, который будет держаться полгода. Мы оставили эту опцию для продакта и мониторим, чтобы ей не пользовались слишком часто – пока что у нас был только один такой кейс. Запрет выставляется через поле в jire, на котором настроен таймер. Пока не пройдет полгода, баг не будет попадать в выборку на понижение приоритета.
Если вас все еще беспокоит факт закрытия существующего бага – то вы не прочувствовали полностью философию Zero Bug Policy: не фиксим — значит не будем, поэтому не держим в бэклоге вечно.
Граница приоритетов по RICE
Как я уже вкратце упомянул, мы ввели цифровую границу по RICE между high и medium.
Посмотрите на вот эти два бага:
Баг 1: Reach(1) x Impact (5) x Confidence (5) x Ease (3) = 75
Баг 2: Reach(5) x Impact (5) x Confidence (5) x Ease (4) = 500
Наблюдение №1
Когда мы предложили продактам проскорить имеющиеся 100 high багов в бэклоге, мы заметили, что часть багов получили гораздо более низкую оценку, чем остальные. Как видно на примере выше, RICE бага №1 почти в 7 раз меньше бага №2.
Наблюдение №2
Среди 100 high багов часть слишком долго ждут починки, поэтому некорректно называть приоритет таких багов high: они не берутся на фикс уже долго и имеют RICE сильно ниже остальных high багов.
Решение – ввести границу для низко оцененных багов.
Мы остановились на интуитивной границе в RICE = 90: если баг от 90 и более, то он high, если же ниже, то не high.
При внедрении границы можно поступить более технично: посмотреть срезы по 70 перцентилю для оценки RICE для всех high багов и сопоставить с тем же перцентилем срока ожидания бага фикса. А можно выбрать интуитивно и отладить цифру на ходу.
Четвёртый элемент. Информирование участников процесса
Автоматическая система уведомлений участников процесса — must have. Она поможет поддерживать самостоятельную работу всего процесса. С вашей стороны останется минимальный контроль фильтров и проверка багов.
Как настроили систему мы, и как я рекомендую сделать вам:
Создайте отдельный канал в slack (или в другом рабочем мессенджере) для уведомлений. Добавьте туда участников процесса – продактов, проджектов, QA менеджеров.
Настройте уведомления в этом канале на каждую часть процесса:
2.1. Публикация выборки планируемых к понижению приоритета / закрытию багов + тег соответствующего продакта (за неделю до понижения приоритета).
2.2. Автоматическое информирование продактов о понижении / закрытии бага (как только понижена / закрыта эта выборка багов).
2.3. Автоматическое информирование о сброшенном RICE соответствующего продакта (если прошло 3 месяца с момента проставления RICE для high бага).
2.4. Автоматическое уведомление продакта о багах, достигших порога по полю обращений от пользователей.
За автоматизацию информирования у нас также отвечает Automaton, о котором я написал раньше. В общем, делаем прозрачным и автоматическим всё, что возможно.
Финальная схема процесса автопонижения и закрытия багов
Система приоритизации багов + сбор фидбека пользователей + автоматизация понижения приоритета + система уведомлений = единый процесс управления бэклогом багов. На схеме ниже отображены все составные части процесса и видно их взаимодействие друг с другом.

Судьба 300 багов
Вы, вероятно, заметили, что я рассказываю про дизайн процесса, но не говорю, удалось ли нам разгрести имеющийся бэклог из 300 багов.
Да, удалось. Сначала мы вручную проводили максимально старые баги через ревью продактов (порциями по 10 багов в неделю). Когда осталось 30 багов, мы запустили автоматический процесс по всем правилам, описанным выше.
Мы начали разгребать бэклог багов по описанному флоу в августе 2022 года.
А что по цифрам?
Всего закрыли 297 багов, из которых:
24 high бага – стали medium, затем low и потом закрылись;
267 medium багов – стали low, затем закрылись;
6 low багов – закрылись.
Стоит признаться, что мы начали проводить high баги по флоу понижения приоритета только в августе 2023 года (то есть через год после запуска всего процесса). Нам самим потребовалось время, чтобы решиться на это и затем продать концепцию продакт-менеджерам.
А что по выводам?
Чистый бэклог – это про классные процессы, автоматизацию и майндсет. То, как вы работаете с бэклогом багов, влияет на многое – от общей морали команды до того, на что тратится ресурс в спринтах.
Ваши усилия по причесыванию бэклога приведут вас к тому, что ключевые баги ни в коем случае не будут упущены, ведь вы будете опираться на реальный фидбек пользователей и ревью продакт-менеджеров.
Желаю вам опрятного бэклога багов и классных процессов!

