На Хабре уже была новость об этом знаменательном событии. Правда, она похожа на пересказ официального пресс-релиза Microsoft, но такой и должна быть "новость".

Я же по какой‑то непонятной мне самому причине начал пробовать использовать Python внутри Excel раньше, несколько недель тому назад. Безуспешно. Не получилось вопреки всем моим усилиям: в начале подключился к Microsoft 365 Insider, Beta Channel — там опции не наблюдалось, затем загрузил add‑in от Excel Labs, Microsoft Garage project — фича, хотя и запустилась, но у меня не работала, постоянно возвращая ошибки.
И вот 12.10.2023 пришёл и-мейл с радостным известием и после обновления Office (уточняю - Microsoft 365 Insider, Beta Channel) в меню Formulas есть опция Python in Excel

ввод в командную строку
=PY(
приводит к превращению текущей ячейки в подобие ячейки Jupyter Notebook.
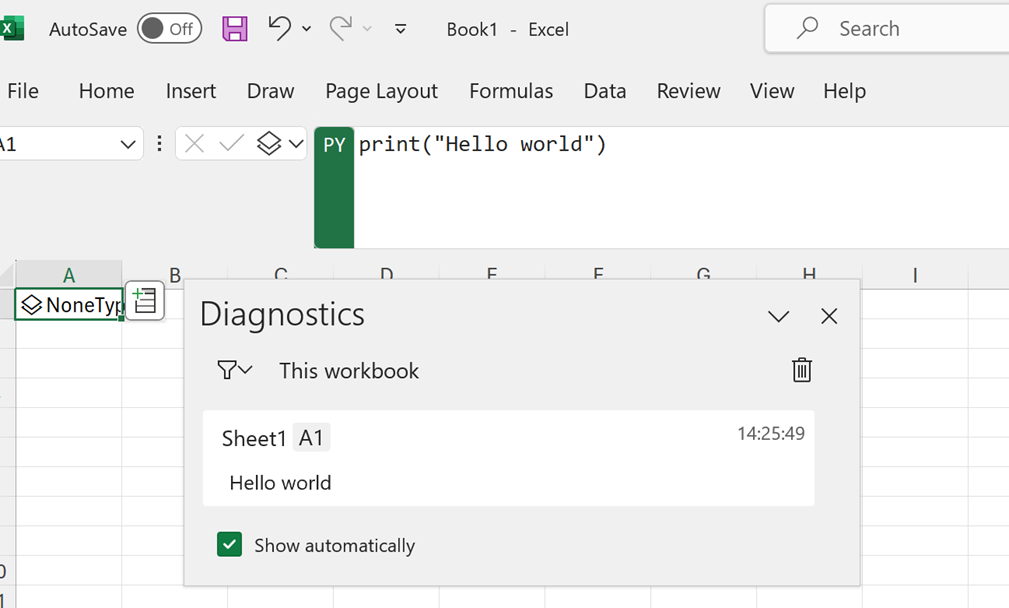
Как это работает
Код исполняется на серверах Microsoft.
Все что нужно сделать на локальном компьютере -- запустить Excel и ввести в ячейку уже знакомую нам волшебную комбинацию =PY( .
Затем можно вводить код. Конечно, же copy‑paste работает. Синтаксис — Python, с небольшой спецификой, если нужно обращаться к данным.
Команда Ctrl+Enter запускает код на исполнение.
Зачем он, Python, внутри Excel вообще нужен?!?
Это главный вопрос. И вопреки всем моим тяжелым размышлениям, ответа не нахожу, хотя и очень стараюсь.
Есть ли преимущества перед независимым использованием двух продуктов, обмениваясь при необходимости между ними данными? Возможно, такие преимущества и есть, но — со знаком вопроса. Большим и жирным знаком вопроса.
Например:
Можно обойтись вообще без установки Python.
Для простых задач, которые эффективнее решать кодом, чем встроенными инструментами Excel, не нужно плодить сущности: и код, и данные могут жить внутри одного файла.
Что‑то еще, мне неизвестное или не приходящее в голову.
Рассуждая трезво, ничего рационального здравому смыслу, требующему забыть о Python в Excel как о ненужной игрушке, я противопоставить не могу. Но! Прокрастинация и/или любопытство вынуждают разбираться с фичей и придумывать сценарии ее использования. Человек — слаб (я точно), не может устоять перед соблазнами.
Результатом моей слабости и стал этот материал.
Первое знакомство
По уже устоявшейся отвратительной привычке, вместо того, чтобы начать процесс с внимательного чтения релевантной страницы Microsoft, приступил к исследованию самым простым и эффективным из всех методов, а именно «методом тыка». Что, как часто это бывает, привело к нескольким часам метаний от одной элементарной ошибки к другой и пустой трате времени и нервной энергии. К счастью, и того, и другого у меня — с запасом, ведь я регулярно практикую осознанное дыхание.
Здравый смысл все же возобладал и — о чудо! — после знакомства с документацией (ссылки в подвале материала) ларчик открылся.
Как оказалось, то, что код исполняется на серверах Microsoft, имеет побочные эффекты: задержка по времени, нельзя устанавливать сторонние библиотеки, доступ к данным вне текущей рабочей книги — только через Power Query, нельзя сохранять данные вне текущей рабочей книги и т. д.

Плюс Python‑синтаксис — часто с поправкой на «жизнь внутри Excel». Например, чтобы присвоить переменной значение из ячейки В2 пишем x = xl(«B2»).
И, конечно, писать код внутри командной строки Excel — удовольствие для извращенцев. Хотя ничего не мешает писать в текстовом редакторе и затем copy‑paste. Со всеми «НО», большими и малыми.
Попробую на реальном жизненном кейсе.
Эпический фэйл
Со средины января этого, 2023, года у меня длится роман с Garmin, в частности, с его спортивными часами, мобильным приложением и личным кабинетом. Роман -- специфический (нет, нет, никаких девиаций!), требующий периодической обработки данных: каждую неделю я выгружаю и обрабатываю данные о тренировках, дыхательных упражнениях и т. п., а затем комбинирую с записями о пульсе в состоянии покоя и HRV. С задачей сейчас без проблем справляется написанный мной Python script, живущий в отдельном файле, но (здесь должна быть фраза про любопытство и прокрастинацию) я ведь решил разобраться с Python in Excel!
Поэтому, решил я, заранее выгруженным из раздела Activities личного кабинета CSV-файлом с сырыми данными (и не только ими) будет заниматься новый экземпляр прирученного Excel Python. Суммировать, подтягивать недостающие, объединять, обновлять базу данных.
Но, к моему стыду, после нескольких часов борьбы я сдался и перешел к задаче попроще.
А теперь получилось.
Работаю с CSV: читаю и обрабатываю данные.
Данные с Garmin я дополняю записями о пульсе в состоянии покоя и HRV, полученными из приложения Elite HRV (что это такое). Выгрузить данные из не-ПРО версии Elite HRV самому нельзя, но можно их запросить и -- о чудо -- через несколько минут на почту придет ссылка для загрузки архива из TXT-файлов, дата-сетов с записями каждого выполненного в приложении замера.
Дата-сеты в данном случае -- RR-интервалы, каждый из которых -- время в миллисекундах между сердцебиениями. Мне нужно (действительно "нужно", а не "захотелось", запросил врач-кардиолог) извлечь показания пульса в каждый момент замера и построить график, отображающий, как пульс изменялся.
Не могу сказать, что все прошло без сучка и задоринки, были небольшие сложности с созданием запросов (строка кода rr_intervals = xl("EliteHRV_SS"), но в целом на разработку этого суперсложного кода ушло минут пятнадцать.
# read data rr_intervals = xl("EliteHRV_SS") rr_intervals.columns = ['rr_intervals'] rr_intervals['rr_intervals'] = pd.to_numeric(rr_intervals['rr_intervals']) # calculating heart rate for each interval rr_intervals['heart_rate'] = (60000 / rr_intervals['rr_intervals']).astype(int) # Calculate cumulative time in seconds for each RR interval cumulative_time = np.cumsum(rr_intervals['rr_intervals'].values) / 1000 # Convert from ms to s cumulative_time = [int(t) for t in cumulative_time] heart_rates = rr_intervals['heart_rate'].values df = pd.DataFrame({ 'timepoints': cumulative_time, 'heart_rate': heart_rates }) # Plotting plt.figure(figsize=(15, 6)) plt.plot(cumulative_time, heart_rates, label='Heart Rate', color='blue') plt.xlabel('Time (seconds)') plt.ylabel('Heart Rate (bpm)') plt.title('Heart Rate Over Time') plt.legend() plt.grid(True) plt.show()
Код запустился и, главное, работает, как и задумывалось: данные из TXT‑файла экспортировались, график построился.

Немного об особенностях
Кроме специфик в работе с данными, особенно внешними, и необходимости костылей для сохранения данных вне текущей рабочей книги, обнаружил еще несколько особенностей.
Нет необходимости импортировать библиотеки, если они (библиотеки) установлены на сервере Microsoft. Обратите внимание -- в строке
pd.to_numeric(rr_intervals['rr_intervals'])из Pandas вызываетсяto_numeric, но импорта Pandas нет.Автодополнение работает, но не так красиво, как мы привыкли.
Уверен, что список особенностей -- гораздо длиннее.
Буду ли использовать фичу?
Ответ: скорее "да", чем "нет". Для простеньких задач, вроде элементарной обработки небольшого дата-сета, вполне рабочий инструмент.
Но как только задача хоть немного усложняется, обычный Python (Anaconda в моем случае) -- гораздо удобней и эффективней.
А вы как думаете? Попробуете?

