
Есть много локальных аналогов ChatGPT, но им не хватает качества, даже 65B модели не могут конкурировать хотя бы с ChatGPT-3.5. И здесь я хочу рассказать про 2 открытые модели, которые всё-таки могут составить такую конкуренцию.
Речь пойдет о OpenChat 7B и DeepSeek Coder. Обе модели за счет размера быстры, можно запускать на CPU, можно запускать локально, можно частично ускорять на GPU (перенося часть слоев на GPU, на сколько хватит видеопамяти) и для такого типа моделей есть графический удобный интерфейс.
И бонусом затронем новую модель для качественного подробного описания фото.
UPD: Добавлена информация для запуска на Windows с ускорением на AMD.
OpenChat
Ссылка: https://huggingface.co/openchat/openchat_3.5
Онлайн демо: https://openchat.team/

Эта модель, по заявлению разработчиков, превосходит модели с 70B параметров имея всего лишь 7B параметров и даже может конкурировать с ChatGPT-3.5, который по слухам имеет 175B параметров.
На практике, она не всегда дотягивает до ChatGPT, но она ощутимо превосходит Alpaca, Vicuna и прочие открытые модели. При этом, для модели размером 7B, хорошо, хоть и не идеально, понимает русский язык и сразу же на нем и отвечает, без дополнительных подсказок об этом.
А то, что она маленькая позволяет запускать её без проблем даже на CPU. Требуется 14гб памяти или после квантования до 5 bit всего 5гб, что для модели уровня ChatGPT-3.5 хороший результат.
DeepSeek Coder
Ссылка: https://github.com/deepseek-ai/deepseek-coder
Онлайн демо: https://chat.deepseek.com/coder
Эта локальная модель предназначена для генерации кода и представлена в виде base и Incruct версия с вариантами весов 1.3B, 5.7B, 6.7B или 33B. Incruct версия генерирует код лучше базовой модели, но с базовой модель можно поболтать. Понимает команды на русском.
Модель по тестам для Python'а оценивается выше чем ChatGPT-3.5 на 3% и отстает от ChatGPT-4.0 всего на 5%. С другими языками могут быть другие результаты, но в среднем результаты близки:

LLaVA: Large Language and Vision Assistant
Ссылка: https://github.com/haotian-liu/LLaVA
Онлайн демо: https://llava.hliu.cc/
gguf модель 13B: https://huggingface.co/mys/ggml_llava-v1.5-13b
gguf модель 7B: https://huggingface.co/jartine/llava-v1.5-7B-GGUF
Аналог ChatGPT Vision. Может распознать, что находится на изображении и ответить на вопросы связанные с этим, попытаться объяснить в чем юмор и прочее. Модель старается описать красиво и красочно, при этом сохраняет выверенную детализацию.
Есть варианты в 7B и 13B параметров.

Можно спросить, что она видит конкретное на изображении?

Где брать модели и как их квантовать самостоятельно
Модели обычно можно найти на https://huggingface.co/
В поиске нужно ввести название модели. Например, введя DeepSeek + gguf можно сразу найти конвертированную модель с разными уровнями квантования:

Либо качать оригинал модели и конвертировать вручную с помощью llama.cpp.
Рассмотрим на примере OpenChat. На странице https://huggingface.co/openchat/openchat_3.5 нажимаете на 3 точечки и выбираете Clone repository и там будет инструкция как клонировать оригинальный репозиторий из которого и можно будет сконвертировать в gguf модель.
Если вы под Windows, вам нужно будет установить cmake - https://cmake.org/download/, либо использовать wsl.
# клонируем репозиторий с openchat git lfs install git clone https://huggingface.co/openchat/openchat_3.5 # клонируем llama.cpp и переходим в её папку git clone https://github.com/ggerganov/llama.cpp.git cd llama.cpp # собираем все нужные бинарники make # если установили cmake, то команда будет cmake, вместо make # установим зависимости pip install -r requirements.txt # теперь можно запустить саму конвертацию python3 convert.py ../openchat_3.5/ --outfile openchat_3.5-f16.gguf # после этого модели можно устроить квантование 5bit или другое ./quantize openchat_3.5-f16.gguf openchat_3.5-q5_K_M.gguf q5_K_M
Теперь у вас есть файлы openchat_3.5-f16.gguf и openchat_3.5-q5_K_M.gguf - первый будет использовать 15гб памяти, а второй - 6.3гб.
Какой метод квантования выбрать - https://github.com/ggerganov/llama.cpp/discussions/406 оптимальный это q4_K_M, где меньше 1% потерь, но если память позволяет, можно взять q5_K_M. Цитата оттуда:

+ppl % - процентное увеличение неточности.
+ppl от 13b до 7b % - неточность при переходе от модели 13b к модели 7b.
Графический интерфейс для text2text моделей
Есть как минимум несколько вариантов запуска text2text моделей с графическим интерфейсом, включая AMD на Windows:
text-generation-webui - для тех кому привычен подход аналогичного интерфейса для stable diffusion, запускается сервер, открывается указанная ссылка в браузере и дальше работа в браузере.
koboldcpp - запускается exe файл и работа происходит в отдельной программе, для Nvidia карт, ускорение через CUDA.
https://github.com/YellowRoseCx/koboldcpp-rocm/releases - koboldcpp для AMD на Windows. Сборка с ROCm, вместо CUDA.
llama server - реализация сервера для Chatbot UI, реализация интерфейса как у chatGPT.
open-chat-ui - запуск сервера и UI для OpenChat как на их сайте онлайн.
Как запустить LLaVA
Хотя изначально LLaVA запускалась только под Linux, но для Windows уже есть несколько вариантов:
https://github.com/haotian-liu/LLaVA/blob/main/docs/Windows.md - официальный способ с графическим интерфейсом, только для f16 моделей, достаточно тяжелый вариант с требованием к видеокарте, так как не может запускать квантированные модели (квантование для этого способа работает только на Linux).
Запуск через консоль с помощью llama.cpp, там в наборе уже есть llava. Позволяет запускать квантированные модели на cpu/gpu. Нужно скачать и саму модель и mmproj модель (качается также на huggingface). Запускается командой:
./llava-cli -m models/llava/llava-v1.5-7b-Q4_K.gguf --mmproj models/llava/llava-v1.5-7b-mmproj-Q4_0.gguf --image 01.jpgЕсли указать параметр -p, можно задать вопрос про картинку, например, спросить какого цвета пингвин:
./llava-cli -m models/llava/llava-v1.5-7b-Q4_K.gguf --mmproj models/llava/llava-v1.5-7b-mmproj-Q4_0.gguf --image red_linux.jpg -p "what colour is the penguin?"С помощью text-generation-webui multimodal, удобный графический интерфейс, но придется повозится с установкой и запуска сервера для поддержки множественности типов моделей.
Запуск на Windows с ускорением на AMD видеокартах
ROCm - это аналог CUDA от AMD. Портирование ROCm на Windows продолжается. Например, уже можно запускать Blender с ускорением на ROCm. И есть форк для koboldcpp с ROCm, который тоже уже работает. Спасибо @DrXakза подсказку, что это уже работает для Windows.
Для запуска вам нужно скачать файл koboldcpp_rocm_only.exe и запустить его, там выбрать модель и указать нужное количество GPU слоев (зависит от количества видеопамяти):

После этого откроется интерфейс в браузере, где можно будет найти поле для ввода промпта, найти параметры генерации, по умолчанию Instruct Mode и сценарии для отыгрыша персонажей. Для продолжения генераций нужно нажимать Generate More.

По скорости 7900 xtx не уступает 4090, 66 токенов в секунду:

Установка и запуск text-generation-webui
Раньше установка была сложной, но сейчас установка производиться в 1 действие, нужно просто запустить start_windows.bat и дальше всё установится само.
Для этого нужно скачать zip-архив репозитория или сделать:
git clone https://github.com/oobabooga/text-generation-webui
После распаковки архива и перехода в папку, нужно найти и запустить скрипт запуска, если вы под Windows, то это будет, например, start_windows.bat, или start_linux.sh если вы под Linux.
При запуске вам предложат выбрать на чем вы будете запускать, на GPU или CPU. Если у вас совместимая видеокарта, то выбирайте вариант с GPU, даже на видеокарте с 4гб памяти можно будет часть нагрузки разместить на ней, а часть будет считаться на CPU.
Для AMD видеокарт пока доступен только вариант ускорения ROCm под Linux. Работы над портированием ROCm под Windows ведутся.

Модели нужно положить в папку models и после этого выбрать модель и загрузчик:

Для моделей с разрешением gguf нужно выбирать llama.cpp в качестве загрузчика.
Также тут можно указать сколько слоев будет обработано на GPU, это позволит ускорить работу даже если у вас видеокарта с небольшим объемом видеопамяти.
Можно подобрать экспериментально на сколько хватает памяти, поэтому можете выкрутить этот ползунок на максимум, тогда будет выставлено автоматически максимальное значение для видеокарты и после в консоли нужно смотреть, сколько он хочет всего видео памяти, постепенно уменьшая это значение.
После этого остается нажать Load и начнется загрузка модели, спустя некоторое времени появится надпись, что модель успешно загружена.

В параметрах можно выставить 2048 токенов, чтобы не требовалось каждый раз нажимать "Continue" во время генерации, так как по умолчанию выставлено всего 200 токенов и длинные ответы будут залипать на половине ответа. Главное после этого не забывайте создавать новый чат каждый раз, когда хотите сменить тему или получить новые ответы на тот же вопрос.

Теперь можно перейти на вкладку Chat и попытаться что-то поспрашивать:

Можно дать текст на анализ:
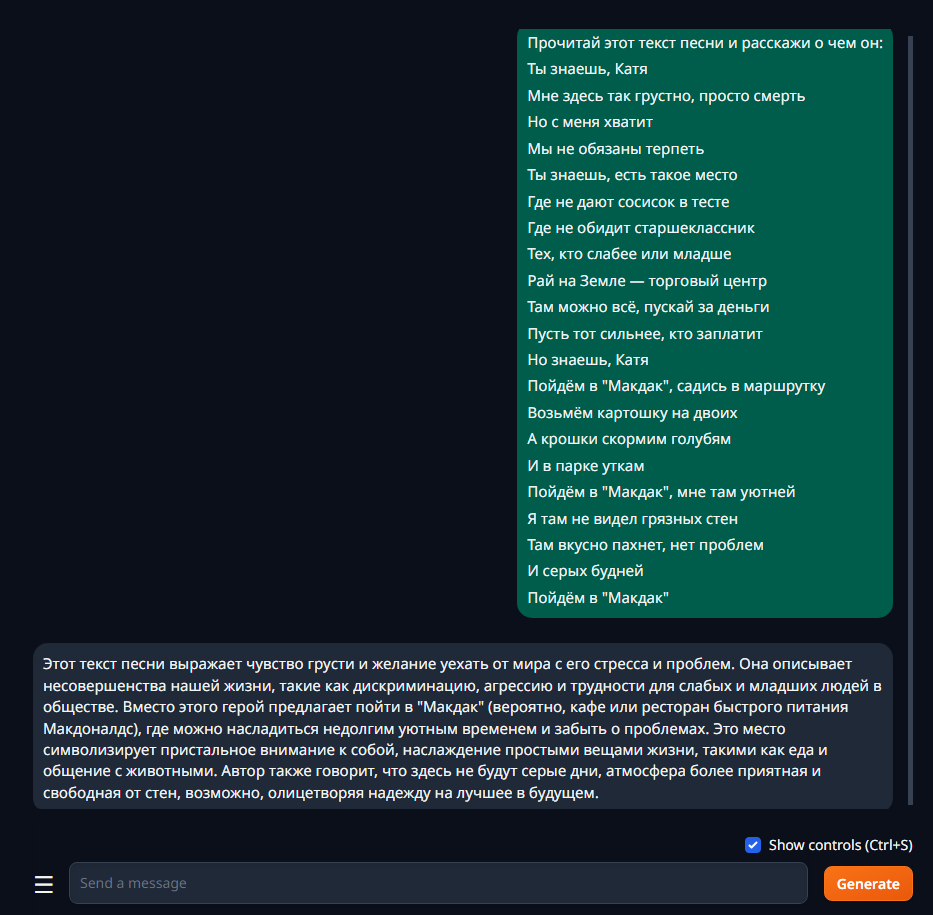
Chat работает в 3 режимах взаимодействия с моделью: chat, chat-instruct и instruct, по умолчанию выставлен chat. В режиме chat модель будет пытаться общаться невзирая на то, что вы у неё просите.
Например, если вам нужно, чтобы модель писала в ответ только перевод, без пояснений, для этого нужно выбрать режим chat-instruct или instruct:

Дальше уже можно поэкспериментировать. Можно попросить написать простой todo на js:


Результат простой и частично рабочий, кнопка X не работает, но об этом модель сразу предупреждает, само добавление работает:

Можно проверить на сколько 7B модель может в простую математику:

Попробуем что-то посложнее. Запрос: напиши flutter приложение которое имитирует мессенджер:

Как использовать DeepSeek Coder
OpenChat может генерировать код, но в зависимости от сложности и дополнительных условий, она будет выдавать не совсем то, что ожидается. В этом смысле DeepSeek куда ближе к ChatGPT, чем OpenChat.
Для генерации только кода, вам нужно взять модель с именем instruct, она генерирует код лучше чем base модель в которой есть режим чата и поэтому она хуже справляется с кодом. А сам чат нужно перевести тоже в режим instruct для лучшего результата (тоже самое можно делать для OpenChat, если нужен только код):

После этого модель сможет лучше понимать, что вы от неё хотите и лучше додумывать, что это могло бы означать в формате кода. Попробуем попросить его сгенерировать bash-скрипт, с которым у OpenChat проблема.

Если дать тоже задание OpenChat, то с первого раза модель не всегда будет выполнять все условия которые ожидаются, например, будет записывать уже обработанные файлы, но не проверяет их, чтобы повторно не обрабатывать. И с одной стороны правильно, этого не было в условии, но DeepSeek и ChatGPT сразу понимают, что это подразумевается и ожидается.

Попробуем что-то посложнее, с чем и у ChatGPT есть сложность, чтобы с 1 раза сгенерировать всё правильно.
Запрос: Напиши приложение на flutter которое будет показывать случайный комикс xkcd. Должна быть кнопка показать следующий комикс. Должна быть кнопка добавить в избранное и возможность посмотреть своё избранное

Код с виду рабочий, но при запуске показываются ошибки, пока ничего страшного, такие же ошибки генерирует и ChatGPT. ChatGPT может их исправить если ему кидать сообщения об ошибках, посмотрим как с этим у DeepSeek:


Применим исправления и попробуем запустить и посмотреть, что получилось. Да, теперь программа успешно запустилась:

Пролистывание работает, но оно не рандомное, а на 1 комикс вперед. Кнопка добавления в избранное работают, сам список избранного в виде бесконечной ленты отображает, кнопка назад на главный экран тоже предусмотрена.
")
В этой же задачей ChatGPT-3.5 справился похожим образом, он тоже не получал рандомный комикс и генерировал не рабочий Flutter код, но после нескольких итераций сообщения об ошибках, он ошибки исправил, также как и DeepSeek. Можно сделать поверхностный вывод, что в более редких сценариях, чем являются Dart и Flutter, они показали себя равнозначно.

