Автор оригинала Скотт Чакон — сооснователь GitHub и основатель нового клиента GitButler. Этот клиент ставит во главу угла рабочий процесс и удобство разработки, в том числе код-ревью, и не является просто очередной обёрткой над CLI git.
Вам хочется использовать ванильный Git, чтобы управлять репозиторием с объёмом 300 ГБ в 3,5 млн файлов, которые без проблем получают пуш каждые 20 секунд от 4000 разработчиков? Тогда читайте дальше!
Вот агенда блога — наша блогенда:
- Предварительное извлечение.
- Граф коммитов.
- Монитор файловой системы.
- Частичное клонирование.
- Разреженный checkout.
- Scalar.
Сначала поблагодарим Windows
Прежде чем начать, первое, что нужно сделать, — поблагодарить Microsoft почти за всё вот это.
В 2017 Microsoft с успехом перенесла кодовую базу Windows на Git. Брайан Гарри написал об этом по-настоящему великолепный пост под названием Самый большой репозиторий Git на планете, который сто́ит прочитать, если вам интересно; размер и объём этого репозитория поражают:
- 3,5 млн файлов (для справки, ядро Linux содержит около 80 тыс. файлов, или 2% от этого количества).
- Репозиторий на 300 ГБ (против Linux с ядром ~4,5 ГБ).
- 4000 активных разработчиков.
- 8421 пуш в день (в среднем).
- 4352 активных веток-тем.
Microsoft проделала большую работу, чтобы любым возможным способом заставить это работать. В то время как при использовании чистого Git выполнение многих команд (например, git status, если они вообще когда-нибудь так выполнялись) занимало бы часы, выполнять каждую команду нужно было так же быстро, как в Source Depot.
Первым решением проблемы стал новый проект под названием VFS for Git. Он был слоем виртуальной файловой системы, который выполнял виртуальные checkout, а затем запрашивал файлы с центрального сервера по требованию.
В конце концов, всё больше и больше разработанных решений переместилось в проект Scalar, который избавился от слоя виртуализации. Вместо этого он запрашивает содержимое файла не по запросу, а при извлечении.
Затем разработчики переместили всё, кусочек за кусочком, в форк Microsoft Git и, наконец, переместили всё это в основной Git. Так что, как и обещано, если вы хотите сегодня использовать Git «из коробки» для управления репозиторием объёмом 300 ГБ с 3,5 млн файлов, получающими пуш каждые 20 секунд от 4 тыс. разработчиков, вы на 100% можете делать это. Давайте разбираться со всем, что добавили для нас.
Предварительное извлечение
Итак, в последнем посте я говорил, что git maintenance выполняет в репозитории предварительное извлечение и обслуживает граф коммитов каждый час. Начнём с первой из этих тем. Что такое «предварительное извлечение»?
Одна из вещей, которые раздражали разработчиков Windows, заключалась в том, что извлечение часто проходило медленно, поскольку постоянно происходило очень много активности. При каждом извлечении нужно было извлекать все данные с момента последнего извлечения вручную.
Поэтому разработчики добавили cron-задачу — так называемое предварительное извлечение, которое, по сути, автоматически запускает для вас команду извлечения каждый час. Однако она не обновляет ваши удалённые ссылки, как обычно, вместо этого заполняя особую область ваших ссылок — refs/prefetch:

Эти ссылки обычно не отображаются. Даже если вы запускаете что-то вроде git log --all, они скрыты от вас. Тем не менее они используются при общении с удалённым сервером, а это означает, что если функция включена, то каждый раз, когда вы выполняете извлечение, компьютер никогда не отстаёт от пушей более чем на час.
По сути, ускоряется ручное извлечение.

Шутка украдена у Мартина Вудворда :)
Граф коммитов
Другая вещь, которую git maintenance делает каждый час, — обновляет данные графа коммитов. Что именно это означает? По существу, ускоряется обход истории коммитов.
Вместо того чтобы открывать по одному объекту коммита за раз, чтобы увидеть, какой объект у него родительский, а затем открыть объект, чтобы увидеть, какой объект у него родительский и т. д., граф коммитов является, в сущности, индексом всей этой информации, которую можно быстро обойти за раз, что намного ускоряет штуки типа git log --graph или git branch --contains. Для большинства репозиториев скорость этих команд, наверное, не кошмарная проблема, но, когда коммитов миллионы, их скорость имеет огромное значение.
Ниже тест кое-каких связанных с логом подкоманд, выполняемых в кодовой базе ядра Linux с данными графа коммитов и без них (из блога GitHub):
| Команда | Без commit-graph | С commit-graph |
|---|---|---|
| git rev-list v5.19 | 6,94 с | 0,98 с |
| git rev-list v5.0.v5.19 | 2,51 с | 0,30 с |
| git merge-base v5.0 v5.19 | 2,59 с | 0,24 с |
Вот быстрый тест, который я провёл в том же репозитории Linux, запустив git log --graph --oneline до и после добавления файла графа коммитов:

Опять же, если у вас запущены cron-задачи maintenance, это магическим образом просто делается для вас постоянно, вам на самом деле нечего делать.
Монитор файловой системы
Одной из вещей, в которых нуждался VFS для Git, был монитор файловой системы, чтобы он определял, когда запрашивается содержимое виртуального файла, и при необходимости получал его с центрального сервера.
Этот монитор в конечном счёте ускорял git status за счёт обновления индекса на основе событий изменения файловой системы, а не за счёт запуска stat для каждого файла каждый раз, когда вы его запускаете.
Хотя первый [монитор] стал ненужным после отказа от слоя виртуализации, второй интегрировали в основной Git. Если вы хотите, чтобы git status работал намного быстрее на очень больших рабочих каталогах, этот самый новый монитор файловой системы Git просто спасёт вас.
По сути, вы просто устанавливаете параметры конфигурации:
git config core.fsmonitor true
Команда добавляет параметр, который git status увидит при запуске и поймёт, что использовать нужно fsmonitor-daemon. Если демон не выполняется, команда запустит его.

На Chromium fsmonitor выполняет status в 20 раз быстрее
При первом запуске git status после установки настроек конфигурации он будет не намного быстрее, но намного быстрее станет на каждом запуске дальше. Опять же, после установки этого значения особо делать нечего, всё просто ускоряется.
Частичное клонирование
Ещё одна большая проблема с большими репозиториями — размер клона. Как вы, наверное, знаете, по умолчанию Git извлекает всё. Вам даже не обязательно иметь репозиторий на 300 ГБ, чтобы это было проблемой: Linux — более 4 ГБ, Chromium — более 20 ГБ. Полное клонирование Chromium легко способно занять час, даже при довольно быстром соединении.
Долгое время клоны Git были поверхностными. Почти всегда можно запустить что-нибудь типа git clone --length=1, чтобы получить только последний коммит и необходимые ему объекты, а затем — git fetch --unshallow, чтобы, если нужно, позже получить остаток истории. Но это много чего ломало: никакого вам blame, никакого log и т. д.
Однако теперь у Git есть и клоны без блобов, и клоны без деревьев. Так что вы получаете всю историю (все коммиты), но не актуальное содержимое локально. Давайте сейчас проигнорируем клоны без деревьев, потому что обычно они не рекомендуются, а вот клоны без блобов — рекомендуются.

Полный клон репозитория Linux — 4,6 ГБ или (для меня) процесс на 20 минут
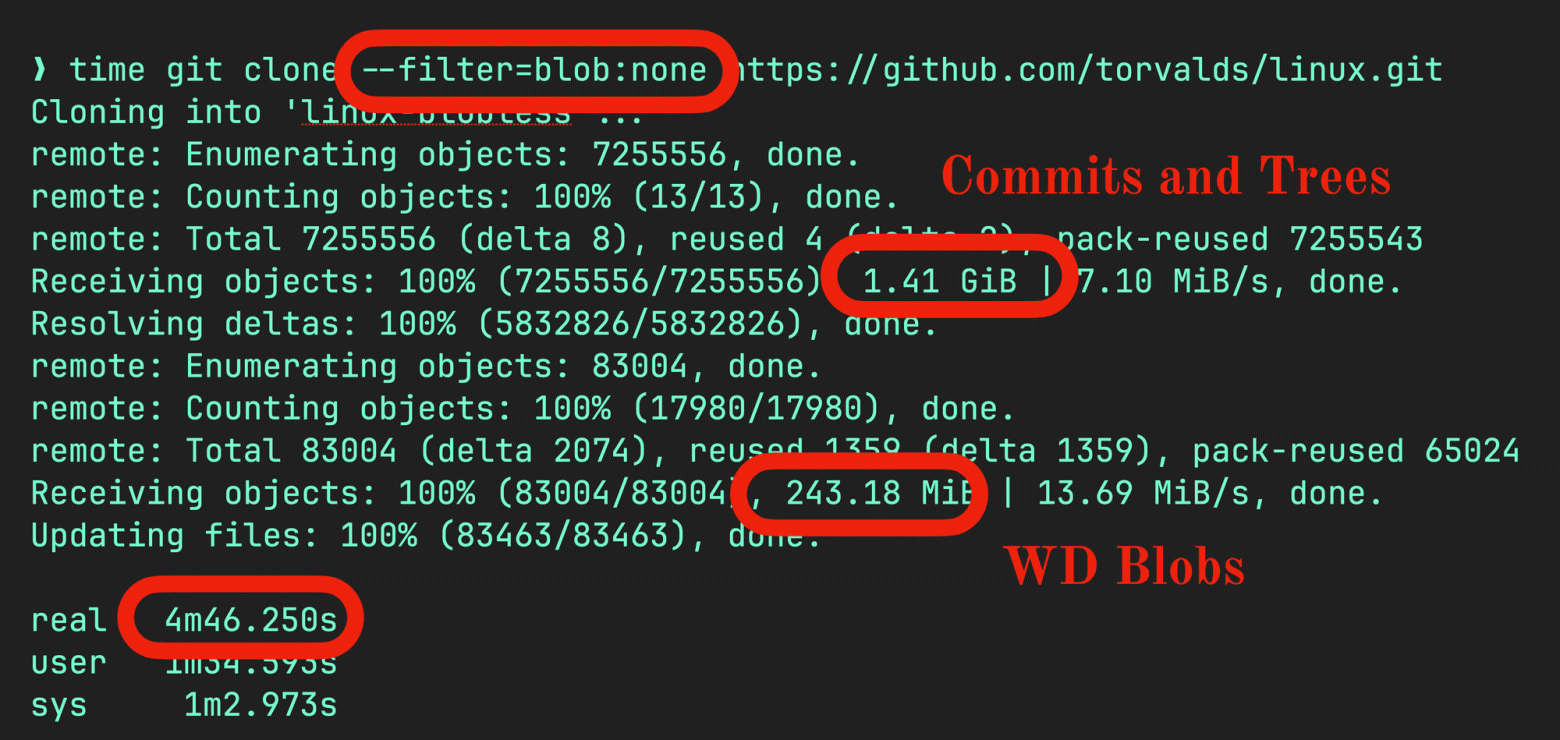
Если хотите клон без блобов, просто передайте --filter=blob: none. Процесс немного изменится. Загрузятся все коммиты и деревья, что в случае ядра Linux сократит 4,6 ГБ до 1,4 ГБ, а затем произойдёт второе извлечение, оно коснётся только блобов, необходимых git checkout:
Так что, как видите, вместо 20 минут на клон у меня ушло 4,5 минуты. А ещё видно, что Git выполнил два извлечения: одно на 1,4 ГБ данных коммитов и дерева, второе — на 243 МБ файлов, необходимых для моего локального теста.
Есть в этом и недостатки. Если хочется запустить команду, а ей нужны данные, которых нет, Git придётся вернуться на сервер и запросить объекты. К счастью, он делает загрузку по требованию, когда объекты нужны, но что-то вроде blame может заставить проделать кучу обходов:

Мы идём по кругу
В данном случае с Linux тесты показывают, что git blame обычного файла может занимать 4 секунды, а занимает 45. Но это только для первого раза.
Разреженный checkout
Последняя важная вещь, на которую стоит обратить внимание, полезна не только для больших репозиториев, но особенно для монорепозиториев. То есть репозиториев, содержащих несколько проектов в подкаталогах.
Например, в GitButler наши веб-сервисы находятся в монорепозитории, причём каждый сервис, который мы запускаем на AWS, расположен в подкаталоге:
tree -L 1 . Gemfile Gemfile.lock README.md auth-proxy butler chain check.rb copilot git 6 directories, 4 files
Если бы каждый из этих подкаталогов был огромным, управление ими раздражало бы. Но можно делать разреженные checkout, когда команда отфильтровывает только указанные каталоги. Для этого запустим git sparse-checkout set [dir1] [dir2] …:
git sparse-checkout set butler copilot tree -L 1 . Gemfile Gemfile.lock README.md butler check.rb copilot
Таким образом, у нас по-прежнему есть файлы верхнего уровня, но остались только два указанных нами подкаталога. Это называется «режим конуса», он склонен быть быстрым. Ускоряется также выполнение status и связанных с ним команд, ведь нужно обходить меньше файлов. Ещё вместо подкаталогов можно установить шаблоны, но это сложнее.
Вот локальный тест, который я запустил в репозитории Chromium:
time git status On branch main Your branch is up to date with 'origin/main'. nothing to commit, working tree clean real0m5.931s git sparse-checkout set build base time git status On branch main Your branch is up to date with 'origin/main'. You are in a sparse checkout with 2% of tracked files present. nothing to commit, working tree clean real0m0.386s
Это без fsmonitor. Видно, что время status сократилось с 6 секунд до 0,3 секунды, потому что файлов не так много.
Если вы используете большие монорепозитории, это означает, что можно клонировать без блобов, чтобы иметь гораздо меньшую локальную базу данных (ещё можно запустить clone --no-checkout, чтобы пропустить git checkout при инициализации). Затем выполните sparse-checkout, чтобы выполнять checkout только в указанных каталогах, и всё будет происходить намного быстрее.
Scalar
Наконец, Git (с октября 2022 года, Git 2.38) поставляется с альтернативной командой CLI, которая оборачивает какие-то из всех этих штук. Эта команда называется scalar. Просто введите её:
scalar usage: scalar [-C <directory>] [-c <key>=<value>] <command> [<options>] Commands: clone list register unregister run reconfigure delete help version diagnose
Scalar в основном используется только чтобы клонировать с подходящими умолчаниями и конфигурацией (клон без блобов, --no-checkout по умолчанию, должным образом настроенная git maintenance и т. д.)
Если вы управляете большими репозиториями, клонирование со Scalar отменяет необходимость запускать git maintenance start, отправлять команду --no-checkout, помнить о --filter= tree: 0 и много чего ещё.
Вот мы и нарастили мас!.. штаб.
Кое-что почитать
Если вы хотите прочитать обо всём этом очень подробно, GitHub проделал потрясающую работу, охватив и многое из списка:
- граф коммитов;
- разреженный checkout;
- монитор файловой системы;
- разреженный индекс;
- частичное и поверхностное клонирование;
- история Scalar.
У Деррика Столи, который в этих проектах перелопатил тонны, есть ещё масса завораживающих подробностей.
Это вся серия советов по Git! Надеюсь, вы наслаждались. Сообщите нам в Discord, если у вас есть какие-то вопросы или комментарии, или вы хотели бы, чтобы мы поговорили на другие темы на территориях Git.
Спасибо!
Скотт Чакон.

