Я работаю в DataNewton сервисе для скрининга контрагентов. Данные, которые мы предоставляем, берутся из 43-х официальных источников. Чаще всего это базы данных государственных сервисов. И тут есть проблема: такие сервисы любят менять формат массивов, в которых они отдают данные. Например, недавно один из них без предупреждения поле «name» поменял на «firstname», из-за чего могли полететь многие названия компаний. Но мы быстро увидели это в самодельной панели и предотвратили ошибку, которая для нашего сервиса была бы критической.
Как мы построили визуальное отображение ошибок — рассказываем в статье.
Какие ошибки могут быть
Не все данные выгрузились. Мы работаем с большими массивами данных: база «весит» больше 10 терабайт, и она продолжает расти. Для работы с таким объемным массивом данных используем Elastic Search — базу данных, оптимизированную под поиск. С ее использованием поиск среди миллионов компаний редко занимает больше секунды. В Elastic мы загружаем только ключевые метрики, нужные для поиска.
Периодичность обновления данных в источнике. Обновление источников происходит с различной периодичностью. Это может происходить ежедневно, еженедельно, ежемесячно, ежеквартально, ежегодно или со случайной периодичностью. За данными мы приходим ночью — в это время практически отсутствует нагрузка на инфраструктуру госорганов.
Разные форматы данных. Все отдают данные по-разному: через FTP, веб-страницы или API. Форматы приходящих данных тоже отличаются — XML, csv, json. Более того, их тоже могут поменять без предупреждения. Внезапно может измениться и структура отдаваемых источником данных.
Данные могут не скачаться, или скачаться, но не распарситься, или распарситься, но не загрузиться в БД и так далее. Все эти ошибки тут же будут видны нашим пользователям, если их вовремя не отловить. Поэтому, с целью минимизации временных затрат на чтение логов, мы внедрили систему контроля обновления данных.
Какая система была раньше
Количество обрабатываемых источников наращивалось постепенно. В начале получалось контролировать работоспособность при помощи телеграм-бота: все хорошо — в общий канал приходило позитивное сообщение, что-то пошло не так — Alarm! Но список источников рос, и следить за работоспособностью всех источников одновременно становилось все сложнее.
Как модифицировали систему мониторинга
Решение, как архитектурное так и практическое, пришло, как это часто бывает, со стороны разработки. Операции, производимые с данными, логировались с самого начала. Эти логи складывались в БД. Мы решили их расширить, продлить (не все источники логировались с одинаковой степенью глубины) и визуализировать.
Для визуализации взяли популярный инструмент, который выводит нужную информацию в удобочитаемом виде — Grafana. Обновления в этой системе выглядят в виде самолетной панели — все видно на одном экране.
Теперь у нас работает цепочка Backend -> Prometheus -> Grafana. Скорость изучения статуса обновления снизилась с 2 часов (когда специалист вручную шел в логи при возникновении ошибки) до 15 секунд.
Как это работает. Как уже писали выше, единица данных проходит несколько этапов:
Скачивание
Загрузка в БД
Загрузка в Elastic Search
В Графане панелька выглядит так:
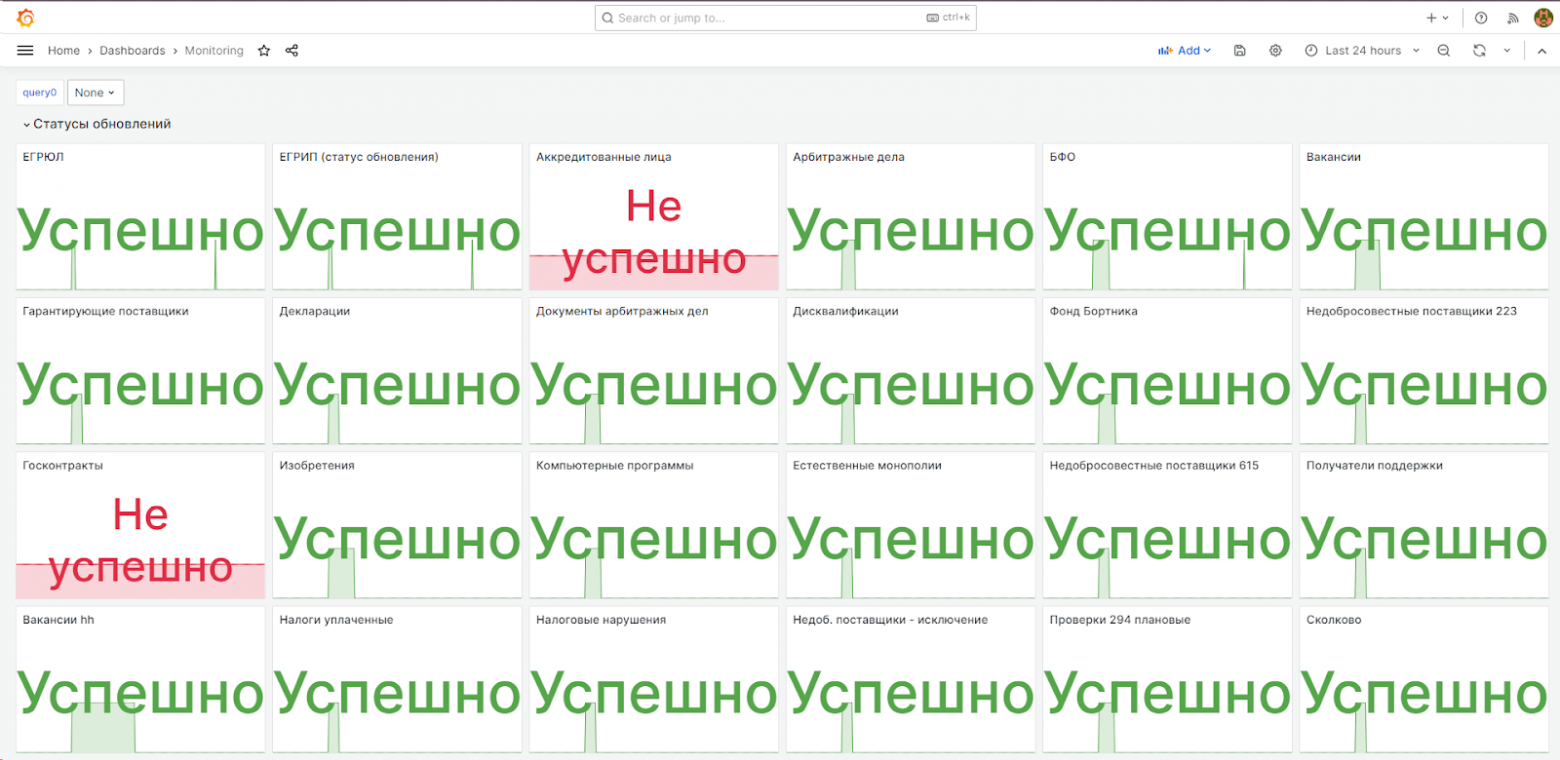
Всего отслеживаем 4 метрики.
Первая метрика, которую отслеживаем — статус обновления.

Каждый этап имеет статус завершенности — ОК или НЕ ОК. Если каждый этап завершился со статусом ОК, то Prometheus присылает в Grafana ноль (0). Это означает, что процесс обновления данных из источника прошел корректно на всех этапах и пользователи увидят данные корректно.
Если хотя бы один этап НЕ ОК, то в Графану приходит двойка (2). Это говорит о том, что обновление отработало некорректно или не отработало вовсе, и есть повод завести блокер.
Следующее за чем мы следим — процент файлов, загруженных из источника.
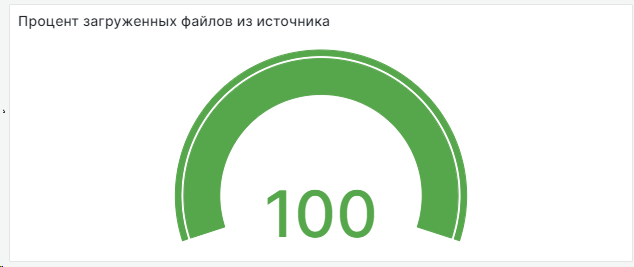
Часто источник обновляется из нескольких архивов. У нас была ситуация, когда в источнике лежало два архива для обновления, но мы по какой-то причине забрали только один. Это значит, что до пользователей какие-то данные не дошли — критично.
Проверяем просто: считаем, сколько файлов лежит в источнике и сравниваем с количеством файлов на сервере после завершения процесса скачивания. Вычисляем процент и передаем его в метрику.
Дальше идет набор метрик, связанных с объемом полученных данных. Вот так они выглядят на панельке:
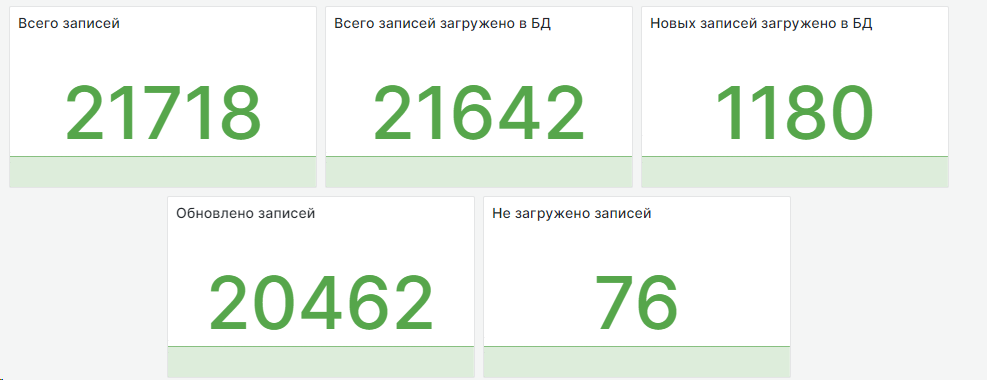
Если сумма «Всего записей загружено в БД» и «Не загружено записей» равна «Всего записей», то все прошло хорошо.
Если какие-то записи распарсить не получилось, то из метрик мы этого не увидим. Мы планируем обновление системы, в котором добавим метрику «Количество ошибок» — она будет сигнализировать, когда что-то не так в процессе парсинга записей.
Последняя метрика показывает время (в минутах), затраченное на обновление данных по конкретному источнику.
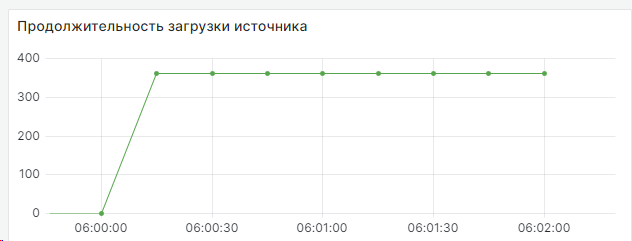
Пока практического применения эта метрика не имеет. Для анализа она не особо нужна, так как анализировать удобнее при помощи селекта в БД. Скорее всего, в будущем, когда не будет ежедневного человеческого участия в проверке метрик, в Графане будет настроено оповещение, которое будет сообщать, что текущее время обновления источника превышает «Среднее значение» + n.
Немного технических деталей
Сбор, хранение и отображение метрик выполнено на основе опенсорсных Grafana и Prometheus. Решение это распространенное и хорошо задокументированное.
Все работает следующим образом:
Datanewton предоставляет API для запроса метрик в формате Prometheus через Spring Boot Actuator: GET …/actuator/prometheus,
Каждые 10 секунд Prometheus опрашивает API Datanewton и сохраняет у себя значение метрик,
Grafana по запросу пользователя обращается в Prometheus, забирает сохраненные метрики и отображает их на дашборде.

Что будет в следующей версии системы мониторинга
Планируем внедрить метрику по тестам. Несколько раз в день TeamCity будет запускать автотесты. Таких тестов у нас более тысячи штук — они имитируют поведение реального пользователя. Если вдруг какие-то тесты упали, мы это тут же увидим в Графане. Эти тесты планируем запускать каждый час, чтобы в режиме реального времени знать: все ли у нас работает хорошо.
Заключение
Мы — стартап. Если вы обнаружили недочеты в статье или у вас есть предложения по улучшению системы мониторинга — будем рады вашим комментариям и советам.
Также, приглашаем поделиться личным опытом использования Графаны или аналогов. Какие инструменты оказались полезными для вас? Какие инструменты рассматривали, но в итоге не выбрали, и почему?

