Как и обо всех новых технологиях, об искусственном интеллекте уже успело сформироваться немало легенд. Например, о том, что сложные ИИ-модели вроде GPT-3 или DALLE оставляют огромный углеродный след и оказывают разрушительное воздействие на окружающую среду. В поисках истины мы нашли материал с интересной точкой зрения и перевели ее для вас. И кстати, 10 мая в Светлогорске мы обсудим технологии будущего на фестивале KODE Waves.
В последние годы заголовки в СМИ часто пугали читателей количеством электроэнергии, нужной для развития цифровых технологий. Например, когда в 2019 году Apple, Disney и HBO и другие видеостриминговые сервисы анонсировали платные подписки для конкуренции с Netflix, Amazon и YouTube, СМИ написали, что «согласно заявлению Французского аналитического центра, получасовой просмотр Netflix генерирует такой же выброс CO₂, как проезд на машине 6,5 километров». Год спустя аналитический центр обнаружил ошибку в вычислениях и подсчитал, что получасовой просмотр Netflix по количеству CO₂ сопоставим скорее с проездом на машине от 10 до 100 метров, но об этом СМИ не написали.

История не нова: например, во времена бума доткомов в 1990-е годы одна статья в Forbes сообщала: «Каждый раз, когда в Интернете заказывают книгу, где-то в США сгорает кусок угля». Этой судьбы не удалось избежать и ИИ-технологиям, поэтому в материале мы разобрали популярные логические ошибки и заблуждения, а также выяснили, сколько на самом деле потребляют энергии и выбрасывают CO₂ крупные ИИ-модели.
Дисклеймер: материал является переводом статьи Центра инноваций в области данных. Мы незначительно сократили его без искажения сути.
Энергопотребление ИИ-технологий и углеродный след
Непросто подсчитать, сколько энергии потребляет и CO₂ выбрасывает ИИ-модель. В уравнении много переменных: чипы и системы охлаждения, конструктивные особенности дата-центров, ПО, рабочая нагрузка и источники энергии, используемые для генерации электричества. Однако несколько исследований поделили работу ИИ-модели на два этапа: обучения и генерацию ответов на запросы, и попытались выдать оценку.
Обучение ИИ-систем
Одно из первых крупных исследований провел Массачусетский университет в Амхерсте в 2019 году. В ходе него выяснилось, что BERT — большая языковая модель (LLM) Google, за 79 часов обучения выбросила 1438 фунтов CO₂. Для сравнения: перелет из Нью-Йорка в Сан-Франциско приводит к выбросу 1000 фунтов CO₂ на одного пассажира. Также исследователи оценили выброс CO₂ во время обучения ИИ-модели по поиску нейронной архитектуры (NAS) — для машинного обучения это одна из наиболее сложных вычислительных задач. Обучение NAS привело к выбросу 626 155 фунтов CO₂, что эквивалентно 300 перелетам туда и обратно с Восточного побережья США на Западное.
Результаты исследования стали сенсацией и разлетелись по заголовкам популярных СМИ. Даже уважаемые научные издания вроде MIT Technology Review публиковали материалы вроде «Обучение одной ИИ-модели может выбросить в атмосферу столько же CO₂, сколько пять автомобилей за всю свою жизнь». Авторы статей думали, что обучение ИИ-модели — типичный пример ее повседневной деятельности, а также сообщали, что несмотря на крупный выброс CO₂, обучение лишь незначительно улучшило модель.
Позже оказалось, что исследователи из Массачусетского университета в Амхерсте сделали несколько ложных предположений, которые завысили их оценку энергопотребления и выбросов CO₂. В ответ на их исследование NAS предоставили подробную сводку о своей ИИ-модели и отметили, что фактические выбросы были в 88 раз меньше. К сожалению, СМИ не обратили внимания на их заявление.
В последующие годы было опубликовано множество исследований об энергопотреблении и выбросе CO₂ при обучении известных ИИ-моделей. Мы свели данные из открытых источников в таблицу (см. ниже) и увидели, что логика «Чем сложнее и крупнее ИИ-модель, тем больше энергии она израсходует и тем больший углеродный след оставит» — неверна.
Например, обучение GPT-3 — ИИ-модели на 175 миллиардов параметров, используемой в ChatGPT — привело к выбросам 552 тонн CO₂. При этом сопоставимые с ней ИИ-модели от Meta и Google — OPT и Gopher на 175 и 280 миллиардов параметров, оставили значительно меньший углеродный след — 75 и 380 тонн CO₂ соответственно.
Кроме того, эффективность обучения ИИ-моделей увеличивается. Например, через 18 месяцев после GPT-3 Google выпустил GLaM — LLM с 1,2 триллионом параметров. Несмотря на то, что GLaM почти в семь раз больше GPT-3 и превосходит любую другую ИИ-модель, она требует в 2,8 раза меньше энергии для обучения.
Наконец, на выбросы CO₂ влияет энергопотребление дата-центра, в котором разработчики обучают ИИ-модель. Например, разработчики BLOOM использовали французский дата-центр, работающий на атомной энергии, и уменьшили углеродный след модели.

Использование ИИ-моделей
Постепенно ученые пришли к пониманию, что ИИ-модель расходует большую часть энергии не во время обучения, а во время генерации результатов по запросу.
В Amazon Web Services считают, что на генерацию результата приходится 90% потребления электроэнергии ИИ-модели.
В Schneider Electric прогнозировал, что 80% нагрузки ИИ-моделей в дата-центрах в 2023 году придутся на генерацию результата и 20% — на обучение.
Исследователи из Meta считают, что точное соотношение между обучением и генерацией варьируется в зависимости от сценария использования. Например, генерация результатов LLM-модели может занимать 65% углеродного следа от всей ее работы. Но для рекомендательных моделей, в которых параметры необходимо часто обновлять из-за поступления новых данных, распределение потребления энергии между обучением и генерацией результата будет равномерным.
При этом количество энергии, которое нужно для генерации результата, зависит от множества факторов. Например, использование ИИ для классификации текста обычно требует меньше вычислительных мощностей (следовательно, меньше энергии), чем использование ИИ для создания изображения. Разные ИИ-модели тратят разное количество энергии, а в рамках конкретных моделей (например, Llama 2 7B против Llama 2 70B) большее количество параметров требует больше энергии для генерации результата.
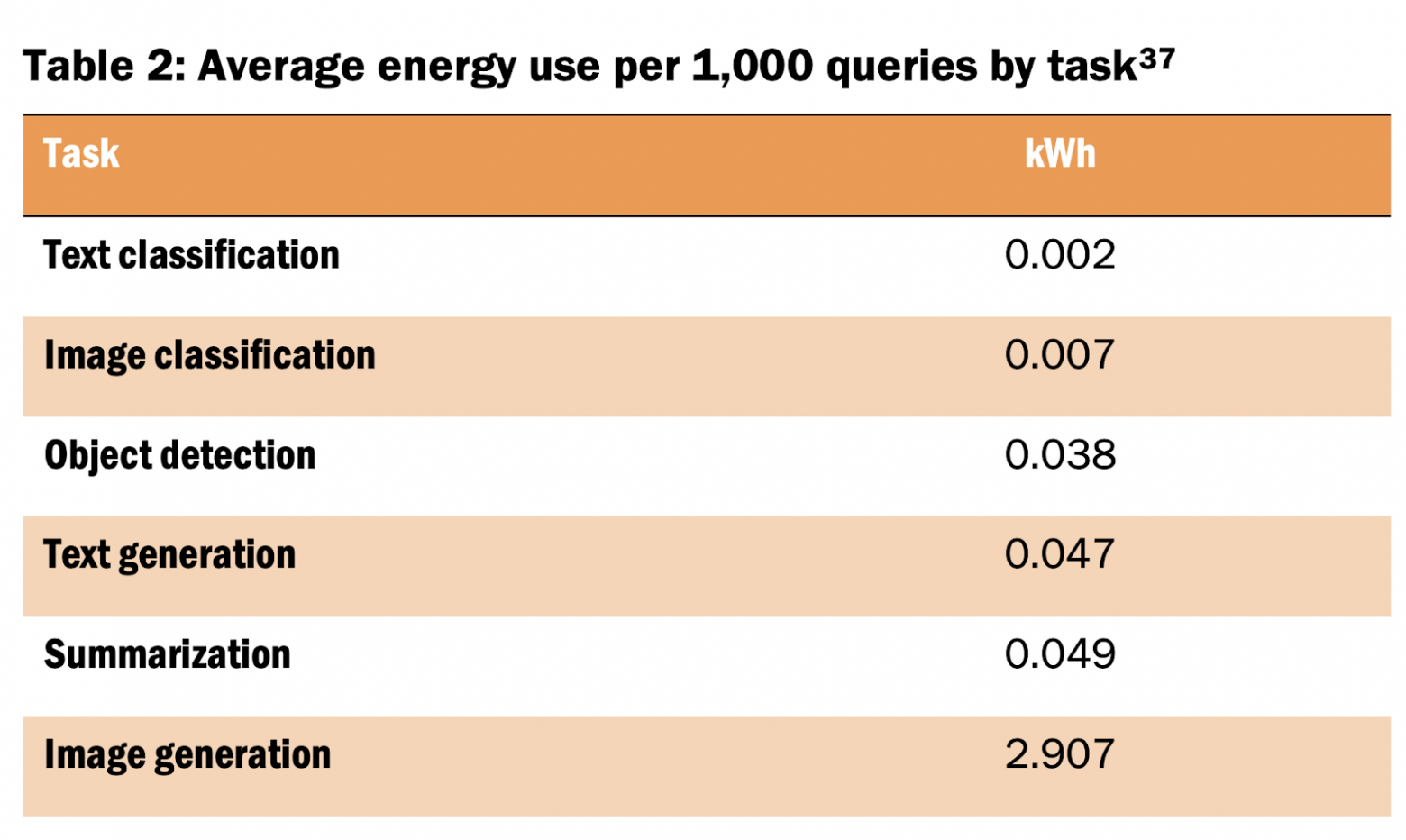
В статье из журнала Joule за октябрь 2023 года один исследователь подсчитал, что запрос в LLM тратит в 10 раз больше энергии, чем обычный запрос в поисковик. Он экстраполировал этот рассчет и пришел к выводу: «При наихудшем сценарии одна только ИИ-модель от Google может тратить столько же энергии, как Ирландия за год (29,3 ТВтч)».
Есть причины сомневаться в том, что мир близится к порогу этого наихудшего сценария. В 2022 году общее энергопотребление компании Google составило 21,8 ТВтч. Значит, чтобы сценарий сбылся, компания должна потратить больше энергии, чем тратит сейчас — причем только на ИИ.
И да, с ростом Google росло и энергопотребление компании. Например, в 2022 году его дата-центры потребляли на 3 ТВтч электроэнергии больше, чем в 2021. Но при общем росте энергопотребления доля энергии, используемой для машинного обучения, оставалась неизменной — от 10 до 15% от общего энергопотребления с 2019 по 2021 год, из которых 60% уходило на генерацию результатов. Это постоянство объясняет улучшение ИИ-моделей и аппаратного обеспечения ИИ, которые увеличивают производительность и КПД.
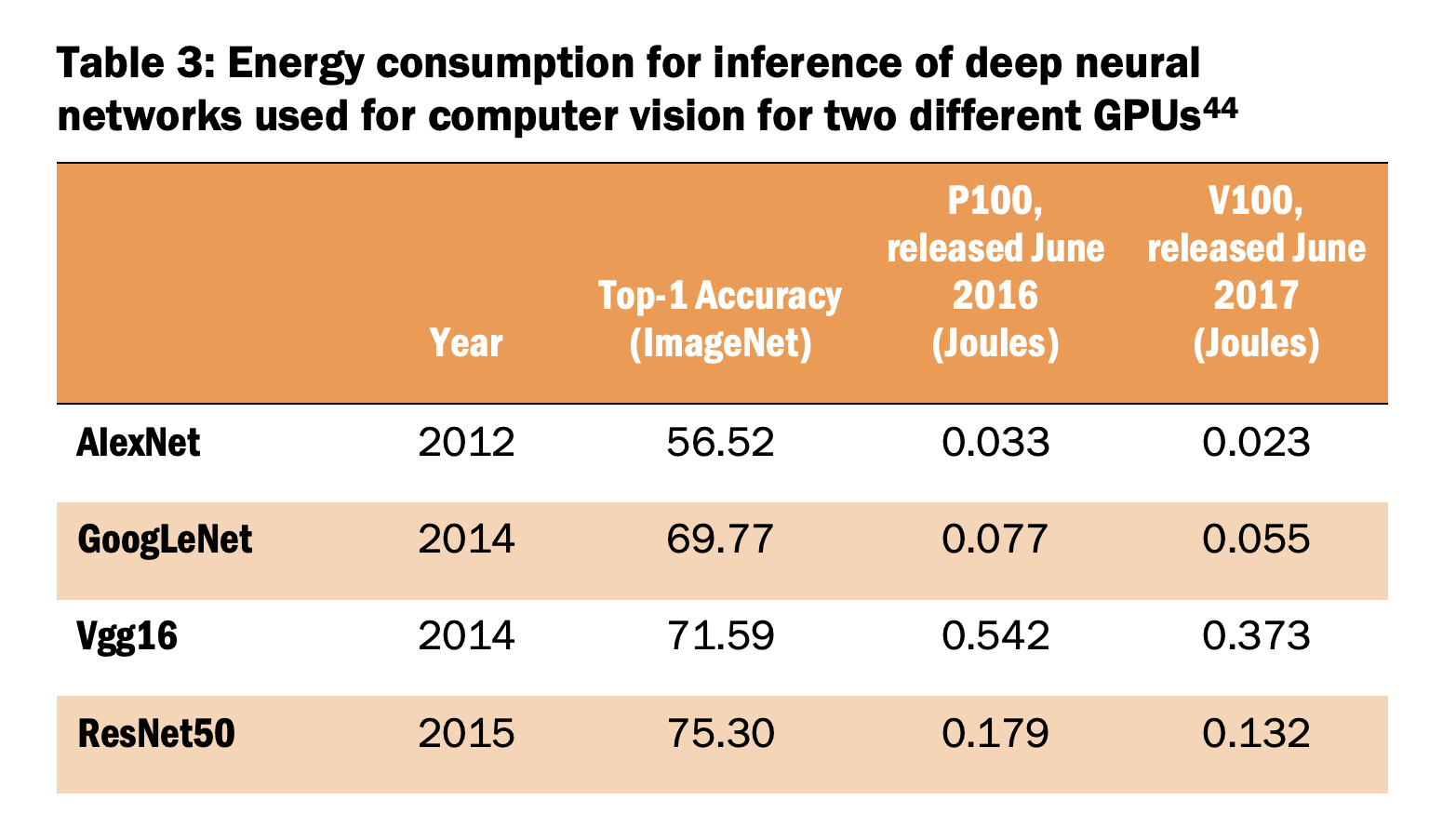
В третьей таблице видно, что за несколько лет точность ИИ-моделей компьютерного зрения значительно повысилась. Кроме того, выход новейшего чипа снижает энергозатраты на генерацию результата. Одно недавнее исследование энергии, используемой для генерации результата в ИИ-моделях подчеркнуло: сразу после выпуска ИИ-модель содержит огромное количество FLOPs (операций с плавающей запятой) и потребляет большое количество энергии, а через пару лет она превращается в модель той же точности, но с гораздо меньшим количеством FLOPs. На старте новейшая ИИ-модель может быть не сильно оптимизирована в плане потребления энергии, потому что в начале ее создатели обычно сосредоточены на увеличении ее производительности. Спустя время они переходят к увеличению эффективности ИИ-модели, и она начинает потреблять меньше энергии.
В чем ошибка прогнозов в области ИИ-энергетики
Выше мы описали первую причину завышенных прогнозов о будущих потребностях ИИ-моделей в энергии — неточные измерения. Вторая причина заключается в том, что прогнозы игнорируют экономические и технические реалии, которые возникают в связи с широкой коммерциализацией ИИ.
Энергопотребление ИИ ограничено экономическими соображениями
Покупка новых чипов, строительство дата-центров и их энергоснабжение стоят дорого. Даже автор прогноза о том, что ИИ-модели Google могут потреблять 29,3 ТВтч электроэнергии в год, признал, что для этого потребуются инвестиции в чипы на сумму 100 миллиардов долларов, а также еще миллиарды эксплуатационных расходов на дата-центры и электроснабжение. Это непосильные расходы даже для техногигантов: им невыгодно предлагать услуги, обеспечение предоставления которых превышает доход, который они приносят. Значит, либо ИИ-технологии научатся будут развиваться в сторону меньшего энергопотребления, либо способы их внедрения упрутся в финансовые ограничения.
Скорость повышения производительности ИИ со временем будет снижаться
За последние несколько лет ИИ-модели значительно улучшились. Например, модель LLM GPT-4, выпущенная OpenAI в марте 2023 года, позволяет сдавать экзамены вроде SAT, GRE, LSAT, и проходить тесты по различным предметам. По сравнению с предыдущей версией модели, выпущенной годом ранее, это существенный шаг вперед. При этом у развития ИИ есть потолок — например, вряд ли он сможет научиться абстрактному мышлению. Скорее всего, разработчики будут уделять больше внимания оптимизации ИИ-моделей, потому более крупным моделям будут требоваться все большие инвестиции при все меньшей отдаче.
Инновации будущего позволят повысить энергоэффективность ИИ
История вычислительной техники — это история непрерывных инноваций, которые распространяются в том числе и на энергоэффективность. С 2010 по 2018 год количество вычислительных ресурсов увеличилось на 550%, емкость хранилищ в крупных дата-центрах выросла на 2400%, а энергопотребление дата-центров увеличилось всего на 6%. Повышение энергоэффективности стало возможным благодаря усовершенствованию аппаратного обеспечения, виртуализации и дизайну дата-центров, и это одна из причин масштабирования облачных вычислений.
Вероятно, улучшения в аппаратном и программном обеспечении и дальше будут сдерживать темпы роста энергопотребления ИИ. Производители чипов будут создавать более эффективные графические процессоры для ИИ. Исследователи продолжают эксперименты с такими методами, как сокращение, квантование и дистилляция, для создания более компактных ИИ-моделей, которые работают быстрее и энергоэффективнее с минимальной потерей точности.
Оценка урона от ИИ-технологий игнорирует эффект замещения
Цифровые технологии заменяют атомы на биты и помогают декарбонизации экономики. Например, отправка электронного сообщения заменяет отправку письма по почте, просмотр фильма заменяет прокат DVD-диска, а участие в видеоконференции заменяет поездку на личную встречу.
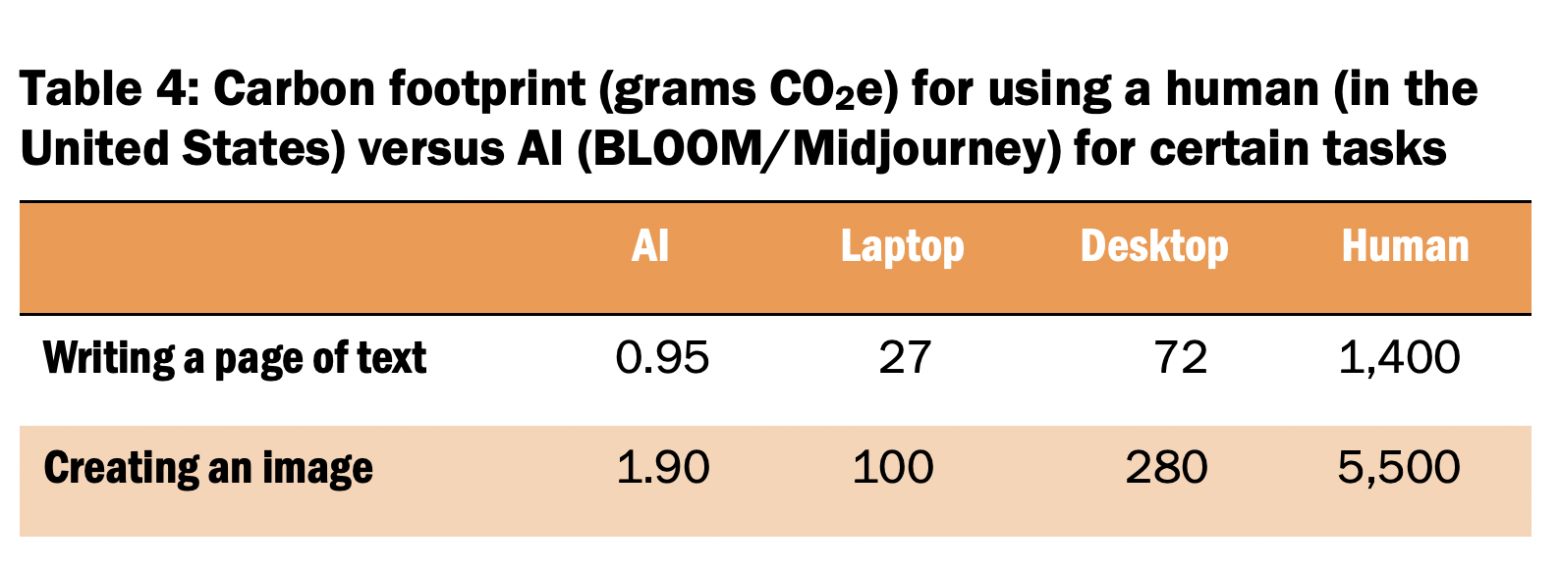
Исследование 2023 года сравнивает углеродный след, который оставляет человек и искусственный интеллект при написании страницы текста или создании иллюстрации. Рассмотрев выбросы CO₂ для разных моделей ИИ (ChatGPT, BLOOM, Midjourney и DALLE-2) и сравнив их с сотрудниками в США и Индии, исследователи обнаружили, что ИИ, пишущий страницу текста, выделяет в 130-1500 раз меньше CO₂, а ИИ, создающий изображение, выделяет в 310-2900 раз меньше CO₂, чем человек. ИИ не устраняет выброс CO₂ от человека, который существует, ест и дышит, но он устраняет выбросы от устройств, которые он использует для этих задач — ноутбуков или настольных компьютеров. Как показано в таблице 4, такая экономия может быть существенной, но обобщать эти результаты пока рано — вдруг упрощение создания текста и изображений приведет к увеличению объема работ.
Итак, учитывая огромные возможности использования ИИ на благо экономики и общества, включая переход к низкоуглеродному будущему, крайне важно, чтобы мы опирались на действительно корректные исследования о воздействии ИИ на окружающую среду.

