
Всем привет! Меня зовут Дмитрий Рейман, я техлид аналитической платформы Авито. Уже третий год мы занимаемся миграцией с Vertica на Trino. Изначально казалось, что это будет просто: перенесём запросы, перепишем коннекторы, чуть подправим пайплайны. Но за два с лишним года миграция перестала быть просто миграцией: проект разросся в инженерную одиссею, и вокруг Trino мы начали строить целую экосистему.

В предыдущей статье – «Миграция DWH Авито в Lakehouse. Начало» – мы подробно разобрали предпосылки этой миграции, рассказали, почему в какой-то момент классическая модель DWH перестала нас устраивать, как мы выбирали новый движок и с чего начинали переход к Lakehouse-архитектуре.
В этой статье я хочу сосредоточиться на следующем шаге: узких местах, с которыми мы столкнулись на практике, и на том, какую инфраструктуру и какие сервисы нам пришлось построить вокруг Trino, чтобы новая архитектура действительно заработала как единая и устойчиво масштабируемая система.
Trino в Авито: масштаб и сценарии

Сейчас Trino – один из ключевых элементов аналитической платформы Авито.
Ежедневно им пользуются около 500 человек: аналитики, разработчики, ML-инженеры и специалисты внутренних платформ.
Мы обрабатываем порядка 1.5 ПБ данных в сутки, включая:
ad-hoc аналитику;
витрины Datamart;
BI и отчётность;
Feature Store;
и постепенно мигрирующий ETL.
Чтобы выдерживать такую нагрузку, у нас работает более 20 кластеров Trino, развёрнутых на 200+ физических серверах.
Система исполняет свыше миллиона запросов в сутки, достигая пиков около 200 запросов в секунду.
Через Ceph, наш основной сторадж, проходит до 25 ГБ/с чтения под типичной рабочей нагрузкой.
Всего в хранилище более 50 000 таблиц и 20 миллионов партиций в разных слоях – от основного DWH до метрик и Feature Store. В сумме это около 1 ПБ данных.
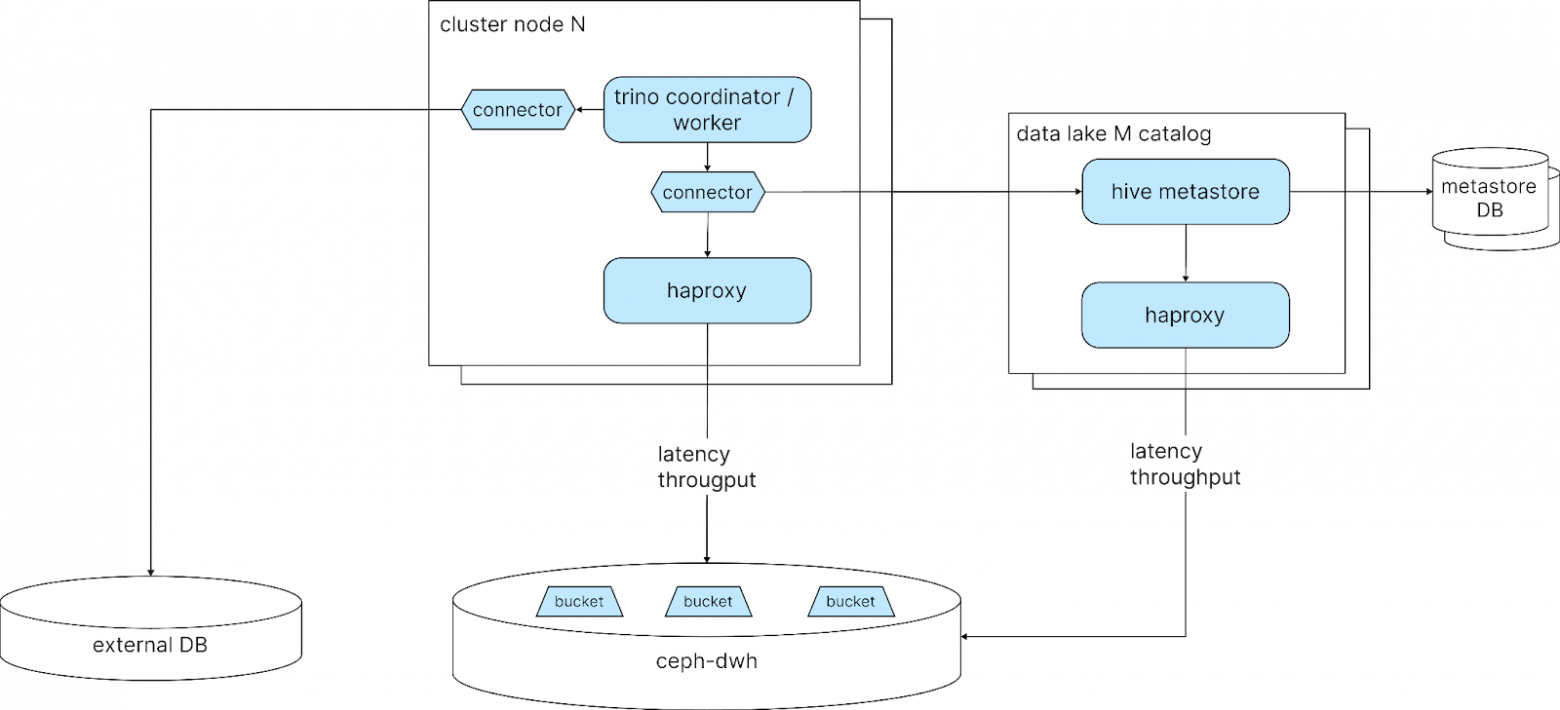
Помимо классического DWH мы также предоставляем Lakehouse как сервис, и Trino является его вычислительным ядром, но далеко не единственным компонентом. Вокруг него работает большой ландшафт сервисов: каталог, сторадж, кэши, балансировщики и прокси, коннекторы, контрол-плейн и инструменты управления жизненным циклом данных.
На первый взгляд может показаться, что Trino – это «готовый движок», который просто достаёшь из коробки. Но в реальности это ядро, вокруг которого приходится строить обширную экосистему.
Bottleneck #1: Хранилище
Данные мы храним в Ceph (S3-совместимом объектном хранилище) — с ним работают и Vertica, и Trino. Мы сознательно держим одинаковые схемы и наборы таблиц в обеих системах, чтобы пользователи не переписывали пайплайны и могли запускать одни и те же запросы в любой из них.
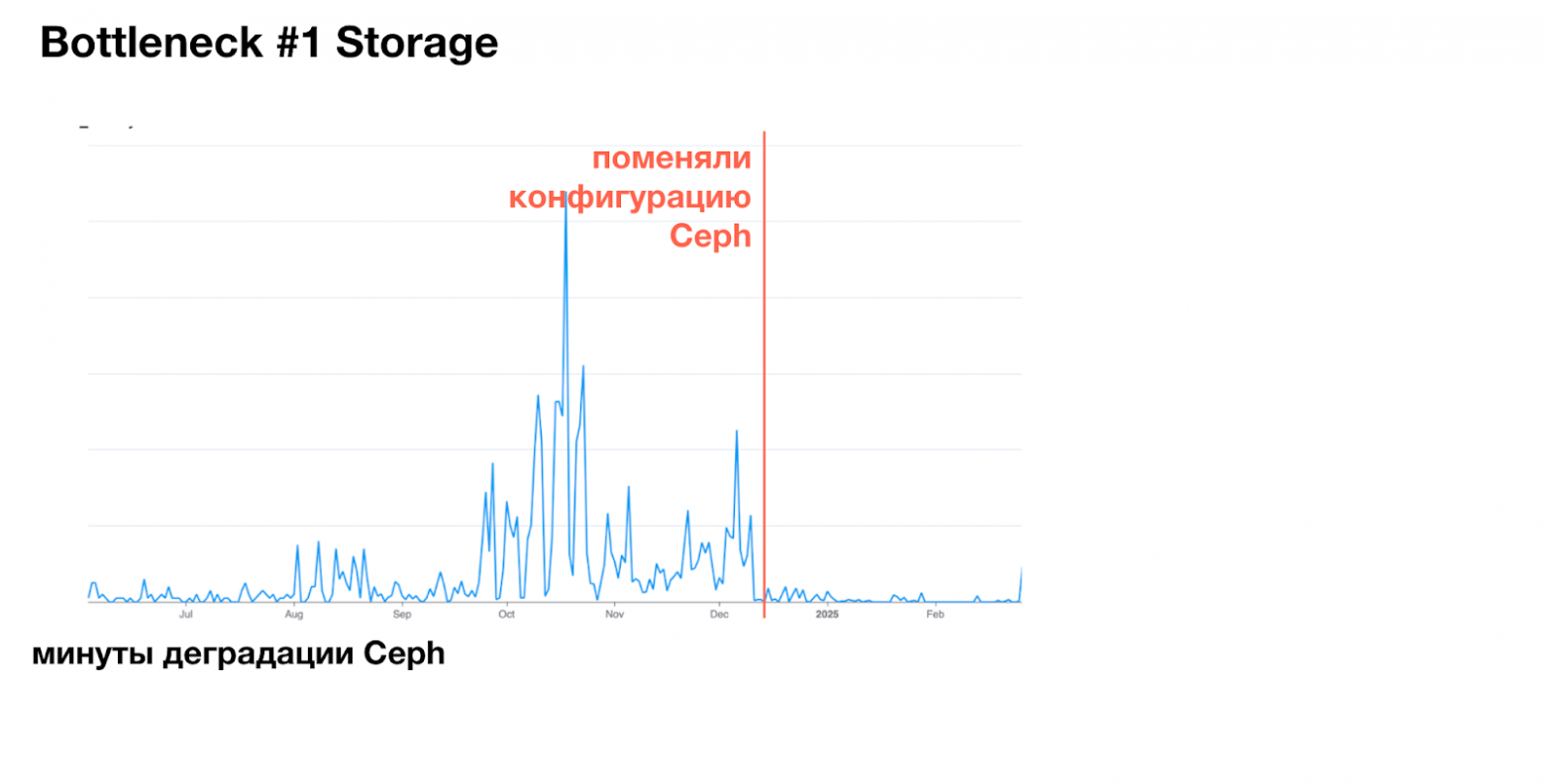
В какой-то момент мы обнаружили, что Ceph перестаёт выдерживать нагрузку. На графике минуты деградации: самый большой пик доходил до 500 минут, следующий — до 200. Ceph отвечал очень медленно, и вместе с ним проседали любые Table Scan-операции: регламентные расчёты тормозили, аналитика вставала, запросы выполнялись значительно дольше — недовольны были все.

Как мы до этого дошли?
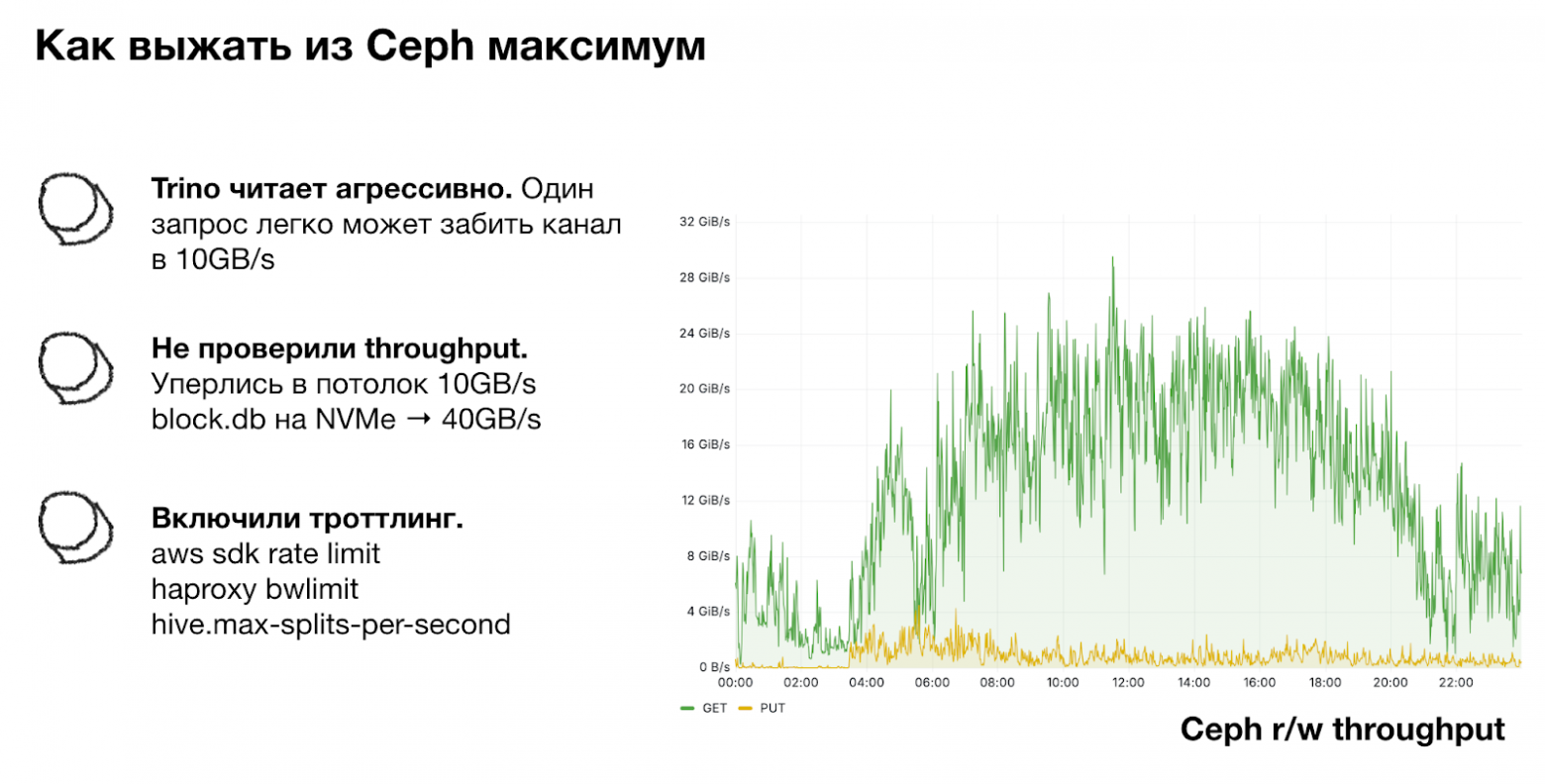
Начнём с базового факта: любая массово-параллельная система (MPP) стремится выполнять запросы как можно быстрее и как можно более параллельно. И Trino, и Vertica с этим отлично справляются. Но со временем мы увидели, что пропускная способность чтения стабильно упирается в ~10 ГБ/с.
На первый взгляд, 10 ГБ/с – не такая уж большая цифра для крупного кластера объектного хранилища. Наш Ceph работает на 500+ HDD-дисках: это дешёвое, но масштабное хранилище, рассчитанное на высокий параллелизм.
Однако в какой-то момент стало ясно, что мы упёрлись в потолок: даже если иногда замеры показывали 12 ГБ/с, было очевидно, что это далеко не предел. Теоретическая пропускная способн��сть нашего Ceph доходила до 40 ГБ/с, а мы использовали лишь небольшую часть этого потенциала.
Мы начали управлять нагрузкой:
сначала в Vertica через rate limit в AWS SDK,
потом поставили HAProxy между каждой воркер-нодой и Ceph (и в Vertica, и в Trino) и настроили bw_limit, сделав разные ограничения для людей и регламентных процессов,
в Trino пытались управлять throughput через настройку hive.max-splits-per-second.
Эти меры помогли сгладить пики: один запрос больше не мог забить весь канал. Но сам потолок остался прежним: примерно 10 ГБ/с. Расширение Ceph также ничего не изменило.
Кроме того, мы заметили важный эффект: активная запись приводила к деградации чтения примерно в соотношении 1 ГБ/с записи – минус 3 ГБ/с чтения. То есть любая интенсивная выгрузка данных напрямую «съедала» пропускную способность для аналитики.
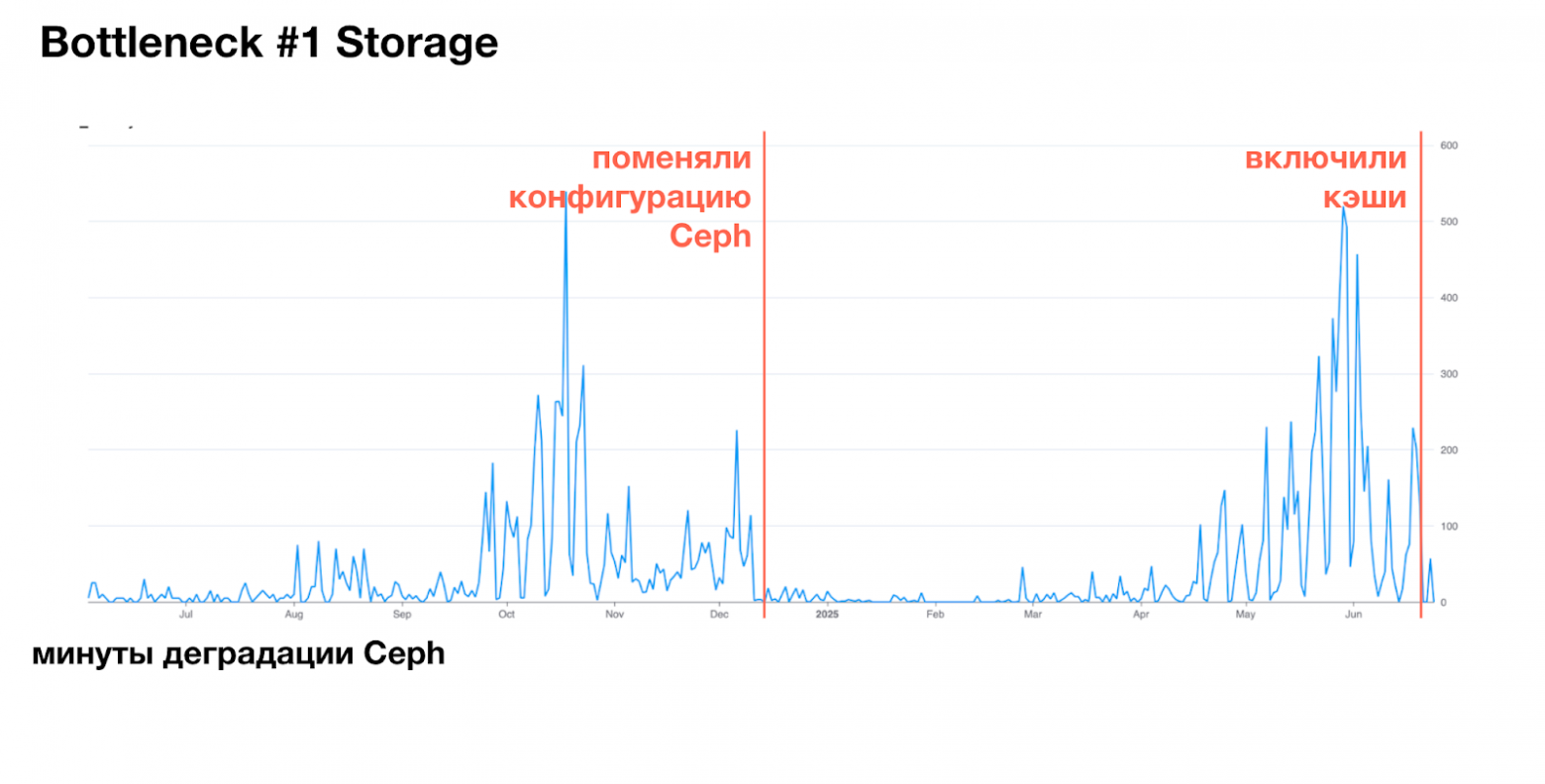
Отклик спасло то, что мы поменяли конфигурацию Ceph: вынесли хранение метаданных с HDD на NVMe. Это сразу подняло throughput с 10 до 40 ГБ/с. В нагрузочном тесте мы увидели потолок в 40 ГБ/с, а в реальной эксплуатации — до 25 ГБ/с, то есть комфортный запас примерно в 15 ГБ/с от пика. Мы расслабились: средняя нагрузка держалась на уровне 20 ГБ/с, запас есть – кажется, всё хорошо.
Мы выдохнули, но ненадолго. Когда на систему одновременно давили ETL и пользовательские запросы, история повторилась. Критичной оказалась именно нагрузка от ETL: мы начали переносить её в Trino, но только в июне наконец нашли root cause того, что происходило.
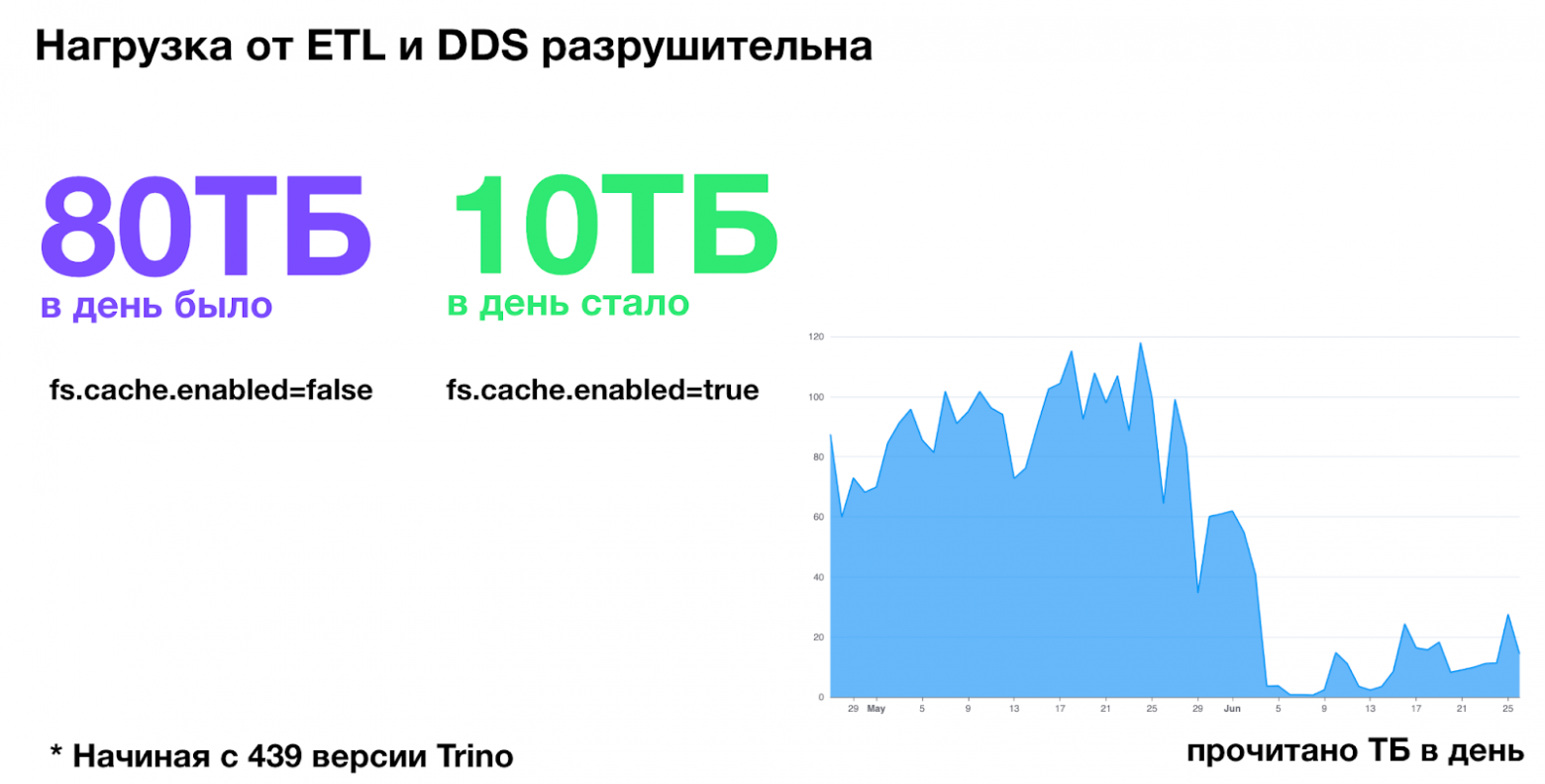
Тут нас выручила новая возможность Trino – локальные кэши, которые появились в версии 439. Мы включили их на нескольких кластерах, и в ряде сценариев нагрузка на Ceph упала в разы. Особенно это было заметно на повторяющихся пользовательских запросах и отчётных витринах: существенная часть данных стала читаться напрямую с локальных дисков воркеров, а не с Ceph.
S3 из коробки не работает под реальной нагрузкой. Просто положить данные в Ceph недостаточно. Нужно учиться читать.
Первый вывод, который мы сделали: Ceph «из коробки» не работает под реальной нагрузкой. Просто положи��ь данные в storage недостаточно – нужно уметь правильно читать из этого хранилища так, чтобы оно отвечало с приемлемой скоростью под реальными, постоянно меняющимися нагрузками.
Bottleneck #2: Каталог
Основной формат хранения у нас – Hive, хотя мы активно используем и Iceberg. Так сложилось не случайно: на момент начала миграции у нас уже была настроена репликация из Vertica в Hive, этот путь был самым простым и надёжным. Iceberg тогда ещё не обладал нужным для нас функционалом, поэтому мы сознательно не спешили с переходом.
В качестве каталога мы используем Hive Metastore: там расположены Hive-таблицы, а также через него умеет работать Iceberg – это сделало выбор каталога логичным и минимизировало издержки.
Однако, у каждого формата есть свой ряд проблем.
Hive – надёжный «старичок», проверенный временем, но он делает много лишней работы и болезненно реагирует на миллионы партиций. Мы начали использовать его ещё до появления Trino и даже до появления самого Metastore: данные выгружали из Vertica в Hive-формате, а в Vertica создавали внешние таблицы. Vertica выступала каталогом, Ceph хранилищем, и всё работало из коробки.
Проблемы начались не столько из-за формата, сколько из-за экосистемы вокруг него.
Да, Hive устарел, у него нет полноценного ACID, но для аналитики это не критично при правильном моделировании: витрины пересчитываются раз в сутки или несколько раз в день, и если кто-то в момент перезаписи поймает ошибку чтения – это терпимо.
Да, эволюция схемы работает со звёздочкой. Да, иногда приходится создавать виртуальные колонки для партиций. Но на масштабе Авито с этим можно жить – и мы живём.
Конечно, хотелось бы полностью перейти на Iceberg, но это потребовало бы серьёзных ресурсов на перенос и доработки, а приоритеты сейчас в другом. Поэтому Hive продолжает оставаться в работе.

С Hive Metastore (HMS) отдельная история: для нас это откровенный legacy. Он делает массу лишней работы. Например, постоянно листит файлы в Ceph, хотя это уже сделал Trino и просто просит у каталога метаданные. Получается, если Ceph работает медленно, начинают тормозить листинги, из-за чего в Trino замедляется и планирование, и выполнение запросов.
Metastore чувствителен к ресурсам: стоит ограничить CPU у базы, где хранятся метаданные, и он начинает подвисать.
Однажды мы попытались хранить в HMS партиции для наших гиперкубов: это несколько миллионов записей. Мы упёрлись в классическую O+1 проблему: Metastore начинал поштучно обрабатывать каждую партицию, и планирование запросов на таких таблицах выходило за 10 минут.
Ещё одна проблема: загрузка данных извне. Чтобы положить данные, нужно сначала записать их в Ceph, а затем зарегистрировать таблицу или партицию. Делать INSERT через Trino категорически не стоит. Большинство клиентов генерирует вставки по строкам, из-за чего каждая запись уходит в отдельный файл, что приводит к лавине мелких файлов и резкой деградации. Правильный путь ��� сначала загрузить файл в storage, а затем зарегистрировать метаданные. Но storage у нас чувствителен к нагрузке, и появление неконтролируемых потоков записи нам ни к чему.
В четвёртой версии Hive Metastore многие вещи поправили, но мы не спешим мигрировать, так как своими силами обошли узкие места и сфокусировались на других задачах.
Iceberg, наоборот, решает важные для нас задачи: обеспечивает атомарность операций и отлично работает с гиперкубами. После перехода на Iceberg-таблицы мы перестали хранить миллионы партиций в HMS. За счет этого мы выиграли время и ресурсы на операциях планирования и удаления.
Но и здесь есть свои ограничения. Стандартный Iceberg-коннектор в Trino пока уступает Hive-коннектору по производительности. Мы понимаем в какую сторону его можно развивать, но сейчас у нас нет ресурсов довести его до уровня Hive, стабильно работающего под нашей нагрузкой. Тем не менее, за время эксплуатации мы уже успели исправить несколько багов в Iceberg-коннекторе и продолжаем следить за его развитием.
У самого Iceberg есть ещё один нюанс: за таблицами нужно регулярно ухаживать. Однажды мы забыли включить обслуживание. За месяц метаданные разрослись почти до трёх терабайт – это тот случай, когда не сразу понимаешь, смеяться или плакать.
Экосистема вокруг Iceberg, конечно, взрослеет: когда мы начинали миграцию, не было ни одной стабильной реализации каталога. Сейчас вариантов больше, качество улучшилось, но для полного перехода нам всё ещё не хватает зрелости инструментов.
Универсального решения нет. Придется чем-то жертвовать и строить вокруг.
Мы остановились на компромиссе. Hive остаётся основой нашего большого DWH, а Iceberg используем точечно: в небольших платформах, где критична атомарность и требуются специфические сценарии обновления.
Bottleneck #3: ETL
А теперь самая спорная часть миграции: ETL в Trino.
В сообществе часто можно услышать мнение, что ETL через Trino – это плохая практика. Обычно рекомендуют Spark, а Trino только для ad-hoc.
Для нас путь был практически предопределён. В Vertica мы подключались к внешним источникам, читали данные и выполняли трансформации прямо в базе – весь наш ETL изначально жил внутри SQL-движка. Поэтому при миграции для нас естественным и понятным было повторить тот же подход в Trino.
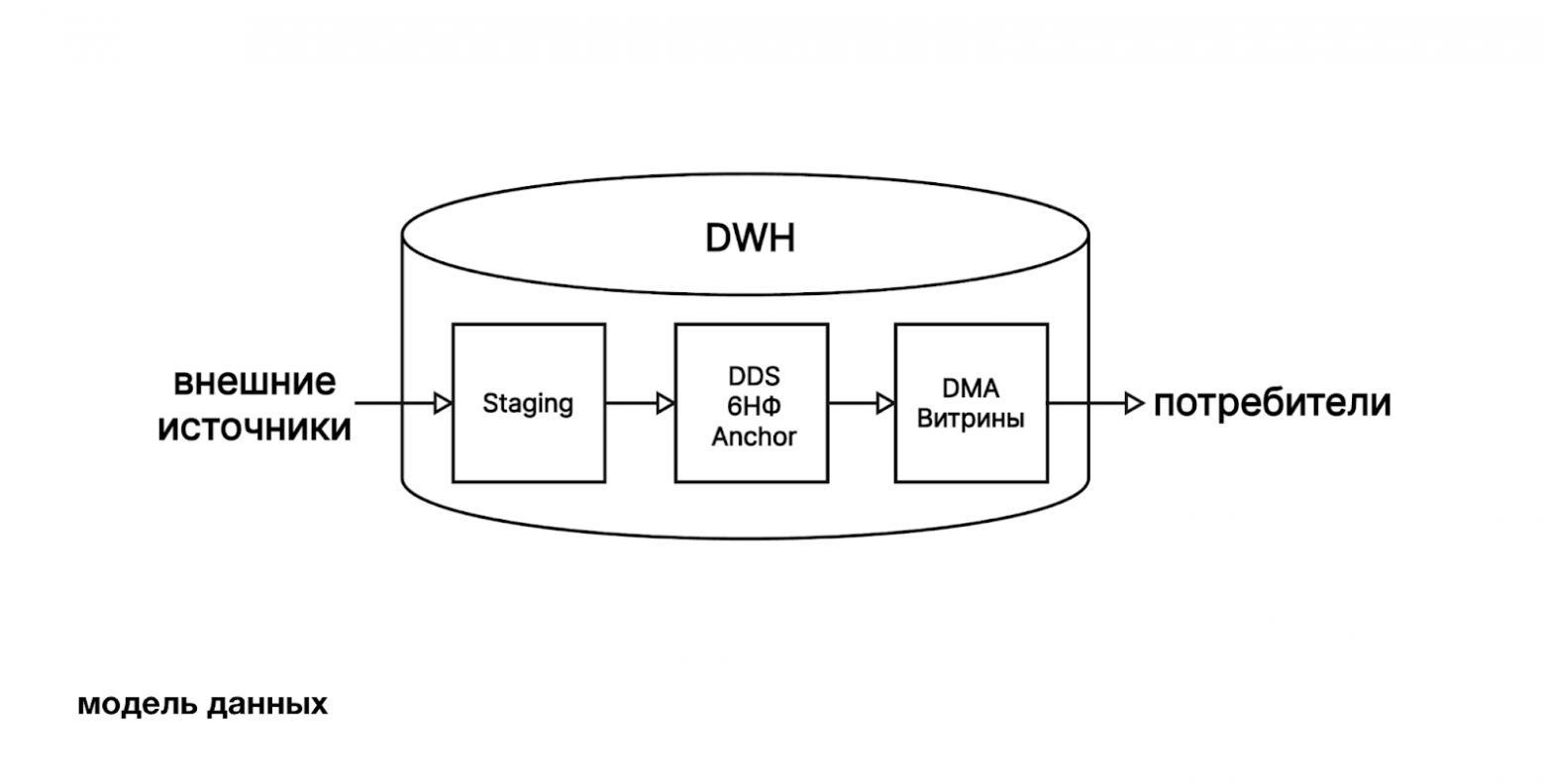
Мы проверили как Trino справляется с нагрузкой, и оказалось, что по чтению он работает не хуже Vertica. Кроме того, у нас уже были примеры крупных компаний, которые делают ETL через Trino, что дополнительно усилило уверенность в выборе. Сейчас мы используем Trino и для загрузки данных из внешних источников, и для раскладки данных в Anchor Model / 6НФ (DDS). Это те структуры, которые применяются аналитиками в ad-hoc и регулярных расчётах. Подробнее о том, что это такое и как мы это используем, можно прочитать в статье 2017 года.

Основная проблема – работа с большими DDS-таблицами. Без индекс��в и расширенной статистики Trino неизбежно читает много лишнего. А на наших объёмах часто ещё и не срабатывает pushdown динамического фильтра: из-за ограничения на его размер фильтр из join-а хоть и применяется, но уже после того, как данные полностью прочитаны с диска и разжаты. В итоге движок делает full scan – а для таблиц вроде item или cookie это +1-2 ТБ данных. Несколько параллельных запросов такого типа легко перегружают Ceph-кластер и заметно ухудшают отклик.
Частично ситуацию улучшили локальные кэши. Поскольку DDS – append-only, значительную часть данных удаётся держать на локальных дисках рабочих узлов, что существенно снижает нагрузку на Ceph.
Но помимо сложностей, сам Trino дал нам и важное преимущество – возможность спрятать 6НФ за удобным интерфейсом широких таблиц. Мы разработали плагин, который выполняет локальный N-way merge join и не требует загружать все данные в память. Нагрузка на Trino заметно снизилась, а пользователи получили простой и привычный SQL-интерфейс.
Еще один отдельный блок: загрузка данных из внешних источников. В Vertica мы активно использовали UDx и федеративные запросы, поэтому в Trino логично было реализовать похожий подход. Постепенно мы развили целый набор коннекторов: можем описывать API-эндпоинты как таблицы и работать с ними как с реляционными; читать данные из S3, Nextcloud и SFTP; обрабатывать файлы в разных форматах, включая Excel; подключать базы – Mongo, Kafka и другие.
Чтобы представлять внешние источники в виде таблиц, нам понадобился каталог. В Vertica он был встроенным, а для Trino пришлось делать собственный. Iceberg-каталог для этой задачи оказался избыточным, а Hive Metastore мы сознательно не стали использовать из-за его legacy-природы и ограничений. В итоге мы разработали свой каталог для хранения метаданных. Он разблокировал миграцию ETL и открыл широкие возможности для интеграций. Более того, теперь разные команды внутри компании могут создавать собственные коннекторы к внешним источникам и регистрировать их в этом каталоге.

Таким образом, ETL в Trino возможен. С локальными кэшами, доработкой динамических фильтров и собственным DDS-движком он стал эффективным инструментом для наших задач.
Bottleneck #4: Репликация и миграция
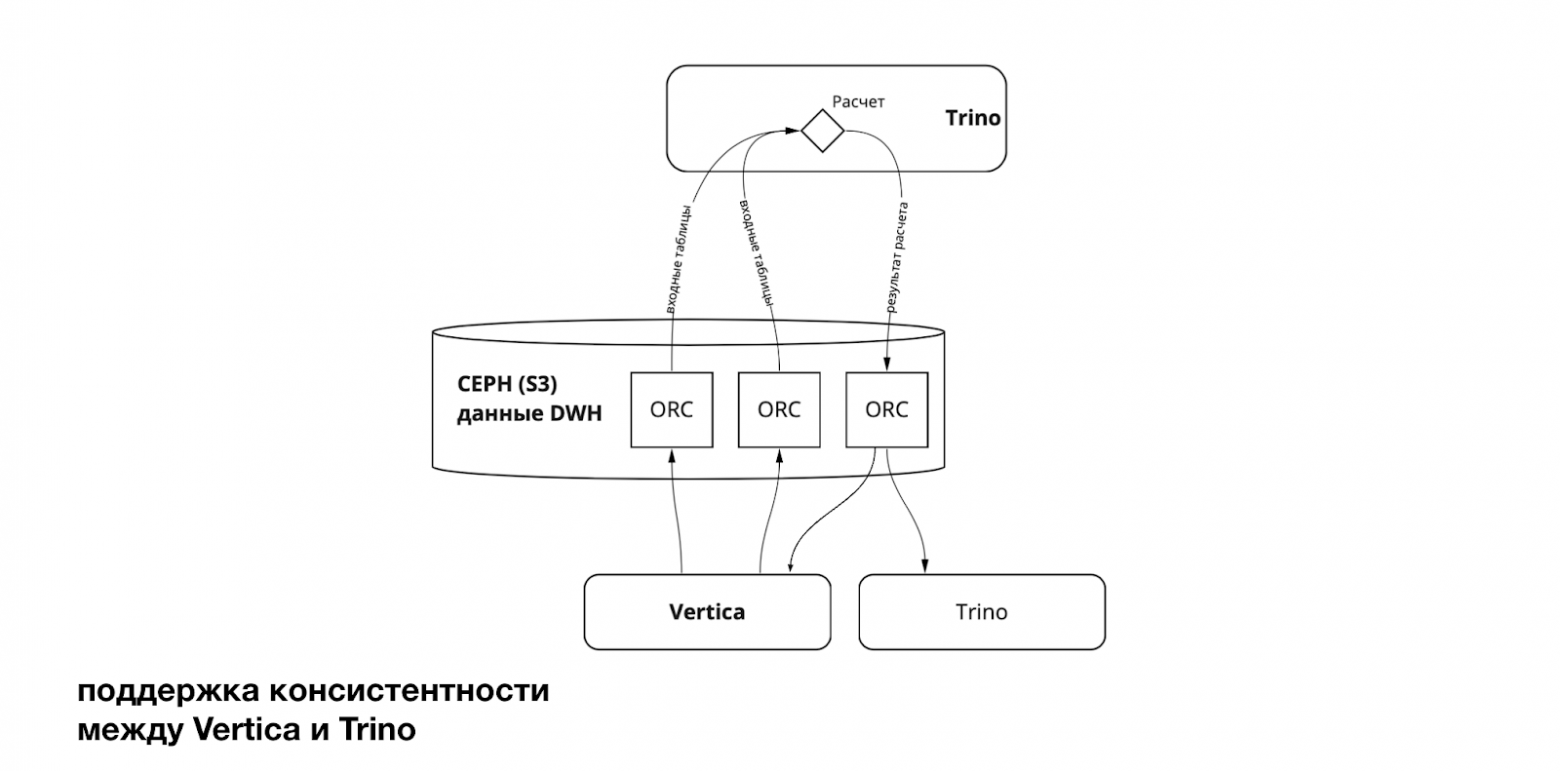
Хочется поделиться деталями самой миграции: как она идёт и где мы находимся сейчас. Напомню важный момент архитектуры: мы поддерживаем консистентность между Vertica и Trino, поэтому данные должны постоянно и надёжно реплицироваться в Ceph.
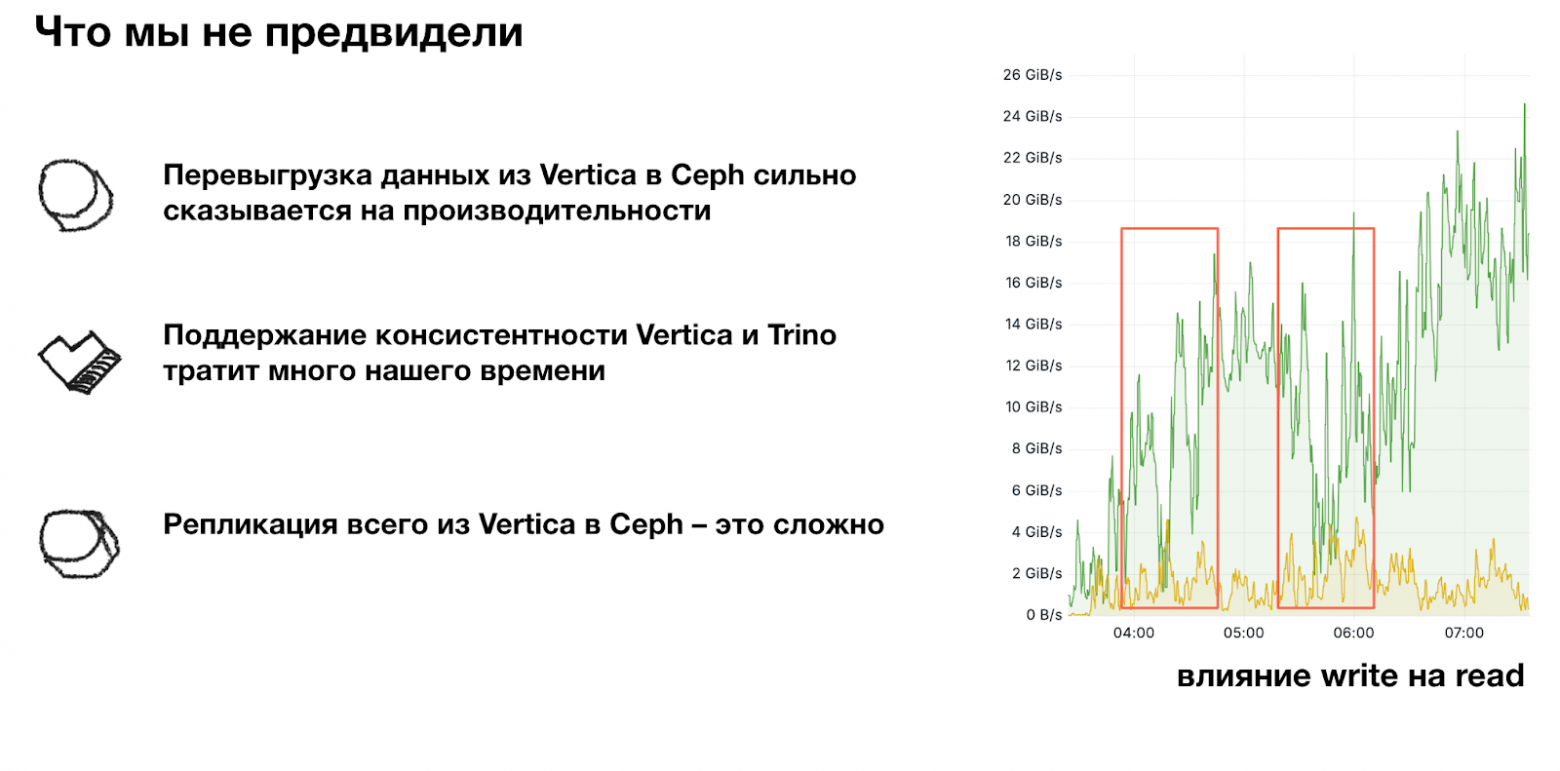
Одним из самых неприятных сюрпризов стали резкие провалы пропускной способности на чтение, вызванные активной записью при выгрузке данных из Vertica в Ceph. Логично: HDD-диски постоянно забиты записью, и ресурсов на чтение просто не остаётся. Но в таких масштабах мы к этому не были готовы.
Ещё одна проблема – сама Vertica. Полная выгрузка таблиц съедает огромное количество её ресурсов. Казалось бы, самый простой способ поддерживать консистентность – раз в день выгружать таблицу целиком. Но у нас уже больше петабайта данных, и ежедневно такие объёмы не выдержит ни Vertica, ни Ceph.
Поэтому мы начали оптимизировать объём выгрузки.
Для витрин всё относительно просто: они регулярно пересчитываются и партиционированы, поэтому мы просто перевыгружаем новые и изменённые партиции.
Но с DDS всё сложнее: там нет партиционирования. Некоторые хабы – например, cookie или item – занимают несколько терабайт. Полная выгрузка таких таблиц каждый день – это часы работы и прямой удар по SLA зависимых пайплайнов.
Выходом стало инкрементальное обновление. Мы научились выгружать из Vertica только новые данные, опираясь на epoch. Это сильно сократило объём выгрузки, но принесло новые сложности.

Инкрементальная выгрузка привела к появлению множества мелких файлов, что заметно ухудшает эффективность чтения. Пришлось добавить компакшн. Но компакшн тоже требует ресурсов, а пропускная способность Ceph ограничена. Получилось, что мы разгрузили одну часть системы и тут же создали нагрузку в другой. И вот тут мы поняли, что выгрузка ≠ просто «сохранить данные». Это целая отдельная система.
В итоге решение, которое казалось простой инженерной задачей, превратилось в длинную цепочку доработок и архитектурных изменений. Пришлось менять процессы, инструменты, форматы данных, оптимизировать весь контур задержек и очень внимательно следить за балансом нагрузки между Vertica, Trino и Ceph.
Тем не менее, несмотря на все сложности, за последние два года мы продвинулись очень далеко. Напомню: хранилище в Авито существует уже больше 10 лет, и «просто взять и мигрировать всё сразу» невозможно. Это даже звучит смешно в нашем масштабе.
На текущий момент мы пришли к следующим результатам:
примерно половина витрин (около 2500) уже считается в Trino;
более 70% аудитории аналитической платформы ежедневно работают именно в Trino;
скорость расчётов сопоставима с Vertica, и на этом направлении у нас нет проблем.
Это всё ещё путь, и он требует времени, но фундамент уже заложен, а миграция идёт уверенно и предсказуемо.
Итоги

Главный вывод: Trino – это мощное ядро, но его ценность раскрывается только в связке с грамотной инфраструктурой вокруг. Хранилище, каталоги, ETL, коннекторы – всё это требует внимания и доработок.
Мы ни разу не пожалели, что пошли на миграцию, но устали от её масштабов. И если вы думаете, что заменить движок просто, то будьте готовы, что в процессе вы построите целую экосистему, о которой изначально даже не думали.
TL;DR Жалеем ли мы, что выбрали Trino? Нет. Устали ли мы от миграции? Да, очень устали.
А вы пробовали строить аналитику на Trino? С какими узкими местами сталкивались и как их решали? Расскажите об этом в комментариях!
В следующей статье серии мы подробнее поговорим о сторидже и о том, как объектное хранилище из фонового компонента архитектуры превратилось в один из ключевых факторов, определяющих ограничения, проблемы и инженерные решения Lakehouse-платформы.
