Современный Deep Learning уперся в производительность вычислений с плавающей точкой и пропускную способность памяти. Мы предлагаем архитектуру, где нейрон — это не сумма произведений, а битовая хэш-функция. Ноль умножений, ноль сложений. Только логика и статистика.
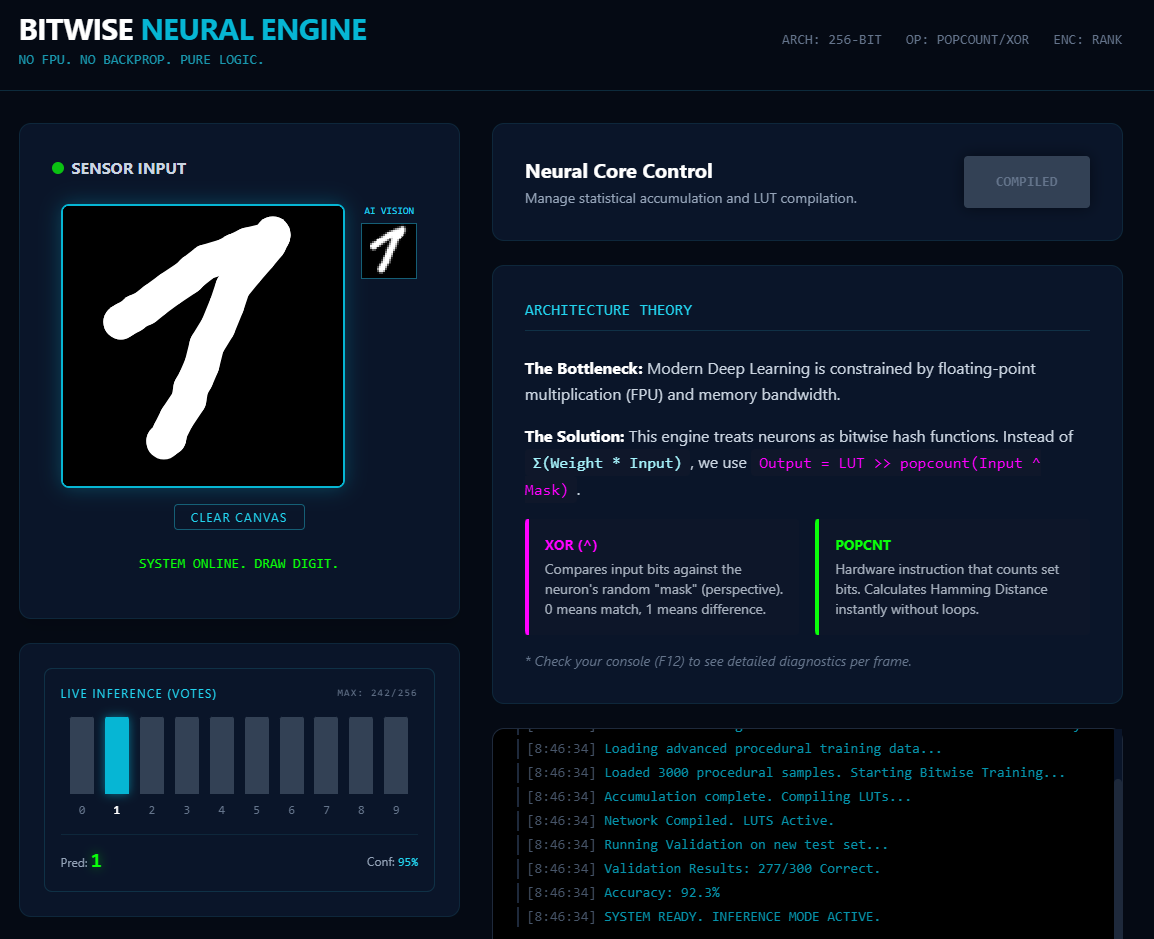
Концепт: Нейрон как компаратор
Классический нейрон: Activation(Sum(Weight * Input))
Наш нейрон: Output = A[ popcount( Input XOR Mask ) ]
Разберем формулу:
Input (64 бита): Входные данные.
Mask (64 бита): «Взгляд» нейрона. Фиксированный случайный (для изображений) или не случайный (для текста) шаблон.
XOR: Битовое сравнение. 0 — совпадение, 1 — отличие.
popcount: Аппаратная инструкция процессора (Population Count). Считает количество единиц в слове. Это Дистанция Хэмминга — насколько вход отличается от маски (число от 0 до 64).
A [...] (LUT): Массив отклика. Это память нейрона, где хранится его «опыт».
Массив A: Эволюция от статистики к биту
Самое важное — как живет и меняется массив A.
1. Обучение (Накопление) *Концепт
На этапе обучения A — это массив счетчиков (например, uint16 размером 65 ячеек).
Подаем пример.
Вычисляем дистанцию dist = popcount( Input XOR Mask ).
Если пример «полезный» — делаем A[dist]++.
Мы просто копим гистограмму: при каком расстоянии Хэмминга этот нейрон должен активироваться.
2. Компиляция (Порог)
Обучение закончено. Мы превращаем «жирные» счетчики в чистую логику.
Применяем Threshold:
Если A[i] > порог — записываем 1.
Иначе — 0.
Теперь массив A — это набор битов. Так как индексов всего 65 (от 0 до 64), весь массив A сжимается в одно 64-битное целое число.
3. Инференс (Скорость)
В рабочем режиме нейрон — это два регистра процессора: Mask и сжатый A.
Логика умещается в 4 инструкции ассемблера:
XOR (Сравнить маску и вход)
POPCNT (Получить дистанцию)
SHIFT (Сдвинуть сжатый массив A на величину дистанции)
AND (Взять младший бит)
Никакого FPU. Теоретическая производительность ограничена только частотой процессора.
Попробовать нейросеть в деле можно здесь:
https://schoolscience.org/bit_nn/
Let the bitwise revolution begin!

