 Недавно вышел новый FineReader for Mac – и пора про него написать пару слов. Признаюсь, я был первым человеком в компании, который решил полностью перейти на Mac в своей работе еще в далеком уже сейчас 2006 году. ABBYY до того делала в основном продукты только для Windows, и лишь немного для остальных платформ. Я тогда регулярно ходил в департамент FineReader и ныл, что у нас нет нормального FineReader для Mac (была только устаревшая версия для PowerPC), но потом прекратил нытье, и сел программировать. С тех пор утекло много воды, но мое усилие не прошло даром, и запустило процесс создания обновленных версий FineReader for Mac. Именно поэтому я к этому продукту очень неровно дышу.
Недавно вышел новый FineReader for Mac – и пора про него написать пару слов. Признаюсь, я был первым человеком в компании, который решил полностью перейти на Mac в своей работе еще в далеком уже сейчас 2006 году. ABBYY до того делала в основном продукты только для Windows, и лишь немного для остальных платформ. Я тогда регулярно ходил в департамент FineReader и ныл, что у нас нет нормального FineReader для Mac (была только устаревшая версия для PowerPC), но потом прекратил нытье, и сел программировать. С тех пор утекло много воды, но мое усилие не прошло даром, и запустило процесс создания обновленных версий FineReader for Mac. Именно поэтому я к этому продукту очень неровно дышу.К счастью, вышедший сейчас FineReader for Mac практически не имеет отношения к тому, что я тогда напрограммировал. Он стильный, быстрый и удобный. Он намного функциональнее FineReader Express for Mac, который был до сих пор. Я не буду делать подробный обзор продукта, потому что хорошие программы не выигрывают от расчленения на куски, как это принято делать в жанре традиционного обзора. Я лишь напишу, чем, с моей точки зрения, этот продукт отличается от его тезки для Windows.
Отличается от тем, что он проще (и, на мой вкус, изящней). FineReader для Windows буквально нашпигован возможностями. В полной совокупности они нужны только продвинутым пользователям, которых мы очень ценим и любим. Но среди людей, которым нужно иногда получить текст документа для редактирования, эти продвинутые пользователи составляют лишь небольшую часть. Такова судьба большинства зрелых продуктов: они растут с годами, наполняются фичами, от которых уже невозможно никуда подеваться, и которые, возможно, не очень часто применяются, но есть преданные пользователи, которым они нужны, и мы вынуждены эти фичи поддерживать.
В версии для Mac у нас была возможность посмотреть на проблему свежим взглядом, и сконцентрироваться на функциональности, которая нужна большинству пользователей, не слишком уходя в дебри сложных фич. Получился легкий продукт с минимальным набором удобных и интуитивно простых средств управления. Выглядит он очень по-маковски, и мало чем похож на своего собрата для платформы Windows.
Исходная идея была следующая. Само по себе качество OCR на современных документах таково, что ошибки распознавания самого потока текста случаются очень редко, ну разве только если исходное изображение совсем плохое. Однако при сложной верстке, в случае всевозможных хитрых таблиц, картинок со сложным контуром возникают ошибки анализа документа, которые приводят к трудноисправимым дефектам на выходе. Поэтому в первую очередь пользователю нужны инструменты улучшения самой картинки, если с ней есть проблемы, а также исправления результатов анализа расположения информации на странице.
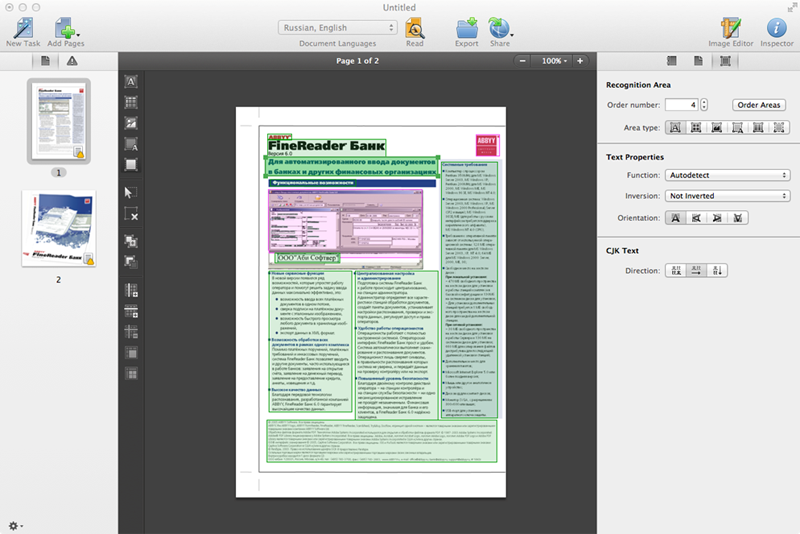
Именно эти две компоненты и добавлены в первую очередь в FineReader. Ну и есть удобный инструмент работы с документом: удаления и добавления страниц, перестановки страниц и т.д.
В результате, даже если система не угадала, как расположен текст в вашем сложном документе, небольшими усилиями вы можете помочь ей получить на выходе качественный результат.
Правда, одной важной функции мне все еще не хватает в новом продукте. И не только мне, судя по отзывам пользователей. Не хватает возможности работы с полученным текстом внутри продукта. Правда, в вопросе о том, как эта функция должна быть реализована, мнения разделились. Есть традиционная реализация, как это сделано в Windows-версии FineReader, с помощью встроенного редактора. Такой подход существовал с незапамятных времен. Мне эта идея не очень нравится, и я попытаюсь привести свои доводы.
Дело в том, что встроенный редактор, каким совершенным бы он ни был, не способен конкурировать с тем же Microsoft Word или LibreOffice с точки зрения полноты отображения текста. А это значит, что делая мало-мальски сложные правки в тексте, вы рискуете его окончательно «сломать», когда, будучи загруженным во внешний редактор, он поплывет, став совершенно не похожим на оригинал, и могут потребоваться значительные усилия, чтобы восстановить форматирование. И с какой стати, вообще говоря, вам нужно делать такие сложные правки в самом FineReader? Единственное, почему стоит править текст внутри OCR-продукта, это из-за наличия возможности быстро сверить конкретные слова с их изображениями в исходном тексте, чтобы убедиться, что ошибок нет. Любые сложные правки форматирования лучше делать там, где вы будете готовить окончательный документ.
Поэтому никакой полноценный редактор, с моей точки зрения, в FineReader for Mac не нужен. Все, что нужно – это удобный спеллер, показывающий пользователю сомнительные и несловарные слова вместе с изображением окрестности проверяемого слова в исходном изображении. Но это моя точка зрения. Если она возобладает, то такая функция может появиться в FineReader for Mac относительно быстро.
Хотелось бы в комментариях услышать ваши мнения.
Арам Пахчанян,
директор департамента продуктов для ввода данных
