Введение
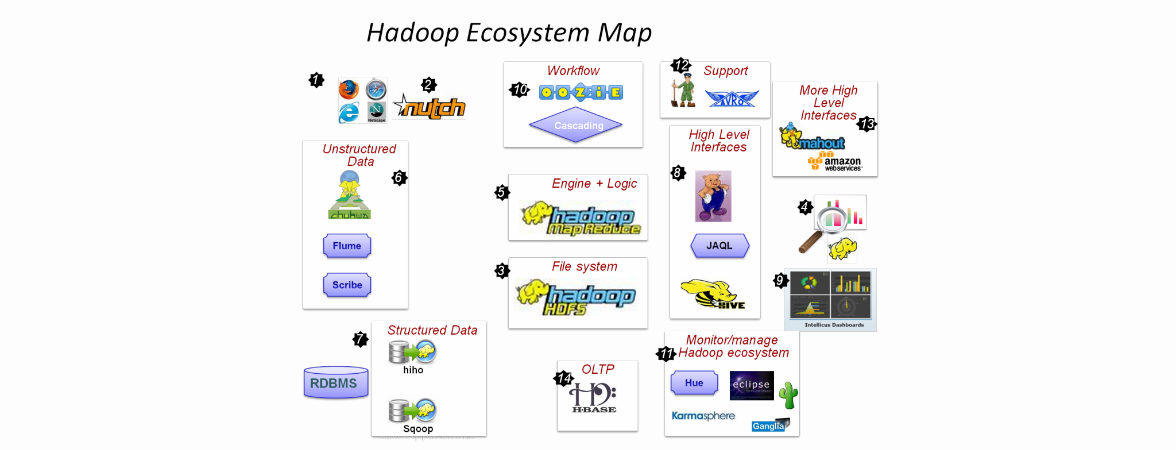
Как человеку с не очень устойчивой психикой, мне достаточно одного взгляда на картинку, подобную этой, для начала панической атаки. Но я решил, что страдать буду только сам. Цель статьи — сделать так, чтобы Hadoop выглядел не таким страшным.
Что будет в этой статье:
- Разберем, из чего состоит фреймворк и зачем он нужен;
- разберем вопрос безболезненного развертывания кластера;
- посмотрим на конкретный пример;
- немного коснемся новых фич Hadoop 2 (Namenode Federation, Map/Reduce v2).
Чего не будет в этой статье:
- вообще статья обзорная, поэтому без сложностей;
- не будем лезть в тонкости экосистемы;
- не будем зарываться глубоко в дебри API;
- не будем рассматривать все околоdevops-задачи.
Что такое Hadoop и зачем он нужен
Hadoop не так уж сложен, ядро состоит из файловой системы HDFS и MapReduce фреймворка для обработки данных из этой файловой системы.
Если смотреть на вопрос «зачем нам нужен Hadoop?» с точки зрения использования в крупном энтерпрайзе, то ответов достаточно много, причем варьируются они от «сильно за» до «очень против». Я рекомендую просмотреть статью ThoughtWorks.
Если смотреть на этот же вопрос уже с технической точки зрения — для каких задач нам есть смысл использовать Hadoop — тут тоже не все так просто. В мануалах в первую очередь разбираются два основных примера: word count и анализ логов. Ну хорошо, а если у меня не word count и не анализ логов?
Хорошо бы еще и определить ответ как-нибудь просто. Например, SQL — нужно использовать, если у вас есть очень много структурированных данных и вам очень хочется с данными поговорить. Задать как можно больше вопросов заранее неизвестной природы и формата.
Длинный ответ —просмотреть какое-то количество существующих решений и собрать неявным образом в подкорке условия, для которых нужен Hadoop. Можно ковыряться в блогах, могу еще посоветовать прочитать книгу Mahmoud Parsian «Data Algorithms: Recipes for Scaling up with Hadoop and Spark».
Попробую ответить короче. Hadoop следует использовать, если:
- Вычисления должны быть компонуемыми, другими словами, вы должны иметь возможность запустить вычисления на подмножестве данных, а затем слить результаты.
- Вы планируете обрабатывать большой объем неструктурированных данных — больше, чем можно уместить на одной машине (> нескольких терабайт данных). Плюсом здесь будет возможность использовать commodity hardware для кластера в случае Hadoop.
Hadoop не следует использовать:
- Для некомпонуемых задач — например, для задач рекуррентных.
- Если весь объем данных умещается на одной машине. Существенно сэкономите время и ресурсы.
- Hadoop в целом — система для пакетной обработки и не подходит для анализа в режиме реального времени (здесь на помощь приходит система Storm).
Архитектура HDFS и типичный Hadoop кластер
HDFS подобна другим традиционным файловым системам: файлы хранятся в виде блоков, существует маппинг между блоками и именами файлов, поддерживается древовидная структура, поддерживается модель доступа к файлам основанная на правах и т. п.
Отличия HDFS:
- Предназначена для хранения большого количества огромных (>10GB) файлов. Одним Следствие — большой размер блока по сравнению с другими файловыми системами (>64MB)
- Оптимизирована для поддержки потокового доступа к данным (high-streaming read), соответственно производительность операций произвольного чтения данных начинает хромать.
- Ориентирована на использование большого количество недорогих серверов. В частности, серверы используют JBOB структуру (Just a bunch of disk) вместо RAID — зеркалирование и репликация осуществляются на уровне кластера, а не на уровне отдельной машины.
- Многие традиционные проблемы распределенных систем заложены в дизайн — уже по дефолту все выход отдельных нод из строя является совершенно нормальной и естественной операцией, а не чем-то из ряда вон.
Hadoop-кластер состоит из нод трех типов: NameNode, Secondary NameNode, Datanode.
Namenode — мозг системы. Как правило, одна нода на кластер (больше в случае Namenode Federation, но мы этот случай оставляем за бортом). Хранит в себе все метаданные системы — непосредственно маппинг между файлами и блоками. Если нода 1 то она же и является Single Point of Failure. Эта проблема решена во второй версии Hadoop с помощью Namenode Federation.
Secondary NameNode — 1 нода на кластер. Принято говорить, что «Secondary NameNode» — это одно из самых неудачных названий за всю историю программ. Действительно, Secondary NameNode не является репликой NameNode. Состояние файловой системы хранится непосредственно в файле fsimage и в лог файле edits, содержащим последние изменения файловой системы (похоже на лог транзакций в мире РСУБД). Работа Secondary NameNode заключается в периодическом мерже fsimage и edits — Secondary NameNode поддерживает размер edits в разумных пределах. Secondary NameNode необходима для быстрого ручного восстанавления NameNode в случае выхода NameNode из строя.
В реальном кластере NameNode и Secondary NameNode — отдельные сервера, требовательные к памяти и к жесткому диску. А заявленное “commodity hardware” — уже случай DataNode.
DataNode — Таких нод в кластере очень много. Они хранят непосредственно блоки файлов. Нода регулярно отправляет NameNode свой статус (показывает, что еще жива) и ежечасно — репорт, информацию обо всех хранимых на этой ноде блоках. Это необходимо для поддержания нужного уровня репликации.
Посмотрим, как происходит запись данных в HDFS:
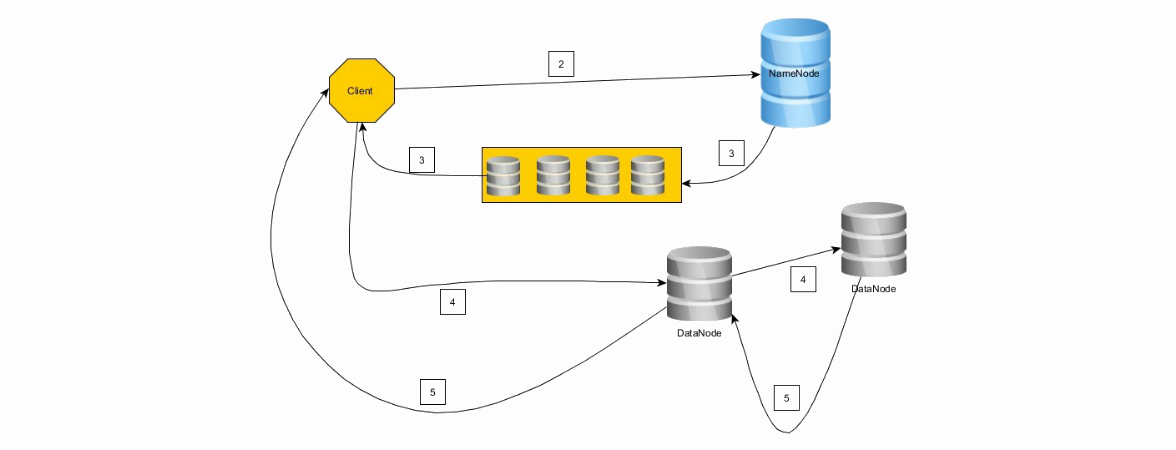
1. Клиент разрезает файл на цепочки блокового размера.
2. Клиент соединяется с NameNode и запрашивает операцию записи, присылая количество блоков и требуемый уроень репликации
3. NameNode отвечает цепочкой из DataNode.
4. Клиент соединяется с первой нодой из цепочки (если не получилось с первой, со второй и т. д. не получилось совсем — откат). Клиент делает запись первого блока на первую ноду, первая нода — на вторую и т. д.
5. По завершении записи в обратном порядке (4 -> 3, 3 -> 2, 2 -> 1, 1 -> клиенту) присылаются сообщения об успешной записи.
6. Как только клиент получит подтверждение успешной записи блока, он оповещает NameNode о записи блока, затем получает цепочку DataNode для записи второго блока и т.д.
Клиент продолжает записывать блоки, если сумеет записать успешно блок хотя бы на одну ноду, т. е. репликация будет работать по хорошо известному принципу «eventual», в дальнейшем NameNode обязуется компенсировать и таки достичь желаемого уровня репликации.
Завершая обзор HDFS и кластера, обратим внимание на еще одну замечательную особенность Hadoop'а — rack awareness. Кластер можно сконфигурировать так, чтобы NameNode имел представление, какие ноды на каких rack'ах находятся, тем самым обеспечив лучшую защиту от сбоев.
MapReduce
Единица работы job — набор map (параллельная обработка данных) и reduce (объединение выводов из map) задач. Map-задачи выполняют mapper'ы, reduce — reducer'ы. Job состоит минимум из одного mapper'а, reducer'ы опциональны. Здесь разобран вопрос разбиения задачи на map'ы и reduce'ы. Если слова «map» и «reduce» вам совсем непонятны, можно посмотреть классическую статью на эту тему.
Модель MapReduce
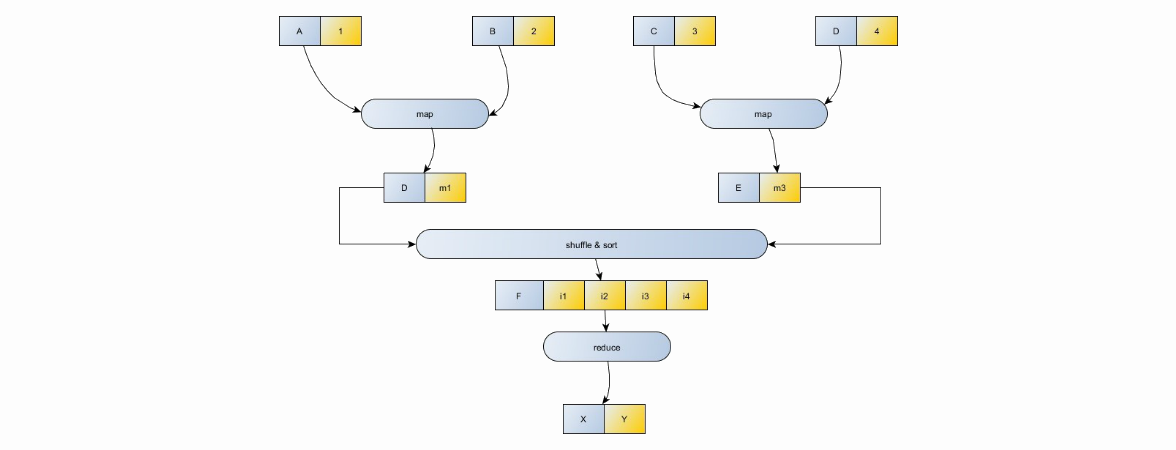
- Ввод/вывод данных происходит в виде пар (key, value)
- Используются две функции map: (K1, V1) -> ( (K2, V2), (K3,V3), ...) — отображающая пару ключ-значение на некое множество промежуточных пар ключей и значений, а также reduce: (K1, (V2,V3,V4,VN)) -> (K1, V1), отображающая некоторое множество значений, имеющий общий ключ на меньшее множество значений.
- Shuffle and sort нужна для сортировки ввода в reducer по ключу, другими словами, нет смысла отправлять значение (K1, V1) и (K1, V2) на два разных reducer'а. Они должны быть обработаны вместе.
Посмотрим на архитектуру MapReduce 1. Для начала расширим представление о hadoop-кластере, добавив в кластер два новых элемента — JobTracker и TaskTracker. JobTracker непосредственно запросы от клиентов и управляет map/reduce тасками на TaskTracker'ах. JobTracker и NameNode разносится на разные машины, тогда как DataNode и TaskTracker находятся на одной машине.
Взаимодействие клиента и кластера выглядит следующим образом:
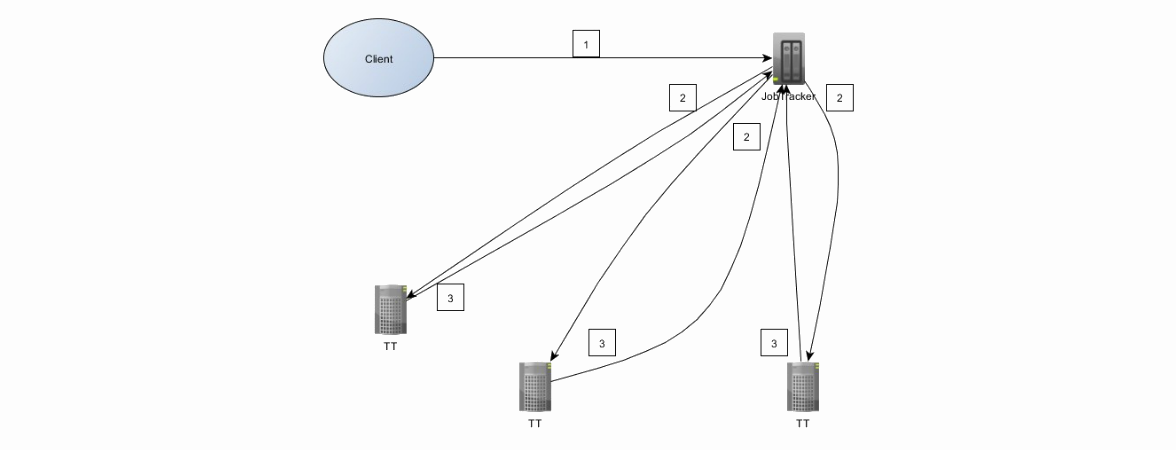
1. Клиент отправляет job на JobTracker. Job представляет из себя jar-файл.
2. JobTracker ищет TaskTracker'ы с учетом локальности данных, т.е. предпочитая те, которые уже хранят данные из HDFS. JobTracker назначает map и reduce задачи TaskTracker'ам
3. TaskTracker'ы отправляют отчет о выполнении работы JobTracker'у.
Неудачное выполнение задачи — ожидаемое поведение, провалившиеся таски автоматически перезапускаются на других машинах.
В Map/Reduce 2 (Apache YARN) больше не используется терминология «JobTracker/TaskTracker». JobTracker разделен на ResourceManager — управление ресурсами и Application Master — управление приложениями (одним из которых и является непосредственно MapReduce). MapReduce v2 использует новое API
Настройка окружения
На рынке существуют несколько разных дистрибутивов Hadoop: Cloudera, HortonWorks, MapR — в порядке популярности. Однако мы заострять внимание на выборе конкретного дистрибутива не будем. Подробный анализ дистрибутивов можно найти здесь.
Есть два способа безболезненно и с минимальными трудозатратами попробовать Hadoop:
1. Amazon Cluster — полноценный кластер, но этот вариант будет стоить денег.
2. Скачать виртуальную машину (мануал №1 или мануал №2). В этом случае минусом будет, что все сервера кластера крутятся на одной машине.
Перейдем к способам болезненным. Hadoop первой версии в Windows потребует установки Cygwin. Плюсом здесь будет отличная интеграция со средами разработки (IntellijIDEA и Eclipse). Подробнее в этом замечательном мануале.
Начиная со второй версии, Hadoop поддерживает и серверные редакции Windows. Однако я бы не советовал пытаться использовать Hadoop и Windows не только в production'e, но и вообще где-то за пределами компьютера разработчика, хотя для этого и существуют специальные дистрибутивы. Windows 7 и 8 в настоящий момент вендоры не поддерживают, однако люди, которые любят вызов, могут попробовать это сделать руками.
Отмечу еще, что для фанатов Spring существует фреймворк Spring for Apache Hadoop.
Мы пойдем путем простым и установим Hadoop на виртуальную машину. Для начала скачаем дистрибутив CDH-5.1 для виртуальной машины (VMWare или VirtualBox). Размер дистрибутива порядка 3,5 гб. Cкачали, распаковали, загрузили в VM и на этом все. У нас все есть. Самое время написать всеми любимый WordCount!
Конкретный пример
Нам понадобится сэмпл данных. Я предлагаю скачать любой словарь для bruteforce'а паролей. Мой файл будет называться john.txt.
Теперь открываем Eclipse, и у нас уже есть пресозданный проект training. Проект уже содержитя все необходимые библиотеки для разработки. Давайте выкинем весь заботливо положенный ребятами из Clouder код и скопипастим следующее:
package com.hadoop.wordcount;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class WordCount {
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
Получим примерно такой результат:
В корень проекта training добавив майл john.txt через меню File -> New File. Результат:
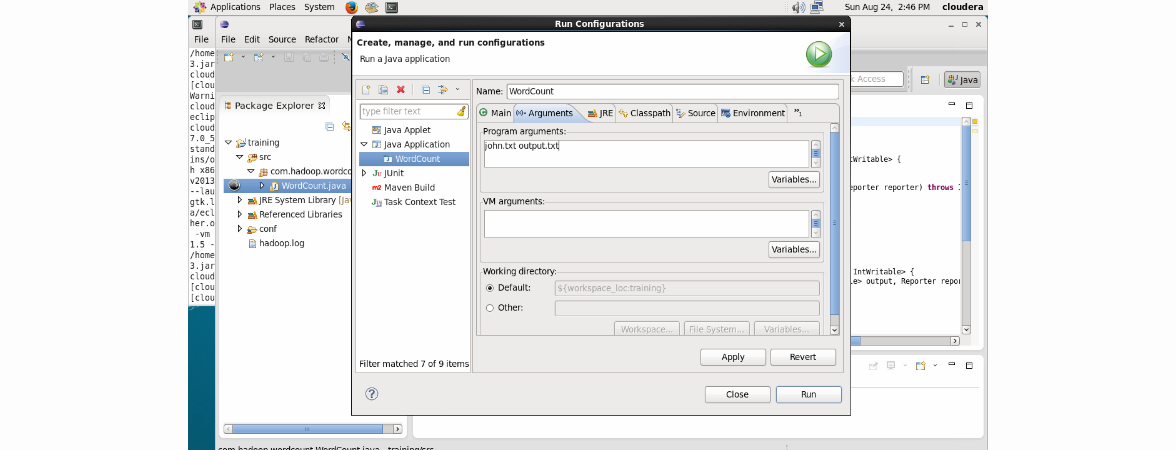
Нажимаем Run -> Edit Configurations и вводим в качестве Program Arguments соответственно input.txt и output
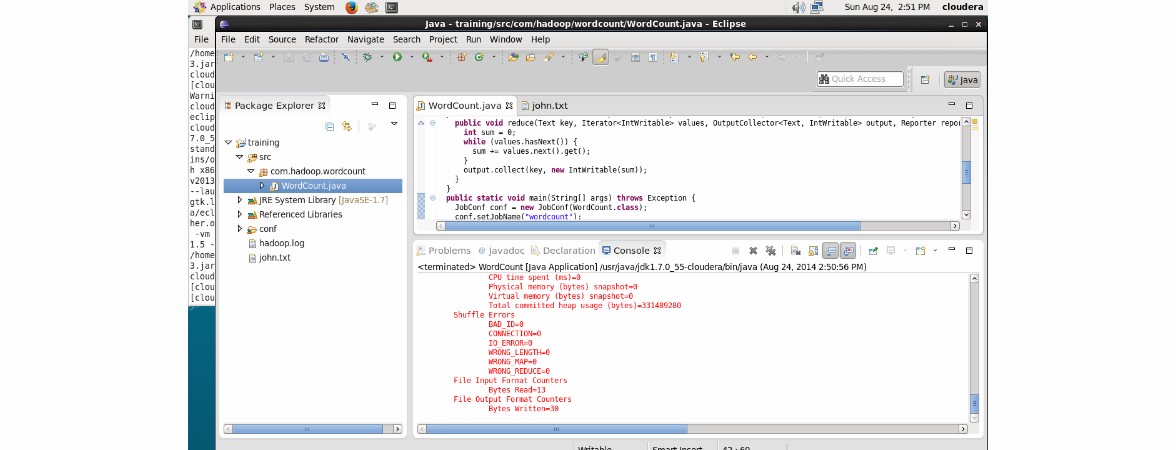
Нажимаем Apply, а затем Run. Работа успешно выполнится:
А где же результаты? Для этого обновляем проект в Eclipse (кнопкой F5):
В папке output можно увидеть два файла: _SUCCESS, который говорит, что работа была выполнена успешно, и part-00000 непосредственно с результатами.
Этот код, разумеется, можно дебажить и т. п. Завершим же разговор обзором unit-тестов. Собственно, пока для написания unit-тестов в Hadoop есть только фреймворк MRUnit (https://mrunit.apache.org/), за Hadoop он опаздывает: сейчас поддерживаются версии вплоть до 2.3.0, хотя последняя стабильная версия Hadoop — 2.5.0
Блиц-обзор экосистемы: Hive, Pig, Oozie, Sqoop, Flume
В двух словах и обо всем.
Hive & Pig. В большинстве случаев писать Map/Reduce job'ы на чистой Java — слишком трудоемкое и неподъемное занятие, имеющее смысл, как правило, лишь чтобы вытащить всю возможную производительность. Hive и Pig — два инструмента на этот случай. Hive любят в Facebook, Pig любят Yahoo. У Hive — SQL-подобный синтаксис (сходства и отличия с SQL-92). В лагерь Big Data перешло много людей с опытом в бизнес-анализе, а также DBA — для них Hive часто инструмент выбора. Pig фокусируется на ETL.
Oozie — workflow-движок для jobs. Позволяет компоновать jobs на разных платформах: Java, Hive, Pig и т. д.
Наконец, фреймворки, обеспечивающие непосредственно ввод данных в систему. Совсем коротко. Sqoop — интеграция со структурированными данными (РСУБД), Flume — с неструктурированными.
Обзор литературы и видеокурсов
Литературы по Hadoop пока не так уж много. Что касается второй версии, мне попадалась только одна книга, которая концентрировалась бы именно на ней — Hadoop 2 Essentials: An End-to-End Approach. К сожалению, книгу никак не получить в электронном формате, и ознакомиться с ней не получилось.
Я не рассматриваю литературу по отдельным компонентам экосистемы — Hive, Pig, Sqoop — потому что она несколько устарела, а главное, такие книги вряд ли кто-то будет читать от корки до корки, скорее, они будут использоваться как reference guide. Да и то всегда можно обойдись документацией.
Hadoop: The Definitive Guide — книга в топе Амазона и имеет много позитивных отзывов. Материал устаревший: 2012 года и описывает Hadoop 1. В плюс идет много положительных ревью и достаточно широкое покрытие всей экосистемы.
Lublinskiy B. Professional Hadoop Solution — книга, из которой взято много материала для этой статьи. Несколько сложновата, однако очень много реальных практических примеров —внимания уделено конкретным нюансам построения решений. Куда приятнее, чем просто читать описание фич продукта.
Sammer E. Hadoop Operations — около половины книги отведено описанию конфигурации Hadoop. Учитывая, что книга 2012 г., устареет очень скоро. Предназначена она в первую очередь, конечно же, для devOps. Но я придерживаюсь мнения, что невозможно понять и прочувствовать систему, если ее только разрабатывать и не эксплуатировать. Мне книга показалось полезной за счет того, что разобраны стандартные проблемы бэкапа, мониторинга и бенчмаркинга кластера.
Parsian M. «Data Algorithms: Recipes for Scaling up with Hadoop and Spark» — основной упор идет на дизайн Map-Reduce-приложений. Сильный уклон в научную сторону. Полезно для всестороннего и глубокого понимания и применения MapReduce.
Owens J. Hadoop Real World Solutions Cookbook — как и многие другие книги издательства Packt со словом “Cookbook” в заголовке, представляет собой техническую документацию, которую нарезали на вопросы и ответы. Это тоже не так просто. Попробуйте сами. Стоит прочитать для широкого обзора, ну, и использовать как справочник.
Стоит обратить внимание и на два видеокурса от O’Reilly.
Learning Hadoop — 8 часов. Показался слишком поверхностным. Но для меня некую ценность представили доп. материалы, потому что хочется поиграть с Hadoop, но нужны какие-то живые данные. И вот он — замечательный источник данных.
Building Hadoop Clusters — 2,5 часа. Как понятно из заголовка, здесь упор на построение кластеров на Амазоне. Мне курс очень понравился — коротко и ясно.
Надеюсь, что мой скромный вклад поможет тем, кто только начинает освоение Hadoop.
