
Всем привет! Меня зовут Сергей Спорышев, я директор направления DevOps-продуктов в ITSumma. В этом тексте я хочу рассказать, как задача по переносу в облако простого на первый взгляд проекта оказалась не такой уж простой и превратилась в целый квест.

Вместо пролога
За 15 лет сопровождения интернет-магазинов и сервисов мы подготовили десятки решений для масштабируемой и отказоустойчивой инфраструктуры e-commerce.
Этот опыт позволил нам выделить особенности интернет-магазинов, которые нужно учитывать, проектируя инфраструктуру:
огромное количество загружаемого контента, в том числе в высоком разрешении;
частые акции, email-рассылки, которые приводят к лавинообразному скачку трафика;
периодические выгрузки для внешних систем (CRM, бонусная программа и т.д.);
выгрузки из 1С и подобных систем, которые не всегда реализовываются “адекватно” и могут нагружать сайт;
сезонные “предсказуемые” нагрузки — это может быть 14 февраля, 8 Марта, свадебный сезон, 1 сентября и другие особенные и специфические конкретно для данного магазина даты.
много специфичных решений, которые не соответствуют двенадцати факторам, но отвечают задачам бизнеса; например, раздача статики бэкендом или же перепроверка остатков в КШД на каждый чих.
Почти все эти особенности проявились и в кейсе, о котором я расскажу далее.
О проекте
Клиентом в этом проекте был Island Soul Jewelry — интернет-магазин дизайнерских украшений из серебра, вдохновленных островом Бали.
Это бренд, 7 лет существующий на рынке и владеющий сетью из 70+ магазинов в пяти странах. Кроме физических точек, у компании есть сайт с доставкой по всему миру, на который заходят в среднем по 30 тысяч посетителей в сутки.

Популярность компании продолжает неуклонно расти — только за прошлый год они увеличили посещаемость на 340 000 уникальных посетителей, каждый второй из них возвращался повторно за покупками на сайт. Клиент увидел значительный рост нагрузки и в декабре им стало окончательно тесно в самописной инфраструктуре. Это и ожидание сезонного прироста трафика побудило Island Soul Jewelry обратиться к нам.
Мы осознавали, что февраль и март — самый высокий сезон для ювелирного рынка.
Более того, компания достигла такого роста, когда омникальность стала для нас краеугольной. Текущая инфраструктура не могла обеспечивать стабильность ни в нагрузочные часы, ни в обычные, от этого мы критично теряли в конверсии и доходе. Поэтому, было принято решение идти с проверенным и рекомендованным партнером ва-банк прямо перед праздниками. Миграция подразумевала полное изменение архитектуры и повышение стабильности, что совпадало с текущими потребностями бизнеса и отвечало требованиям текущего масштабирования. Проект реализовывали силами внутренней команды и коллег из ITSumma.

Ксения Казанцева
Заказчик и руководитель проекта миграции, Island Soul Jewelry
Что было до
На начало декабря 2022 серверная инфраструктура клиента состояла из двух железных серверов в reg.ru с логическим разделением на фронтенд и бэкенд.

Frontend представлял собой node.js-приложение на фреймворке React, а Backend был реализован на RoR (Ruby On Rails). В проекте использовалась СУБД PostgreSQL, поисковая система Sphinxsearch, key-value хранилище Redis.
Проблемы инфраструктуры
Первым делом мы провели аудит и поняли следующее:
Эта инфраструктура не способна выдержать резкий наплыв посетителей на сайт.
Её мощности невозможно масштабировать горизонтально.
Системное и прикладное программное обеспечение проекта устарело.
Монолитная инфраструктура затрудняет возможность дальнейших доработок.
Система доставки кода, реализованная подрядчиком, использует устаревшие технологии и затрудняет эксплуатацию проекта.
Статические файлы обрабатываются бэкендом.
Не внедрен системный мониторинг.
Не выполняются требования к быстродействию системы.
Не выстроены уровни сетевой безопасности.
Отсутствует резервирование.
Эти проблемы ограничивали и бизнес, и разработку, и эксплуатацию. Поэтому мы предложили разработать и внедрить инфраструктуру, в которой:
С минимальной задержкой можно увеличивать вычислительные мощности для обработки трафика.
Есть управляемый CI/CD и необходимый инструментарий, чтобы при необходимости подключить независимых разработчиков.
Список приложений и сервисов готов к расширению, в частности, к подключению сервиса по обработке мобильного трафика.
Внедрен мониторинг, резервное копирование, есть сопроводительная документация и резервирование.
Реализованы минимальные требования к цифровой безопасности: развернуты инструменты управления секретами и реализованы правила сетевой безопасности.
Есть возможность в короткое время поднять дополнительные окружения для разработки и тестирования, а также внедрять новые компоненты.
Какие решения предложили клиенту
Обсудив задачу, мы предложили клиенту использовать следующий стек технологий:
Kubernetes как средство управления рабочей нагрузкой;
Gitlab как хранилище репозиториев и инструмент CI/CD;
managed-решения PostgreSQL для решения задач отказоустойчивости и быстрого масштабирования;
Vault как решение, которое позволит управлять доступами к конфиденциальным данным;
CDN для обслуживания запросов к изображениям и другим статическим файлам.

Предложенная нами схема инфраструктуры выглядела так В предложенной инфраструктуре есть несколько групп приложений:
Frontend-приложение — это деплоймент и HPA (Horizontal Pod Autoscaling) с фронтенд-приложением, которое может реагировать на возросшую нагрузку.
RoR backend для API – обрабатывает большую часть трафика, тоже с HPA. По большей части это основное приложение, из которого мы выделили компоненты для разделения потоков нагрузки и логики работы с ресурсами и запросами.
RoR static — первый “отпочковавшийся” инстанс бэкенда. Обслуживает запросы на ресайз, апдейт и другую обработку статики. Эту группу выделили, поскольку для работы со статикой требуется отдельный пласт логики и дополнительных ресурсов со специфичным конфигурированием.
RoR queue worker — инстанс для обработки очередей. Выделили его для возможности независимого масштабирования. Асинхронные задачи в работе интернет-магазина выполняют очень важные для бизнеса функции. Поэтому нужно, чтобы никакой трафик или сбои с отдельными деплойментами не влияли на работу выгрузок из 1С или других систем.
RoR admin — инстанс, который обеспечивает работу административной части интернет-магазина. Админку тоже решили вынести отдельно, чтобы обеспечивать отдельные решения по безопасности. Из нашего опыта, в случае каких-либо проблем с сайтом, иногда очень важно попасть в админку и сделать что-то. Соответственно, при проблемах с сайтом лучше иметь независимый деплоймент с админкой.
RoR partners – на момент проведения работ обсуждалось подключение больших и тяжелых во взаимодействии партнеров и сервисов. Поэтому вместе с клиентом мы решили выделить их в отдельный тип нагрузки.
Также мы продумали и другие важные моменты. Собственно скрин из ТЗ с их описанием:

Почему мы выбрали Yandex Cloud для реализации решения
В нем есть все необходимые нам управляемые ресурсы:
Managed Service for Kubernetes
Managed Service for PostgreSQL
Application Load Balancer
Object storage
Cloud CDN
Container Registry
Security groups
Compute Cloud
Плюс этими сервисами можно вполне адекватно управлять через Terraform. Так мы быстро можем организовывать dev- и stage- окружения.
Отдельно о том, почему мы выбираем Yandex.Cloud для задач по IaC можно почитать в нашей статье про сравнения облаков.
До Island Soul Jewelry у нас уже был опыт работы с этим облаком. Поэтому мы уже знали некоторые его особенности по “жонглированию” роутами и реализации многозонального автомасштабируемого кластера Kubernetes.
Но нужно сказать, что с некоторыми вещами нам пришлось разбираться в первый раз. В частности, с механизмом fallback на ALB для обработки ошибок 404 на статике, и там не возникло особых проблем.
Как видите, вся миграция была тщательно спланирована и продумана. Но предусмотреть все было невозможно.
Особенности работы статики в проекте
В этом проекте используется специализированный движок/фреймворк Spree для создания интернет-магазинов, основанный на Ruby on Rails. Одна из особенностей Spree — это механизм работы с изображениями: к каждому товару, странице блога, варианту товара и т. д. можно прикрепить набор изображений, которые будут отображаться на сайте в различных размерах и пропорциях (например, 612x612, 1024x1024, 2048x2048).
Изначально для хранения изображений использовалось локальное файловое хранилище на сервере с объемом около 20-30 ГБ. Однако при миграции на Kubernetes стало очевидно, что такой подход неэффективен, и решено было перейти на хранение изображений в облачном S3-like хранилище.
Более того, все изображения на сайте изначально обрабатывались через Ruby без кеширования, что приводило к проблемам с производительностью. Поэтому мы перевезли изображения в Yandex Object Storage с помощью специализированных скриптов.
Однако в процессе синхронизации с prod базой данных возникали проблемы с временным появлением ошибок 502. Это было обнаружено на одном из этапов тестирования с помощью Яндекс.Танка, но изначально проблема была проигнорирована, так как считалось, что это связано с поднятием новых подов и отсутствием health check'ов.
Как решали эту проблему
Мы провели небольшое исследование и поняли вот что:
При запросе списка товаров вместе с основными данными к товару приходит набор ссылок на каждый вариант изображения (по 3 варианта на товар 612, 1024, 2048 px).
Скрипты миграции просто это не учитывают — в бакет при синхронизации улетели только исходные изображения файлов, отресайзеных файлов не было.
Если Ruby видит, что для определенного варианта изображения нет, система генерирует его прямо в основном потоке: выкачивает исходник, создает варианты, сохраняет и отдает необходимые ссылки.
При этом один из исходников весил 50 Mb, и Ruby попросту падало из-за лимитов памяти, пытаясь его скачать.
В идеале это исправляют две вещи:
Консольная команда, которая пройдет по списку товаров, и для недостающих вариантов сгенерирует необходимые картинки;
Автоматически в фоновом режиме (через очереди) при создании товара запускать генерацию всех вариантов его изображений.
Разработчикам понадобилось бы время, чтобы внести эти изменения. Но нам нужно было исправить проблему прямо сейчас. Поэтому мы сделали следующее:
сформировали список url, который примерно на 70-80 процентов покрывает реальный пользовательский трафик;
с помощью крон-задач стали в командной строке раз в 10 минут проходиться по этому списку url и фактически “прогревать кеш изображений”.
Прогрев реализовали с помощью Postgres запроса:
psql -t "host=$DATABASE_HOST port=6432 dbname=$DATABASE_NAME user=$DATABASE_USERNAME password=$DATABASE_PASSWORD" -c "DO \\$\\$ DECLARE parent bigint ;
BEGIN DROP TABLE if EXISTS temp_for_warm_query; CREATE TABLE temp_for_warm_query (count integer, parent integer);
FOR parent in (SELECT DISTINCT parent_id from spree_taxons where parent_id is not null ) LOOP
INSERT into temp_for_warm_query ( count ,parent ) values (( SELECT count(*) from spree_products_taxons join spree_products on spree_products.id = spree_products_taxons.product_id where taxon_id in (select id from spree_taxons where parent_id=parent) and spree_products.deleted_at is null and spree_products.available_on <= NOW()) , parent ) ;
END LOOP;
RETURN;
END; \\$\\$ ; select 'curl -s -o /dev/null''https://prod.client.com/api/v2/storefront/products?page=1&s ort=created_at&per_page=' || count || '&filter%5Btaxons%5D=' || parent || '&include=images''' from temp_for_warm_query;" | grep curlМы собираем список taxon с их товарами в id в каждом. Из этого списка составляем список url вида:
curl -s-o/dev/null'https://prod.client.com/api/v2/storefront/products?page=1&sort=created_at&per_page=52&filter%5Btaxons%5D=56&include=images'.Запускаем их, Ruby прогревается. В случае с таксонами, которые скрыты от неавторизованного пользователя (оптовый каталог), запускаем curl с хедером authorization: Bearer.
Как перевезти Spree на ROR в Kubernetes
Расскажу и про основные работы. По ним мы собрали базовую инструкцию с самыми важными моментами по тому, как перевезти Spree на Kubernetes, которую я опишу ниже.
Самое важное — это начальное конфигурирование приложения RubyOnRails.
В директории <rootdir>/config есть файлы, описывающие конфигурацию каждого окружения: прод, стейдж тест, дев и т.д. и набор yml-файлов под каждый сервис/конфиг. Выглядит файл вот так:
production:
param1: value1_prod
param2: value2_prod
staging:
param1: value1_stage
param2: value2_stage
Файлы с параметрами игнорируются, но есть файл “образец” и его нужно создавать на готовом окружении и каждый раз загружать настройки. Это очень неудобно, поэтому лучше перевести всё на переменные окружения:
Поставить вот этот замечательный gem: https://github.com/bkeepers/dotenv
Вынести файлы с конфигами из гитигнора и привести их к виду на иллюстрации ниже.

Настроите доставку этих переменных в приложение.
Есть 2 варианта настройки.
Если это локальная разработка, просто формируем .env файл с нужными переменными, кладем его в гитигнор.
Если у вас Kubernetes. Нечувствительные переменные подкладываем через config map, набор значений формируем из values-файла через Helm. Если это чувствительные переменные (пароли, приватные ключи), в приложение закидываем это через секрет. Секреты синхронизируем любым удобным способом. Самый адекватный — ставим хранилище, настраиваем политики доступа, ставим синхронизатор. Пример, как это сделать, я напишу ниже.
Сборка приложения на этапе docker-файла
Тут была интересная особенность. Админка и кабинет партнера на проекте отдается пользователю не самим Ruby, а React.
На этапе билда ассетов для этих приложений (команда - bundle exec rails assets:precompile) приложения отвалились, сообщив, что не могут соединиться с базой данных. Фикс, найденный в “замечательных” статьях из интернетов: DATABASE_ADAPTER=nulldb REDIS_CACHE_URL=redis://fake/0 bundle exec rails assets:precompile, выдал только ещё более странную ошибку о том, что невозможно найти ни один из объектов базы.
Разобравшись, мы поняли, что на старте руби-приложение прогревает так называемый программный кеш, предзагружает классы и декораторы. В некоторых классах есть константы, значение которых получается в результате запроса к базе данных.
В коде это выглядит вот так:

Исправлять это приходится следующим образом:
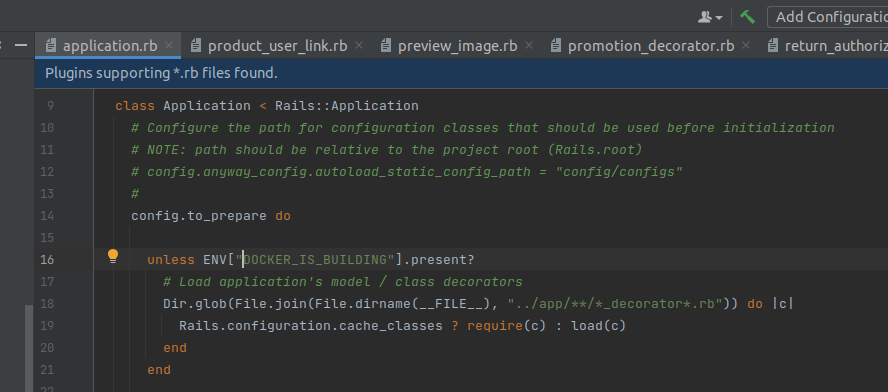
И при сборке ассетов для фронтенда делать вот такую команду для запуска: RUN SECRET_KEY_BASE=skb DATABASE_ADAPTER=nulldb DOCKER_IS_BUILDING=true REDIS_CACHE_URL=redis://fake/0 bundle exec rails assets:precompile
Настройка логирования
Обычно RoR и Spree логируют все в файлы, и там средствами фреймворка реализовываются ротации и прочие нужные нам процедуры. Если в лог-драйвер написать какой-то произвольный блок логов, то его занесет в файлы вида logs/tinkoff.log, logs/retailcrm.log и т. п.
Писать логи в файлы в 2023 году — это моветон, так что по-хорошему стоит поправить этот момент. Можно научить сборщик логов ходить внутрь контейнера и читать логи из разных файлов, но мы нашли решение проще и собрали все в stdout.
Вот как это выглядит:

Настройка CI/CD и пайплайна
В идеале сборка и доставка всего выше описанного должны происходить в следующем порядке:
билд докер-файла;
пуш докер-файла в Registry;
деплой через Helm.
Важно учитывать следующие моменты:
для этого нужен механизм запуска миграции;
в поде с Ruby сайдкиком должен быть еще и Nginx;
обязательно нужны хелсчеки, т.к. Ruby медленно реагирует.
Как сделали мы.
Сначала написали helm-темплейт, в котором есть основные темплейты:
деплоймент
сервис
ингресс
configmap
секреты
HPA (host protected area)
джоба с миграциями БД
Нам нужно, чтобы сначала запускалась миграция, если она не прошла — деплой останавливался. Для этого делаем следующее. В джобе с миграциями выставляем вот такие аннотации:

При этом мы поняли, что на развороте в новое окружение/неймспейс джоба с миграциями запускается первой. Но ведь ни configmap, ни секретов еще нет, а значит, она не может попасть в БД. Исправили этот момент вот так:
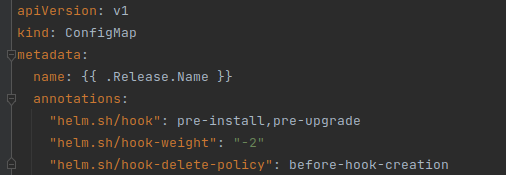
Соответственно любой деплой в Kubernetes теперь будет идти по схеме:
накатываем секреты/конфигмапы;
запускаем мигратор:
обновляем/деплоим все остальное.
Дальше делаем примитивные хелсчеки. Лучше, чтобы это были не банальные сообщения “Hello, world!”, а какой-нибудь полноценный json из базы.
Потом распределяем ресурсы, где надо включаем HPA. Для CPU триггер срабатывания — 50 процентов утилизации.
Для ресурсов у нас были вот такие настройки:
реквесты — 1 ядро процессора, 2 Gb RAM;
лимиты — 2 ядра процессора, 4 Gb RAM;
Если свести все к небольшому чек-листу, то перенести Spree на ROR можно в 4 этапа:
настройка приложения на работу с переменными окружения;
настройка логирования;
написание хельмчарта, CI/CD, пайплайна:
калькуляция ресурсов, где надо — включение HPA.
Итоги миграции
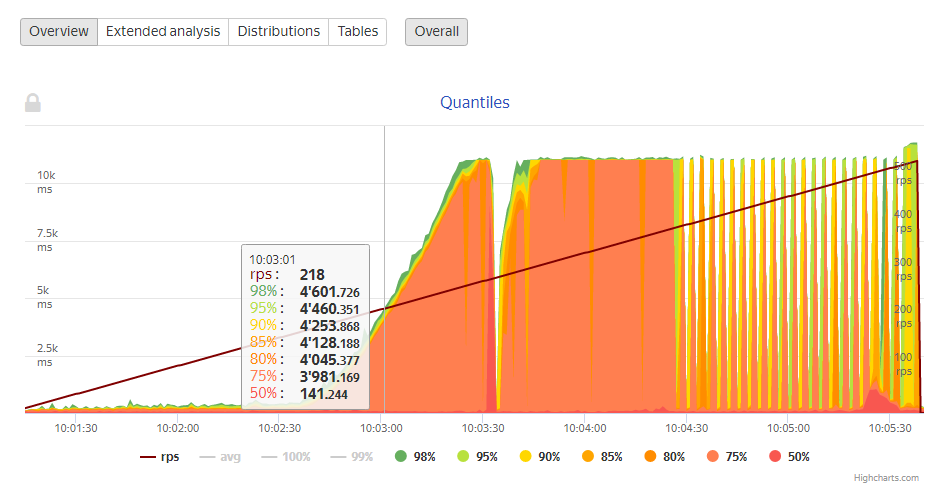
Теперь о результатах. Вот график нагрузочного тестирования проекта до миграции. Система падает примерно при 218 rps, а с 170 rps уже наблюдаются проблемы.
Ниже график после переезда. Наблюдаем прямо противоположную картину. Инфраструктура спокойно выдерживает больше восьмисот запросов в секунду. И это не предел.
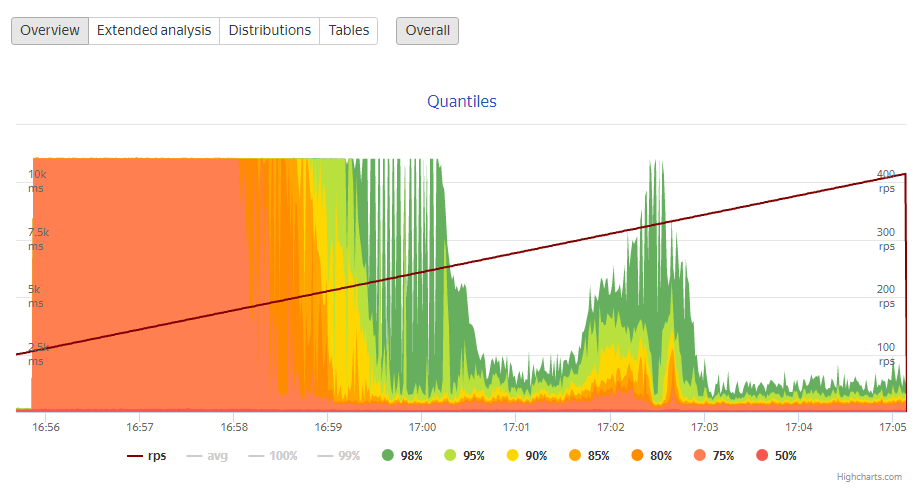
Кроме этого, мы исправили ошибки, связанные с выдачей изображений. И настроили обработку трафика — здесь нагрузка на источники снизилась более чем на 90%, а количество 4хх и 5хх ошибок уменьшилось на порядок.

Слово заказчику:
Команда ITSumma не просто выполнила поставленные задачи, а взяла на себя проведение всей миграции: от аудита и поиска слабых мест до проработки ТЗ и непосредственно самих работ. Благодаря симбиозу внутренних команд и ITSumma проект был успешно реализован, а миграция никак не повлияла на текущую активную разработку. Более того, внедренная архитектура помогла развести несколько команд и вести разработку параллельно. ITSumma без простоев в работе сайта перевезли, оптимизировали и по новой развернули в облаке всю инфраструктуру. Сезонные акции прошли без проблем, у интернет-магазина есть необходимая нам гибкость при работе со скачкообразным трафиком и такая важная для нас возможность быстрого масштабирования.

Ксения Казанцева
Заказчик и руководитель проекта миграции, Island Soul Jewelry.
В 2023 году DevOps чувствует себя как никогда хорошо. У нас есть SaaS, автомасштабирование, Kubernetes с кучей решений на GitHub и кейсов в интернете. Все это значительно облегчает инженерам жизнь
Но все равно будут попадаться типовые проекты, которые окажутся не совсем типовыми. И в таких кейсах очень помогает опыт. К сожалению, бывает так, что опыта не хватает или обладатель необходимых знаний попросту завален другими задачами.
Если вы испытываете затруднения при переезде в облако или у вас есть вопросы по миграции, но нет ответов, напишите нам.
Получать больше полезного контента от нас можно не только на Хабре, но и в Телеграмм. Подписывайтесь на наш аккаунт!
