Очевидный для ML-инженера факт: если на вход модели подать мусор — на выходе тоже будет мусор. Это правило действует всегда, независимо от того, насколько у нас крутая модель. Поэтому важно понимать, как ваши данные будут храниться, использоваться, версионироваться и воспроизведутся ли при этом результаты экспериментов. Для всех перечисленных задач есть множество различных инструментов: DVC, MLflow, W&B, ClearML и другие. Git использовать недостаточно, потому что он не был спроектирован под требования ML. Но есть инструмент, который подходит для версионирования данных и не только — это ClearML. О нем я сегодня и расскажу.
Разница между Git и ClearML в контексте ML-задач
Git не подходит для версионирования данных по нескольким причинам:
- ограничения в эффективности при работе с большими объемами данных;
- не всё хорошо с безопасностью данных;
- обработка бинарных файлов неоптимальна;
- управление большими файлами сложное.
В итоге у нас получится медленная и тяжелая система, с которой неудобно работать.
ClearML представляет собой огромную MLOps-экосистему:
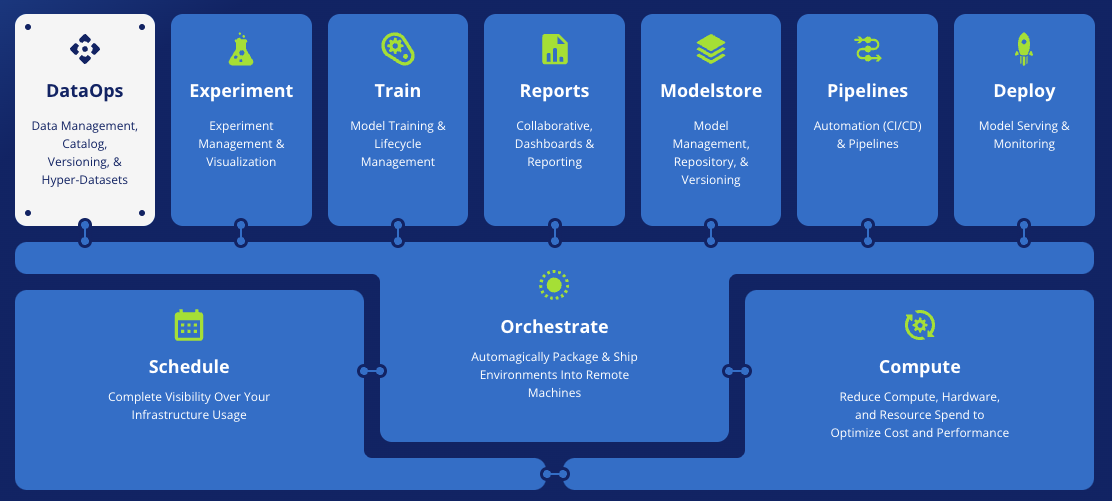
Модули ClearML, покрывающие весь цикл разработки ML-продукта
Некоторые из модулей ClearML:
- ClearML Python (clearml) — служит интеграции ClearML в существующую базу кода. Это обычная питоновская библиотека. Есть CLI и SDK, о работе с ними мы поговорим далее.
- ClearML Server (clearml-server) — предназначен для хранения данных экспериментов, моделей и рабочих процессов, а также для поддержки Web UI менеджера экспериментов. Можно развернуть у себя локально.
- ClearML Agent (clearml-agent) — агент оркестровки MLOps. Обеспечивает воспроизводимость экспериментов и рабочих процессов, а также их масштабируемость.
- ClearML Serving (clearml-serving) — нужен для развертывания и оркестровки моделей. Есть интеграция с Triton. Но на мой взгляд он недоработан: есть проблемы с запуском и версиями на этапе сборки.
- ClearML Session (clearml-session) необходим для запуска удаленных экземпляров Jupyter Notebooks и VSCode. Очень интересное решение, работает хорошо, можно создавать рабочие места для ML-инженеров и выделять нужное количество мощностей для каждого из них. Все запускается через clearml-agent, для которого можно указать кастомный docker-image.
- ClearML Data (clearml-data) предназначен для управления данными и версионирования поверх файловых систем/объектных хранилищ, таких как AWS S3.
Редко инструменты покрывают абсолютно все нужды проекта, поэтому обычно приходится использовать зоопарк из различных решений. В случае с ClearML покрыты все возможные потребности ML-проекта. В этой статье мы рассмотрим модуль ClearML Data.
Особенности ClearML по сравнению с аналогичными инструментами
В отличие от, например, DVC, в ClearML версионирование данных происходит отдельно от версионирования кода. Как утверждают сами создатели инструмента, данные не являются кодом, поэтому они не должны находиться в git-репозитории:
We believe Data is not code. It should not be stored in a git tree, because progress on datasets is not always linear. Moreover, it can be difficult and inefficient to find on a git tree the commit associated with a certain version of a dataset.
У ClearML удобный и приятный интерфейс. MLflow в этом плане не так дружелюбен.
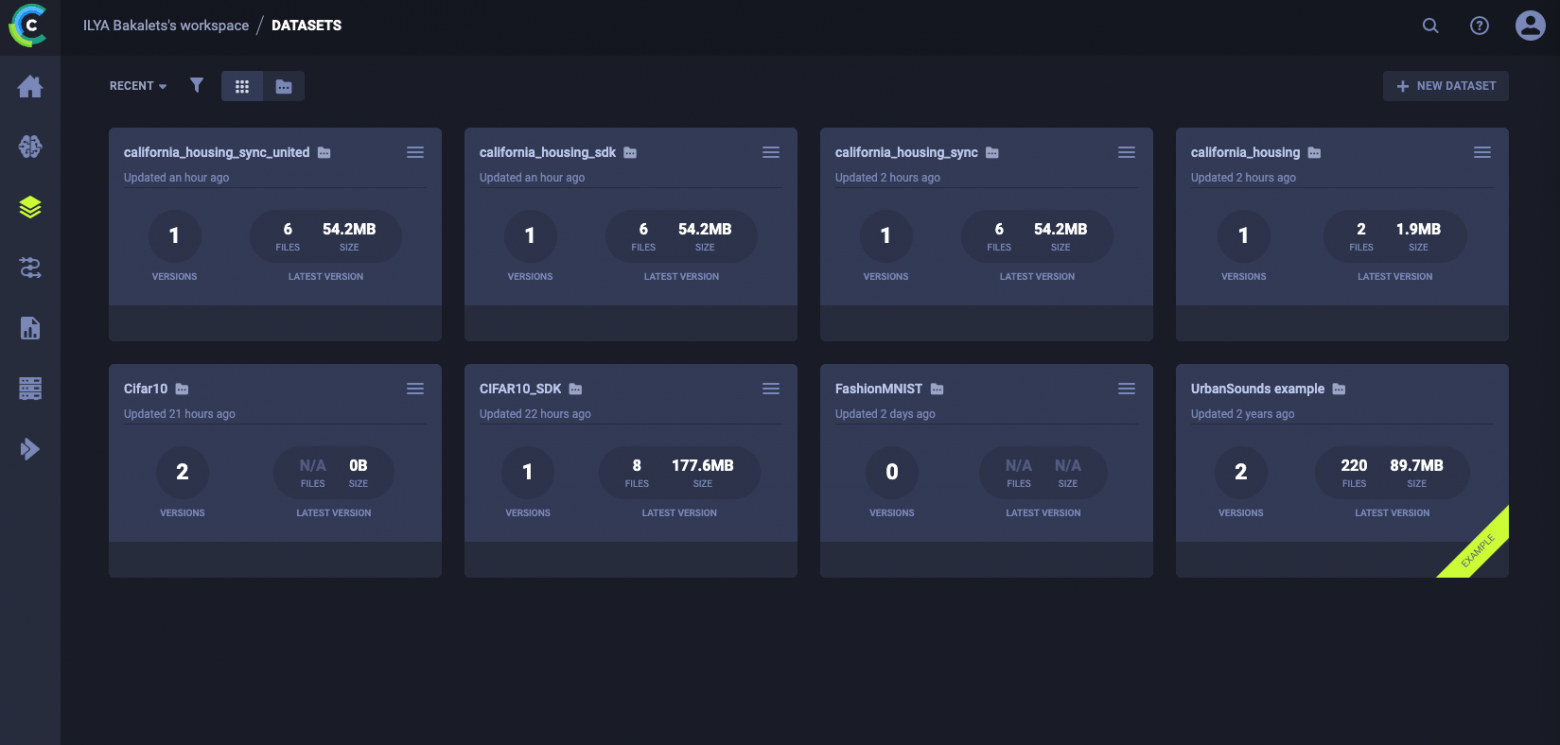
Web UI ClearML для датасетов
Познакомиться с отдельными частями интерфейса можно по ссылкам: dataset_details и dataset_page.
Еще одна особенность ClearML заключаются в том, что все сущности являются типом task (experiments в UI). Например, датасеты, эксперименты с моделями, пайплайны — у всех одинаковый тип. Никаких лишних сущностей и понятные статусы для каждого типа. Task — это отдельный сеанс выполнения кода, который может представлять собой эксперимент, шаг или контроллер рабочего процесса, любую пользовательскую реализацию.

Возможные статусы tasks
Данными можно управлять с помощью интеграции хранилищ данных: Azure, AWS, MinIO и других [документация]. Также существуют некоторые платные фичи — гипердатасеты.
Интеграция со многими DS-библиотеками (scikit-learn, Matplotlib, PyTorch, TensorFlow и другими) позволяет подхватывать все метрики, графики обучения, гистограммы, логи, незакоммиченные части кода, версии библиотек — нужно просто создать task в начале .py файла / jupyter notebook и в результате можно будет воспроизвести любой эксперимент.
Сейчас инструмент все еще совершенствуется. Как и у всех развивающихся платформ, у этого модуля есть свои недостатки:
- В некоторых браузерах plots и debug изображения не будут отображаться;
- Мобильная версия сайта неудобна в использовании, поэтому нужно переходить в ПК-версию;
- Графики обучения моделей не такие красивые, как у W&B 🙂;
- Не всегда автоматически подхватываются метрики для pytorch lightning, из-за чего приходится подключать tensorboard (а метрики из tensorboard уже подхватываются в clearml).
Теперь давайте подробнее рассмотрим работу с модулем СlearML Data, который входит в библиотеку ClearML.
ClearML Data на практике
Воспользуемся платформой ClearML с ограничением в 100 GB для данных и возможностью пригласить еще двух человек в ваше рабочее пространство clearml. Подобные условия есть и у W&B. А вот развернуть W&B локально или на вашем сервере бесплатно нельзя, в отличие от ClearML.
Первый этап: регистрация и создание кредов [более подробно см. в документации]
- Устанавливаем у себя clearml через pip install clearml
- Регистрируемся по ссылке: app.clear.ml/login
- Заходим в Settings → Workspace → Создаем креды «Create new credentials»
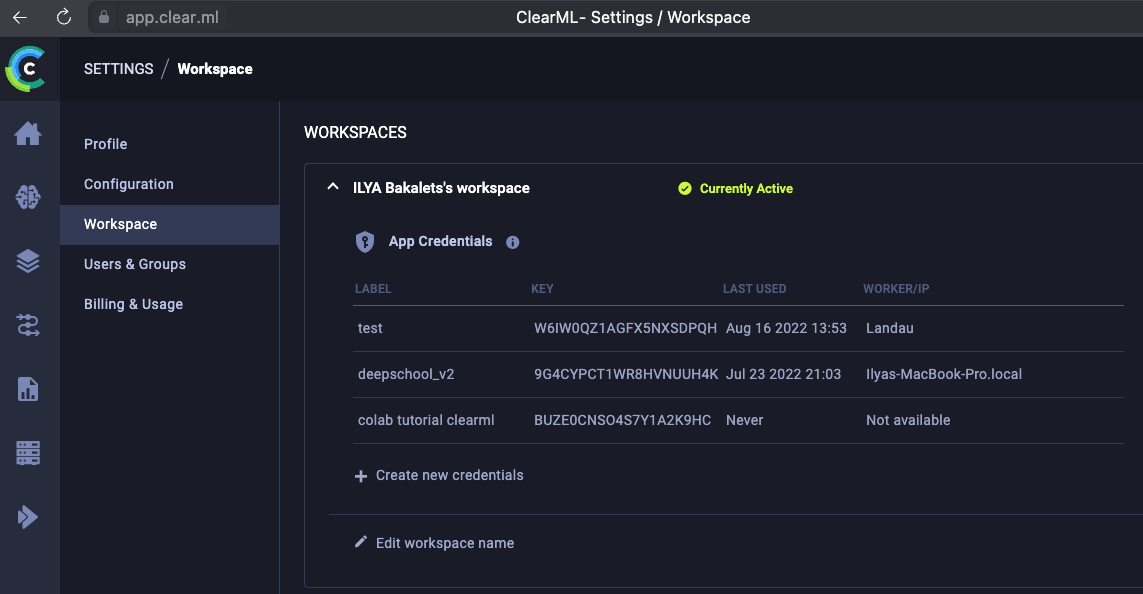
Настройка рабочего пространства и создание кредов
Можно воспользоваться Local Python или Jupyter Notebook. Инструкция для них представлена ниже.
Local Python
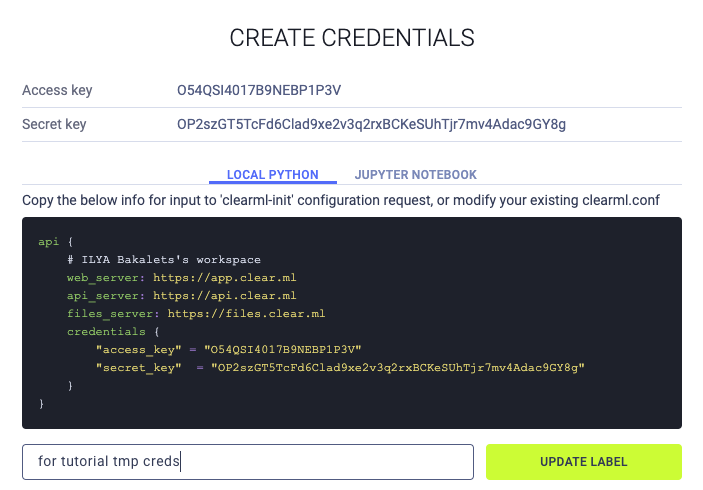
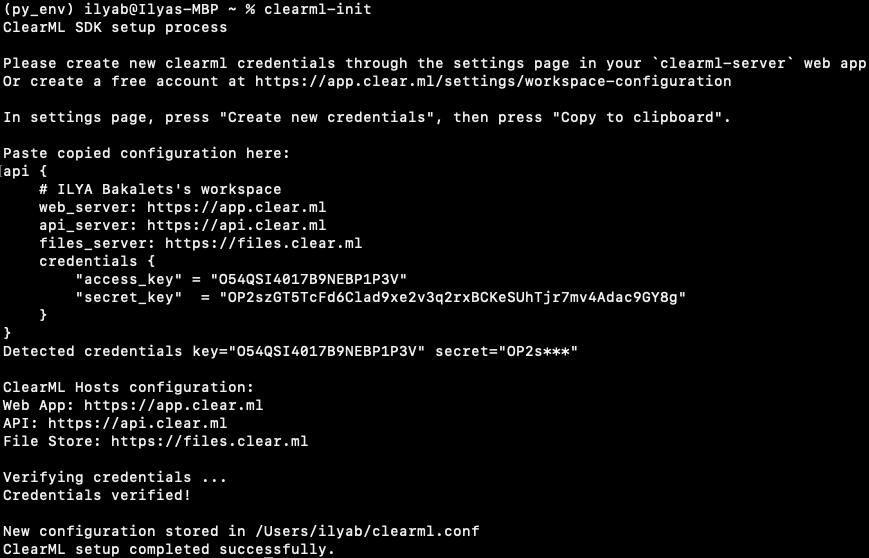
В консоли запускаем команду clearml-init и вставляем креды:
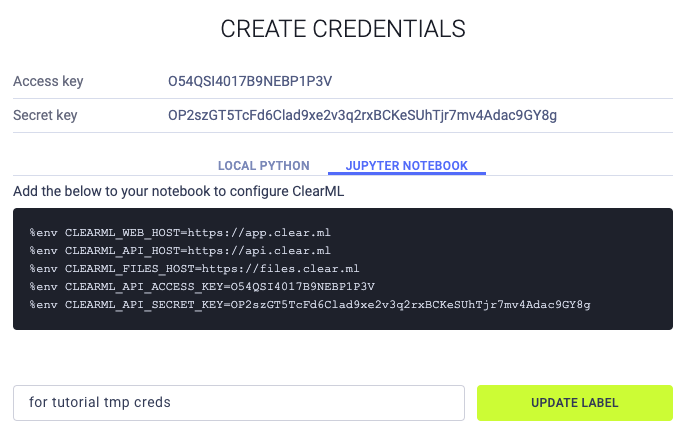
Jupyter Notebook
В табе Jupyter Notebook копируем креды в ячейку ноутбука:
После создания кредов с помощью Local Python или Jupyter Notebook появится конфигурационный файл ~/clearml.conf для Linux. Для других ОС путь может отличаться. В этом файле возможно, например, настроить интеграцию с S3.
Креды не должны коммититься и публично показываться. Примеры выше представлены только в демонстрационных целях.
Весь код данной статьи есть тут → Ссылка на колаб. Попробуйте на практике! 😉
ClearML Data поддерживает два интерфейса:
- clearml-data — утилита CLI для создания, загрузки и управления наборами данных;
- clearml.Dataset — интерфейс Python для создания, извлечения, управления и использования наборов данных.
Рассмотрим работу с каждым из них по отдельности.
Создание датасета с CLI
Скачаем и распакуем датасет, с которым будем работать далее:
wget -P /content/dataset_v1/ https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_5340.zip
unzip /content/dataset_v1/kagglecatsanddogs_5340.zip -d /content/dataset_v1/Есть два способа загрузки данных в ClearML: через ручной контроль каждого этапа и при помощи sync.
Первый способ: ручной контроль каждого этапа
- сreate создает датасет. Тут мы указываем проект, название датасета, теги, версию. Если не указать версию, она поставится автоматически.
# Инициализируем датасет
clearml-data create --project DeepSchool/Tutorials/cats_vs_dogs \
--name cats_vs_dogs \
--tags init_data--project — аргумент, в котором можно указать иерархию. Например: Turorials/Toy_Datasets/Cifar10/Train и так до глубины 10.
После выполнения команды clearml-data create в UI мы можем посмотреть статус датасета. Сейчас у нас «Uploading», значит, есть возможность добавлять, удалять и изменять файлы этой версии.

Статус «Uploading» в ClearML UI после инициализации датасета
clearml-data работает в режиме отслеживания состояния, поэтому после создания нового набора данных для следующих команд не требуется флаг --id.
- add добавляет локальные файлы в созданный датасет. Он позволяет рекурсивно добавить файлы в датасет через ~/data/*.jpg.
# Добавим файлы.
clearml-data add --files "/content/dataset_v1"# Перед загрузкой на ClearML можно проверить, какие файлы добавились
clearml-data list --id <dataset_id>- close закрывает и загружает данные в clearml. Можно указать --storage — по умолчанию это хранилище ClearML.
Этап close включает в себя загрузку и финализацию датасета finalize и upload, которые также можно использовать по отдельности, например, если нужно загрузить данные и при этом иметь возможность изменить датасет.
<dataset_id> будет получен при создании датасета и виден в ClearML UI после этапа close.
# команда равна clearml-data upload и clearml-data finalize
clearml-data closeПосле этапа finalize загруженную версию датасета изменить будет нельзя: это нужно для воспроизводимости. Теперь у нашего датасета статус «Final».
Так выглядит результат после выполненных выше команд:

Загруженный датасет в ClearML
Второй способ: c помощью sync
sync объединяет в себе все вышеперечисленные этапы загрузки данных, но при одном условии: все должно лежать в одной папке.
clearml-data sync --project DeepSchool/Tutorials/cats_vs_dogs \
--name cats_vs_dogs_sync \
--folder /content/dataset_v1
Загруженный датасет при помощи sync через CLI
Теперь в UI появилась папка «DeepSchool». В ней есть два подпроекта, которые были загружены с помощью предыдущих команд:

Загруженные датасеты в папке «DeepSchool»
Получение данных с CLI
Для получения локальной копии датасета, которую нельзя изменять (read only), нужно выполнить следующую команду при помощи get:
clearml-data get --id <created_dataset_id> Получить id датасета можно в UI:

Получение id датасета из ClearML UI
Получение датасета в read only может стать удобным решением, если вы хотите избежать повторного скачивания одних и тех же данных. Если данные хранятся в кэше, при их обновлении скачается только дельта.
Для получения локальной копии датасета, которую можно изменять, нужно выполнить следующую команду при помощи get и указать папку, в которую необходимо скачать датасет:
# Получить изменяемые локальные данные.
# Если нет, то просто копируется локальная версия для изменений
clearml-data get --id 717662694123428bab2b103efed87e4b \
--copy ./cats_vs_dogs_sync/Наши данные уже в кэше, следовательно, ClearML сможет проверить, отличается ли кэш-версия от нужной для скачивания. Если нет — он скопирует часть датасета из кэша и отличающуюся часть из ClearML.
В этом случае вы сможете изменить датасет и загрузить измененную версию.
Создание новой версии датасета с CLI
Изменим датасет, скачав новые изображения для класса Fish.
fish_images = ['http://www.michigansportsman.com/Boaters_Guide/10.18.05_Manistee_Lake_Coho_004_small.jpg',
'http://www.aosalaska.com/gallery/silvers/silver24.jpg',
'http://www.piscatorialpursuits.com/images/jimmy.jpg',
'http://www.fpc.org/spawning/images/multnomahcoho11-04.jpg',
'http://www.alaskaantlerworks.com/images/jerm_silver.jpg']
from clearml import StorageManager
for image_path in fish_images:
StorageManager.get_local_copy(remote_url=image_path,
extract_archive=False,
cache_context="/content/cats_vs_dogs_sync/PetImages/Fish")Теперь, когда у нас есть измененная локальная версия датасета, мы можем загрузить ее с помощью команды sync, указав при этом аргумент --parents:
# Загрузим измененный датасет с новым классом Fish,
# важно указать id родительского датасета,
# иначе вместо загрузки только новых файлов загрузится весь датасет, что займет много времени
!clearml-data sync --project DeepSchool/Tutorials/cats_vs_dogs \
--name cats_vs_dogs_sync \
--parents 717662694123428bab2b103efed87e4b \
--folder /content/cats_vs_dogs_syncРезультат версионирования датасета представлен на рисунке ниже. Через VERSION INFO справа на скриншоте можно посмотреть статистику по количеству добавленных, удаленных и измененных изображений.

Новая версия датасета в ClearML UI. Добавлена папка с классом «Fish»
В загруженных файлах есть битая картинка, удалим ее.
Для начала выведем список фото с помощью clearml-data list:
clearml-data list --id 8f13d861488248fca90aa9522b882ea5 \
--filter PetImages/Fish/*.jpgclearml-data - Dataset Management & Versioning CLI
List dataset content: 8f13d861488248fca90aa9522b882ea5
Listing dataset content
file name | size | hash
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
PetImages/Fish/24af78f36dd391046209db21577ec667.multnomahcoho11-04.jpg | 1,520 | 31bb5a2bdbb753adebd1a7c88b69fd7ddd405241619bbb866db4ed9c51d729e2
PetImages/Fish/4d536d76aaf42c0e5524b6f8c6918227.jimmy.jpg | 19,515 | 0432f283284a5ab33c31f42040267bde9a37853b5c4557060c2bcd1527ef78b2
PetImages/Fish/70a4b2cb727768e435b3f77ba7b782b6.silver24.jpg | 19,715 | 803de343fd2410e1e5568fbac54f3dba9a699048e1b44d9194b03b8888b2ff90
PetImages/Fish/c18a90447be153bab0d90e175bff269f.10.18.05_Manistee_Lake_Coho_004_small.jpg | 3,548 | c654999d76c033bcb0ed04d75c6a592280c2c8dbbb60133f2c2013a54ca4229e
PetImages/Fish/cdcbd1c83803abb15830e0f0c16bc353.jerm_silver.jpg | 67,725 | 0b5ac127c2b7e766116ecc1f8f1a8f5023a23749d255761bbc2785c77b42fc5e
Total 5 files, 112023 bytesУдалим битую фотографию из папки «Fish» в нашем датасете:
rm -f ./cats_vs_dogs_sync/PetImages/Fish/24af78f36dd391046209db21577ec667.multnomahcoho11-04.jpgОбновим датасет c помощью sync:
clearml-data sync --project DeepSchool/Tutorials/cats_vs_dogs \
--name cats_vs_dogs_sync \
--parents 8f13d861488248fca90aa9522b882ea5 \
--folder /content/cats_vs_dogs_syncВ ClearML UI можно посмотреть обновленную версию нашего датасета:

Новая версия датасета с удаленным изображением
Создание датасета с SDK
Аналогично все работает через интерфейс python. Давайте рассмотрим пример на тех же данных:
- Загрузка данных в ClearML и контроль каждого этапа:
# Первый способ с возможностью выборочно добавлять файлы from clearml import Dataset
dataset_project = "DeepSchool/Tutorials/cats_vs_dogs"
dataset_name = "cats_vs_dogs_SDK"
dataset_path = "/content/cats_vs_dogs_sync"
dataset = Dataset.create(dataset_name=dataset_name,
dataset_project=dataset_project)
dataset.add_files(dataset_path) # рекурсивно добавить файлы в датасет
dataset.upload()
dataset.finalize()
2. Загрузка данных в ClearML через *sync*:
```python
# Второй способ с sync
from clearml import Dataset
dataset_project = "DeepSchool/Tutorials/cats_vs_dogs"
dataset_name = "cats_vs_dogs_SDK_sync"
dataset_path = "/content/cats_vs_dogs_sync"
dataset = Dataset.create(dataset_name=dataset_name,
dataset_project=dataset_project)
dataset.sync_folder(dataset_path)
dataset.finalize(auto_upload=True)Важно: после выполнения finalize() мы не сможем изменить слепок датасета в clearml, но сможем создать новую версию датасета с измененными файлами.

Загруженные версии через CLI и SDK
Получение данных с SDK
Скачать загруженный датасет можно тремя способами.
Получить метаданные, например, имена файлов.
# Получить данные на read only, # в данном случае получим cats_vs_dogs_SDK_sync датасет from clearml import Dataset from pathlib import Path dataset_path = Dataset.get(dataset_name=dataset_name, dataset_project=dataset_project) # или dataset_path = Dataset.get(dataset_id=<dataset_id>)
Для скачивания данных явно указать .get_local_copy(), при этом данные будут скачаны в кэш, и их можно будет только читать.
# Получить данные на read only from pathlib import Path dataset_path = Dataset.get(dataset_name=dataset_name, dataset_project=dataset_project ).get_local_copy() # или dataset_path = Dataset.get(dataset_id=<dataset_id>).get_local_copy()
Получить датасет локально в вашей рабочей директории для удаления, добавления, версионирования через .get_mutable_local_copy(target_folder="where/to/save/data”).
# Получить изменяемые локальные данные dataset_path = Dataset.get(dataset_name=dataset_name, dataset_project=dataset_project ).get_mutable_local_copy( target_folder="./cats_vs_dogs_sdk_sync" ) # или dataset_path = Dataset.get( dataset_id=<dataset_id> ).get_mutable_local_copy(target_folder="./cats_vs_dogs_sdk_sync")
Создание новой версии датасета с SDK
Изменим локальные данные, полученные через SDK, и зальем новую версию датасета.
В этот раз удалим папку «Cat» c помощью метода remove_files (возможны проблемы с использованием этого метода, рекомендуется использовать sync).
--parents — аргумент, в котором можно указать id родительского датасета или нескольких датасетов.
Удалим папку «Cat»:
rm -rf ./cats_vs_dogs_sync/PetImages/Cat# Первый способ с возможностью выборочно добавлять и удалять файлы
from clearml import Dataset
dataset_project = "DeepSchool/Tutorials/cats_vs_dogs"
dataset_name = "cats_vs_dogs_SDK_sync"
dataset_path = "/content/cats_vs_dogs_sdk_sync"
dataset = Dataset.create(dataset_name=dataset_name,
dataset_project=dataset_project,
parent_datasets=["f2999e995d924d239dcd5db8981f27d0"])
# важно указать родительский датасет
# по умолчанию рекурсивно удаляет файлы из датасета
dataset.remove_files('./PetImages/Cat')
dataset.finalize(auto_upload=True)Таким образом, вы можете изменить датасет даже без его скачивания.
Важно: если вы измените имя датасета, он будет считаться новым и появится в новой карточке датасета в ClearML UI.
С помощью sync обновить датасет удобнее, так как в большинстве случаев он уже существует локально. Здесь проверяется разница между локальными файлами и файлами в ClearML:
from clearml import Dataset
dataset_project = "DeepSchool/Tutorials/cats_vs_dogs"
dataset_name = "cats_vs_dogs_SDK_sync"
dataset_path = "/content/cats_vs_dogs_sdk_sync"
dataset = Dataset.create(dataset_name=dataset_name,
dataset_project=dataset_project,
parent_datasets=["f2999e995d924d239dcd5db8981f27d0"])
# важно указать родительский датасет
dataset.sync_folder(
local_path=dataset_path
)
dataset.finalize(auto_upload=True)
Версия с удаленной папкой класса «Cat»
Объединение датасетов с CLI и SDK
С помощью команды search выведем все датасеты, в названии которых есть подстрока «cats»:
clearml-data search --name cats
clearml-data - Dataset Management & Versioning CLI
Search datasets
project | name | version | tags | created
---------------------------------------------------------------------------------------------------------------------------------------------------
DeepSchool/Tutorials/cats_vs_dogs | cats_vs_dogs | 1.0.0 | 'init_data' | 2024-02-20 06:35:02
DeepSchool/Tutorials/cats_vs_dogs | cats_vs_dogs_sync | 1.0.0 | | 2024-02-20 06:55:16
DeepSchool/Tutorials/cats_vs_dogs | cats_vs_dogs_sync | 1.0.1 | | 2024-02-20 07:52:41
DeepSchool/Tutorials/cats_vs_dogs | cats_vs_dogs_sync | 1.0.2 | | 2024-02-21 03:11:04
DeepSchool/Tutorials/cats_vs_dogs | cats_vs_dogs_SDK | 1.0.0 | | 2024-02-21 03:32:02
DeepSchool/Tutorials/cats_vs_dogs | cats_vs_dogs_SDK_sync | 1.0.0 | | 2024-02-21 03:33:41
DeepSchool/Tutorials/cats_vs_dogs | cats_vs_dogs_SDK_sync | 1.0.1 | | 2024-02-21 05:37:12Есть небольшая проблема — id датасетов тут не пишут 😢 Поэтому нужно скопировать все id в UI.
Объединить два (и больше) датасета в один можно довольно просто: нужно указать id датасетов с аргументом --parents.
Давайте объединим наши датасеты c create и close, которые мы создали ранее. Для этого укажем новое имя проекта и все id созданных датасетов:
# id возмем из UI
clearml-data create --project DeepSchool/Tutorials/cats_vs_dogs \
--name UNITED_DATASET_CLI \
--parents 4fb7cf2830c449ca8fc7fc9d62e4fcb8 89158f088e354385a5b905716f746659 \
b1f6537691f74d94b4bd5d6569fdd865 55322da674c6439c91a089eb36ff5e29 \
--tags united
clearml-data closeНа рисунке ниже показан результат объединенного (по последним версиям) датасета, наследованный от четырёх разных родителей. Мы видим каждый датасет и все его версии.

Результат объединенного датасета, который был наследован от четырех разных родителей
Важно: удаление родительского датасета может повлечь за собой потерю данных в объединенном датасете.
Через SDK мы объединим только с двумя родителями:
# Объединение с SDK, тут возьмем поменьше датасетов
dataset = Dataset.create(
dataset_name='UNITED DATASET SDK',
dataset_project='DeepSchool/Tutorials/cats_vs_dogs',
parent_datasets=['4fb7cf2830c449ca8fc7fc9d62e4fcb8',
'89158f088e354385a5b905716f746659'],
dataset_version="1.0",
# output_uri="gs://bucket-name/folder", # S3 или любое другое хранилище
description='cats vs dogs vs fish'
)
Результат объединенного датасета, который был наследован от двух разных родителей
Объединение табличных данных
При объединении файлы не соединятся в один. Например, у нас не получится объединить два датасета построчно (CSV-файлы) в один общий файл.
- Если CSV-файлы имеют одно и то же название, то в объединенном датасете будет только одна версия первого указанного родительского датасета.
- Если названия файлов разные, то будет два разных файла в одной версии датасета.
Рабочий процесс аналогичен git: вы не используете git для редактирования файла. Вы сами редактируете файл, а затем применяете git, чтобы отслеживать изменения и их время.
Документация датасета
В начале статьи мы говорили, что все сущности ClearML — это task. Датасеты не исключение. К ним можно подгрузить разные метрики, гистограммы, дебаг изображения, а затем посмотреть их в task датасета.

Переход к task датасета
Информацию можно посмотреть следующим образом: task information -> debug samples

Информация, которая представлена в task созданного датасета
На рисунке выше мы видим информацию разного типа. В открытой табе DEBUG SAMPLES к датасету подгружены изображения (это примеры для просмотра). Подгрузить можно также графики (посмотреть их в PLOTS и SCALARS). А в ARTIFACTS можно подгрузить CSV-файлы, zip и т. д.
Для загрузки CSV-файлов к датасету, картинок, графиков предлагается использовать Dataset.get_logger().
Пример из документации:
# Attach a table to the dataset
dataset.get_logger().report_table(
title="Raw Dataset Metadata", series="Raw Dataset Metadata", csv="path/to/csv"
)
# Attach a historgram to the table
dataset.get_logger().report_histogram(
title="Class distribution",
series="Class distribution",
values=histogram_data,
iteration=0,
xlabels=histogram_data.index.tolist(),
yaxis="Number of samples",
)Хранение кеша
Весь локальный кэш (модели, созданные и скаченные датасеты и др.) будет храниться в ~/clearml/cache.
Для каждого пользователя — свой кэш. Иногда это неудобно: например, если датасет весит больше 1TB, а пропускная способность маленькая. Тогда можно столкнуться с очень долгой (многочасовой) загрузкой этих данных на сервер. Если над таким датасетом работает большая команда, где у каждого своя копия датасета — это может занять приличную часть SSD или HDD на сервере. Для решения дублирования данных на сервере можно сделать общий кэш и скачать туда все датасеты ClearML. Он будет автоматически обновляться с изменением каких-либо датасетов на clearml-server. Таким образом, у всех будут актуальные версии датасетов в локальном доступе.
Заключение
Сейчас есть очень много инструментов версионирования и хранения данных. Не все из них удобны в работе с видео и изображениями. Не все могут предложить единую экосистему жизненного цикла ML-проекта. А при помощи ClearML можно аккуратно и эффективно хранить данные, воспроизводить эксперименты, онбордить новичков и делать еще много чего 🙂
ClearML предлагает два удобных способа взаимодействия через интерфейсы CLI и Python SDK, работу с которыми мы и рассмотрели выше.
В следующих статьях мы разберем clearml agents и clearml pipelines и узнаем, как интегрировать S3 или Minio в clearml и какие у этого есть плюсы.
Полезные ссылки:
- Интересное выступление про то, как строилась MLOps платформа на базе ClearML в MTS
- Best practices от ClearML Data (версионирование, организация датасетов, документация)
- Документация CLI
- Документация SDK
- Туториалы от ClearML
- Целый плейлист по работе с ClearML
- Видео по работе с clearml-data
P.S.
Первая версия статьи написана для deepschool-pro, на Хабре публикуется с изменениями и дополнениями.
