Тренды трендами, а всегда найдутся те, кто плывет против течения. Пока трендом становится уменьшение размеров модели, авторы из университета штата Вашингтон решили вообще не обращать внимание на размер и проверить, имеет ли смысл в эпоху LLM вернуться к N-граммным языковым моделям. Оказалось, что имеет. Во всяком случае, хотя бы просто из интереса.
На N-граммы, пожалуй, действительно давно никто не обращал внимания. Техники масштабирования, выведшие трансформеры на заоблачные высоты, к ним не применяли. Но авторы статьи Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens обучили N-граммную модель на 1,4 триллиона токенов — это самая гигантская модель такой архитектуры. Она занимает 10 тебибайт, зато ей нужно всего 20 миллисекунд, чтобы подсчитать n-граммы, вне зависимости от того чему равно n. Самое интересное — возможные значения n.
Развитие n-граммных моделей быстро уперлось в экспоненциальный рост размера от n. Уже при 5-граммах на адекватном датасете число комбинаций, для которых нужно сохранить значения в таблицу вероятностей, очень большое, поэтому дальше 5 не заходили. Но и 5 (а на самом деле 4) токенов — настолько маленький контекст, что даже о сравнении с LLM речи не шло. Но авторы статьи не просто подняли n выше 5, они сняли любые ограничения — n может быть сколь угодно большим. Поэтому авторы условно называют это ∞-граммы, или “бесконечнограммы”. Конечно, для этого пришлось немного модифицировать подход.
Числитель и знаменатель в дроби, которая определяет вероятность токена после заданного контекста, могут оказаться нулевыми. Имеется в виду простое определение, когда просто подсчитывается количество заданных n-грамм в корпусе. То есть, если таких последовательностей токенов в корпусе не было, то и посчитать ничего не получится. Чтобы справится с этим, да еще и на бесконечнограммах, авторы применили backoff-технику, то есть технику откидывания. Если числитель и знаменатель равны нулю, будем уменьшать n на единицу до тех пор, пока знаменатель не станет положительным (числитель может остаться нулем). Отбрасывание начинается условно с бесконечности. На деле начальное “бесконечное” n рассчитывается как длина самого длинного суффикса из промпта, который встречается в корпусе, плюс один.
10 тебибайт, конечно, очень даже небольшой размер для бесконечнограммной модели на 1,4 миллиарде токенов (классическая 5-граммная модель весила бы 28 тебибайт). Чтобы добиться этого, авторы составили специальную структуру данных — массив суффиксов. Следите за руками. Для заданного массива длиной N сначала строятся все возможные суффиксы и выстраиваются в лексикографическом порядке. Массив суффиксов построен таким образом, что на нулевом месте стоит позиция, на котором в исходном массиве впервые встречается нулевой суффикс. На первом — позиция, где встречается первый и так далее.
Массив суффиксов строится за линейное время относительно длины токенизированного корпуса. На RedPajama c 1,4 триллиона токенов на это ушло 56 часов, 80 CPU и 512G RAM.
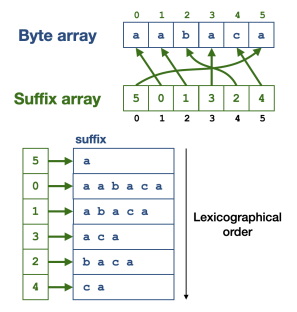
Чтобы посчитать вероятность n-граммы, нужно посчитать число “иголок” (строчек из токенов заданной длины) в “стоге сена” (массиве суффиксов). А так как этот стог отражает упорядоченный набор всех суффиксов, то позиции всех нужных “иголок” находятся в одном последовательном фрагменте массива суффиксов. Поэтому нужно просто найти первый и последний и посчитать разницу ними. Это занимает логарифмическое по размеру массива и линейное по размеру искомой строки время.
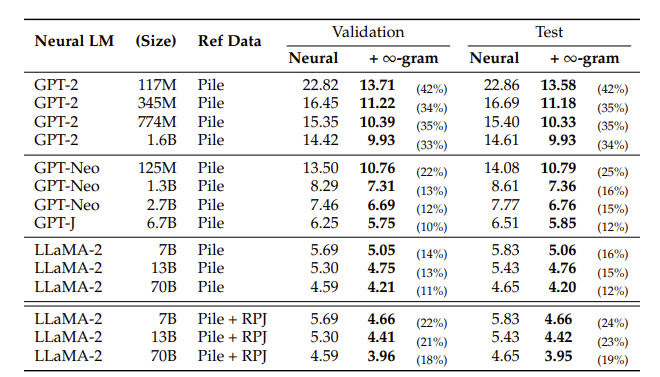
Авторы прикрутили бексконечнограмы к большим языковым моделям с помощью линейной интерполяции и оценили перплексию на датасете Pile. На GPT-2, GPT-Neo и LLaMa-2 улучшения оказались весьма убедительными — от 12% до 42% на тестовой выборке. Авторы, правда добавляют, что такое заметное улучшение GPT-2 может быть из-за того, что её единственную не обучали на Pile
Еще одно важное замечание авторов. Бесконечнограммы могут значительно улучшать перплексию LLM, но на задачах генерации открытого текста могут не просто не помогать, а еще и мешать. Бесконечнограмы могут, например, извлекать совершенно не нужные токены и модель выдаст ерунду. Так что на замену LLM авторы совсем не претендуют. Но всё равно планируют поискать тут возможные способы совместного применения.
Больше наших обзоров AI‑статей на канале Pro AI.
