
Продолжаю серию статей про хорошую интеграцию. В первой статье я говорил, что хорошая админка обеспечит быстрое решение инцидентов — как ключевой фактор для устойчивости работы всего комплекса систем. Во второй — про использование идемпотентных операций для устойчивой работы в условиях асинхронного взаимодействия и при сбоях. В этой статье рассмотрим синхронный, асинхронный и реактивный способы взаимодействия между сервисами и более крупными модулями. А так же способы обеспечить консистентность данных и организовать транзакции.
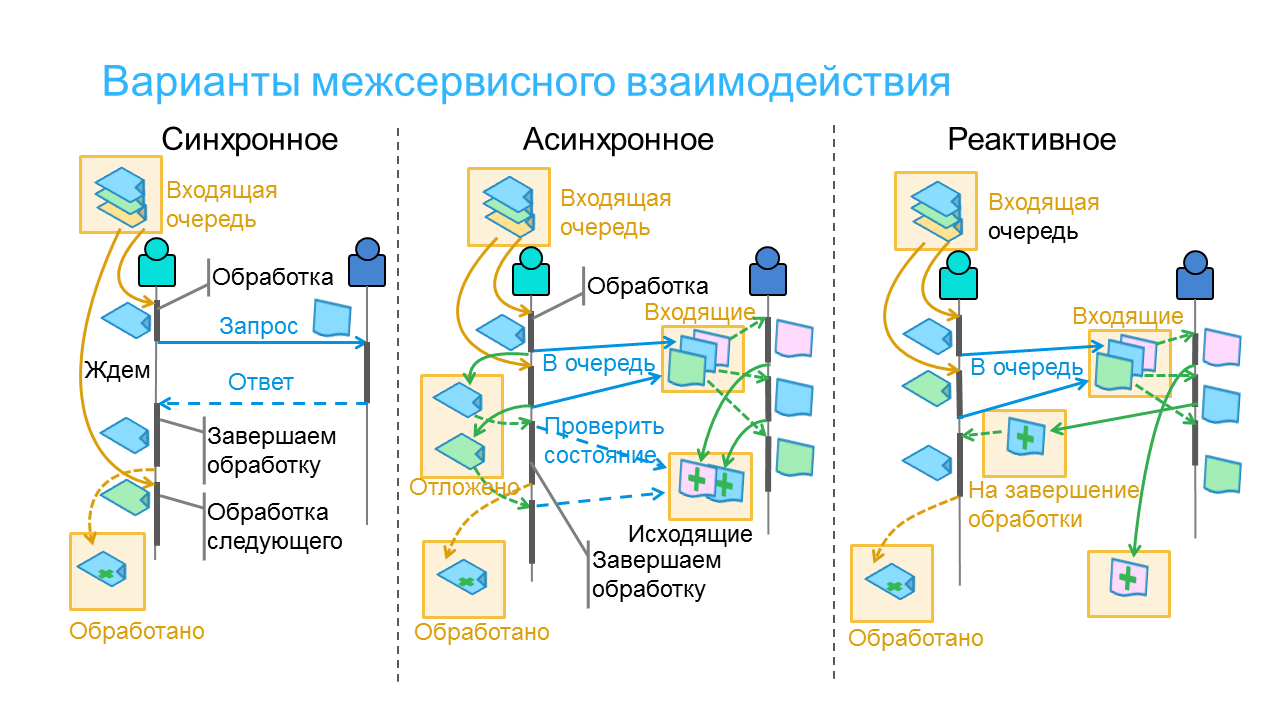
На схеме вы можете увидеть все три варианта взаимодействия. Важно то, что схема описывает обработку не одного сообщения, а нескольких из входящей очереди. Потому что для анализа производительности и устойчивости важна не просто обработка одного сообщения — важно, как экземпляр сервиса обрабатывает поток сообщений из очереди, переходя из одного к другому и откладывая незавершенную обработку.
На самом деле под любыми способами взаимодействия (в том числе синхронным) лежит посылка сообщения. Которое будет получено некоторым обработчиком и обработано сразу с отправкой сообщения-ответа. Либо поставлено в очередь на обработку с квитанцией о приеме, а содержательная обработка произойдет позднее. Однако это не означает, что все способы одинаковы — обработка сообщений и очереди организуются по-разному. Конечно, детали реализации часто скрыты протоколом обмена, библиотеками или синтаксическим сахаром языка реализации, однако для разработки эффективных и устойчивых приложений нам необходимо понимать, как именно организована обработка (включая обработку ошибок), где возникают очереди, задержки и как происходит обработка при большом потоке сообщений.
Синхронное взаимодействие
Синхронное взаимодействие — самое простое. Оно скрывает все детали удаленного вызова, что для вызывающего сервиса превращается в обычный вызов функции с получением ответа. Для его организации есть множество протоколов — например, давно известные RPC и SOAP. Но очевидная проблема синхронности в том, что удаленный сервис может отвечать не очень быстро даже при простой операции — на время ответа влияет загруженность сетевой инфраструктуры, а также другие факторы. И все это время вызывающий сервис находится в режиме ожидания, блокируя память и другие ресурсы (хотя и не потребляя процессор). В свою очередь, блокированные ресурсы могут останавливать работу других экземпляров сервиса по обработке сообщений, замедляя тем самым уже весь поток обработки. А если в момент обращения к внешнему сервису у нас есть незавершенная транзакция в базе данных, которая держит блокировки в БД, мы можем получить каскадное распространение блокировок.
Например, при распиле монолита мы выносим сервис хранения товаров отдельно. И в бизнес-логике обработки заказа (где-то в середине) нам надо получить какой-то атрибут для действий в зависимости от него — например, узнать вес и объем товара, чтобы решить: курьер довезет или нужна машина (или даже газель). Если раньше мы обращались за атрибутом локально и быстро получали ответ, то теперь мы используем удаленное обращение — и пока он идет, этот процесс держит не только свои ресурсы, но и блокировки, связанные с незавершенной транзакцией.
При этом стандартный шаблон работы с базой данных - все изменения по одному запросу пользователя проводить в одной транзакции (разумно их делить), а не завершать транзакции после каждого оператора для обеспечения консистентности данных. Поэтому при выносе хранения товаров в отдельный сервис нам не просто надо переписать процедуры запроса атрибутов на обращения к сервису, а провести реинжиниринг кода: сначала запросить все необходимые данные от других сервисов, а потом начать делать изменения в базе данных.
Казалось бы, это всё очевидно. Но я встречался со случаями, когда синхронные вызовы ставили без необходимости, искренне не понимая, что выполнение будет долгим, а накладные расходы — большими. Отдельная засада заключается в том, что современные системы разработки позволяют вынести сервисы на удаленный сервер не меняя исходного кода, — и сделать это могут администраторы при конфигурировании системы. В том числе на уровне базы данных — я встречался с идеями, когда централизованное хранение логов на полном серьезе предлагали делать просто за счет переноса локальных таблиц на общий сервис так, чтобы прямые вставки в них превратились в ставки по dblink. Да, это — простое решение. Только очень неустойчивое по производительности и чувствительное к сбоям сетевой инфраструктуры.
Другая проблема связана с падениями удаленных вызовов. Падение вызываемого сервиса еще укладывается в общую логику обработки — всякий вызов процедуры может породить ошибку, но эту ошибку можно перехватить и обработать. Но ситуация становится сложнее, когда вызываемый сервис отработал успешно, но вызывающий за это время был убит в процессе ожидания или не смог корректно обработать результат. Поскольку этот уровень скрыт и не рассматривается разработчиками, то возможны эффекты типа резервов для несуществующих заказов или проведенные клиентом оплаты, о которых интернет-магазин так и не узнал. Думаю, многие сталкивались с подобными ситуациями.
И третья проблема связана с масштабированием. При синхронном взаимодействии один экземпляр вызывающего сервиса вызывает один экземпляр вызываемого, но который, в свою очередь, тоже может вызывать другие сервисы. И нам приходится существенно ограничивать возможность простого масштабирования через увеличение экземпляров запущенных сервисов, при этом мы должны проводить это масштабирование сразу по всей инфраструктуре, поддерживая примерно одинаковое число запущенных сервисов с соответствующей затратой ресурсов, даже если проблема производительности у нас только в одном месте.
Поэтому синхронное взаимодействие между сервисами и системами — зло. Оно ест ресурсы, мешает масштабированию, порождает блокировки и взаимное влияние разных серверов.
Я бы рекомендовал избегать его совсем, но, оказывается, есть одно место, в котором протокол поддерживает только синхронное взаимодействие. А именно — взаимодействие между сервером приложений и базой данных по JDBC синхронно принципиально. И только некоторые NoSQL базы данных поддерживают реально асинхронное взаимодействие со стороны сервера приложений и вызовы callback по результату обработки. Хотя казалось бы, мы находимся в поле бэкенд-разработки, которая в наше время должна быть ориентирована на асинхронное взаимодействие... Но нет — и это печально.
Транзакции и консистентность
Раз уж зашла речь про базы данных, поговорим о транзакционности работы. Там более, что именно она часто является аргументом за синхронное взаимодействие.
Начнем с того, что транзакционность была в свое время громадным преимуществом реляционных баз данных и снимала с разработчиков громадное количество работы по обработке ошибок. Вы могли рассчитывать, что все изменения, которые бизнес-логика выполняет в базе данных при обработке одного запроса пользователя либо будут целиком зафиксированы, либо целиком отменены (если при обработке произошла ошибка), а база данных вернется в прежнее состояние. Это обеспечивал механизм транзакций реляционной базы данных и паттерн UnitOfWork в приложении-клиенте или на сервере приложений.
Как это проявлялось практически? Например, если вы резервировали заказ, и какой-то одной позиции не хватило, то ошибка обработки автоматически снимала все сделанные резервы. Или если вы исполняли сложный документ, — и при этом создавалось много проводок по разным счетам, а также изменялись текущие остатки и история, — то вы могли быть уверены, что либо все проводки будут созданы и остатки будут им соответствовать, либо ни одной проводки не останется. Поведение по умолчанию было комфортным и при этом обеспечивало консистентность, и лишь для сохранения частичных результатов (например, для частичного резерва заказа) надо было предпринимать специальные сознательные усилия. Но и в этом случае на уровне базы данных за счет механизма триггеров все равно можно было следить за консистентностью внутри транзакций при частичном сохранении результатов —, например, обеспечивая жесткое соответствие проводок и остатков по счетам.
Появление трехзвенной архитектуры и сервера приложений принципиально не изменило ситуацию. Если каждый запрос пользователя обрабатывается сервером приложений в одном вызове, то заботу о консистентности вполне можно возложить на транзакции базы данных. Это тоже было типовым шаблоном реализации.
Когда же пришла пора распределенных систем, то это преимущество решили сохранить. Особенно на уровне базы данных — потому что возможность вынести часть хранения на другой сервер средствами администратора представлялась крайне желанной. В результате появились распределенные транзакции и сложный протокол двухфазного завершения, который призван обеспечить консистентность данных в случае распределенного хранения.
Призван, но по факту — не гарантирует. Оказывается, в случае сбоев даже промышленные системы межсистемных транзакций, — такие, как взаимодействие по Oracle dblink, — могут привести к тому, что в одной из систем транзакция будет завершена, а в другой — нет. Конечно, это тот самый «исчезающе маловероятный случай», когда сбой произошел в крайне неудачный момент. Но при большом количестве транзакций это вполне реально.
Это особенно важно, когда вы проектируете систему с требованиями высокой надежности, и рассчитываете использовать базу данных как средство, обеспечивающее резервирование данных при падении сервера, передавая данные на другой сервер и получая, таким образом, копию, на которую рассчитываете оперативно переключиться при падении основного сервера. Так вот, если падение произошло в этот самый «крайне неудачный момент», вы не просто получаете транзакции в неопределенном состоянии, вы должны еще разобраться с ними вручную до запуска штатного режима работы.
Вообще, расчет на штатные средства резервирования базы данных в распределенном IT-ландшафте иногда играет злую шутку. Очень печальная история восстановления после аварии произошла, когда основной сервер одной из систем деградировал по производительности. Причина проблем была совершенно неясна, не исключены были даже проблемы на уровне железа, поэтому решили переключиться на standby — в конце концов, его именно для таких случаев и заводили. Переключились. После этого выяснилось, что потерялись несколько последних минут работы, но в корпоративной системе это не проблема — пользователей оповестили, они работу повторили.
Проблема оказалась в другом: смежные системы, с которыми взаимодействовал сервер, оказались совершенно не готовы к откату его состояния на несколько минут — они же уже обращались и получили успешный ответ. Ситуация усугубилась тем, что об этом просто не подумали при переключении, а проблемы начали проявляться не сразу — поэтому эффект оказался довольно большим, и его пришлось несколько дней искать и устранять сложными скриптами.
Так вот там, где взаимодействие было асинхронным, с этим получилось разобраться скриптами на основе сравнения журналов обоих серверов. А вот для синхронного взаимодействия оказалось, что никаких журналов не существует в природе, и восстановление консистентности данных потребовало сложных межсистемных сверок. Впрочем, для асинхронных взаимодействий при отсутствии журналов будет тоже самое, поэтому ведите их с обеих сторон.
Таким образом, механизмы межсистемных транзакций часто погребены очень глубоко на системном уровне, и это — реальная проблема в случае сбоев. А при временных нарушениях связи проблема станет еще больше из-за больших таймаутов на взаимодействие систем — многие из них разворачивались еще в тот период, когда связь была медленной и ненадежной, а управление ими при этом далеко не всегда вынесено на поверхность.
Поэтому использование транзакций базы данных и встроенных механизмов, в общем случае, не будет гарантией консистентности данных и устойчивости работы комплекса систем. А вот деградацию производительности из-за межсистемных блокировок вы точно получите.
Когда же объектно-ориентированный подход сменил процедурную парадигму разработки, мы получили еще одну проблему. Для поддержки работы с персистентными объектами на уровне сервера приложений были разработаны объектно-реляционные мапперы (ORM). Но тут-то и выяснилось, что шаблон UnitOfWork и возможность отката транзакций концептуально противоречат ORM — каждый объект инкапсулирует и сложность, и логику работы, и собственные данные. Включая активное кэширование этих данных, в том числе — и между сессиями разных пользователей для повышения производительности при работе с общими справочниками. А отката транзакций в памяти на уровне сервера приложений не предусмотрено.
Конечно, на уровне ORM или в надстройке над ним можно вести списки измененных объектов, сбрасывать их при завершении UnitOfWork, а для отката — считывать состояние из базы данных. Но это возможно, когда вся работа идет только через ORM, а внутри базы данных нет никакой собственной бизнес-логики, изменяющей данные, — например, триггеров.
Может возникнуть вопрос — а какое все это имеет отношение к интеграции, это же проблемы разработки приложения как такового? Это, было бы так, если бы многие legacy-системы не выставляли API интеграции именно на уровне базы данных и не реализовывали логику на этом же уровне. А это уже имеет прямое отношение к интеграции в распределенном IT-ландшафте.
Замечу, что взаимодействие между базами данных тоже не обязательно должно быть синхронным. Тот же Oracle имеет различные библиотеки, которые позволяют организовывать асинхронное взаимодействие между узлами распределенной базы данных. И появились они очень давно — мы успешно использовали асинхронное взаимодействие в распределенной АБС Банка еще в 1997 году, даже при скорости канала между городами, по которому шло взаимодействие, всего 64К на всех пользователей интернета (а не только нашей системы).
Асинхронное и реактивное взаимодействие
Асинхронное взаимодействие предполагает, что вы посылаете сообщение, которое будет обработано когда-нибудь позднее. И тут возникают вопросы — а как получать ответ об обработке? И нужно ли вообще его получать? Потому что некоторые системы оставляют это пользователям, предлагая периодически обновлять таблицы документов в интерфейсе, чтобы узнать статус. Но достаточно часто статус все-таки нужен для того, чтобы продолжить обработку — например, после полного завершения резервирования заказа на складе передать его на оплату.
Для получения ответа есть два основных способа:
обычное асинхронное взаимодействие, когда передающая система сама периодически опрашивает состояние документа;
и реактивное, при котором принимающая система вызывает callback или отправляет сообщение о результате обработки заданному в исходном запросе адресату.
Оба способа вы можете увидеть на схеме вместе с очередями и логикой обработки, которая при этом возникает.
Какой именно способ использовать — зависит от способа связи. Когда канал однонаправленный, как при обычном клиент-серверном взаимодействии или http-протоколе, то клиент может запросить сервер, а вот сервер не может обратиться к клиенту — взаимодействие получается асинхронным.
Впрочем, такой асинхронный способ легко превращается в синхронный — достаточно в методе отправки сообщения поставить таймер с опросом результата. Сложнее превратить его в реактивный, когда внутри метода отправки находится опрос результата и вызов callback. И вот это второе превращение — далеко не столь безобидно, как первое, потому что использующие реактивную интеграцию рассчитывают на ее достоинства: пока ответа нет, мы не тратим ресурсы и ждем реакции. А оказывается, что где-то внутри все равно работает процесс опроса по таймеру…
Реактивное взаимодействие требует определенной перестройки мышления, которая не столь проста, как кажется, потому что есть желание не просто упростить запись, а скрыть реактивное программирование и писать в традиционном стиле. Впервые я это осознал, когда был в 2014 году на конференции GoToCon в Копенгагене (мой отчет) и там же услышал про Реактивный манифест (The Reactive Manifesto). Там как раз обсуждалось создание различных библиотек, поддерживающих эту парадигму взаимодействия, потому что она позволяет гибко работать с производительностью. Сейчас это встроено в ряд языков через конструкции async/await, а не просто в библиотеки.
Но фишка в том, что такое скрытие усложняет понимание происходящего внутри приложения. Засада происходит в том случае, когда к объектам, обрабатываемым в таком асинхронном коде, обращаются из других мест — например, они могут быть возвращены в виде коллекций, запрашивающих объекты. И если не позаботиться специально, то вполне могут быть ситуации одновременного изменения объектов. Вернее, псевдо-одновременного — между двумя асинхронными вызовами объект изменяется, хотя с точки зрения разработчика мы как бы находимся внутри потока управления одной процедуры.
Впрочем, шаблоны реактивного программирования — это отдельная тема. Я же хочу заострить внимание на том, что в реактивном взаимодействии есть не только переключение потоков, но и скрытые очереди. А скрытые очереди хуже явных, потому что когда возникает дефицит ресурсов и возрастает нагрузка, все тайное становится явным. Это, конечно, не повод усложнять запись, но, как и в случае с автоматическим управлением памятью, эти механизмы надо понимать и учитывать. Особенно в интеграции, когда это используется для взаимодействия между узлами и сервисами, которые потенциально находятся на разных узлах.
Поэтому я рекомендую представить вашу конкретную интеграцию со всеми скрытыми очередями на схеме как в начале статьи,. И с ее помощью продумать, что произойдет, если один из сервисов упадет в середине обработки? Сделать это нужно как минимум трем людям:
Проектирующий систему аналитик, должен понимать, какие будут последствия для пользователей, и как именно с ними разбираться — что нужно автоматизировать, а что может решить служба поддержки.
При этом аналитик плотно взаимодействует с разработчиком, который смотря на соответствие этой схемы и фактической реализации, может указать на разные проблемы и предложить их решение.
А третий человек — тестировщик. Он должен придумать, как проверить, что в случае сбоев и падений отдельных сервисов система ведет себя именно так, как задумано — что не возникает документов в промежуточных состояниях и которые не видны ни на интерфейсах ни службе поддержки; что отсутствует случайная двойная обработка документа и так далее.
Поясню эти задачи на примерах. Пусть один сервис обрабатывает заказы от покупателей, а другой — резервирует товары по этим заказам на остатках. Задача в этом случае — несмотря на падения серверов или сбои связи, не должно быть ситуации, когда по заказу на 3 единицы они зарезервировались дважды, то есть заблокировалось 6 единиц, потому что первый раз сервис резервирования его выполнил, а квитанцию о резерве не послал или сервис обработки заказов не смог эту квитанцию обработать.
Другой пример — в дата-центре установлен сервис отправки чеков в ФНС, которая выполняется через взаимодействие со специализированным оборудованием — ККМ. И тут тоже надо обеспечить, чтобы каждый чек был отправлен в налоговую ровно один раз, при том, что сама ККМ может работать ненадежно и со сбоями. А в тех случаях, когда алгоритм не может однозначно выяснить результат обработки чека, о появлении такой ситуации должна быть оповещена служба поддержки для разбора. Это должны спроектировать аналитики с разработчиками, а тестировщики — проверить при различных сбойных ситуациях. И лучше это делать автоматически, особенно если в интеграции есть сложные алгоритмы обработки.
Конечно, никакая проверка не дает гарантий. Поэтому при межсистемном взаимодействии важно вести журналы с обеих сторон (хотя при большом объеме приходится думать, как чистить или архивировать логи). Казалось бы, это очевидно. Но нет — я встречал много систем, где журналы отсутствовали и диагностировать проблемные ситуации было невозможно. И много раз доказывал при проектировании, что журналирование обмена – необходимо.
Консистентность данных
Вернемся к вопросам консистентности данных при асинхронном взаимодействии. Как его обеспечивать, если транзакции недоступны? В прошлой статье я предложил одно из решений — шаблон идемпотентных операций. Он позволяет в случае проблем с получением ответа в обработке сообщения просто отправить его повторно, и оно при этом будет обработано корректно. Этот же прием можно применять в ряде ситуативных технических ошибок, например, при отказе из-за блокировок на сервере.
Если же вы получили содержательную ошибку, — например, отказ в отгрузке уже зарезервированного и оплаченного заказа, — то, скорее всего, с такими проблемами надо разбираться на бизнес-уровне, никакие транзакции тут не помогут. В самом деле, отказ отгрузки может в том числе означать, что зарезервированный товар присутствовал только в остатках информационной системы, а на реальном складе его не было. То есть, его действительно не получится отправить покупателю, — а значит, разбираться с этим надо на уровне бизнес-процесса, а не технически. По моему опыту, подобные ситуации достаточно распространены — многие разработчики почему-то забывают, что ИТ-системы лишь отражают реальный мир (и отражение может быть неверным) и сосредотачиваются на техническом уровне.
Организация транзакций
Обработка сообщений порождает транзакции, так как системы по обе стороны взаимодействия работают с базами данных. Но при асинхронном взаимодействии нет никакого смысла сохранять ту транзакционность обработки, какая была в исходной системе. Это опять кажется очевидным, но при обсуждении базовых механизмов интеграции эту задачу почему-то часто ставят и тратят силы не ее решение. Это — лишняя работа.
В основе транзакционной работы лежит необходимость персистентного сохранения в базу данных, при этом транзакции и кванты обработки стоит настраивать отдельно, исходя из требований производительности. По моему опыту, если у вас идет массовая загрузка или передача данных, то вовсе не обязательно оптимальным будет commit на каждую запись — всегда есть некоторое оптимальное количество. При этом внутри процедуры загрузки можно ставить savepoint с перехватом ошибок для каждой отдельной записи, чтобы откатывать не всю порцию загрузки, а лишь обработку ошибочных. Только помните, что откатываются только изменения в таблицах, а некоторые другие вещи могут не откатываться, — например, работа с переменными пакетов в Oracle или некоторые способы постановки в очереди или работа с файлами. Но это и при обычном rollback сохраняется.
Еще надо понимать, что при передаче документов со строками (например, больших накладных) принимающая система далеко не всегда работает корректно, если документ был обработан частично (даже если у строк есть отдельный атрибут-статус). При этом, что интересно, передающая система, наоборот, может не обеспечивать целостность обработки документов. И тогда надо принимать специальные меры для обеспечения согласованности.
У меня было два подобных кейса. В одном случае требовалось в принимающей системе снять ограничение, связанное с долгим проведением больших документов, потому что некоторые накладные включали тысячи позиций и обычный режим исполнения (целиком) приводил к долгим блокировкам. В этом случае для построчной обработки мы создали отдельную технологическую таблицу со статусами строк и очень аккуратно работали со статусом самого документа.
В другом случае складская система обрабатывала документы отгрузки наоборот, построчно, выдавая общий поток ответов по всем строкам всех входящих документов. Тогда как передающая система рассчитывала, что на каждый переданный документ придет целостный ответ. В этом случае нам пришлось создать специальный промежуточный сервис, который на входе запоминал, сколько строк имеет каждый передаваемый документ, фиксировал полученные ответы и передавал их обратно в отправляющую систему только когда по всем строкам получал ответ. Он также поднимал тревогу, когда ответ по некоторым строкам слишком долго задерживался. Эвристики для этого алгоритма мы прорабатывали отдельно, так как за формированием ответа стояла реальная обработка позиций документа людьми, которая, естественно, была далеко не мгновенной.
На этом я завершаю третью статью про интеграцию. Надеюсь, она помогла вам разобраться в различных вариантах взаимодействия систем, и это окажется полезным при проектировании, разработке и тестировании.
С 1 февраля стоимость очного участия в DevOpsConf 2021 составит 36000 рублей. Забронируйте билет сейчас, и у вас будет ещё несколько дней на оплату.
На данный момент Программный комитет одобрил уже около 40 докладов, но до 28 февраля ещё принимает заявки. Если вы хотите быть спикером, то подать доклад можно здесь.
Чтобы быть на связи, подписывайтесь на наши соцсети, чтобы не упустить важные новости о конференции и наших онлайн-событиях — VK, FB, Twitter, Telegram-канал, Telegram-чат.
