
С каждым годом культура разработки растет, появляются новые инструменты для обеспечения качества кода и новые идеи, как эти инструменты использовать. Мы уже писали про устройство статического анализа, про то, на какие аспекты анализаторов нужно обращать внимание, и, наконец, про то, как с организационной точки зрения можно построить процесс на основе статического анализа.
Отталкиваясь от вопросов, с которыми мы часто сталкиваемся, мы описали весь процесс внедрения сканера кода в процесс безопасной разработки. Сегодня речь пойдет о том, как выбрать подходящий вам анализатор.
Все разработчики так или иначе сталкиваются со статическим анализом (анализом кода без выполнения). Например, когда компилятор по результатам сборки выдает какие-то ошибки или предупреждения — это результаты статического анализа. Мы часто используем линтеры — это тоже статический анализ, хоть зачастую и очень простой. Есть и более интересные примеры — spotbugs (ранее — findbugs), который позволяет находить довольно интересные уязвимости в байткоде Java, или хорошо известный SonarQube — платформа для контроля качества кода.
Однако с полноценными SAST-инструментами пока мы сталкиваемся редко. В первую очередь мы говорим про тулы, которые могут находить сложные уязвимости. Как оказывается на практике, открытые известные инструменты не справляются с этой задачей, как минимум потому, что фокусируются на другой области (баги и простые уязвимости). Хороший SAST-тул реализует межпроцедурный анализ потока данных. Анализ должен проходить не на тексте программы, а на внутреннем представлении — CFG, AST и т.п. Про это подробнее лучше почитать в предыдущей статье.
SAST
Здесь приведем пример — всем известную SQL-инъекцию. В этом примере данные от пользователя попадают в функцию completed из запроса, передаются в функцию injectableQuery и уже там попадают в SQL-запрос, делая приложение уязвимым к SQL-инъекции.

Для того чтобы найти такую уязвимость, нужно понимать, откуда могут приходить “плохие” данные, как такие данные могут валидироваться, где их нельзя использовать. И самое важное — нужно отслеживать передачу данных по всему приложению, это и есть dataflow-анализ. Пример очень простой, в реальном же приложении данные могут пройти через множество функций и модулей, присваиваний и синонимов.
Понятно, что текстовый поиск не найдет такую уязвимость. Внутрипроцедурный анализ также не найдет, а в некоторых открытых инструментах только он и реализован. Чтобы находить такие уязвимости (а это обычно и есть самые критические уязвимости, то есть главная цель работы SAST-тула), нужны хорошо проработанные алгоритмы межпроцедурного анализа потока данных с большими базами правил.
Именно исходя из алгоритмической сложности возникает ряд технических вопросов, которые отличают внедрение SAST-инструмента от других статических анализаторов, например, SonarQube. Эти вопросы мы и обсудим в серии статей. Спойлер: потребление ресурсов, продолжительность анализа, ложные срабатывания.
Надо упомянуть, что помимо алгоритмов хороший инструмент оборачивает всю математику в удобную интерфейсную оболочку, позволяя использовать SAST без серьезной подготовки. Такие инструменты также встраиваются в CI/CD с помощью плагинов и API, таким образом автоматизируя поиск уязвимостей и позволяя строить процессы безопасной разработки.

В первой статье мы попытались классифицировать основные вопросы, которые возникают при изучении SAST, а также и после решения внедрить инструмент. О каких-то вопросах поговорим здесь, какие-то уйдут в следующие статьи.
Начнём
Зачем SAST, если уже есть бесплатные статические анализаторы?
Этот вопрос мы частично затронули в предыдущей части. Мы, конечно, ни в коем случае не умаляем заслуги открытых инструментов. Все знают SonarQube — прекрасный инструмент для автоматизации оценки качества кода, с большим количество поддерживаемых языков, интеграций и плагинов. SonarQube хорош для встраивания в процесс разработки, но предназначен больше для подсчета различных метрик кода и поиска достаточно простых ошибок или уязвимостей. В нем не реализован межпроцедурный анализ потока данных, соответственно, его нельзя использовать для поиска сложных уязвимостей. Обычно мы рекомендуем использовать как SonarQube, так и хороший SAST-тул (тут может быть полезно, если SAST-тул умеет интегрироваться с SonarQube).
Есть и другие хорошие открытые статические анализаторы. Можно назвать spotbugs (findbugs) для байткода JVM с плагином find-sec-bugs, в котором реализован внутрипроцедурный анализ потока данных с небольшим набором правил. Для Python есть известный анализатор bandit. Нельзя не упомянуть встроенный в clang статический анализатор, который обладает и хорошим движком анализа, и неплохой базой правил.

Проблемы таких инструментов в том, что обычно они довольно узко специализированы (например, подходят для одного языка), реализуют простые алгоритмы (то есть не позволяют находить сложные уязвимости), обладают сильно меньшими базами правил, чем коммерческие инструменты. Помимо этого они обладают меньшим набором функциональности, как интерфейсной, так и интеграционной. Ну и можно упомянуть отсутствие поддержки.
С другой стороны хорошие коммерческие SAST-тулы (а есть и нехорошие) реализуют сложные специфические алгоритмы и обладают обширными базами правил, которые могут насчитывать тысячи записей. Обычно они поддерживают много языков программирования, обладают богатыми возможностями интерфейса и интеграции (плагины, API). Ниже привожу пример, о каких интеграциях может идти речь.

А еще ниже посмотрите на пример схемы интеграции, которую можно построить на основе SAST-инструмента. В целом схема не отличается от внедрения других средств контроля качества кода. Разработчики пишут код и могут сразу запускать проверку SAST. Код попадает в репозиторий и оттуда по различным триггерам с помощью CI/CD попадает в SAST. Результаты сканирования можно либо смотреть в интерфейсе SAST, либо они могут попадать в средства, обеспечивающие процесс разработки (багтрекер, почту и т.п.).
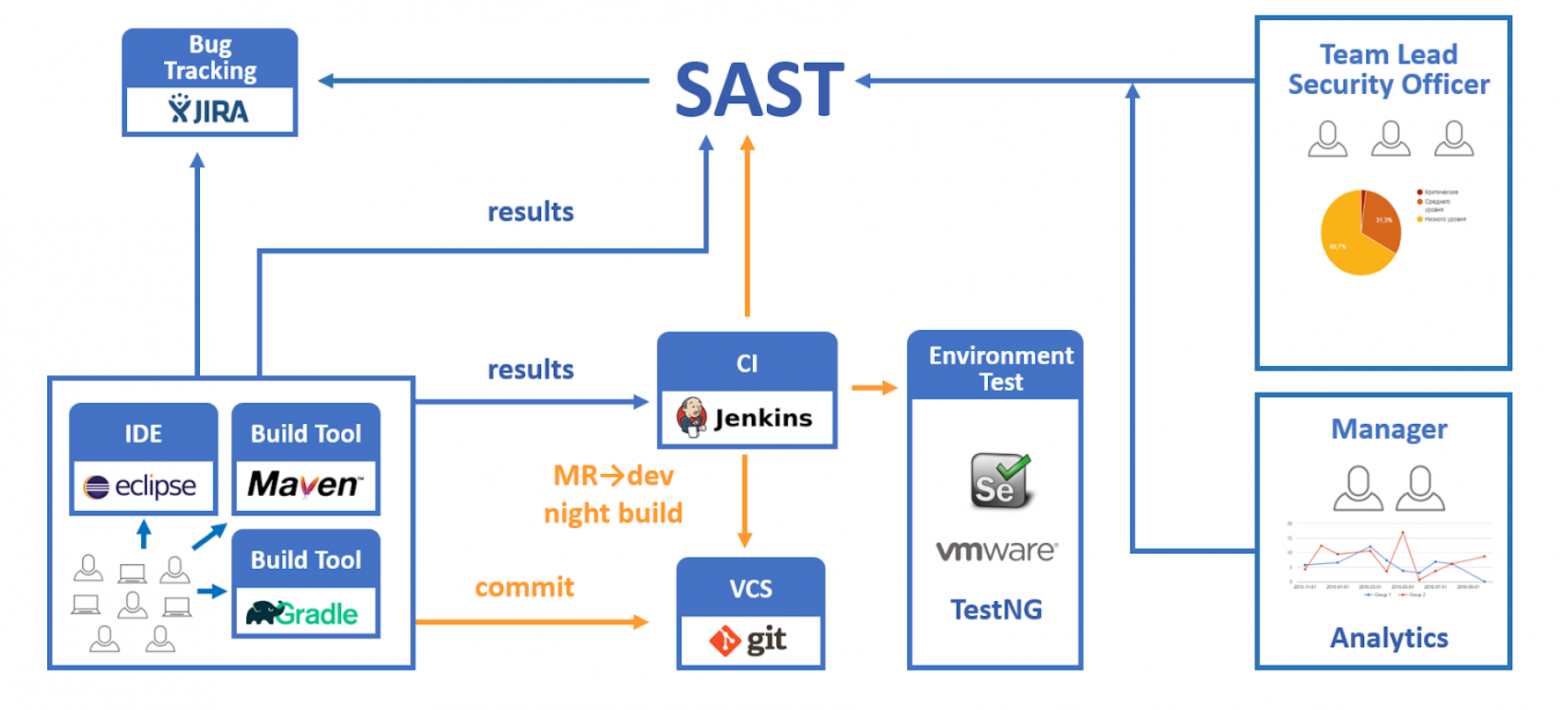
Какой SAST-тул выбрать?
Немного остановлюсь на этапе выбора инструмента. SAST-тулов довольно много, на рынке обычно представлено несколько штук (3-4). Возникает вопрос, как выбрать нужный инструмент, на что обращать внимание? Тут не буду удивлять, остановлюсь на трех пунктах: функциональное сравнение, сравнение по качеству и лицензирование. Важно взять инструмент на тестирование (пилот) в свой локальный контур и проверять на своем коде в своей инфраструктуре.
Хорошо бы попробовать все фичи интерфейса, понять, насколько они применимы к вашему кейсу и насколько ими удобно пользоваться. Отсылаю к одной из предыдущих статей. Приведу несколько полезных фич:
- максимально автоматизированный запуск сканирования (в идеале, без лишних настроек в две кнопки можно запустить скан);
- возможность анализа разных типов приложений — исходный код, бинарный код, несколько языков в одном файле;
- исключение директорий из анализа;
- инкрементальный анализ;
- добавление своих правил поиска уязвимостей;
- сравнение сканирований (качественное, то есть отслеживание уязвимостей между сканами одного проекта);
- редактирование результатов сканирования с отслеживанием результатов редактирования между сканированиями одного проекта;
- понятные описания уязвимостей, желательно с трассой анализа потока данных для уязвимостей типа “внедрение”;
- наличие метрики “уверенность тула в том, что он нашел не ложное срабатывание”;
- гибкое администрирование;
- широкие и удобные в использовании аналитические функции.
Очень важными являются возможности по интеграции — c CI/CD, багтрекерами, репозиториями, Active Directory. Хорошо бы попробовать автоматизировать простое действие с помощью API, если он есть.
Для проверки качества нужно просканировать ваш код. Хорошо выбрать несколько разных примеров на разных языках, чтобы выборка была репрезентативна. С точки зрения качества нужно смотреть на ложные срабатывания (там, где явно нет уязвимости, а тул показывает) и на пропуски (в идеале нужно знать, где есть уязвимости, ну или сравнивать найденные уязвимости в разных тулах). Я бы чуть меньше внимания обращал на ложные срабатывания, так как обычно достаточно один раз пройтись по результатам сканирования, пометить ложные, и дальше они не будут беспокоить вас.
Остановлюсь на двух важных моментах. Во-первых, очень важно смотреть на все это в применении именно к вашей ситуации. Проверять именно ваш код (SAST может по-разному работать на разных типах приложений). Искать те фичи, которые нужны вам для встраивания тула в процесс разработки. Проверять интеграции с системами, которые у вас есть.
Во-вторых, очень важно во время пилота общаться с вендором. SAST — не самая простая штука, и часто достаточно получить обычную консультацию от вендора, чтобы оценить в полную силу мощь инструмента.
В какой момент запускать сканирования?
Чем раньше найдена уязвимость — тем она дешевле. Есть избитые графики, кочующие из презентации в презентацию, даже не буду сюда их добавлять. Но утверждение достаточно очевидное. Одно дело — исправить уязвимость на следующий день после ее внесения, другое дело — вносить изменение на боевой сервер, когда он уже был взломан. Соответственно, нужно переносить использование SAST на ранние стадии разработки. Тут можно поспорить, что внедрение SAST в разработку — само по себе дорогостоящее мероприятие и оно может не окупиться. Тут я поспорю: обычно нахождение нескольких критических уязвимостей покрывает всё внедрение (в рамках пилота можно даже провести оценку).
При таком подходе мы еще и получаем бонус: разработчики, когда видят результаты SAST “каждый день”, продвигаются в знаниях безопасного программирования, таким образом в целом повышается культура безопасной разработки и код становится лучше.
Само собой, при внедрении SAST в процесс разработки необходимо внедрение в CI/CD, построение DevSecOps. Тренд переноса SAST с контрольных проверок перед релизом в процесс разработки виден давно, и в последние 2-3 года он догнал наш рынок. Сейчас ни один пилот не проходит без тестирований возможностей интеграции.
При этом я бы оставлял контрольные проверки перед релизом, в идеале, — по бинарным сборкам (такое тоже возможно). Так можно удостовериться, что никаких новых уязвимостей не было добавлено в процессе сборки и переноса приложения в продуктив.
Технические вопросы
А дальше приведу сразу 4 вопроса.
- Подключим SAST как SonarQube, в чем сложность?
- SAST работает долго, как настроить DevSecOps?
- SAST дает ложные срабатывания, как настроить Quality Gate?
- И без ложных срабатываний в отчете несколько тысяч уязвимостей, что с ними делать?
Это главные технические вопросы, возникающие при внедрении SAST. Они возникают по следующим причинам.
- Из-за экспоненциальной природы алгоритмов SAST может работать долго и потреблять много ресурсов — сильно больше, чем линтер или SonarQube.
- По той же причине SAST может давать довольно много ложных срабатываний — вряд ли разработчики захотят разбирать кучу фолзов каждый день после очередного скана.
- Обычно SAST запускается на кодовой базе впервые, и первый прогон может показать очень много срабатываний, особенно если кода много и база не очень новая.
Все вопросы — решаемые. В следующей статье серии мы разберем на конкретном примере из нашего опыта, как можно внедрить SAST так, чтобы нивелировать все его технические особенности и чтобы все были довольны.
Организационные вопросы
Я бы не стал забывать и про организационные вопросы. В больших компаниях их возникает немало, от самого процесса внедрения, выделения ресурсов до создания регламентов и тиражирования процессов.
Организационные вопросы порождаются теми же техническими особенностями, которые мы обсуждали в предыдущем пункте. Ну а помимо этого пока никуда не девается исторически сложившееся разделение и противостояние разработки и безопасности. Также отсылаю к предыдущей нашей статье.
Продолжение следует
Внедрять SAST — надо, обычно это оправдано. Но, приступая к внедрению, хорошо бы ознакомиться со всеми подводными камнями, которые возникнут на вашем пути. В этой статье мы начали их разбирать, продолжим техническими аспектами в следующей.
