
За последнее время значимость голосовых функций и звука заметно выросла. Примером тому может служить уже громкая история запуска приложения Clubhouse, голосовых ассистентов Сбера и общего оживления интереса со стороны пользователей, компаний и инвесторов к звуку на мобильных устройствах.
В этой статье я бы хотел рассмотреть пример разработки голосового помощника на платформе iOS, используя язык Swift.
Почему голос и звук?
На мой взгляд, звук как интерфейс между пользователем и приложениями изначально был недооценен, однако с появлением технологий искусственного интеллекта, высокой информационной нагрузки и нехватки времени, польза аудио становится очевиднее.
Например, в этой статье представлены интересные факты об использовании голоса за последние 4 года и вывод:
The key, however, is the device letting the human think and speak like a human. Once we get there, this whole voice thing will become the predominant mode for input. We’re likely five to ten years away from getting there. However, many businesses are seeing great success building their own personal assistant apps (aka Alexa Skills or Actions on Google apps) and developing a great deal of positive attention and visibility for their organizations.
То есть, звук и голос как интерфейс имеют шанс стать преобладающим интерфейсом через 5-10 лет когда голосовые ассистенты будут достаточно умными и способными поддерживать разговор как человек. Исследования и развитие технологий в области ИИ в перспективе открывают перед нами подобные возможности.
Технологии синтеза и распознавания речи на iOS
Сегодня есть достаточно большой выбор среди речевых технологий распознавания и синтеза речи. В качестве примера можно привести доступные речевые библиотеки Apple и Yandex.
В Apple Speech Kit синтез и распознавание речи доступны «из коробки» для iOS 10 и выше, а для его использования необходимо подключить Speech.framework в проект. Распознавание речи на достойном уровне, а вот насчет синтеза не могу этого сказать.
В компании Яндекс есть собственные технологии синтеза и распознавания речи — репозитории для iOS и Android с подробными примерами их использования.
Пишем голосовой Hello World!
Напишем своё первое приложение, в котором используем перечисленные выше библиотеки. Создадим новый XCode проект, и поскольку мы будем пока тестировать различные SDK, то определим два таргета: speechkit_apple и speechkit_yandex.
В качестве системы управления зависимостями будем использовать Cocoapods, поэтому в корне проекта необходимо создать Podfile:
Pod file
target 'speechkit_apple' do
end
target 'speechkit_yandex' do
pod 'YandexSpeechKit', '~> 3.12.2'
endПереходим в корень проекта и выполняем pod install чтобы все зависимости установились:
Pod install output
iMac:~ dmitry$ cd /Volumes/Data/work/speechkit_tutorial/chapter1_ios
iMac:chapter1_ios dmitry$ pod install
Analyzing dependencies
Downloading dependencies
Installing YandexSpeechKit (3.12.2)
Generating Pods project
YandexSpeechKit
Pods-speechkit_apple
Pods-speechkit_yandex
Integrating client project
Pod installation complete! There is 1 dependency from the Podfile and 1 total pod installed.
iMac:chapter1_ios dmitry$Оба таргета будут использовать общие ресурсы из папки speechkit_demo_ios и иметь свои реализации SpeechViewController:
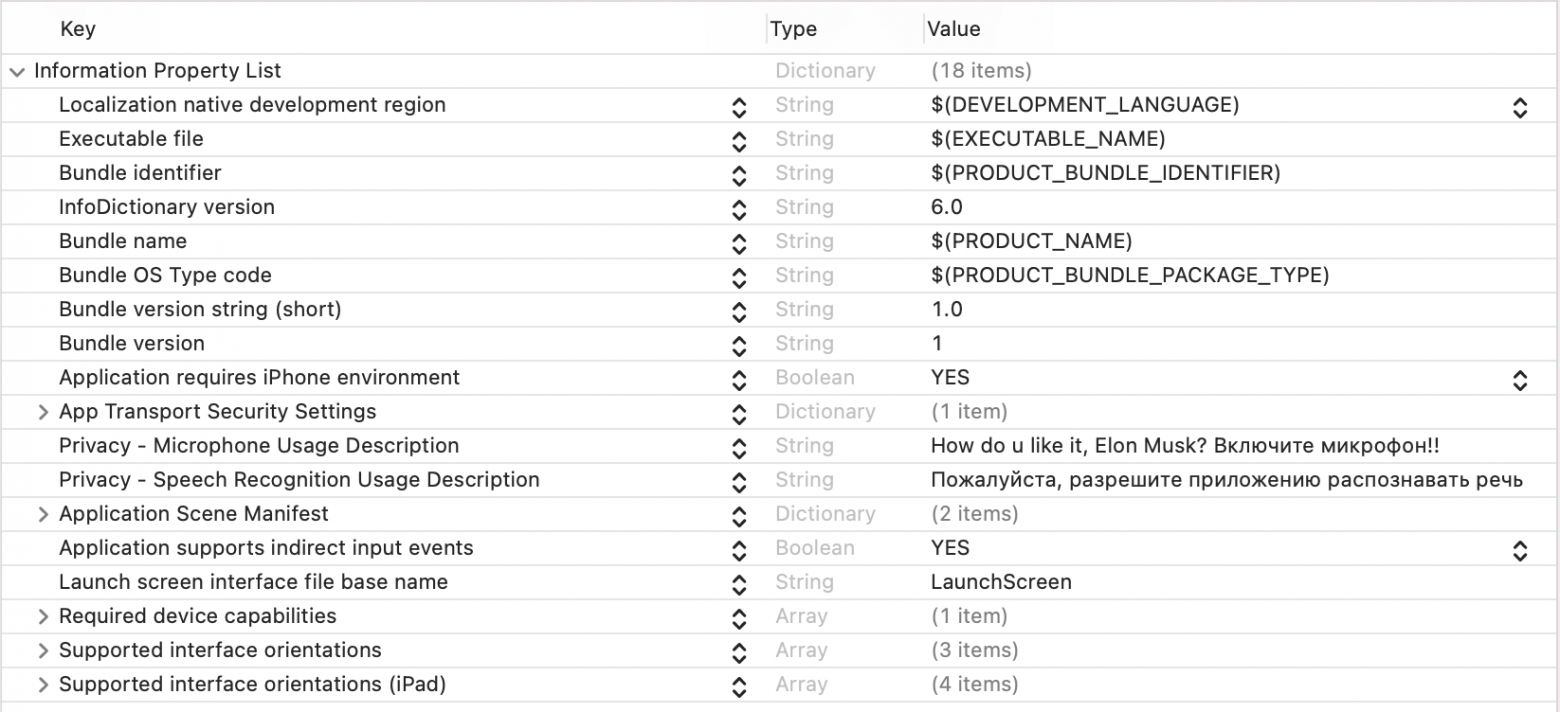
Для работы с микрофоном необходимо разрешение NSMicrophoneUsageDescription, а для распознавания речи NSSpeechRecognitionUsageDescription. Эти ключи и текстовые описания к ним нужно сразу добавить в Info.plist проекта:
Info.plist
<key>NSMicrophoneUsageDescription</key>
<string>Пожалуйста, разрешите использование микрофона для распознавания голоса</string>
<key>NSSpeechRecognitionUsageDescription</key>
<string>Пожалуйста, разрешите приложению распознавать речь</string>В итоге, получится примерно следующее:
Работа с речевым технологиями Apple
В случае Apple в проект необходимо подключить библиотеку Speech и использовать SFSpeechRecognizer, SFSpeechRecognitionTask и AVSpeechSynthesizer для распознавания и синтеза голоса. Для каждой новой сессии распознавания необходимо проделать следующие шаги:
Cоздать новый запрос:
Recoginition request
recognitionRequest = SFSpeechAudioBufferRecognitionRequest()
recognitionRequest.shouldReportPartialResults = trueCоздать задачу распознавания:
Recognition task
recognitionTask = _speechRecognizer?.recognitionTask(with: recognitionRequest!) { [weak self] result, error in var isFinal = false if let result = result { isFinal = result.isFinal self?.log(text: result.bestTranscription.formattedString) } if error != nil || isFinal { // Stop recognizing speech if there is a problem. self?.stopRecording() if isFinal == false, let errorMessage = error?.localizedDescription{ self?.log(text: errorMessage) } } if isFinal == true{ self?.log(text: NSLocalizedString("Finish voice recognition..", comment: "")) } }Cоздать и запустить захват аудио буфера из AVAudioEngine в запрос распознавания:
Audio engine
let recordingFormat = self.audioEngine.inputNode.outputFormat(forBus: 0)
self.audioEngine.inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) {
[weak self] (buffer: AVAudioPCMBuffer, when: AVAudioTime) in
self?.recognitionRequest?.append(buffer)
}
audioEngine.prepare()
try audioEngine.start()Для синтеза речи необходимо инициализировать и запустить AVSpeechSynthesizer:
Синтез речи Apple Speech
let utterance = AVSpeechUtterance(string: text)
utterance.rate = 0.5 // Скорость речи
let voiceIdentifier = "com.apple.ttsbundle.Milena-premium"
utterance.voice = AVSpeechSynthesisVoice.init(identifier: voiceIdentifier)
synthesizer.speak(utterance)Готовый пример приложения можно скачать здесь: chapter1_ios, проект speechkit_demo_ios, таргет speechkit_apple.
Работа с Yandex SpeechKit
Если вы используете Swift, то для подключения Yandex SpeechKit потребуется использовать Bridging-header для связи с Objective-C кодом, который использует эта библиотека. Самый простой способ быстро подключить Bridging-header — создать любой *.m файл в нужном таргете, а затем можно удалить этот файл. В нашем случае к проекту добавится speechkit_yandex-Bridging-Header.h, в котором нужно указать ссылку на header от Objective-C библиотеки компании Yandex:
Bridging header
#ifndef speechkit_yandex_Bridging_Header_h
#define speechkit_yandex_Bridging_Header_h
#import <YandexSpeechKit/YandexSpeechKit.h>
#endif
Далее в Swift коде уже не нужно подключать специально эту библиотеку через конструкцию виде import. Основные шаги инициализации:
указание API ключа. Ключ необходимо создать в личном кабинете Yandex Cloud. Более подробную информацию можно найти в документации:
YSKSpeechKit.sharedInstance().apiKey = "YOUR API KEY"активация аудиосессии не в главном потоке приложения (поскольку это может занимать некоторое время и блокировать UI):
DispatchQueue.global(qos: .default).async {
try? YSKAudioSessionHandler.sharedInstance().activateAudioSession()
}создание и инициализация экземпляров синтезатора и менеджера распознавания речи:
Yandex SpeechKit
let settings = YSKOnlineVocalizerSettings(language: YSKLanguage.russian())
vocalizer = YSKOnlineVocalizer(settings: settings)
vocalizer?.delegate = self
vocalizer?.prepare()
let settings = YSKOnlineRecognizerSettings(language: YSKLanguage.russian(), model: YSKOnlineModel.queries())
recognizer = YSKOnlineRecognizer(settings: settings)
recognizer?.delegate = self
recognizer?.prepare()синтез или старт распознавания речи:
vocalizer?.synthesize(“Hello World!”, mode: .append)
recognizer?.startRecording()В нашем случае ViewController (у вас это может быть View Model или VIPER модуль) должен реализовать протоколы YSKVocalizerDelegate и YSKRecognizerDelegate для возможности получения событий от библиотеки: старт записи, конец записи, окончание распознавания, получения ошибок и т.д.
Готовый пример приложения можно найти здесь: chapter1_ios, проект speechkit_demo_ios, таргет speechkit_yandex.
Создаём своего голосового ассистента

Сделаем несложный голосовой ассистент, который умеет управлять светом, воспроизведением музыки, поддерживать приветствие и отвечать на различные запросы пользователя. Например, может рассказать анекдот, прочитать цитату или прогноз погоды.
Чтобы сделать возможным использование любого речевого SDK используем абстракцию и определим протоколы синтеза и распознавания речи, которые должны будут реализовать конкретные речевые SDK:
Протоколы синтеза и распознавания речи
internal protocol VBSpeechSynthesizerProtocol {
func sythesizeVoice(text: String, completion: ((_ error: Error?)->())?)
func pauseSpeaking()
func stopSynthesize()
var delegate: VBAudioInputDelegate? {get set}
}
internal protocol VBSpeechRecognizerProtocol{
func startRecognize(withAnchors anchors: [String])
func finishRecognize()
func cancelRecognize()
var maxRecordTime: Int? {get}
var delegate: VBSpeechRecognizerDelegate? {get set}
}Например, в случае Apple Speech реализация класса синтеза будет следующая:
Apple speech synthesizer
extension VBAppleSpeechSynthesizer : VBSpeechSynthesizerProtocol{
func sythesizeVoice(text: String, completion: ((Error?) -> ())?) {
let utterance = AVSpeechUtterance(string: text)
utterance.rate = 0.5
utterance.voice = AVSpeechSynthesisVoice.init(identifier: self.voiceIdentifier)
_synthesizer.speak(utterance)
//TO DO: Implement audio metering here..
completion?(nil)
}
func stopSynthesize() {
_synthesizer.stopSpeaking(at: .immediate)
}
func pauseSpeaking() {
_synthesizer.pauseSpeaking(at: .immediate)
}
}
Из первой части статьи мы также знаем, как использовать распознавание речи, используя Apple Speech, поэтому реализуем класс VBAppleSpeechRecognizer в соответствии с протоколом VBSpeechRecognizerProtocol.
Чтобы распознавать окончание записи голоса, сделаем отдельный класс VBVoiceLevelDetector, который реализует протокол VBVoiceLevelDetectorProtocol и будет заниматься отслеживанием начала и окончания записи голосовых фраз. При первом запуске этот класс производит калибровку уровня звука на основе 32 аудио-фреймов.
Для абстракции от музыкального сервиса также опишем протокол:
Music protocol
protocol VBMusicServiceProtocol : class{
var isPlayng: Bool {get}
func disconnect()
func resume()
func pause()
func connect()
func next(play: Bool)
func prev(play: Bool)
func update()
func play(uri: String)
var onConnectedChanged: ((_ isConnected: Bool)->())? { get set }
var onFetchedArtWork: ((_ artWork: UIImage)->())? { get set }
var onStateUpdated: ((_ isPlayerPaused: Bool, _ trackName: String)->())?{ get set }
}и сделаем соответствующую его реализацию в VBAppleMusicPlayer.
Реализация через протоколы очень желательна, поскольку в какой-то момент вы можете захотеть использовать, например, SpotifySDK или Mubert API, а в целях совместимости вам не придется ломать жесткие зависимости от Apple Player в приложении и переход будет проще.
Теперь нам понадобится главный класс, который будет обрабатывать текстовые запросы от пользователя и выдавать результат. Создадим такой класс VoiceBoxManager, который реализует протокол VoiceBoxManagerProtocol, а в качестве коммуникации он будет работать с классом-делегатом, который должен реализовывать протокол VoiceBoxManagerDelegate.
В нашем случае таким делегатом будет выступать VoiceViewModel — View модель для UI контроллера VoiceViewController, который отвечает за визуализацию сообщений и интерфейс пользователя:

Итого, VoiceBoxManager — это общий контейнер или конфигуратор для навыков нашего ассистента:
Voice Box Manager
class VoiceBoxManager{
public static let sharedInstance = VoiceBoxManager()
let musicService: VBMusicServiceProtocol!
weak var delegate: VoiceBoxManagerDelegate?
private let _audioEngine = AVAudioEngine()
private var _speechSynthesizer: VBSpeechSynthesizerProtocol!
private let _assistantProcessors: [VBProcessingProtocol]!
private var _lastUrl: URL?
private var _speechRecognizer: VBSpeechRecognizerProtocol!
init() {
_speechSynthesizer = VBAppleSpeechSynthesizer(engine: _audioEngine)
_speechRecognizer = VBAppleSpeechRecognizer(engine: _audioEngine)
musicService = VBAppleMusicPlayer()
//Набор навыков ассистента
_assistantProcessors = [VBMusicProcessing(musicService: musicService),
VBLocalVoiceProcessing(),
VBHomeKitProcessing(),
VBNewsProcessing(),
VBQuotaProcessing(),
VBCurrencyProcessing(),//Реализован как заглушка
VBWeatherProcessing() //Реализован как заглушка
]
try? initAudio()
}
..
}
, который реализует протокол:
Voice Box Banager protocol
protocol VoiceBoxManagerProtocol {
var delegate: VoiceBoxManagerDelegate? {get set}
var userName: String? {get set}
var isLastLinkExist: Bool {get}
var speechSynthesizer: VBSpeechSynthesizerProtocol {get}
var speechSynthesizerDelegate: VBAudioInputDelegate? {get set}
var speechRecognizerDelegate: VBSpeechRecognizerDelegate? {get set}
func start()
func processUserText(text: String)
}Массив _assistantProcessors содержит реализации протокола VBProcessingProtocol, то есть навыки нашего голосового ассистента:
Processing protocol
typealias processingMessageHandler = (_ responseData:[String : Any]?,_ errorMesage: String?) -> ()
protocol VBProcessingProtocol {
func processMessage(message: String, userName: String?, completion: (processingMessageHandler?))->Bool
func getResponse(with type: ResponseTypeEnum, payload: Any) -> ([String : Any])
}
extension VBProcessingProtocol{
func getResponse(with type: ResponseTypeEnum, payload: Any) -> ([String : Any]){
return ["type" : ResponseTypeEnum.message.rawValue, "data" : payload]
}
}Как можно заметить, классы, реализующие навыки через VBProcessingProtocol, должны отвечать словарём, который содержит «type» — тип ответа и «data». Это сделано чтобы унифицировать ответ навыков и иметь возможность запрашивать любые данные через сторонние API.
Таким образом, мы можем добавлять новые навыки нашему ассистенту, просто добавляя в этот массив новую реализацию протокола VBProcessingProtocol.
Обратите внимание, что обработкой обычных фраз пользователя занимается класс VBLocalVoiceProcessing, который для простоты реализации берёт текстовые значения из файла Resources/voiceProcessigPhrases.plist:

Чтобы добавить обычные реплики ассистента достаточно добавить ответы в этом файле. Конечно, это не искусственный интеллект, однако вам ничего не мешает создать свой класс VBAIVoiceProcessing, который реализует протокол VBProcessingProtocol и, например, будет общаться со своим сервером, использующий для обработки фраз русскоязычную модель GPT-3. Тогда ответы ассистента станут намного интереснее и умнее.
Пример получения афоризмов и цитат можно посмотреть в реализации VBQuotaProcessing, а новостей в VBNewsProcessing. Навыки умного дома реализует класс VBHomeKitProcessing, который в свою очередь использует VBHomeKitManager для управления устройствами Apple HomeKit.
Посмотреть видео-демонстрацию работы приложения можно здесь.
Резюме
В этой статье мы создали мобильные приложение на iOS с использование сторонних речевых SDK. На практике, основные проблемы интеграций речевых технологий заключаются в дополнительных разрешениях, предъявляемых к приложению, получении API ключа и работе с аудио-сессиями. Также попробовали создать собственный голосовой ассистент с абстракцией от используемых речевых технологий и возможностью расширять навыки.
В коде примера chapter2_ios добавлены заготовки для навыков получения курсов валют VBCurrencyProcessing и погоды VBWeatherProcessing. В качестве дополнительной тренировки можно реализовать эти навыки самостоятельно, используя любые открытые API сервисов, например, ЦБ, openweather или другие. Вы также можете добавить собственные навыки, которые считаете интересными и поделиться ими. Для этого сделайте форк репозитория, добавьте навыки и отправьте pull запрос, будет любопытно посмотреть.
Надеюсь, данная статья была полезна, и вы теперь сможете создавать голосовые помощники для своих проектов или даже создать цифровой продукт, который изменит мир =)

Жду ваши примеры реализаций навыков и желаю будущих достижений в области голосовых технологий!

