


В мире есть всего несколько специализированных компаний, которые профессионально занимаются распознаванием музыкальных треков. Насколько нам известно, из поисковых компаний Яндекс стал первым, кто стал помогать российскому пользователю в решении этой задачи. Несмотря на то, что нам предстоит ещё немало сделать, качество распознавания уже сопоставимо с лидерами в этой области. К тому же поиск музыки по аудиофрагменту не самая тривиальная и освещённая в Рунете тема; надеемся, что многим будет любопытно узнать подробности.
О достигнутом уровне качества
Базовым качеством мы называем процент валидных запросов, на которые дали релевантный ответ — сейчас около 80%. Релевантный ответ — это трек, в котором содержится запрос пользователя. Валидными считаем лишь те запросы из приложения Яндекс.Музыки, которые действительно содержат музыкальную запись, а не только шум или тишину. При запросе неизвестного нам произведения считаем ответ заведомо нерелевантным.
Технически задача формулируется следующим образом: на сервер поступает десятисекундный фрагмент записанного на смартфон аудиосигнала (мы его называем запросом), после чего среди известных нам треков необходимо найти ровно тот один, из которого фрагмент был записан. Если фрагмент не содержится ни в одном известном треке, равно как и если он вообще не является музыкальной записью, нужно ответить «ничего не найдено». Отвечать наиболее похожими по звучанию треками в случае отсутствия точного совпадения не требуется.
База треков
Как и в веб-поиске, чтобы хорошо искать, нужно иметь большую базу документов (в данном случае треков), и они должны быть корректно размечены: для каждого трека необходимо знать название, исполнителя и альбом. Как вы, наверное, уже догадались, у нас была такая база. Во-первых, это огромное число записей в Яндекс.Музыке, официально предоставленных правообладателями для прослушивания. Во-вторых, мы собрали подборку музыкальных треков, выложенных в интернете. Так мы получили 6 млн треков, которыми пользователи интересуются чаще всего.
Зачем нам треки из интернета, и что мы с ними делаем
Наша цель как поисковой системы — полнота: на каждый валидный запрос мы должны давать релевантный ответ. В базе Яндекс.Музыки нет некоторых популярных исполнителей, не все правообладатели пока участвуют в этом проекте. С другой стороны, то что у нас нет права давать пользователям слушать какие-то треки с сервиса, вовсе не означает, что мы не можем их распознавать и сообщать имя исполнителя и название композиции.
Раз мы — зеркало интернета, мы собрали ID3-теги и дескрипторы каждого популярного в Сети трека, чтобы опознавать и те произведения, которых нет в базе Яндекс.Музыки. Хранить достаточно только эти метаданные — по ним мы показываем музыкальные видеоклипы, когда нашлись только записи из интернета.
Раз мы — зеркало интернета, мы собрали ID3-теги и дескрипторы каждого популярного в Сети трека, чтобы опознавать и те произведения, которых нет в базе Яндекс.Музыки. Хранить достаточно только эти метаданные — по ним мы показываем музыкальные видеоклипы, когда нашлись только записи из интернета.
Малоперспективные подходы
Как лучше сравнивать фрагмент с треками? Сразу отбросим заведомо неподходящие варианты.
- Побитовое сравнение. Даже если принимать сигнал напрямую с оптического выхода цифрового проигрывателя, неточности возникнут в результате перекодирования. А на протяжении передачи сигнала есть много других источников искажений: громкоговоритель источника звука, акустика помещения, неравномерная АЧХ микрофона, даже оцифровка с микрофона. Всё это делает неприменимым даже нечёткое побитовое сравнение.
- Водяные знаки. Если бы Яндекс сам выпускал музыку или участвовал в производственном цикле выпуска всех записей, проигрываемых на радио, в кафе и на дискотеках — можно было бы встроить в треки звуковой аналог «водяных знаков». Эти метки незаметны человеческому уху, но легко распознаются алгоритмами.
- Нестрогое сравнение спектрограмм. Нам нужен способ нестрогого сравнения. Посмотрим на спектрограммы оригинального трека и записанного фрагмента. Их вполне можно рассматривать как изображения, и искать среди изображений всех треков самую похожую (например, сравнивая как векторы с помощью одной из известных метрик, таких как L²):
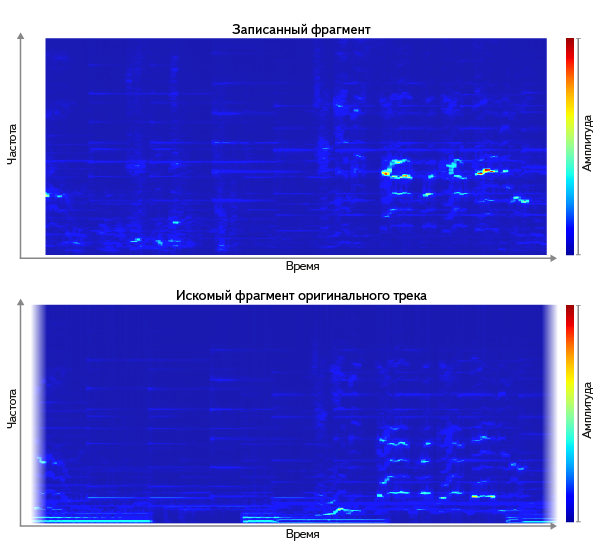
Но в применении этого способа «в лоб» есть две сложности:
а) сравнение с 6 млн картинок — очевидно, дорогая операция. Даже огрубление полной спектрограммы, которое в целом сохраняет свойства сигнала, даёт несколько мегабайт несжатых данных.
б) оказывается что одни различия более показательны, чем другие.
В итоге, для каждого трека нам нужно минимальное количество наиболее характерных (т.е. кратко и точно описывающих трек) признаков.
Каким признакам не страшны искажения?
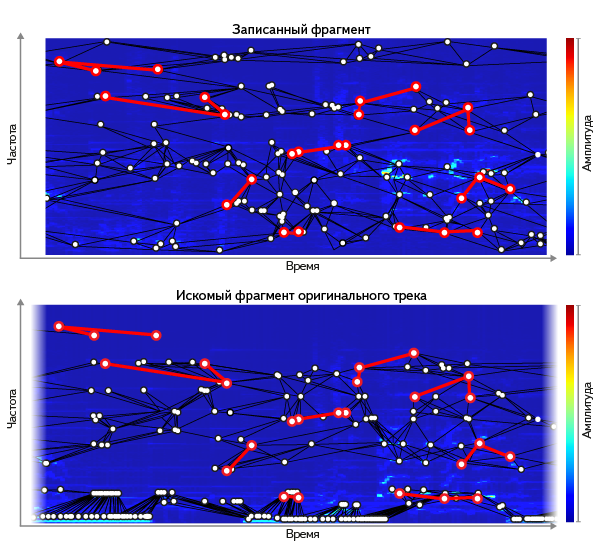
Основные проблемы возникают из-за шума и искажений на пути от источника сигнала до оцифровки с микрофона. Можно для разных треков сопоставлять оригинал с фрагментом, записанным в разных искусственно зашумлённых условиях — и по множеству примеров найти, какие характеристики лучше всего сохраняются. Оказывается, хорошо работают пики спектрограммы, выделенные тем или иным способом — например как точки локального максимума амплитуды. Высота пиков не подходит (АЧХ микрофона их меняет), а вот их местоположение на сетке «частота-время» мало меняется при зашумлении. Это наблюдение, в том или ином виде, используется во многих известных решениях — например, в Echoprint. В среднем на один трек получается порядка 300 тыс. пиков — такой объём данных гораздо более реально сопоставлять с миллионами треков в базе, чем полную спектрограмму запроса.

Но даже если брать только местоположения пиков, тождественность множества пиков между запросом и отрезком оригинала — плохой критерий. По большому проценту заведомо известных нам фрагментов он ничего не находит. Причина — в погрешностях при записи запроса. Шум добавляет одни пики, глушит другие; АЧХ всей среды передачи сигнала может даже смещать частоту пиков. Так мы приходим к нестрогому сравнению множества пиков.
Нам нужно найти во всей базе отрезок трека, наиболее похожий на наш запрос. То есть:
- сначала в каждом треке найти такое смещение по времени, где бы максимальное число пиков совпало с запросом;
- затем из всех треков выбрать тот, где совпадение оказалось наибольшим.
Для этого строим гистограмму: для каждой частоты пика, которая присутствует и в запросе, и в треке, откладываем +1 по оси Y в том смещении, где нашлось совпадение:

Трек с самой высоким столбцом в гистограмме и есть самый релевантный результат — а высота этого столбца является мерой близости между запросом и документом.
Борьба за точность поиска
Опыт показывает, что если искать по всем пикам равнозначно, мы будем часто находить неверные треки. Но ту же меру близости можно применять не только ко всей совокупности пиков документа, но и к любому подмножеству — например, только к наиболее воспроизводимым (устойчивым к искажениям). Заодно это и удешевит построение каждой гистограммы. Вот как мы выбираем такие пики.
Отбор по времени: сначала, внутри одной частоты, по оси времени от начала к концу записи запускаем воображаемое «опускающееся лезвие». При обнаружении каждого пика, который выше текущего положения лезвия, оно срезает «верхушку» — разницу между положением лезвия и высотой свежеобнаруженного пика. Затем лезвие поднимается на первоначальную высоту этого пика. Если же лезвие не «обнаружило» пика, оно немного опускается под собственной тяжестью.
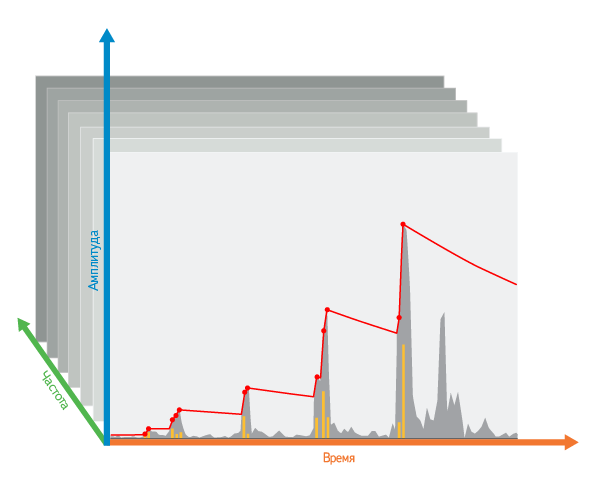
Разнообразие по частотам: чтобы отдавать предпочтение наиболее разнообразным частотам, мы поднимаем лезвие не только в само́й частоте очередного пика, но и (в меньшей степени) в соседних с ней частотах.
Отбор по частотам: затем, внутри одного временно́го интервала, среди всех частот, выбираем самые контрастные пики, т.е. самые большие локальные максимумы среди срезанных «верхушек».
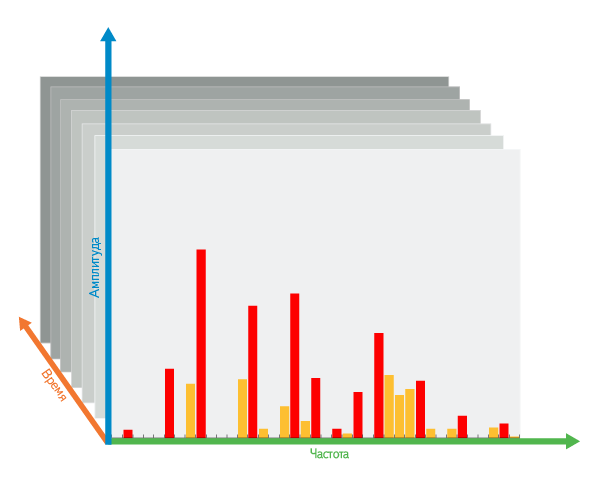
При отборе пиков есть несколько параметров: скорость опускания лезвия, число выбираемых пиков в каждом временно́м интервале и окрестность влияния пиков на соседей. И мы подобрали такую их комбинацию, при которой остаётся минимальное число пиков, но почти все они устойчивы к искажениям.
Ускорение поиска
Итак, мы нашли метрику близости, хорошо устойчивую к искажениям. Она обеспечивает хорошую точность поиска, но нужно ещё и добиться, чтобы наш поиск быстро отвечал пользователю. Для начала нужно научиться выбирать очень малое число треков-кандидатов для расчёта метрики, чтобы избежать полного перебора треков при поиске.
Повышение уникальности ключей: Можно было бы построить индекc
Частота пика → (Трек, Местоположение в нём).Увы, такой «словарь» возможных частот слишком беден (256 «слов» — интервалов, на которые мы разбиваем весь частотный диапазон). Большинство запросов содержит такой набор «слов», который находится в большинстве из наших 6 млн документов. Нужно найти более отличительные (discriminative) ключи — которые с большой вероятностью встречаются в релевантных документах, и с малой в нерелевантных.
Для этого хорошо подходят пары близко расположенных пиков. Каждая пара встречается гораздо реже.
У этого выигрыша есть своя цена — меньшая вероятность воспроизведения в искажённом сигнале. Если для отдельных пиков она в среднем P, то для пар — P2 (т.е. заведомо меньше). Чтобы скомпенсировать это, мы включаем каждый пик сразу в несколько пар. Это немного увеличивает размер индекса, но радикально сокращает число напрасно рассмотренных документов — почти на 3 порядка:
Оценка выигрыша
Например, если включать каждый пик в 8 пар и «упаковать» каждую пару в 20 бит (тогда число уникальных значений пар возрастает до ≈1 млн), то:
- число ключей в запросе растёт в 8 раз
- число документов на ключ уменьшается в ≈4000 раз: ≈1 млн/256
- итого, число напрасно рассмотренных документов уменьшается в ≈500 раз: ≈4000/8
Отобрав с помощью пар малое число документов, можно переходить к их ранжированию. Гистограммы можно с тем же успехом применять к парам пиков, заменив совпадение одной частоты на совпадение обеих частот в паре.
Двухэтапный поиск: для дополнительного уменьшения объёма расчётов мы разбили поиск на два этапа:
- Делаем предварительный отбор (pruning) треков по очень разреженному набору наиболее контрастных пиков. Параметры отбора подбираются так, чтобы максимально сузить круг документов, но сохранить в их числе наиболее релевантный результат
- Выбирается гарантированно наилучший ответ — для отобранных треков считается точная релевантность по более полной выборке пиков, уже по индексу с другой структурой:
Трек→(Пара частот, Местоположение в треке).
В результате всех описанных оптимизаций вся база, необходимая для поиска, стала в 15 раз меньше, чем сами файлы треков.
Индекс в памяти: И наконец, чтобы не ждать обращения к диску на каждый запрос, весь индекс размещён в оперативной памяти и распределён по множеству серверов, т.к. занимает единицы терабайт.
Ничего не найдено?
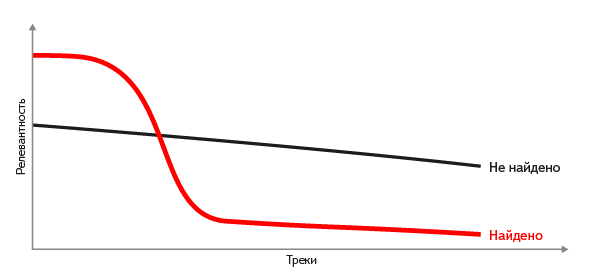
Случается, что для запрошенного фрагмента либо нет подходящего трека в нашей базе, либо фрагмент вообще не является записью какого-либо трека. Как принять решение, когда лучше ответить «ничего не найдено», чем показать «наименее неподходящий» трек? Отсекать по какому-нибудь порогу релевантности не удаётся — для разных фрагментов порог различается многократно, и единого значения на все случаи просто не существует. А вот если отсортировать отобранные документы по релевантности, форма кривой её значений даёт хороший критерий. Если мы знаем релевантный ответ, на кривой отчётливо видно резкое падение (перепад) релевантности, и напротив — пологая кривая подсказывает, что подходящих треков не найдено.
Что дальше
Как уже говорилось, мы в начале большого пути. Впереди целый ряд исследований и доработок для повышения качества поиска: например, в случаях искажения темпа и повышенного шума. Мы обязательно попробуем применить машинное обучение, чтобы использовать более разнообразный набор признаков и автоматически выбирать из них наиболее эффективные.
Кроме того, мы планируем инкрементальное распознавание, т.е. давать ответ уже по первым секундам фрагмента.
Другие задачи аудиопоиска по музыке
Область информационного поиска по музыке далеко не исчерпывается задачей с фрагментом с микрофона. Работа с «чистым», незашумлённым сигналом, претерпевшим только пережатие, позволяет находить дублирующиеся треки в обширной коллекции музыки, а также обнаруживать потенциальные нарушения авторского права. А поиск неточных совпадений и разного вида схожести — целое направление, включающее в себя поиск кавер-версий и ремиксов, извлечение музыкальных характеристик (ритм, жанр, композитор) для построения рекомендаций, а также поиск плагиата.
Отдельно выделим задачу поиска по напетому отрывку. Она, в отличие от распознавания по фрагменту музыкальной записи, требует принципиально другого подхода: вместо аудиозаписи, как правило, используется нотное представление произведения, а зачастую и запроса. Точность таких решений получается сильно хуже (как минимум, из-за несопоставимо бо́льшего разброса вариаций запроса), а поэтому хорошо они опознают лишь наиболее популярные произведения.
Что почитать
- Avery Wang: «An Industrial-Strength Audio Search Algorithm», Proc. 2003 ISMIR International Symposium on Music Information Retrieval, Baltimore, MD, Oct. 2003. Эта статья впервые (насколько нам известно) предлагает использовать пики спектрограммы и пары пиков как признаки, устойчивые к типичным искажениям сигнала.
- D. Ellis (2009): «Robust Landmark-Based Audio Fingerprinting». В этой работе даётся конкрентый пример реализации отбора пиков и их пар с помощью «decaying threshold» (в нашем вольном переводе — «опускающегося лезвия»).
- Jaap Haitsma, Ton Kalker (2002): «A Highly Robust Audio Fingerprinting System». В данной статье предложено кодировать последовательные блоки аудио 32 битами, каждый бит описывает изменение энергии в своем диапазоне частот. Описанный подход легко обобщается на случай произвольного кодирования последовательности блоков аудиосигнала.
- Nick Palmer: «Review of audio fingerprinting algorithms and looking into a multi-faceted approach to fingerprint generation». Основной интерес в данной работе представляет обзор существующих подходов к решению описанной задачи. Также описаны этапы возможной реализации.
- Shumeet Baluja, Michele Covell: «Audio Fingerprinting: Combining Computer Vision & Data Stream Processing». Статья, написанная коллегами из Google, описывает подход на основе вейвлетов с использованием методов компьютерного зрения.
- Arunan Ramalingam, Sridhar Krishnan: «Gaussian Mixture Modeling Using Short Time Fourier Transform Features For Audio Fingerprinting» (2005). В данной статье предлагается описывать фрагмент аудио с помощью модели Гауссовых смесей поверх различных признаков, таких как энтропия Шеннона, энтропия Реньи, спектрольные центроиды, мэлкепстральные коэффициенты и другие. Приводятся сравнительные значения качества распознавания.
- Dalibor Mitrovic, Matthias Zeppelzauer, Christian Breiteneder: «Features for Content-Based Audio Retrieval». Обзорная работа про аудио-признаки: как их выбирать, какими свойствами они должны обладать и какие существуют.
- Natalia Miranda, Fabiana Piccoli: «Using GPU to Speed Up the Process of Audio Identification». В статье предлагается использование GPU для ускорения вычисления сигнатур.
- Shuhei Hamawaki, Shintaro Funasawa, Jiro Katto, Hiromi Ishizaki, Keiichiro Hoashi, Yasuhiro Takishima: «Feature Analysis and Normalization Approach for Robust Content-Based Music Retrieval to Encoded Audio with Different Bit Rates.» MMM 2009: 298-309. В статье акцентируется внимание на повышении робастности представления аудиосигнала на основе мел-кепстральных коэффициентов (MFCC). Для этого используется метод нормализации кепстра (CMN).
