Каждая система мониторинга сталкивается с тремя видами проблем, связанных с производительностью.
Во-первых, хорошая система мониторинга должна очень быстро получать, обрабатывать и записывать поступающие извне данные. Счёт идёт на микросекунды. Навскидку это может показаться неочевидным, но когда система становится достаточно большой, все эти доли секунд суммируются, превращаясь в хорошо заметные задержки.

Вторая задача — обеспечить удобный доступ к большим массивам ранее собранных метрик (другими словами, к историческим данным). Исторические данные используются в самых разных контекстах. По ним, например, генерируются отчёты и графики, на них строятся агрегированные проверки, от них зависят триггеры. Если есть какие-то задержки при доступе к истории, то это сразу сказывается на быстродействии всей системы в целом.
В-третьих, исторические данные занимают много места. Даже относительно скромные конфигурации мониторинга очень быстро обзаводятся солидной историей. Но вряд ли кто-то захочет держать под рукой историю загрузки процессора пятилетней давности, поэтому система мониторинга должна уметь не только хорошо записывать, но и хорошо удалять историю (в Zabbix этот процесс называется «housekeeping»). Удаление старых данных не обязано быть таким же эффективным, как сбор и анализ новых, но тяжёлые операции удаления оттягивают на себя драгоценные ресурсы СУБД и могут замедлить более критичные операции.
Первые две проблемы решаются кешированием. Zabbix поддерживает несколько специализированных кешей для ускорения операций чтения и записи данных. Механизмы самой СУБД здесь не подходят, т.к. даже самый современный алгоритм кеширования общего назначения не будет знать какие структуры данных требуют моментального доступа в заданный момент времени.
Всё хорошо, пока данные находятся в памяти сервера Zabbix. Но память не бесконечна и в какой-то момент данные требуется записать (или прочитать) в базу. И если производительность базы данных серьезно отстает от скорости сбора метрик, то тут никакие даже самые продвинутые специальные алгоритмы кеширования надолго не помогут.
Третья проблема также сводится к производительности базы данных. Для её решения надо подобрать надежную стратегию удаления, которая бы не мешала другим операциям БД. По умолчанию, Zabbix удаляет исторические данные пакетами по несколько тысяч записей в час. Можно настроить более длительные периоды хаускипинга или бОльшие размеры пакетов если скорость сбора данных и место в базе это позволяют. Но при очень большом количестве метрик и/или высокой частоте их сбора правильная настройка хаускипинга может быть непростой задачей, поскольку график удаления данных может не успевать за темпами записи новых.
Обобщая, система мониторинга решает задачи производительности по трём направлениям — сбор новых данных и их запись в базу с помощью SQL запросов INSERT, доступ к данным с помощью запросов SELECT, а также удаление данных с помощью DELETE. Давайте посмотрим, как выполняется типичный SQL-запрос:
В общем, работы тут немало. Большинство СУБД дают массу настроек для оптимизации запросов, но они обычно ориентированы на некие усредненные рабочие процессы, в которых вставка и удаление записей происходит примерно с той же частотой, как и изменение.
Однако, как упоминалось выше, для систем мониторинга наиболее характерны операции добавления и периодического удаления в пакетном режиме. Изменение ранее добавленных данных почти никогда не происходит, а доступ к данным предполагает использование агрегированных функций. Кроме того, обычно значения добавляемых метрик упорядочены по времени. Такие данные обычно называются временными рядами (time series):
С точки зрения базы данных временные ряды обладают следующими свойствами:
Очевидно, что традиционные базы данных SQL не подходят для хранения таких данных, так как оптимизации общего назначения не учитывают эти качества. Поэтому в последние годы появилось довольно много новых, ориентированных на временные ряды СУБД, таких как, например, InfluxDB. Но у всех популярных СУБД для временных рядов есть один существенный недостаток — отсутствие поддержки SQL в полном объёме. Более того, большинство из них даже не являются CRUD (Create, Read, Update, Delete).
Может ли Zabbix каким-то образом использовать эти СУБД? Один из возможных подходов — передавать исторические данные на хранение во внешнюю, специализированную под временные ряды СУБД. Учитывая, что архитектура Zabbix поддерживает внешние бэкэнды для хранения исторических данных (например, так в Zabbix реализована поддержка Elasticsearch), на первый взгляд этот вариант выглядит весьма разумно. Но если бы мы поддерживали одну или несколько СУБД для временных рядов в качестве внешних серверов, то пользователям надо было бы считаться со следующими моментами:
Для некоторых пользователей преимущества специализированного выделенного хранилища под исторические данные могут перевесить неудобства, связанные с необходимостью беспокоиться еще об одной системе. Но для многих такое — излишнее усложнение. Также стоит помнить, что поскольку большинство таких специализированных решений имеют собственные API, то сложность универсального слоя для работы с БД Zabbix заметно возрастёт. А мы, в идеале, предпочитаем создавать новые функции, а не бороться с чужими API.
Возникает вопрос — есть ли способ воспользоваться преимуществами СУБД для временных рядов, но без потери гибкости и преимуществ SQL? Естественно, универсального ответа не существует, но одно конкретное решение подобралось к ответу очень близко – TimescaleDB.
TimescaleDB (TSDB) — это расширение PostgreSQL, которое оптимизирует работу с временными рядами в обычной базе данных PostgreSQL (PG). Хотя, как упомянуто выше, на рынке нет недостатка в хорошо масштабируемых решениях для временных рядов, уникальной чертой TimescaleDB является способность хорошо работать с временными рядами не жертвуя совместимостью и преимуществами традиционных реляционных баз CRUD. На практике это означает, что мы получаем лучшее из обоих миров. База данных знает, какие таблицы должны рассматриваться как временные ряды (и применять все необходимые оптимизации), но с ними можно работать так же как и с обычными таблицами. Более того, приложения совсем не обязаны знать, что данные контролирует TSDB!
Чтобы отметить таблицу как таблицу временных рядов (в TSDB это называется гипертаблицей — hypertable), достаточно вызвать процедуру TSDB create_ hypertable(). Под капотом TSDB разделяет эту таблицу на так называемые фрагменты (английский термин — chunk) в соответствии с заданными условиями. Фрагменты можно представлять как автоматически управляемые секции таблицы. У каждого фрагмента есть соответствующий временной диапазон. Для каждого фрагмента TSDB также устанавливает специальные индексы, чтобы работа с одним диапазоном данных не влияла на доступ к другим.
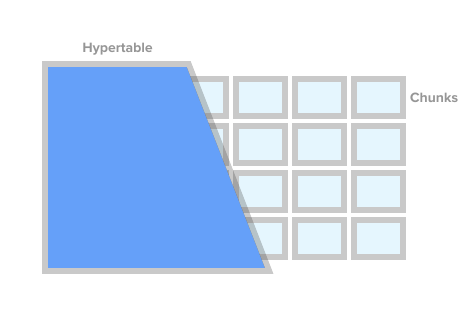
Hypertable Image from timescaledb.com
Когда приложение добавляет новое значение временного ряда, расширение направляет это значение в нужный фрагмент. Если диапазон для времени нового значения не определён, то TSDB создаст новый фрагмент, присвоит ему нужный диапазон и вставит значение туда. Если приложение запрашивает данные из гипертаблицы, то перед выполнением запроса расширение проверяет, какие фрагменты связаны с этим запросом.
Но и это еще не все. TSDB дополняет надежную и проверенную временем экосистему PostgreSQL множеством изменений, связанных с производительностью и масштабируемостью. К ним относятся быстрое добавление новых записей, быстрые запросы по времени и практически бесплатные пакетные удаления.
Как отмечалось ранее, для того, чтобы контролировать размер базы данных и соблюдать политики хранения (т.е. не хранить данные дольше необходимого), хорошее решение для мониторинга должно эффективно удалять большое количество исторических данных. С помощью TSDB мы можем удалить нужную историю, просто удалив определенные фрагменты из гипертаблицы. При этом приложению не нужно отслеживать фрагменты по именам или любым другим ссылкам, TSDB удалит все нужные фрагменты по заданному временному условию.
На первый взгляд может показаться, что TSDB — это красивая обёртка вокруг стандартного секционирования таблиц PG (декларативное секционирование, как это официально называется в PG10). Действительно, для хранения исторических данных можно воспользоваться стандартным секционированием PG10. Но если присмотреться поближе, то фрагменты TSDB и секции PG10 — это далеко не тождественные понятия.
Для начала, настройка секционирования в PG требует вникнуть в детали, которыми по-хорошему должно заниматься либо само приложение либо СУБД. Во-первых, необходимо распланировать иерархию секций и решить, следует ли использовать вложенные секции (nested partitions). Во-вторых, нужно придумать схему наименования разделов и как-то переложить её в скрипты создания схемы. Скорее всего схема наименования будет включать дату и/или время и такие имена надо будет как-то автоматизировать.
Далее, нужно продумать как удалять данные с истёкшим сроком хранения. В TSDB можно просто вызвать команду drop_chunks(), которая определяет удаляемые за заданный промежуток времени фрагменты. В PG10, если нужно удалить определенный диапазон значений из стандартных секций PG, то вычислять список имён секций для этого диапазона придётся самостоятельно. Если выбранная схема секционирования предполагает вложенные секции, это ещё более усложняет удаление.
Ещё одна проблема, которую придётся решать — это, что делать с данными, которые выходят за рамки текущих временных диапазонов. Например, данные могут придти из будущего, под которое ещё не созданы секции. Или из прошлого для уже удалённых секций. По умолчанию в PG10 добавление такой записи не сработает и мы просто потеряем данные. В PG11 можно определить секцию по умолчанию для таких данных, но это лишь временно маскирует проблему, а не решает ее.
Конечно, все вышеперечисленные проблемы решаемы тем или иным способом. Можно увешать базу триггерами, cron-джобами и обильно приправить скриптами. Будет хоть и некрасиво, но работоспособно. Без сомнений, секции PG лучше, чем гигантские монолитные таблицы, но что точно не решаемо через скрипты и триггеры, так это рассчитанные на временные ряды улучшения, которых нет в PG.
Т.е. по сравнению с секциями PG гипертаблицы TSDB выгодно отличаются не только экономией нервов DB-администраторов, но и оптимизациями как доступа к данным, так и добавления новых. Например, фрагменты в TSDB — всегда одномерный массив. Это упрощает управление фрагментами и ускоряет вставки и выборки. Для добавления новых данных TSDB использует свой собственный алгоритм маршрутизации в нужный фрагмент, который, в отличии от стандартного PG, не открывает сразу все секции. При большом количестве секций разница в производительности может отличаться в разы. Технические подробности о разнице между стандартным секционированием в PG и в TSDB можно прочесть в этой статье.
Из всех возможных вариантов TimescaleDB выглядит наиболее безопасным выбором для Zabbix и его пользователей:
Давайте посмотрим, что нужно сделать, чтобы запустить TSDB со свежеустановленным Zabbix. После установки Zabbix и запуска скриптов создания базы PostgreSQL необходимо скачать и установить TSDB на нужную платформу. Инструкции по установке см. здесь. После установки расширения необходимо включить его для базы Zabbix, а затем запустить скрипт timecaledb.sql, поставляемый вместе с Zabbix. Он расположен либо в database/postgresql/timecaledb.sql, если установка производится из исходников, либо в /usr/share/zabbix/database/timecaledb.sql.gz, если установка выполняется из пакетов. На этом всё! Теперь можно запустить сервер Zabbix и он будет работать с TSDB.
Скрипт timescaledb.sql тривиален. Все, что он делает — конвертирует обычные исторические таблицы Zabbix в гипертаблицы TSDB и изменяет настройки по умолчанию — устанавливает параметры Override item history period и Override item trend period. Сейчас (версия 4.2) под управлением TSDB работают следующие таблицы Zabbix — history, history_uint, history_str, history_log, history_text, trends и trends_uint. Этот же скрипт может быть использован для миграции этих таблиц (обратите внимание, что параметр migrate_data установлен в true). Нужно иметь в виду, что миграция данных — это очень длительный процесс и может занять несколько часов.
Перед запуском timecaledb.sql изменения также может потребовать параметр chunk_time_interval => 86400. chunk_time_interval — это промежуток, ограничивающий время значений, попадающих в этот фрагмент. Например, если задать интервал chunk_time_interval равным 3 часам, то данные за целый день будут распределены по 8 фрагментам, причем первый фрагмент №1 будет охватывать первые 3 часа (0:00-2:59), второй фрагмент №2 — вторые 3 часа (3:00-5:59) и т.д. Последний фрагмент №8 будет содержать значения со временем 21:00-23:59. 86400 секунд (1 день) — это среднее значение по умолчанию, но пользователи нагруженных систем могут захотеть его уменьшить.
Чтобы примерно оценить требования к памяти важно понимать сколько места в среднем может занимать один фрагмент. Общий принцип — у системы должно хватить памяти, чтобы расположить как минимум по одному фрагменту из каждой гипертаблицы. При этом, конечно, сумма размеров фрагментов должна не только влезать в память с запасом, но и быть меньше, чем значение параметра shared_buffers из postgresql.conf. Дополнительную информацию по данной теме можно найти в документации TimescaleDB.
Например, если у вас есть система, которая собирает, в основном, целочисленные метрики и вы решили разделить таблицу history_uint на 2-часовые фрагменты, а остальные таблицы разделить на однодневные фрагменты, то вам нужно изменить эту строку в timecaledb.sql:
После того, как накопилось некоторое количество исторических данных, можно проверить размеры фрагментов для таблицы history_uint, вызвав chunk_relation_size():
Этот вызов можно повторить, чтобы найти размеры фрагментов для всех гипертаблиц. Если, например, обнаружилось, что размер фрагмента history_uint составляет 13MB, фрагментов для других таблиц истории, скажем, 20MB и для таблиц трендов 10MB, то общая потребность в памяти составляет 13 + 4 x 20 + 2 x 10 = 113MB. Надо также оставить место из shared_buffers для хранения других данных, скажем 20%. Тогда значение shared_buffers надо установить в 113MB / 0.8 = ~140MB.
Для более тонкой настройки TSDB недавно появилась утилита timescaledb-tune. Она анализирует postgresql.conf, соотносит его с конфигурацией системы (память и процессор), а затем выдает рекомендации по настройке параметров памяти, параметров для параллельной обработки, WAL. Утилита меняет postgresql.conf файл, но её можно запустить с параметром -dry-run и проверить предложенные изменения.
Подробнее остановимся на параметрах Zabbix Override item history period и Override item trend period (доступны в Administration -> General -> Housekeeping). Они необходимы, чтобы удалять исторические данные целыми фрагментами гипертаблиц TSDB, а не записями.
Дело в том, что Zabbix позволяет устанавливать период хаускипинга для каждого элемента данных (метрики) индивидуально. Однако, такая гибкость достигается за счёт сканирования списка элементов и расчета индивидуальных периодов в каждой итерации хаускипинга. Если в системе настроены индивидуальные периоды хаускипинга для отдельных элементов, то в системе, очевидно, не может быть единой точки отсечения истории для всех метрик вместе и Zabbix не сможет дать правильную команду на удаление нужных фрагментов. Таким образом, выключив Override history для метрик, у Zabbix пропадёт возможность быстро удалять историю вызывая процедуру drop_chunks() для таблиц history_*, и, соответственно, выключив Override trends пропадёт та же функция для таблиц trends_*.
Другими словами, чтобы в полной мере воспользоваться преимуществами новой системы хаускипинга, надо сделать оба варианта глобальными. В этом случае процесс хаускипинга вообще не будет считывать настройки элементов данных.
Пора проверить, действительно ли все вышесказанное работает на практике. Наша тестовый стенд — Zabbix 4.2rc1 с PostgreSQL 10.7 и TimescaleDB 1.2.1 под Debian 9. Тестовая машина — это 10-ядерный Intel Xeon с 16 ГБ оперативной памяти и 60 ГБ дискового пространства на SSD. По нынешним меркам это очень скромная конфигурация, но наша цель — выяснить, насколько эффективен TSDB в реальной жизни. В конфигурациях с неограниченным бюджетом можно просто вставить 128-256 ГБ оперативной памяти и поместить большую часть (если не всю) БД в память.
Наша тестовая конфигурация состоит из 32 активных агентов Zabbix, передающих данные непосредственно на сервер Zabbix Server. Каждый агент обслуживает по 10000 элементов. Исторический кэш Zabbix установлен в 256MB, а shared_buffers PG — 2ГБ. Такая конфигурация обеспечивает достаточную нагрузку на базу данных, но в то же время не создает большой нагрузки на серверные процессы Zabbix. Чтобы уменьшить количество движущихся частей между источниками данных и базой, мы не использовали Zabbix Proxy.
Вот первый результат, полученный из стандартной системы PG:

Результат работы TSDB выглядит совсем иначе:

Приведённый ниже график объединяет оба результата. Работа начинается с достаточно высоких значений NVPS в 170-200K, т.к. требуется некоторое время для заполнения кэша истории, прежде чем начинается синхронизация с БД.

Когда таблица истории незаполнена, скорость записи в TSDB сравнима со скоростью записи в PG, причём даже с небольшим отрывом последнего. Как только количество записей в истории достигает 50-60 миллионов, пропускная способность PG падает до 110K NVPS, но, что более неприятно, она и далее меняется обратно пропорционально количеству накопленных в исторической таблице записей. В то же время, TSDB поддерживает стабильную скорость в 130K NVPS в течение всего теста от 0 до 300 миллионов записей.
Итого, в нашем примере разница в усреднённой производительности весьма существенна (130K против 90K без учета начального пика). Также видно, что скорость вставок в стандартном PG варьируется в широком диапазоне. Таким образом, если рабочий процесс требует хранения десятков или сотен миллионов записей в истории, но нет ресурсов для стратегий очень агрессивного кеширования, то TSDB — сильный кандидат на замену стандартного PG.
Преимущество TSDB уже очевидно для этой относительно скромной системы, но скорее всего разница станет ещё более заметной на бОльших массивах исторических данных. С другой стороны, этот тест — отнюдь не обобщение всех возможных сценариев работы с Zabbix. Естественно, существует множество влияющих на результаты факторов, таких как аппаратные конфигурации, настройки операционной системы, параметры сервера Zabbix и дополнительная нагрузка со стороны других служб, работающих в фоновом режиме. Т.е., your mileage may vary.
TimescaleDB — очень перспективная технология. Она уже успешно эксплуатируется в серьезных производственных средах. TSDB хорошо работает с Zabbix и дает заметные преимущества по сравнению со стандартной базой данных PostgreSQL.
Есть ли у TSDB какие-нибудь недостатки или причины повременить с её использованием? С технической точки зрения никаких аргументов против мы не видим. Но следует иметь в виду, что технология всё ещё новая, с неустоявшимся циклом релизов и неясной стратегией развития функционала. В частности, каждый месяц или два выпускаются новые версии с существенными изменениями. Некоторые функции, могут быть удалены, как это, например, случилось с adaptive chunking. Отдельно, как ещё один фактор неопределённости, стоит упомянуть лицензионную политику. Она весьма запутана, поскольку существует три уровня лицензирования. Ядро TSDB сделано под лицензией Apache, некоторые функции выпущены под их собственной лицензией «Timescale License», но есть также закрытая версия Enterprise.
Если вы используете Zabbix с PostgreSQL, то причин хотя бы не попробовать TimescaleDB нет. Возможно, эта вещь вас приятно удивит :) Только имейте в виду, что поддержка TimescaleDB в Zabbix пока что является экспериментальной — на время, пока мы собираем отзывы пользователей и накапливаем опыт.
Во-первых, хорошая система мониторинга должна очень быстро получать, обрабатывать и записывать поступающие извне данные. Счёт идёт на микросекунды. Навскидку это может показаться неочевидным, но когда система становится достаточно большой, все эти доли секунд суммируются, превращаясь в хорошо заметные задержки.
Вторая задача — обеспечить удобный доступ к большим массивам ранее собранных метрик (другими словами, к историческим данным). Исторические данные используются в самых разных контекстах. По ним, например, генерируются отчёты и графики, на них строятся агрегированные проверки, от них зависят триггеры. Если есть какие-то задержки при доступе к истории, то это сразу сказывается на быстродействии всей системы в целом.
В-третьих, исторические данные занимают много места. Даже относительно скромные конфигурации мониторинга очень быстро обзаводятся солидной историей. Но вряд ли кто-то захочет держать под рукой историю загрузки процессора пятилетней давности, поэтому система мониторинга должна уметь не только хорошо записывать, но и хорошо удалять историю (в Zabbix этот процесс называется «housekeeping»). Удаление старых данных не обязано быть таким же эффективным, как сбор и анализ новых, но тяжёлые операции удаления оттягивают на себя драгоценные ресурсы СУБД и могут замедлить более критичные операции.
Первые две проблемы решаются кешированием. Zabbix поддерживает несколько специализированных кешей для ускорения операций чтения и записи данных. Механизмы самой СУБД здесь не подходят, т.к. даже самый современный алгоритм кеширования общего назначения не будет знать какие структуры данных требуют моментального доступа в заданный момент времени.
Данные мониторинга и временных рядов
Всё хорошо, пока данные находятся в памяти сервера Zabbix. Но память не бесконечна и в какой-то момент данные требуется записать (или прочитать) в базу. И если производительность базы данных серьезно отстает от скорости сбора метрик, то тут никакие даже самые продвинутые специальные алгоритмы кеширования надолго не помогут.
Третья проблема также сводится к производительности базы данных. Для её решения надо подобрать надежную стратегию удаления, которая бы не мешала другим операциям БД. По умолчанию, Zabbix удаляет исторические данные пакетами по несколько тысяч записей в час. Можно настроить более длительные периоды хаускипинга или бОльшие размеры пакетов если скорость сбора данных и место в базе это позволяют. Но при очень большом количестве метрик и/или высокой частоте их сбора правильная настройка хаускипинга может быть непростой задачей, поскольку график удаления данных может не успевать за темпами записи новых.
Обобщая, система мониторинга решает задачи производительности по трём направлениям — сбор новых данных и их запись в базу с помощью SQL запросов INSERT, доступ к данным с помощью запросов SELECT, а также удаление данных с помощью DELETE. Давайте посмотрим, как выполняется типичный SQL-запрос:
- СУБД анализирует запрос и проверяет его на синтаксические ошибки. Если запрос синтаксически корректен, то движок строит синтаксическое дерево для дальнейшей обработки.
- Планировщик запросов анализирует синтаксическое дерево и просчитывает различные способы (пути) выполнения запроса.
- Планировщик вычисляет наиболее дешёвый путь. В процессе он учитывает массу вещей — насколько велики таблицы, требуется ли сортировка результатов, есть ли применимые к запросу индексы и т.п.
- Когда оптимальный путь найден, движок выполняет запрос путем доступа к нужным блокам данных (с помощью индексов или последовательного сканирования), применяет критерии сортировки и фильтрации, собирает результат и возвращает его клиенту.
- Для запросов вставки, изменения и удаления движок также должен обновить индексы для соответствующих таблиц. Для больших таблиц эта операция может занять больше времени, чем работа с самими данными.
- Скорее всего, СУБД также обновит внутреннюю статистику использования данных для последующих вызовов планировщика запросов.
В общем, работы тут немало. Большинство СУБД дают массу настроек для оптимизации запросов, но они обычно ориентированы на некие усредненные рабочие процессы, в которых вставка и удаление записей происходит примерно с той же частотой, как и изменение.
Однако, как упоминалось выше, для систем мониторинга наиболее характерны операции добавления и периодического удаления в пакетном режиме. Изменение ранее добавленных данных почти никогда не происходит, а доступ к данным предполагает использование агрегированных функций. Кроме того, обычно значения добавляемых метрик упорядочены по времени. Такие данные обычно называются временными рядами (time series):
Временные ряды — это ряд точек данных, проиндексированных (или внесенных в перечень или граффитированных) во временном порядке.
С точки зрения базы данных временные ряды обладают следующими свойствами:
- Временные ряды могут быть расположены на диске в виде последовательности упорядоченных по времени блоков.
- Таблицы с данными временных рядов можно проиндексировать по обозначающему время столбцу.
- Большинство SQL-запросов SELECT будут использовать условия WHERE, GROUP BY или ORDER BY по обозначающему время столбцу.
- Обычно данные временных рядов имеют «срок годности» по прошествии которого их можно удалить.
Очевидно, что традиционные базы данных SQL не подходят для хранения таких данных, так как оптимизации общего назначения не учитывают эти качества. Поэтому в последние годы появилось довольно много новых, ориентированных на временные ряды СУБД, таких как, например, InfluxDB. Но у всех популярных СУБД для временных рядов есть один существенный недостаток — отсутствие поддержки SQL в полном объёме. Более того, большинство из них даже не являются CRUD (Create, Read, Update, Delete).
Может ли Zabbix каким-то образом использовать эти СУБД? Один из возможных подходов — передавать исторические данные на хранение во внешнюю, специализированную под временные ряды СУБД. Учитывая, что архитектура Zabbix поддерживает внешние бэкэнды для хранения исторических данных (например, так в Zabbix реализована поддержка Elasticsearch), на первый взгляд этот вариант выглядит весьма разумно. Но если бы мы поддерживали одну или несколько СУБД для временных рядов в качестве внешних серверов, то пользователям надо было бы считаться со следующими моментами:
- Ещё одна система, которую надо изучить, настраивать и поддерживать. Ещё одно место, чтобы следить за параметрами, местом на диске, политиками хранения данных, производительностью и т.п.
- Снижение отказоустойчивости системы для мониторинга, т.к. в цепи связанных компонент появляется новое звено.
Для некоторых пользователей преимущества специализированного выделенного хранилища под исторические данные могут перевесить неудобства, связанные с необходимостью беспокоиться еще об одной системе. Но для многих такое — излишнее усложнение. Также стоит помнить, что поскольку большинство таких специализированных решений имеют собственные API, то сложность универсального слоя для работы с БД Zabbix заметно возрастёт. А мы, в идеале, предпочитаем создавать новые функции, а не бороться с чужими API.
Возникает вопрос — есть ли способ воспользоваться преимуществами СУБД для временных рядов, но без потери гибкости и преимуществ SQL? Естественно, универсального ответа не существует, но одно конкретное решение подобралось к ответу очень близко – TimescaleDB.
Что такое TimescaleDB?
TimescaleDB (TSDB) — это расширение PostgreSQL, которое оптимизирует работу с временными рядами в обычной базе данных PostgreSQL (PG). Хотя, как упомянуто выше, на рынке нет недостатка в хорошо масштабируемых решениях для временных рядов, уникальной чертой TimescaleDB является способность хорошо работать с временными рядами не жертвуя совместимостью и преимуществами традиционных реляционных баз CRUD. На практике это означает, что мы получаем лучшее из обоих миров. База данных знает, какие таблицы должны рассматриваться как временные ряды (и применять все необходимые оптимизации), но с ними можно работать так же как и с обычными таблицами. Более того, приложения совсем не обязаны знать, что данные контролирует TSDB!
Чтобы отметить таблицу как таблицу временных рядов (в TSDB это называется гипертаблицей — hypertable), достаточно вызвать процедуру TSDB create_ hypertable(). Под капотом TSDB разделяет эту таблицу на так называемые фрагменты (английский термин — chunk) в соответствии с заданными условиями. Фрагменты можно представлять как автоматически управляемые секции таблицы. У каждого фрагмента есть соответствующий временной диапазон. Для каждого фрагмента TSDB также устанавливает специальные индексы, чтобы работа с одним диапазоном данных не влияла на доступ к другим.
Когда приложение добавляет новое значение временного ряда, расширение направляет это значение в нужный фрагмент. Если диапазон для времени нового значения не определён, то TSDB создаст новый фрагмент, присвоит ему нужный диапазон и вставит значение туда. Если приложение запрашивает данные из гипертаблицы, то перед выполнением запроса расширение проверяет, какие фрагменты связаны с этим запросом.
Но и это еще не все. TSDB дополняет надежную и проверенную временем экосистему PostgreSQL множеством изменений, связанных с производительностью и масштабируемостью. К ним относятся быстрое добавление новых записей, быстрые запросы по времени и практически бесплатные пакетные удаления.
Как отмечалось ранее, для того, чтобы контролировать размер базы данных и соблюдать политики хранения (т.е. не хранить данные дольше необходимого), хорошее решение для мониторинга должно эффективно удалять большое количество исторических данных. С помощью TSDB мы можем удалить нужную историю, просто удалив определенные фрагменты из гипертаблицы. При этом приложению не нужно отслеживать фрагменты по именам или любым другим ссылкам, TSDB удалит все нужные фрагменты по заданному временному условию.
TimescaleDB и секционирование PostgreSQL
На первый взгляд может показаться, что TSDB — это красивая обёртка вокруг стандартного секционирования таблиц PG (декларативное секционирование, как это официально называется в PG10). Действительно, для хранения исторических данных можно воспользоваться стандартным секционированием PG10. Но если присмотреться поближе, то фрагменты TSDB и секции PG10 — это далеко не тождественные понятия.
Для начала, настройка секционирования в PG требует вникнуть в детали, которыми по-хорошему должно заниматься либо само приложение либо СУБД. Во-первых, необходимо распланировать иерархию секций и решить, следует ли использовать вложенные секции (nested partitions). Во-вторых, нужно придумать схему наименования разделов и как-то переложить её в скрипты создания схемы. Скорее всего схема наименования будет включать дату и/или время и такие имена надо будет как-то автоматизировать.
Далее, нужно продумать как удалять данные с истёкшим сроком хранения. В TSDB можно просто вызвать команду drop_chunks(), которая определяет удаляемые за заданный промежуток времени фрагменты. В PG10, если нужно удалить определенный диапазон значений из стандартных секций PG, то вычислять список имён секций для этого диапазона придётся самостоятельно. Если выбранная схема секционирования предполагает вложенные секции, это ещё более усложняет удаление.
Ещё одна проблема, которую придётся решать — это, что делать с данными, которые выходят за рамки текущих временных диапазонов. Например, данные могут придти из будущего, под которое ещё не созданы секции. Или из прошлого для уже удалённых секций. По умолчанию в PG10 добавление такой записи не сработает и мы просто потеряем данные. В PG11 можно определить секцию по умолчанию для таких данных, но это лишь временно маскирует проблему, а не решает ее.
Конечно, все вышеперечисленные проблемы решаемы тем или иным способом. Можно увешать базу триггерами, cron-джобами и обильно приправить скриптами. Будет хоть и некрасиво, но работоспособно. Без сомнений, секции PG лучше, чем гигантские монолитные таблицы, но что точно не решаемо через скрипты и триггеры, так это рассчитанные на временные ряды улучшения, которых нет в PG.
Т.е. по сравнению с секциями PG гипертаблицы TSDB выгодно отличаются не только экономией нервов DB-администраторов, но и оптимизациями как доступа к данным, так и добавления новых. Например, фрагменты в TSDB — всегда одномерный массив. Это упрощает управление фрагментами и ускоряет вставки и выборки. Для добавления новых данных TSDB использует свой собственный алгоритм маршрутизации в нужный фрагмент, который, в отличии от стандартного PG, не открывает сразу все секции. При большом количестве секций разница в производительности может отличаться в разы. Технические подробности о разнице между стандартным секционированием в PG и в TSDB можно прочесть в этой статье.
Zabbix и TimescaleDB
Из всех возможных вариантов TimescaleDB выглядит наиболее безопасным выбором для Zabbix и его пользователей:
- TSDB оформлен как расширение PostgreSQL, а не как отдельная система. Поэтому он не требует дополнительного железа, виртуальных машин или каких-либо других изменений в инфраструктуре. Пользователи могут продолжать использовать выбранные ими инструменты для PostgreSQL.
- TSDB позволяет сохранить почти весь код для работы с БД в Zabbix без изменений.
- TSDB заметно улучшает быстродействие history syncer и housekeeper.
- Низкий порог входа — основные концепции TSDB просты и понятны.
- Лёгкая установка и настройка как самого расширения так и Zabbix — очень поможет пользователям систем малого и среднего размера.
Давайте посмотрим, что нужно сделать, чтобы запустить TSDB со свежеустановленным Zabbix. После установки Zabbix и запуска скриптов создания базы PostgreSQL необходимо скачать и установить TSDB на нужную платформу. Инструкции по установке см. здесь. После установки расширения необходимо включить его для базы Zabbix, а затем запустить скрипт timecaledb.sql, поставляемый вместе с Zabbix. Он расположен либо в database/postgresql/timecaledb.sql, если установка производится из исходников, либо в /usr/share/zabbix/database/timecaledb.sql.gz, если установка выполняется из пакетов. На этом всё! Теперь можно запустить сервер Zabbix и он будет работать с TSDB.
Скрипт timescaledb.sql тривиален. Все, что он делает — конвертирует обычные исторические таблицы Zabbix в гипертаблицы TSDB и изменяет настройки по умолчанию — устанавливает параметры Override item history period и Override item trend period. Сейчас (версия 4.2) под управлением TSDB работают следующие таблицы Zabbix — history, history_uint, history_str, history_log, history_text, trends и trends_uint. Этот же скрипт может быть использован для миграции этих таблиц (обратите внимание, что параметр migrate_data установлен в true). Нужно иметь в виду, что миграция данных — это очень длительный процесс и может занять несколько часов.
Перед запуском timecaledb.sql изменения также может потребовать параметр chunk_time_interval => 86400. chunk_time_interval — это промежуток, ограничивающий время значений, попадающих в этот фрагмент. Например, если задать интервал chunk_time_interval равным 3 часам, то данные за целый день будут распределены по 8 фрагментам, причем первый фрагмент №1 будет охватывать первые 3 часа (0:00-2:59), второй фрагмент №2 — вторые 3 часа (3:00-5:59) и т.д. Последний фрагмент №8 будет содержать значения со временем 21:00-23:59. 86400 секунд (1 день) — это среднее значение по умолчанию, но пользователи нагруженных систем могут захотеть его уменьшить.
Чтобы примерно оценить требования к памяти важно понимать сколько места в среднем может занимать один фрагмент. Общий принцип — у системы должно хватить памяти, чтобы расположить как минимум по одному фрагменту из каждой гипертаблицы. При этом, конечно, сумма размеров фрагментов должна не только влезать в память с запасом, но и быть меньше, чем значение параметра shared_buffers из postgresql.conf. Дополнительную информацию по данной теме можно найти в документации TimescaleDB.
Например, если у вас есть система, которая собирает, в основном, целочисленные метрики и вы решили разделить таблицу history_uint на 2-часовые фрагменты, а остальные таблицы разделить на однодневные фрагменты, то вам нужно изменить эту строку в timecaledb.sql:
SELECT create_hypertable('history_uint', 'clock', chunk_time_interval => 7200, migrate_data => true);После того, как накопилось некоторое количество исторических данных, можно проверить размеры фрагментов для таблицы history_uint, вызвав chunk_relation_size():
zabbix=> SELECT chunk_table,total_bytes FROM chunk_relation_size('history_uint');
chunk_table | total_bytes
-----------------------------------------+-------------
_timescaledb_internal._hyper_2_6_chunk | 13287424
_timescaledb_internal._hyper_2_7_chunk | 13172736
_timescaledb_internal._hyper_2_8_chunk | 13344768
_timescaledb_internal._hyper_2_9_chunk | 13434880
_timescaledb_internal._hyper_2_10_chunk | 13230080
_timescaledb_internal._hyper_2_11_chunk | 13189120Этот вызов можно повторить, чтобы найти размеры фрагментов для всех гипертаблиц. Если, например, обнаружилось, что размер фрагмента history_uint составляет 13MB, фрагментов для других таблиц истории, скажем, 20MB и для таблиц трендов 10MB, то общая потребность в памяти составляет 13 + 4 x 20 + 2 x 10 = 113MB. Надо также оставить место из shared_buffers для хранения других данных, скажем 20%. Тогда значение shared_buffers надо установить в 113MB / 0.8 = ~140MB.
Для более тонкой настройки TSDB недавно появилась утилита timescaledb-tune. Она анализирует postgresql.conf, соотносит его с конфигурацией системы (память и процессор), а затем выдает рекомендации по настройке параметров памяти, параметров для параллельной обработки, WAL. Утилита меняет postgresql.conf файл, но её можно запустить с параметром -dry-run и проверить предложенные изменения.
Подробнее остановимся на параметрах Zabbix Override item history period и Override item trend period (доступны в Administration -> General -> Housekeeping). Они необходимы, чтобы удалять исторические данные целыми фрагментами гипертаблиц TSDB, а не записями.
Дело в том, что Zabbix позволяет устанавливать период хаускипинга для каждого элемента данных (метрики) индивидуально. Однако, такая гибкость достигается за счёт сканирования списка элементов и расчета индивидуальных периодов в каждой итерации хаускипинга. Если в системе настроены индивидуальные периоды хаускипинга для отдельных элементов, то в системе, очевидно, не может быть единой точки отсечения истории для всех метрик вместе и Zabbix не сможет дать правильную команду на удаление нужных фрагментов. Таким образом, выключив Override history для метрик, у Zabbix пропадёт возможность быстро удалять историю вызывая процедуру drop_chunks() для таблиц history_*, и, соответственно, выключив Override trends пропадёт та же функция для таблиц trends_*.
Другими словами, чтобы в полной мере воспользоваться преимуществами новой системы хаускипинга, надо сделать оба варианта глобальными. В этом случае процесс хаускипинга вообще не будет считывать настройки элементов данных.
Производительность с TimescaleDB
Пора проверить, действительно ли все вышесказанное работает на практике. Наша тестовый стенд — Zabbix 4.2rc1 с PostgreSQL 10.7 и TimescaleDB 1.2.1 под Debian 9. Тестовая машина — это 10-ядерный Intel Xeon с 16 ГБ оперативной памяти и 60 ГБ дискового пространства на SSD. По нынешним меркам это очень скромная конфигурация, но наша цель — выяснить, насколько эффективен TSDB в реальной жизни. В конфигурациях с неограниченным бюджетом можно просто вставить 128-256 ГБ оперативной памяти и поместить большую часть (если не всю) БД в память.
Наша тестовая конфигурация состоит из 32 активных агентов Zabbix, передающих данные непосредственно на сервер Zabbix Server. Каждый агент обслуживает по 10000 элементов. Исторический кэш Zabbix установлен в 256MB, а shared_buffers PG — 2ГБ. Такая конфигурация обеспечивает достаточную нагрузку на базу данных, но в то же время не создает большой нагрузки на серверные процессы Zabbix. Чтобы уменьшить количество движущихся частей между источниками данных и базой, мы не использовали Zabbix Proxy.
Вот первый результат, полученный из стандартной системы PG:
Результат работы TSDB выглядит совсем иначе:
Приведённый ниже график объединяет оба результата. Работа начинается с достаточно высоких значений NVPS в 170-200K, т.к. требуется некоторое время для заполнения кэша истории, прежде чем начинается синхронизация с БД.
Когда таблица истории незаполнена, скорость записи в TSDB сравнима со скоростью записи в PG, причём даже с небольшим отрывом последнего. Как только количество записей в истории достигает 50-60 миллионов, пропускная способность PG падает до 110K NVPS, но, что более неприятно, она и далее меняется обратно пропорционально количеству накопленных в исторической таблице записей. В то же время, TSDB поддерживает стабильную скорость в 130K NVPS в течение всего теста от 0 до 300 миллионов записей.
Итого, в нашем примере разница в усреднённой производительности весьма существенна (130K против 90K без учета начального пика). Также видно, что скорость вставок в стандартном PG варьируется в широком диапазоне. Таким образом, если рабочий процесс требует хранения десятков или сотен миллионов записей в истории, но нет ресурсов для стратегий очень агрессивного кеширования, то TSDB — сильный кандидат на замену стандартного PG.
Преимущество TSDB уже очевидно для этой относительно скромной системы, но скорее всего разница станет ещё более заметной на бОльших массивах исторических данных. С другой стороны, этот тест — отнюдь не обобщение всех возможных сценариев работы с Zabbix. Естественно, существует множество влияющих на результаты факторов, таких как аппаратные конфигурации, настройки операционной системы, параметры сервера Zabbix и дополнительная нагрузка со стороны других служб, работающих в фоновом режиме. Т.е., your mileage may vary.
Заключение
TimescaleDB — очень перспективная технология. Она уже успешно эксплуатируется в серьезных производственных средах. TSDB хорошо работает с Zabbix и дает заметные преимущества по сравнению со стандартной базой данных PostgreSQL.
Есть ли у TSDB какие-нибудь недостатки или причины повременить с её использованием? С технической точки зрения никаких аргументов против мы не видим. Но следует иметь в виду, что технология всё ещё новая, с неустоявшимся циклом релизов и неясной стратегией развития функционала. В частности, каждый месяц или два выпускаются новые версии с существенными изменениями. Некоторые функции, могут быть удалены, как это, например, случилось с adaptive chunking. Отдельно, как ещё один фактор неопределённости, стоит упомянуть лицензионную политику. Она весьма запутана, поскольку существует три уровня лицензирования. Ядро TSDB сделано под лицензией Apache, некоторые функции выпущены под их собственной лицензией «Timescale License», но есть также закрытая версия Enterprise.
Если вы используете Zabbix с PostgreSQL, то причин хотя бы не попробовать TimescaleDB нет. Возможно, эта вещь вас приятно удивит :) Только имейте в виду, что поддержка TimescaleDB в Zabbix пока что является экспериментальной — на время, пока мы собираем отзывы пользователей и накапливаем опыт.
