
Привет! Я Руслан Измайлов, работаю бэкенд-разработчиком в Авито. Я курирую стажеров, которые иногда задают вопросы вроде: «Зачем писать код, который тестирует другой код» или «Почему пирамида тестирования выглядит именно так». Чтобы это объяснить, надо сначала разобраться, для чего вообще нужны тесты на бэкенде, какие они бывают и чем отличаются.

Зачем нужны тесты в коде
1) Автоматизация
Представим, что мы написали код, который должен вернуть ответ на запрос. Как ответственные разработчики, мы хотим нашу работу проверить, поэтому делаем запрос в Postman.

Выполняем запрос, получаем нужный ответ — код работает. Передаём задачу на код-ревью, получаем замечания и идем дорабатывать. Затем снова запускаем ручную проверку в Postman.
Если всё хорошо, передаем задачу на тестирование. Возможно, тестировщики вернут задачу на доработку. Доделываем ещё немного и опять проверяем c помощью Postman.
В итоге простая фича прошла несколько итераций ручного тестирования. Хорошо, если мы сохранили нужный запрос, а не писали его каждый раз заново.
Если приложить чуть больше усилий, то можно превратить ручной запрос в автоматический тест, который также пригодится коллегам.
$I->sendGet('/users/1');
$I->seeResponseCodeIs(HttpCode::OK);
$I->seeResponseIsJson();
$I->seeResponseMatchesJsonType([
'id' => 'integer',
'name' => 'string',
'email' => 'string:emai1',
'homepage' => 'string:ur1|null',
'created_at' => 'string:date',
'is_active' => 'boolean'
]);2) Чтобы находить неудачные решения в коде
Допустим, мы написали простейшую функцию:
function calculate(int $a, int $b): int {
return $a + $b;
}На первый взгляд она выглядит безупречной, мало кому придет в голову её тестировать. А что насчёт граничных значений?
function testCalculate(): void
{
$result = calculate(a: PHP_INT_MAX, b: 1);
// TypeError: Return value must be of type int,
// float returned
}Короткая проверка показывает, что функция не так идеальна. Что делать с ней дальше, зависит от многих условий. Возможно, стоит поменять тип данных на float или уточнить у продакт-менеджера, какие данные функция будет получать в реальности.
3) Чтобы не повторять старые баги
Например, вы смотрите код проекта и взгляд цепляется за странную строчку:
private ?int $amount;
public function getAmount(): int
{
if (empty($this->amount)) {
return self::DEFAULT_AMOUNT;
}
return $this->amount;
}
Что ещё за костыльная проверка? Нужно срочно заменить ее на трушную.
Костыльная проверка:
if (empty($this->amount))Трушная проверка:
if ($this->amount === null)Переписываем код, деплоим и радуемся, какие мы молодцы, ведь код теперь стал правильным. Но спустя время появляется баг. Оказывается, в функцию пришёл ноль:
$this->amount = 0;Несложно понять, что эти два условия срабатывают по-разному когда получают ноль. Остаётся только вернуть код в исходное состояние, и всё снова работает как надо.
Проходит время и на ваше место приходит ещё один такой же перфекционист, который хочет посмотреть старый код проекта. Возможно, что он тоже захочет оптимизировать эту проверку и получит такой же баг. Это реальная история: на прошлой работе мне попался такой код. Я открыл историю Git и увидел, что его несколько раз «оптимизировали» разные люди. Поэтому важно покрывать подобные кейсы тестами, чтобы после вас никто не наступал на те же грабли.
К слову, в том случае тест так и не написали.
Есть еще множество причин, почему стоит писать тесты (могут служить в роли документации, упрощают рефакторинг, улучшают архитектуру), но это выходит за рамки этой публикации.
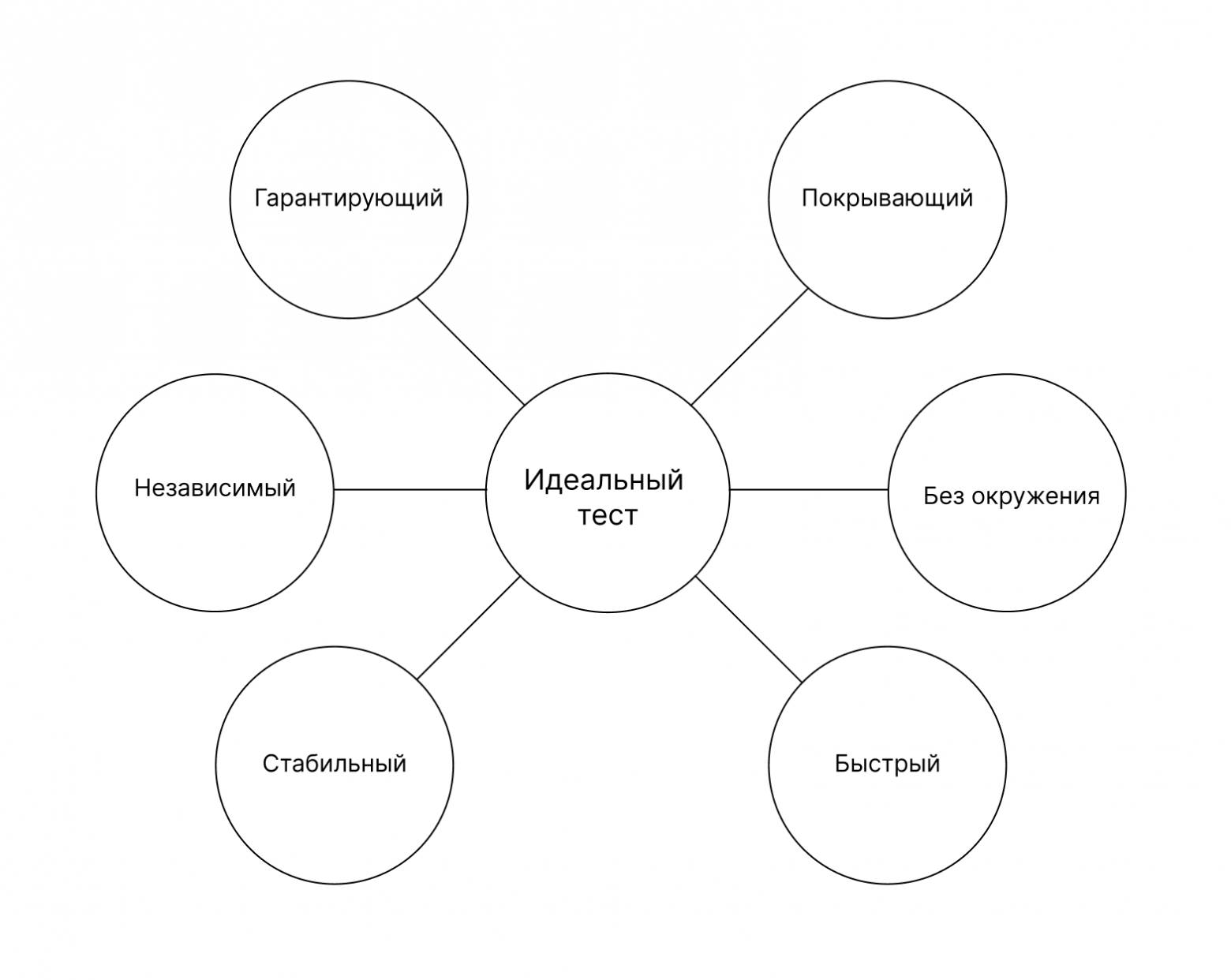
Каким должен быть идеальный тест
От теста мы ожидаем, что он гарантирует работоспособность кода и покрывает все возможные сценарии. Если тесты прошли, то мы уверены, что корректно работает абсолютно всё.
Мы не хотим заморачиваться: деплоить сервис в тестовый кластер, поднимать тестовую базу. Идеальные тесты должны работать без окружения.
При этом мы хотим, чтобы тест работал быстро. Многие сталкиваются с ситуацией, когда тесты идут по 10–15, а то и 30 минут. Особенно это критично вечером пятницы в конце спринта. Хочется побыстрее всё задеплоить, но приходится полчаса ждать, пока закончится pipeline.
Идеальный тест стабильный: либо всегда проходит, либо всегда падает. Бывает, что результат работы тестов зависит от их числа и порядка, а мы не хотим тратить время на поиск причины странного поведения.
Наконец, хочется сделать тесты независимыми, чтобы рефакторинг кода не влиял на них. Наоборот, в идеальном случае тест покажет, насколько успешно прошёл рефакторинг.
Какие бывают тесты
Для примера возьмем такой код:
class ItemController
{
private ItemSearchingService $service;
public function searchAction(Request $request): array
{
$items = $this->service->search(
$request->getSearchQuery(),
$request->getUserId()
);
return $this->formatter->format($items);
}
}
class ItemSearchingService
{
private ItemRepositoryInterface $itemRepository;
private UserRepositoryInterface $userRepository;
public function search(string $searchQuery, int $userId)
{
$user = $tnis->userRepository->get($userId);
$items = $this->itemRepository->find($searchQuery);
foreach ($items as $item) {
$delivery = $this->getDelivery($item, $user);
$dicount = $this->getDiscount($item, $user);
$totalPrice = $item—>getBasePrice()
+ $delivery
- $dicount;
$item->setTotalPrice($totalPrice);
return $items;
}
}Это endpoint для получение товаров. Пользователь вводит в строку поисковый запрос и получает список товаров с ценами.
Мы хотим проверить:
Базовый успешный сценарий: выполнили поиск — получили результат.
Поиск по разным запросам: например, на кириллице, латинице, со специальными символами и в разном регистре.
Как работает ценообразование: например, начисление скидки и добавление стоимости доставки.
Функциональные тесты
Начнём с базового сценария и напишем функциональный тест, чтобы проверить, работают ли все компоненты кода в связке. Как правило с помощью функционального теста проверют весь фукнционал в связке, в нашем случае этот функционал представлен в виде энпоинта.
Для этого теста нам нужна реальная инфраструктура, потому что без неё базовый сценарий не будет работать. Сначала нужно поднять базу данных и наполнить её, авторизовать пользователя.
public function setUp(): void
{
$this->initFixtures();
$this->loginUser();
}В самом тесте выполняем запрос и сравниваем response (ответ) с ожидаемым:
public function testSearchSucces(): void
{
$response = $this->tester->sendRequest(
'item/search',
['searchQuery' => 'чистый код']
);
$this->assertEquals(['items' => [
[
'type' => 'book',
'title' => 'Чистый код',
'рг1се' => 2650,
]
]], $response);
}Насколько этот тест идеальный?

Мы используем реальную инфраструктуру и все компоненты в связке. Поэтому если тест прошел успешно, он гарантирует, что функциональность работает как запланировано.
Тест нельзя назвать покрывающим. Мы не сможем никак стриггерить, например, ошибку базы данных. С помощью такого теста не получится протестировать все возможные кейсы.
Для того, чтобы тест работал, нам нужно окружение: задеплоить приложение, поднять контейнер с базой данных, наполнить базу тестовыми данными. По этой же причине тест нельзя назвать быстрым и стабильным. Например, если откажет один из компонентов инфраструктуры, тест не пройдет, даже если сама функциональность работает.
Этот тест можно считать независимым, потому что конкретная реализация не повлияет на его работоспособность. Если тест работает после рефакторинга, значит, изменения не повлияли на базовый успешный сценарий.
Что важно для функционального тестирования:
Писать хотя бы один тест на каждую точку входа. Проверяем успешный сценарий в бизнес-логике. Если есть время, можно добавить приверки на неуспешные сценарии.
Формировать тест-кейс на основе контракта API. Провереям только то, что отражено в респонсе.
Интеграционные тесты
Теперь нужно проверить, как работает поиск по разным запросам. При этом проверять разные варианты запросов с помощью функционального теста нежелательно, потому что они слишком медленные и нестабильные. Что же можно сделать в этом случае?
Посмотрим код сервиса ItemSearchingService:
class ItemSearchingService
{
private ItemRepositoryInterface $itemRepository;
private UserRepositoryInterface $userRepository;
public function search(string $searchQuery, int $userId)
{
$user = $tnis->userRepository->get($userId);
$items = $this->itemRepository->find($searchQuery);
foreach ($items as $item) {...}
return $items;
}
}У нас есть репозиторий, в который пробрасывается поисковый запрос. Значит, можно написать интеграционный тест. С помощью него проверяем взаимодействие бизнес-логики с инфраструктурными элементами. В нашем случае репозиторий возвращает сущность из предметной области, но при этом «сырые» данные получает из базы данных. Получается, что репозиторий — это интеграция бизнес-логики и инфраструктуры.
Для проверки снова нужна реальная база данных, поэтому инициализируем её и наполняем тестовыми данными.
public function setUp(): void
{
$this->initDatabase();
}Затем пишем тесты для разных поисковых запросов:
public function testFindShouldBeCaseInsitive(): void
{
$actualItems = $this->itemRepository->find('чИстЫй КОД');
$this->assertEquals($this->getExpectedItems(), $actualItems);
}
public function testFindWithLatinLetters(): void{...}
public function testFindWithSpecialCharacters(): void{...}Насколько этот тест идеальный?
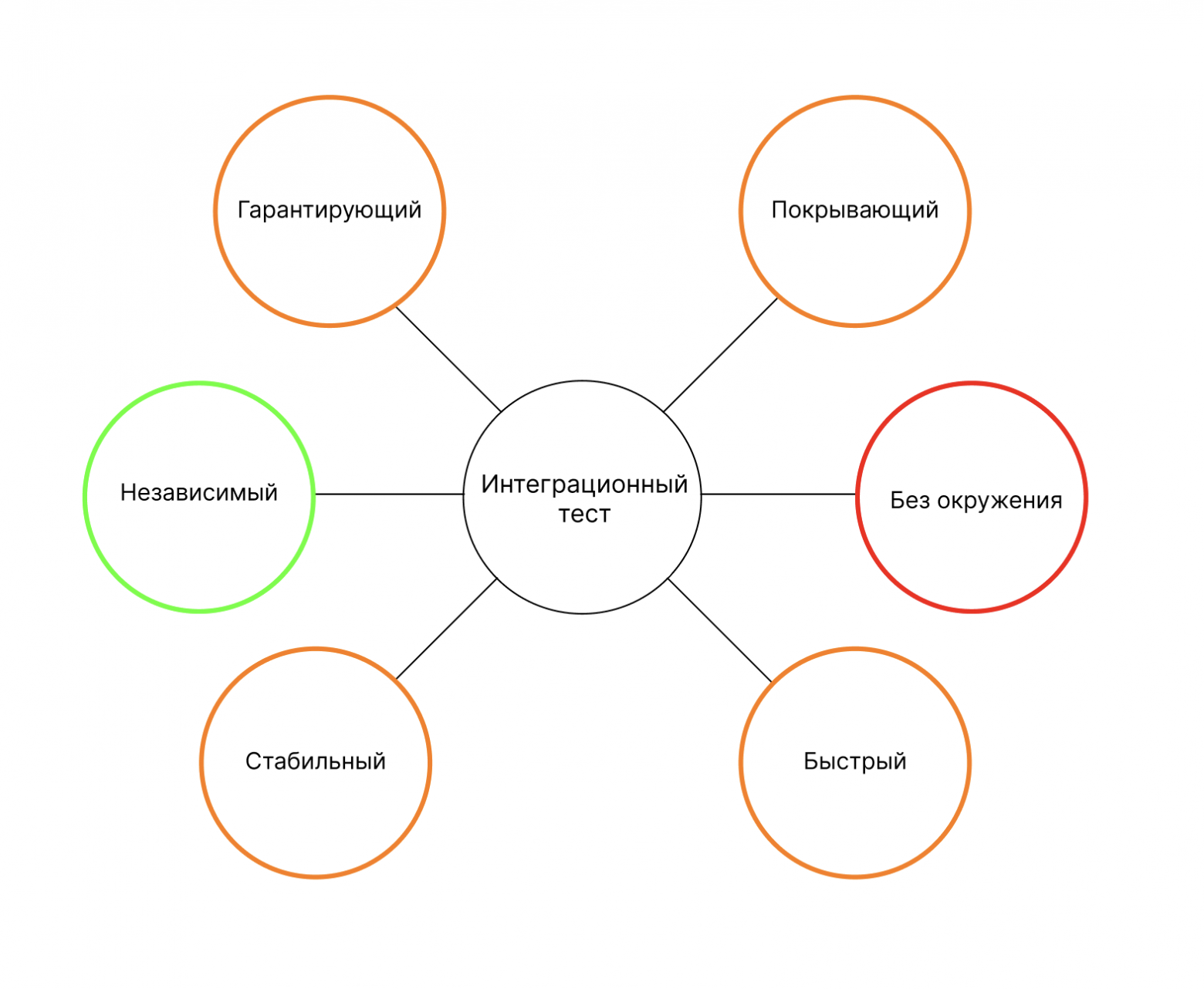
Он гарантирует только то, что инфраструктура верно взаимодействует с бизнес-логикой. То есть, репозиторий отдаёт правильный список по запросу. Но это не значит, что функциональность работает правильно — мы ведь не знаем, в каком виде данные преобразовались в конечный результат. Этот тест не такой точный, как функциональный.
Зато с ним можно покрыть больше кейсов. Мы тестируем конкретный компонент, а значит можем дешевле написать большее количество тест-кейсов. Но при этом стриггерить специфичную ошибку баз данных нам будет сложно: покрыть всё не получится.
Для интеграционного теста нужно развернуть базу данных — создать какое-то минимальное окружение.
Интеграционные тесты быстрее и стабильнее, чем функциональные. Но проблемы с ними всё равно будут. Например, частый кейс — тесты внутри базы данных. Если их запустить параллельно, то может возникнуть проблема с состоянием базы.
Интеграционные тесты независимые: их не нужно дорабатывать, пока интерфейс репозитория не изменится.
Что важно для интеграционного тестирования:
Покрывать все инфраструктурные компоненты: репозитории, http-клиенты, любые компоненты ввода-вывода.
Сами компоненты делать максимально «тонкими». К примеру репозиторий — абстракция над базой данных. Его задача — инкапсулировать работу с базой. Не стоит в него закладывать какую-то дополнительную бизнес-логику: например, считать стоимость товара в репозитории. Если соблюдать это правило, то и тесты писать будет проще, потому что акцент в интеграционных тестах именно на инфраструктуру.
Что делать с http-клиентом
Часто мы делаем http-клиенты для интеграции со сторонним API. По канонам интеграционного тестирования мы должны выполнить реальный http-запрос, чтоб проверить инфраструктуру. Но если в тестах напрямую ходить в стороннее API, то мы получим потенциально нестабильный тест, потому что API может быть недоступным.
Для решения этой проблемы можно использовать Mock‑сервер — инструмент, который эмулирует работу стороннего API. Это просто http‑сервер, который на определённые запросы возвращает заданный ответ. Например, мы в команде используем HoverFly, его конфигурация выглядит следующим образом:
“pairs”: [
{
“request”: {...},
“response”: {“status”: 200...}
},
{
“request”: {...},
“response”: {“status”: 500...}
}
],Сервер HoverFly нужно развернуть в тестовой среде. При этом тесты будут ходить в Mock-сервер. Так вы проверяете инфраструктуру и работу http-клиента, но не зависите от нестабильности стороннего API.
Unit-тесты
Нам осталось проверить только ценообразование:
foreach ($items as $item) {
$delivery = $this->getDelivery($item, $user);
$dicount = $this->getDiscount($item, $user);
$totalPrice = $item—>getBasePrice() + $delivery - $dicount;
$item->setTotalPrice($totalPrice);
}Поскольку ценообразование — это чистая бизнес-логика, у нас есть возможность протестировать эту часть без взаимодействия с инфраструктурой. Так тест будет быстрее и стабильнее. В этом случае нам не обязательно делать запросы в базу данных, чтобы получить пользователя и товары. Нам достаточно представить, что эти данные у нас уже есть — мы уже протестировали репозиторий.
Для этого нам пригодится unit-тест. Он проверяет компонент без взаимодействия с инраструктурой.
Есть заблуждение, что unit-тестом нужно проверять только конкретный класс, а все зависимости заменять на mock-заглушки. Мне такой подход не очень нравится – так тест сильно привязан к реализации. Как только она меняется, тест сразу же требует переделок. Я предпочитаю изолировать unit-тесты только от инфраструктуры, то есть мокать только инфраструктурные компоненты.
Для теста нам нужны готовые Mock. Прописываем их и создаем тестовый экземпляр сервиса:
private function createTestingInstance(): ItemSearchingService
{
$userRepositoryMock = $this->createConfiguredMock(
UserRepositoryInterface::class,
['get' => new TestUserWithPersonaDiscount()]
);
$itemRepositoryMock = $this->createConfiguredMock(
ItemRepositoryInterface::class,
['find' => new TestItemCollection()]
);
return new ItemSearchingService(
$userRepositoryMock,
$itemRepositoryMock
);
}Прописываем тест-кейсы:
public function testSearchWithDiscount(): void
{
$itemSearchingService = $this->createTestingInstance();
$actualItems = $itemSearchingService->search();
$this->assertEquals($expectedItems, $actualItems);
}
public function testSearchWithoutDiscount(): void{...}
public function testSearchWithDelivery(): void{...}Насколько этот тест идеальный?
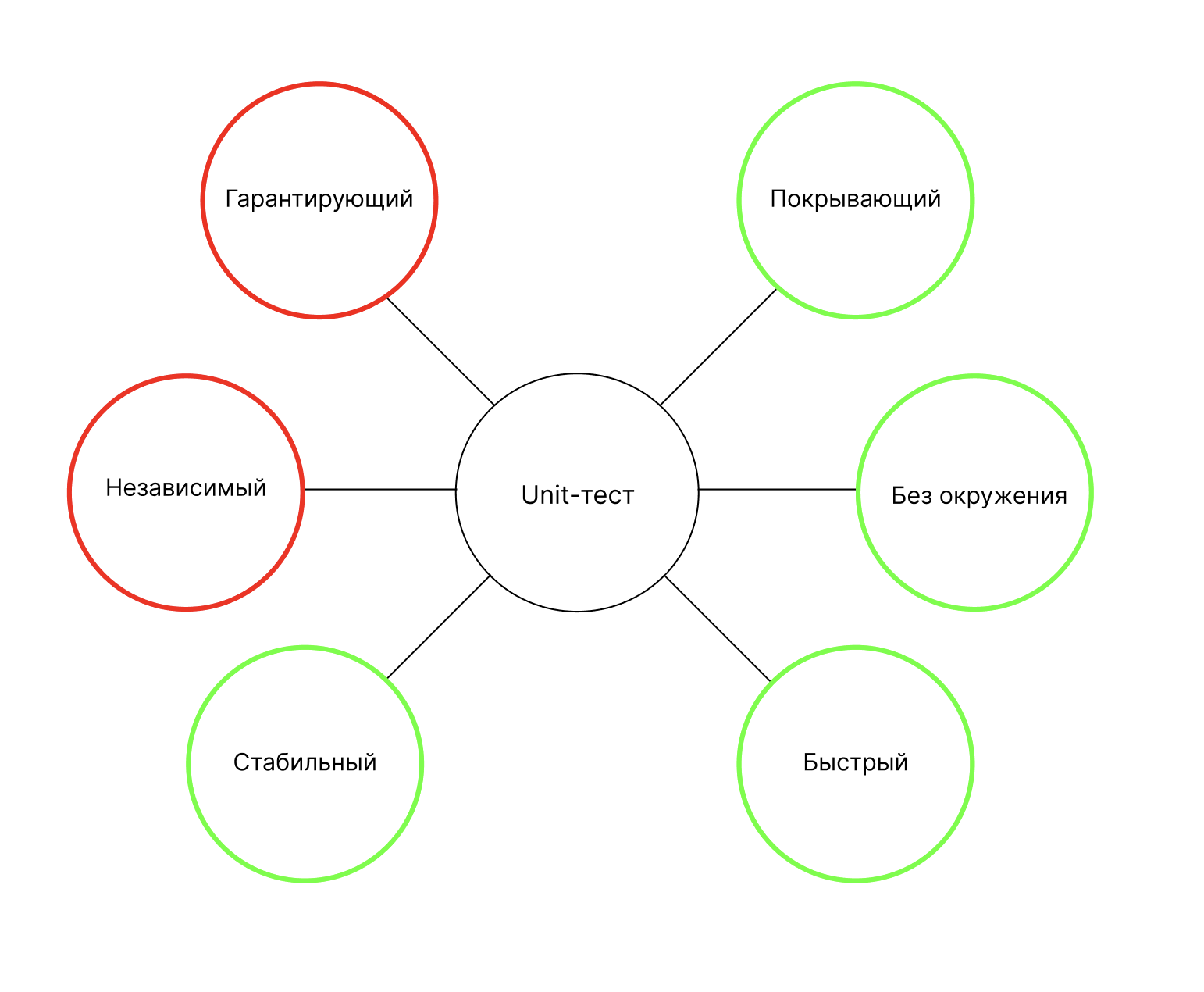
Он гарантирует только то, что функция ценообразования работает именно так, как мы ожидаем. Например, нет гарантий, что репозиторий вернёт нужный результат.
Unit-тесты — самые покрывающие из всех видов тестов, потому что мы можем проверить в них любой кейс. Например, мы можем замокать в репозитории драйвер базы данных и проверить обработку любой ошибки.
Нам не нужно окружение, достаточно файла с самим тестом и Mock-заглушками. Это самые быстрые и стабильные тесты, потому что нет никаких реальных операций ввода/вывода, ожидания ответов от инфраструктуры.
Пример простого рефакторинга: мы вынесли логику с ценообразованием в отдельный компонент.
Было:
private ItemRepositoryInterface $itemRepository;
private UserRepositoryInterface $userRepository;
public function search(string $searchQuery, int $userId): ItemCollection
{
$user = $tnis->userRepository->get($userId);
$items = $this->itemRepository->find($searchQuery);
foreach ($items as $item) {
$delivery = $this->getDelivery($item, $user);
$dicount = $this->getDiscount($item, $user);
$totalPrice = $item—>getBasePrice() + $deliveryPrice - $dicount;
$item->setTotalPrice($totalPrice);
}
return $items;
}Стало:
private ItemRepositoryInterface $itemRepository;
private UserRepositoryInterface $userRepository;
private Pricer $pricer;
public function search(string $searchQuery, int $userId): ItemCollection
{
$user = $tnis->userRepository->get($userId);
$items = $this->itemRepository->find($searchQuery);
foreach ($items as $item) {
$totalPrice = $this->pricer->calculateTotalPrice($item, $user);
$item->setTotalPrice($totalPrice);
}
return $items;
}Кажется, что ничего кардинально не поменялось: просто взяли кусочек кода в несколько строк и перенесли в отдельный класс Pricer. Но наш unit-тест не будет работать, потому что теперь нужно заново инициализировать класс.
Чтобы тест работал, нужно его переписать. Например, создать Mock для класса Pricer или передать экземпляр класса.
private function createTestingInstance(): ItemSearchingService
{
$userRepositoryMock = $this->createMock(UserRepositoryInterface::class);
$itemRepositoryMock = $this->createMock(ItemRepositoryInterface::class);
$pricerMock = $this->createMock(Pricer::class);
return new ItemSearchingService(
$userRepositoryMock,
$itemRepositoryMock,
$pricerMock
);
}Для меня зависимость unit-теста от реализации функции — важная проблема, потому что мы часто меняем структуру кода.
Попробуем сделать тест менее чувствительным к рефакторингу.
Для начала нам понадобится Stub — тестовая реализации компонента. Не путаем с Mock — Mock ожидает, что какой-то метод будет вызван определённое количество раз с определёнными аргументами. Mock сложнее переиспользовать, чем Stub, так что будем использовать именно Stub. Переиспользование нам в дальнейшем пригодится.
Например, можно написать Stub для репозиториев пользователей и товаров:
class UserRepositoryStub implements UserRepositoryInterface
{
public const
USER_WITH_DISCOUNT = 1,
USER_WITHOUT_DISCOUNT =2;
public function get(int $userId): User
{
switch ($userId) {
case self::USER_WITH_DISCOUNT:
return new UserWithDiscount();
case self::USER_WITHOUT_DISCOUNT:
return new UserWithoutDiscount();
}
throw new UserNotFountException();
}
}
class ItemRepositoryStub implements ItemRepositoryInterface
{
public const
QUERY_CLEAN_CODE = 'чистый код',
QUERY_BOOKS = 'книги',
QUERY_TABLE = 'стол';
public function find(string $query): ItemCollection
{
switch ($query) {...}
return new ItemCollection([]);
}
}Теперь настроим контейнер зависимостей следующим образом: в тестовой среде вместо реальных компонентов подставляем Stub.
if ($environment === ('test'){
return [
UserRepositoryInterface::class => UserRepositoryStub::class,
ItemRepositoryInterface::class => ItemRepositoryStub::class,
];
}
return [
UserRepositoryInterface::class => UserRepository::class,
ItemRepositoryInterface::class => ItemRepository::class,
];Переписываем unit-тест.
Было:
private function createTestingInstance()
{
$userRepositoryMock = $this->createMock(UserRepositoryInterface::class);
$itemRepositoryMock = $this->createMock(ItemRepositoryInterface::class);
return new ItemSearchingService(
$userRepositoryMock,
$itemRepositoryMock
);
}Стало:
private function createTestingInstance()
{
return $this->container->get(ItemSearchingService::class);
}Возможно, это спорное решение, потому что в unit-тесте появляется окружение — Stub, контейнер зависимостей. Но оно приносит пользу: вы можете переиспользовать один и тот же Stub для разных кейсов. При этом влияние рефакторинга на тест заметно снизится.
Что важно для unit-тестирования:
Покрывать всю бизнес-логику. Обычно в приложениях она составляет существенную часть кода, поэтому её удобно проверять быстрыми и стабильными unit-тестами.
Дополнять интеграционные тесты. Вспомните пример с базой данных. В нём можно добавить unit-тесты, которые воспроизведут разные ошибки. Для этого нужно будет замокать драйвер базы данных.
Использовать больше Stub и меньше Mock. Разница между ними в том, что Mock ожидает вызов метода. Он привязывает тест к реализации компонента, который вы тестируете. Вам нужно открыть код, проверить какой метод и сколько раз вызывается. Если Mock не получит точно такие же вызовы столько же раз — тесты не будут работать.
Unit… Integration… Зачем?
У многих может возникнуть вполне закономерный вопрос: "Зачем все так сложно? Можно просто писать как тебе удобно и не париться над тем что это за тест".
На первых порах это может показаться переусложнением, но в дальнейшем четкое разделение этих тестов может вам здорово пригодится! К примеру можно неплохо оптимизировать скорость пайплайна в CI/CD. Ведь для unit-тестов не нужно никакое окружение, мы можем их выполнить на более ранних этапах пайплайна + их можно запускать параллельно (помним, что они изолированы и стабильны). Если unit-тесты прошли успешно, тогда уже переходим к следующему шагу - поднимаем тестовое окружение и прогоняем интеграционный тесты.
Если не иметь такое разделение, то вам придется сперва деплоить приложение в тестовую среду и затем прогонять все тесты в перемешку и последовательно. При этом может упасть какой-нибудь unit-тест, для которого не было необходимсоти тратить время на развертывание тестовой среды.

Почему нужно использовать тесты всех видов
Получается, что идеального теста не существует. Если мы хотим писать хорошие тесты, то придётся их комбинировать, учитывать сильные и слабые стороны. Обойтись чем-то одним не получится.
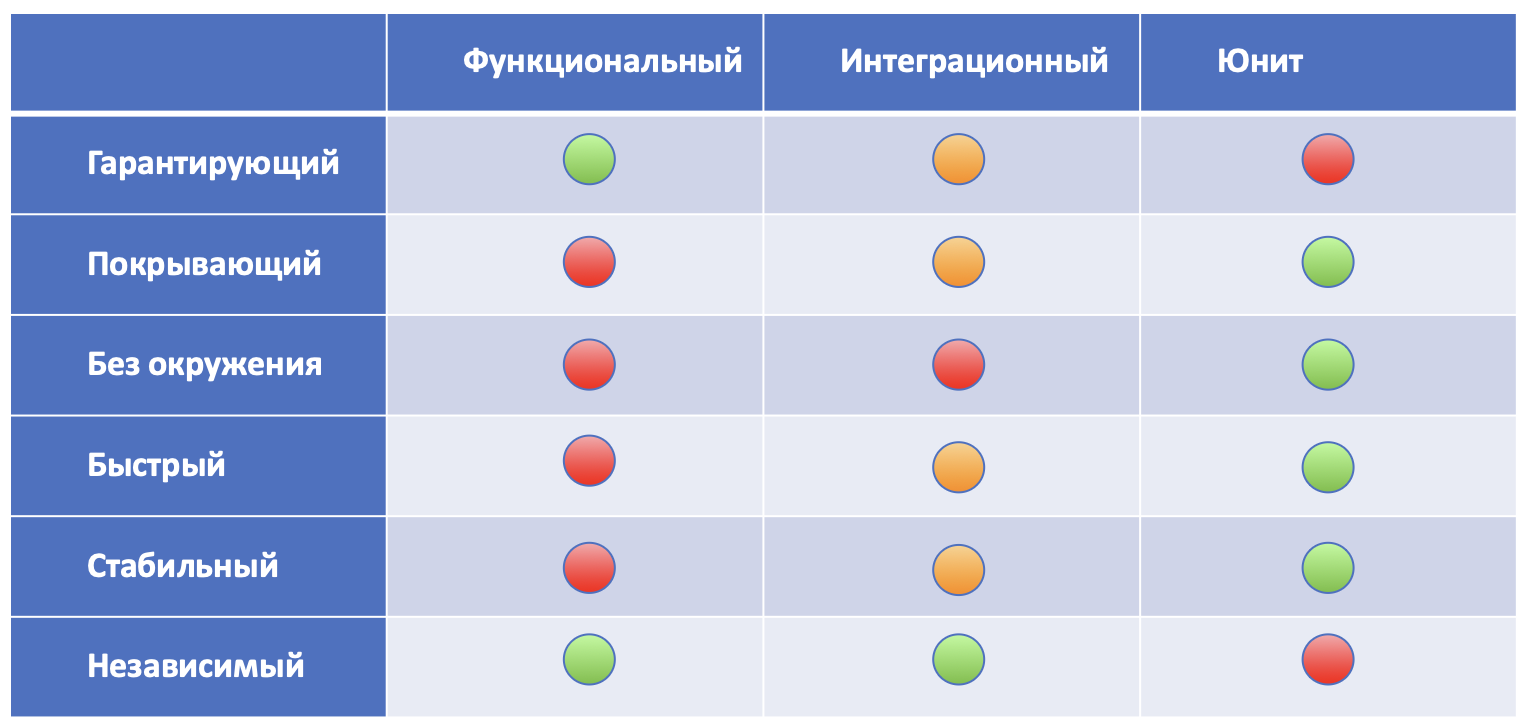
Свойства разных тестов помогают понять, почему пирамида тестирования выглядит именно так:

На верхушке пирамиды находятся самые абстрактные тесты — функциональные. В них мы делаем акцент только на том, что код работает целиком, со всеми компонентами и инфраструктурой. А ещё они нестабильные и медленные, требуют специальное окружение и не дают протестировать мелкие кейсы. Поэтому функциональных тестов должно быть мало.
Средний уровень занимают быстрые и стабильные интеграционные тесты. В них мы проверяем, что инфраструктура работает как надо, но всё ещё не можем проверить все сценарии. Таких тестов больше.
Основание пирамиды — это unit-тесты. В них мы проверяем каждый элемент бизнес-логики отдельно. Её в приложении много, кейсов получается больше всего. Поэтому unit-тестов тоже должно быть много.
Где-то далеко летает НЛО — это системные тесты, e2e, ручное тестирование, которыми обычно занимаются QA-инженеры.
Если мы хотим получить максимальное тестовое покрытие кода, то придётся использовать все виды тестов.
И последнее, что я хочу сказать о тестировании бэкенда: хороший код порождает хорошие тесты. И наоборот. Если какой-то компонент никак не получается протестировать, я советую подумать, всё ли с ним в порядке. Зачастую можно поменять интерфейс компонента таким образом, чтоб тестировать было проще.
Предыдущая статья: Эволюция алгоритма фильтрации модификаций товаров в Авито
