
Тот, кто сталкивался с локализацией приложения, наверняка знает, что это процесс постоянный с большим количеством рутинных задач. Поэтому автоматизировать их — вполне логичное желание/потребность.
В этой статье я хочу рассказать о том, что и как удалось автоматизировать нам самим, а также об альтернативных решениях с использованием сервиса Phrase.com.
Что такое Phrase.com?
Phrase.com — это система управления переводами. Она позволяет оптимизировать путь ресурсов от разработчика к переводчику и обратно. С помощью Phrase можно внедрять автоматизацию на каждом этапе работы:
- Добавление новых строк для перевода
- Перевод
- Получение результата
Как правило, для решения каждой задачи есть несколько способов. Phrase не исключение, новые фичи постепенно дополняют старые, а некоторые зависят от уровня вашей подписки на сервис. По возможности я буду указывать на альтернативные решения, остальные можно всегда посмотреть в документации.
В нашем случае большая часть работы с сервисом происходит через методы api, но иногда сервисом приходится пользоваться вручную. Обычно эта необходимость возникает при сложных кейсах, неправильном переводе и других подобных случаях.
Добавление новых строк для перевода
Проект во Phrase представляет собой набор записей в формате сервиса. Каждая запись содержит ключ, значение в дефолтной локализации и дополнительные параметры. С их помощью можно указать требования к переводу (размер, стилистика), обозначить контекст (текстовое описание, скриншоты). Также можно создать ключ с флагом plurals для поддержки строк с множественными числами.
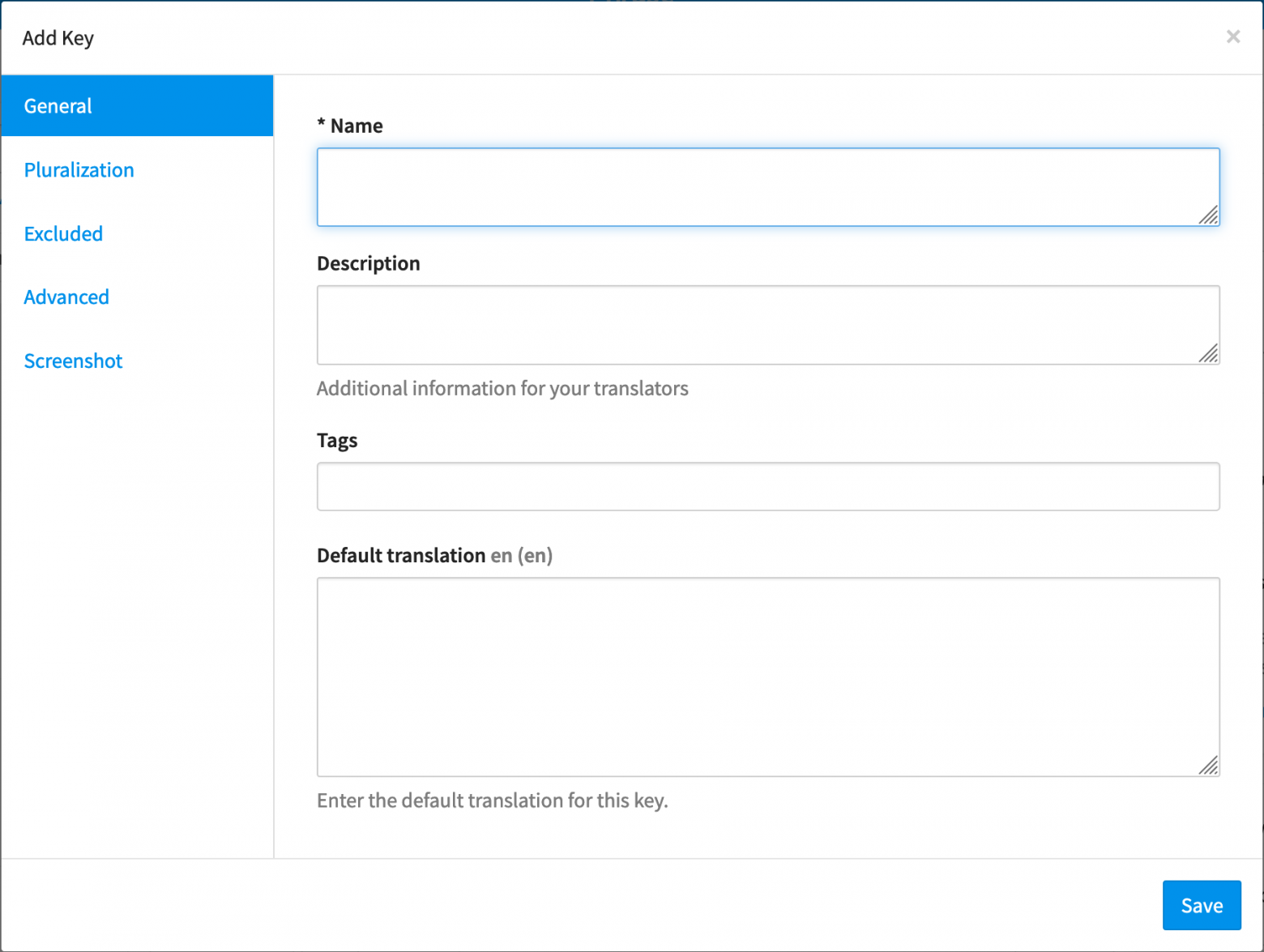
рис 1. Экран создания новой записи
iFunny поддерживает две платформы (Android, iOS) и два языка: английский (en) и бразильский португальский (pt-BR). За некоторым исключением строковые ресурсы идентичны для обеих платформ, поэтому они используют один проект вo Phrase. Это имеет как свои преимущества, так и недостатки.
Есть несколько задач, которые могут привести к изменению строк. Это может быть, например, добавление новой фичи, фикс бага или рефакторинг. В зависимости от ситуации может потребоваться добавить, изменить или удалить строку.
После добавления строки в дефолтную локализацию (значение обычно берётся из описания задачи, фигмы и т.д.) и коммита, триггерится специальный вебхук, который следит за изменениями в строковых ресурсах. После того как новые строки были найдены, они добавляются к проекту во Phrase через api.
Как видно, добавление происходит автоматически, и это несёт некоторую опасность, связанную с увеличением избыточности в строковых файлах. Допустим, работа над фичей А началась одновременно на обеих платформах, тогда, если ключи не совпадут, произойдёт дублирование. Мы боремся с этим с помощью синхронизации в специальном чате. Помимо синхронизации это помогает сообщить ответственному менеджеру о новых строках. Именно на этом этапе он может добавить пояснения и дополнительные требования для переводчиков.
С удалением и редактированием строк дело обстоит проще. Если изменения затрагивают несколько строк, их удаляют вручную. Если же нужно удалить много ключей, поможет простой скрипт с использованием [метода api](https://developers.phrase.com/api/#keys_destroy). Подобные задачи на массовую очистку — довольно редкие и являются скорее исключением из правил, гораздо проще всё сделать руками. Так как чаще всего строки удаляются вручную, об этом необходимо уведомить менеджера. Для этого разработчик пишет в специальный чат, а после того как становится понятно, что строки не нужны на обеих платформах, они удаляются.
Подобный подход имеет одно неприятное долгосрочное последствие — со временем неиспользуемые строки накапливаются. Это не только неприятно, но и увеличивает расходы на перевод. Поэтому иногда приходится делать «уборку» — проводить ревизию ключей на обеих платформах и удалять неиспользуемые. Из опыта, такие «уборки» достаточно делать раз в несколько лет. Важно следить за тем, чтобы строки точно не использовались на обеих платформах одновременно, иначе можно «выстрелить себе в ногу». Мы решили это с помощью дифа отчётов с каждой платформы. Отчёты о неиспользуемых ключах готовят разработчики, потом их мержит скрипт, а менеджер удаляет строки из сервиса.
Перевод
Phrase предоставляет несколько способов работы с переводчиками: создание отдельных заданий — job, создание нового файла локализации с ответственным переводчиком и заказ у сторонних — LSP (Language Service Provider).
Так как у нас в распоряжении есть штатные переводчики, каждый из них отвечает за свой язык. При обновлениях они получают задания на перевод от менеджера и добавляют переводы любым удобным для них способом. Мы не стали автоматизировать этот шаг, потому что дополнительная проверка на этом этапе позволяет обнаружить дублирование в ключах и лучше контролировать работу переводчиков. Разграничение переводчиков по локализациям позволяет гарантировать, что они ничего не сломают в основной локализации.
job — это задание на перевод, ближайшая аналогия — задача в трекере. К нему можно прикрепить описание, ключи и всю необходимую информацию для перевода. Для job можно указывать оунера, это специальная роль без дополнительных прав. Предполагается, что оунер будет владеть всей необходимой информацией о требованиях. Помимо этого, можно прикрепить job к задаче в Jira/Trello, что очень удобно. В своём жизненном цикле job тоже напоминает задачи из трекера: когда перевод готов, job ждёт подтверждения и только потом считается выполненным. Вариант с job использовался до формирования штата переводчиков и хорошо себя зарекомендовал.
Также Phrase можно использовать для заказа переводов у сторонних сервисов. Для этого нужно создать новый order (ордер). Заказать перевод можно у LSP — Gengo, TextMaster или других LSP-партнёров. Подробнее почитать про orders можно в документации. Так как у нас есть переводчики в штате, orders мы не используем.
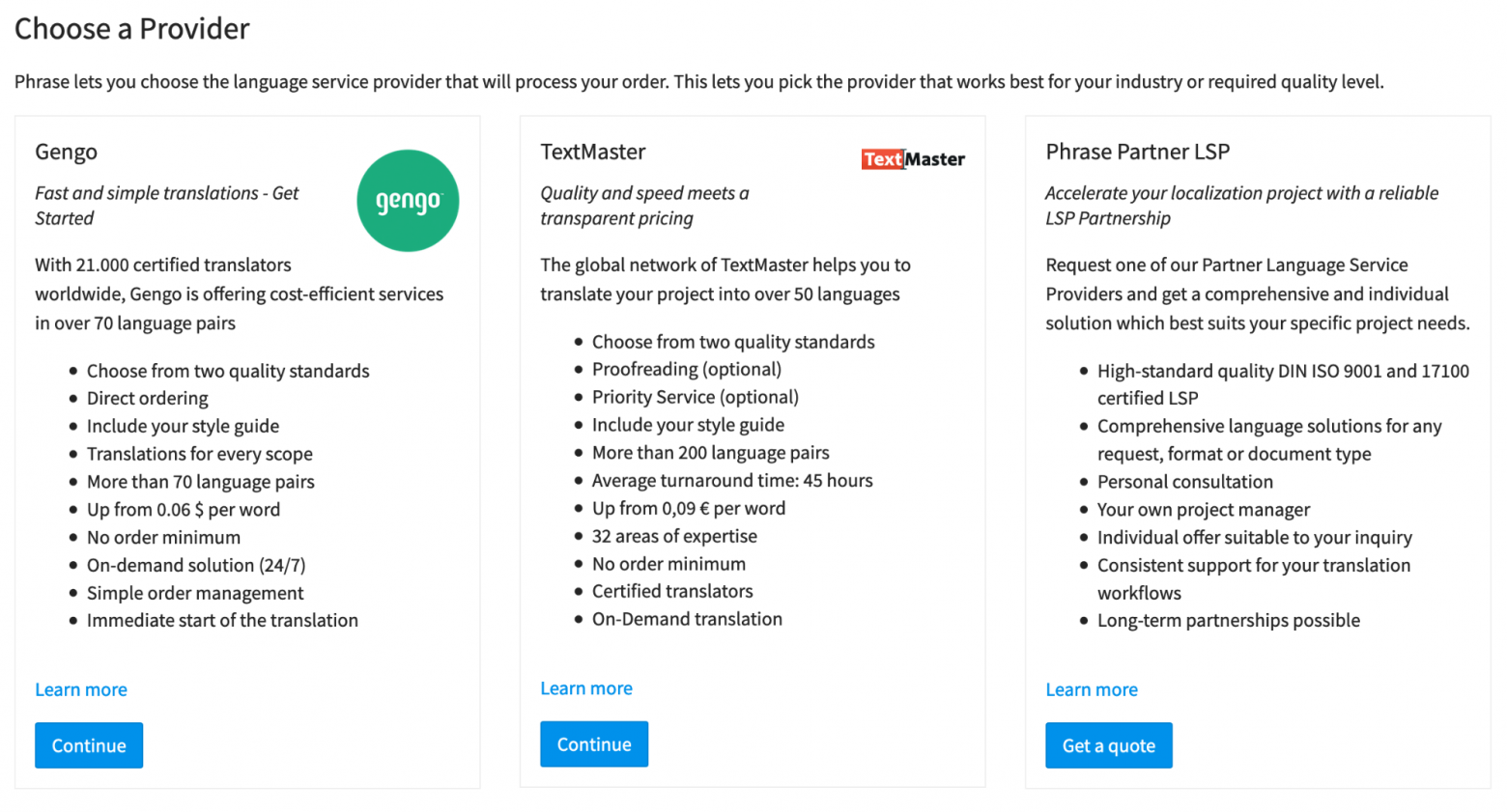
рис 2. Экран выбора LSP для перевода
Получение переводов
Итак, переводы готовы. Но как теперь доставить их в репозиторий, чтобы разработчики смогли ими воспользоваться? Это можно сделать несколькими путями. Первый и самый простой — использовать интеграцию с сервисом через Webhooks. Здесь можно найти список всех доступных ивентов. Они достаточно хорошо покрывают большинство кейсов, но мы не используем вебхуки, потому что не хотим, чтобы для автоматизации скрипты могли получать запросы от сторонних сервисов.
Поэтому актуальную версию ресурсов забирает специальный Jenkins job, вносит исправления в формат ресурсов, которые появились при конвертировании в формат Android, и пушит изменения в девелоп. Хотя есть возможность подливать изменения сразу в ветку с задачей, главная ветка предпочтительнее, потому что это спасает от конфликтов в строках при слитии и заставляет лишний раз подтянуть свежие изменения.
Как я уже писал, мы используем один проект внутри Phrase для Android и iOS, поэтому при экспорте в strings.xml возникают некоторые коллизии. Множества и служебные символы не переживают путешествия туда-обратно.
<string name="work_info_republishers_count##{few}">%s repubs</string>
<string name="work_info_republishers_count##{many}">%s repubs</string>
<string name="work_info_republishers_count##{one}">%s repub</string>
<string name="work_info_republishers_count##{other}">%s repubs</string>
<string name="work_info_republishers_count##{two}">%s repubs</string>
<string name="work_info_republishers_count##{zero}">%s repubs</string>Для внесения правок мы используем Twine. Ошибки просты и однообразны, поэтому подобный скрипт нужно написать лишь один раз.
//выбор нужного формата локализации
switch ($ext) {
case "xml":
$result_file = "$tmpAndroidDir/strings.xml";
$cmd = "/usr/local/bin/twine generate-localization-file $dataFile $tmpAndroidDir/strings.xml --lang $locale --format android";
break;
case "strings":
$result_file = "$tmpIosDir/Localizable.strings";
$cmd = "/usr/local/bin/twine generate-localization-file $dataFile $tmpIosDir/Localizable.strings --lang $locale --format apple";
break;
default:
$result_file = "$tmpIosDir/Localizable.strings";
$cmd = "/usr/local/bin/twine generate-localization-file $dataFile $tmpIosDir/Localizable.strings --lang $locale --format apple";
break;
}
//возврат спец символов к нормальному состоянию
$localeContent = $this->replaceInString(''', ''', $localeContent);
$localeContent = $this->replaceInString("&", '&', $localeContent);
$localeContent = $this->replaceInString('<', '<', $localeContent);
$localeContent = $this->replaceInString('>', '>', $localeContent);
$localeContent = $this->replaceInString('"', '"', $localeContent);
$localeContent = $this->replaceInString('<', '<', $localeContent);
$localeContent = $this->replaceInString('>', '>', $localeContent);Как правило, переводы появляются постепенно, и при каждом запуске скрипт забирает только часть из них, поэтому в истории коммитов появляется много однообразных сообщений такого типа.
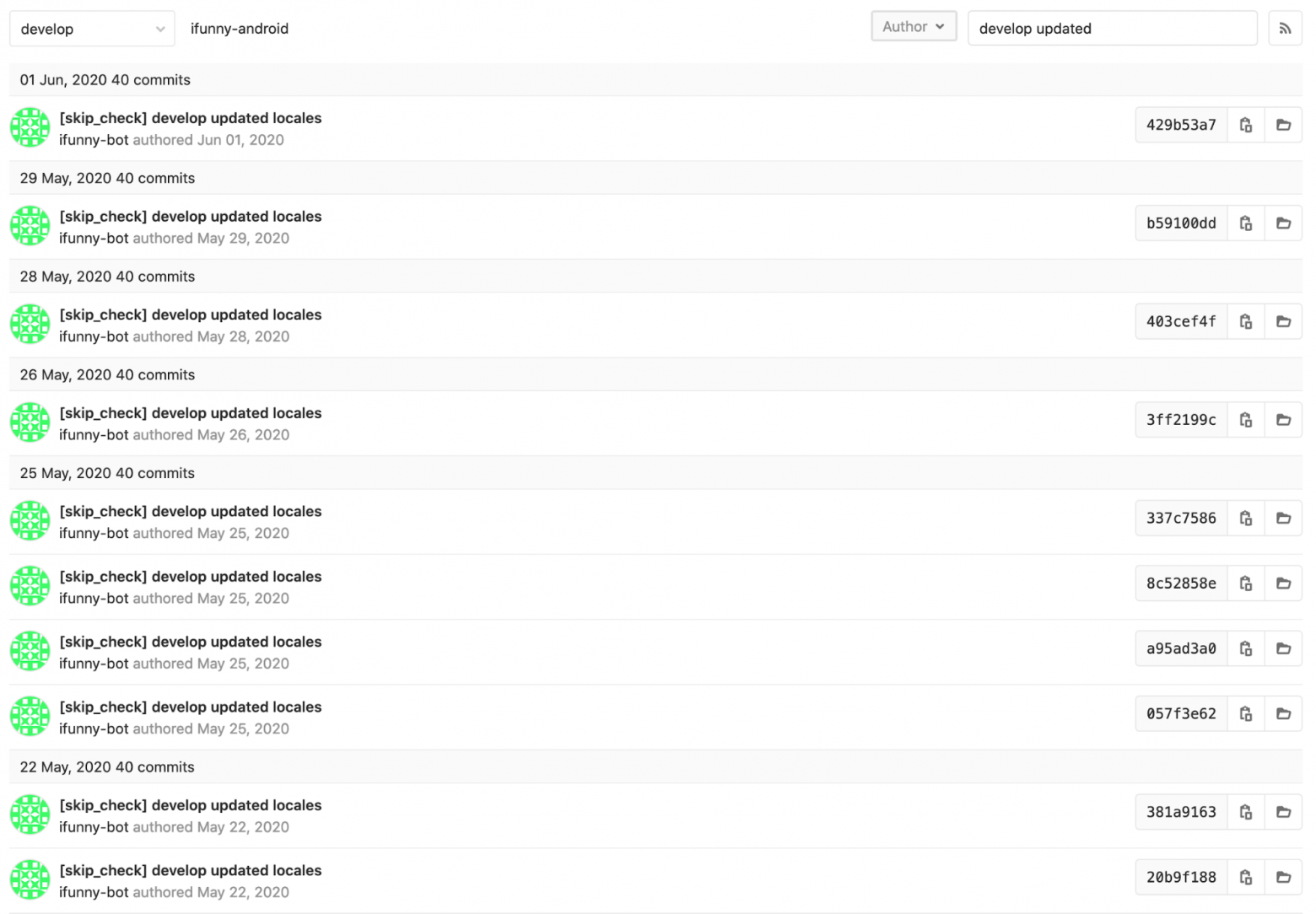
рис 3. Коммиты с обновлением локализации
С одной стороны, это засоряет историю изменений, а с другой – при минимальных проблемах в формате локализации мы узнаём об этом в тот же момент, так как девелоп падает. Дополнительную сложность в этом решении создаёт наш цикл релизов, так как после отвода релизной ветки от девелоп новые переводы приходится вручную забирать в релиз.
Заключение
Подход, который используется в FunCorp не идеален. Однако он проверен временем и доказал свою надёжность. Радует, что есть пространство для роста и будущих улучшений. Возможно, однажды получится полностью автоматизировать переводы и полностью исключить людей из этого процесса.
В этой статье затронута только небольшая часть возможностей по интеграции. Возможности, которые предоставляет Phrase, позволяют закрыть большинство сценариев использования. В документации можно найти массу примеров использования каждой фичи сервиса. Уверен, это поможет улучшить флоу ваших переводов.
