

In Mail.ru Group, we have Tarantool, a Lua-based application server and a database united. It's fast and classy, but the resources of a single server are always limited. Vertical scaling is also not the panacea. That is why Tarantool has some tools for horizontal scaling, or the vshard module [1]. It allows you to spread data across multiple servers, but you'll have to tinker with it for a while to configure it and bolt on the business logic.
Good news: we got our share of bumps (for example, [2], [3]) and created another framework, which significantly simplifies the solution to this problem.
Тarantool Cartridge is the new framework for developing complex distributed systems. It allows you to concentrate on writing business logic instead of solving infrastructure problems. Under the cut, I will tell you how this framework works and how it could help in writing distributed services.
So what exactly is the problem?
We have Tarantool and vshard — what more do we want?
First, it is a question of convenience. Vshard is configured in Lua tables. But for a distributed system of several Tarantool processes to work correctly, the configuration must be the same everywhere. Nobody would want to do it manually, so all sorts of scripts, Ansible, and deployment systems are used.
Cartridge itself manages vshard configuration based on its own distributed configuration. In fact, it is a simple YAML file, and its copy is stored on every Tarantool instance. In other words, the framework monitors its configuration so that it would be the same everywhere.
Second, it is again a question of convenience. Vshard configuration is not related to business logic development and only distracts a developer from his work. When we discuss the architecture of a project, the matter most likely concerns separate components and their interaction. It’s too early to even think about deploying a cluster for 3 data centers.
We solved these problems over and over again, and at some point, we managed to develop an approach in order to simplify working with the application throughout its entire life cycle: creation, development, testing, CI/CD, maintenance.
Cartridge introduces the concept of roles for every Tarantool process. Roles allow the developer to concentrate on writing code. All the roles available in the project can be run on the single instance of Tarantool, and this would be enough for testing.
Key features of Tarantool Cartridge:
- automated cluster orchestration;
- expanded application functionality with new roles;
- application template for development and deployment;
- built-in automatic sharding;
- integration with the Luatest framework;
- cluster management using WebUI and API;
- packaging and deployment tools.
Hello, World!
I can't wait to show you the framework itself, so let's save the story about architecture for later, and start with an easy task. Assuming that Tarantool is already installed, all we have to do is
$ tarantoolctl rocks install cartridge-cli
$ export PATH=$PWD/.rocks/bin/:$PATHAs a result, the command line utilities are installed, which allows you to create your first application from the template:
$ cartridge create --name myappAnd here is what we get:
myapp/
├── .git/
├── .gitignore
├── app/roles/custom.lua
├── deps.sh
├── init.lua
├── myapp-scm-1.rockspec
├── test
│ ├── helper
│ │ ├── integration.lua
│ │ └── unit.lua
│ ├── helper.lua
│ ├── integration/api_test.lua
│ └── unit/sample_test.lua
└── tmp/This is a git repository with a ready-to-use «Hello, World!» application. Let's try to run it after installing the dependencies (including the framework itself):
$ tarantoolctl rocks make
$ ./init.lua --http-port 8080We have launched a node of our future sharded application. If you are curious, you can at once open the web interface, which runs on localhost:8080, use a mouse to configure a one-node cluster and enjoy the result, but don't get excited too soon. The application does not know how to do anything useful just yet, so I will tell you about the deployment later, and now it's time to write some code.
Developing Applications
Imagine that we are designing a system that should receive data, save it, and create a report once a day.

So we draw a diagram with three components: gateway, storage, and scheduler. Let's continue working on the architecture. Since we use vshard as the storage, let's add vshard-router and vshard-storage to the diagram. Neither gateway nor scheduler will directly access the storage — a router is explicitly created for this task.

This diagram looks abstract because the components still do not reflect what we will create in the project. We'll have to see how this project corresponds to real Tarantool, so we group our components by the process.
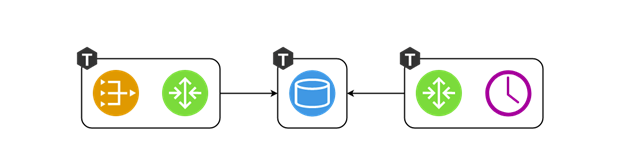
There is not much sense in keeping vshard-router and gateway on separate instances. Why would we go over the network once again, if this is already the responsibility of the router? They should run within the same process, that is, both the gateway and vshard.router.cfg should be initialized in the same process, and interact locally.
During the design phase, it was convenient to work with three components, but as a developer, I do not want to think about launching three instances of Tarantool while writing code. I need to run the tests and verify that I wrote the gateway code correctly. Or I may want to show a new feature to my coworkers. Why would I take trouble with the deployment of three instances? Thus, the concept of roles was born. A role is a regular Lua-module, and Cartridge manages its life cycle. In this example, there are four of them: gateway, router, storage, and scheduler. Another project may have more roles. All the roles can be launched in one process, and it would be enough.
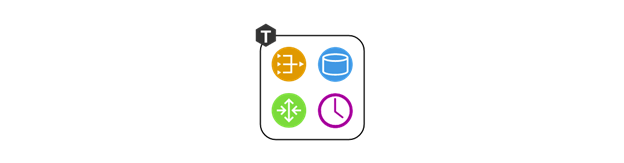
And when the matter concerns deploying to staging or production, then we assign a separate set of roles to every Tarantool process depending on the underlying hardware capabilities:

Topology Management
We should also store information about the running roles somewhere. And «somewhere» means the above-mentioned distributed configuration. The most important thing here is the cluster topology. Here you can see 3 replication groups of 5 Tarantool processes:

We do not want to lose the data, so we treat the information about the running processes with care. Cartridge monitors the configuration using a two-phase commit. As soon as we want to update the configuration, it first checks if the instances are available and ready to accept the new configuration. After that, the configuration is applied in the second phase. Thus, even if one instance is temporarily unavailable, then nothing can go wrong. The configuration simply will not be applied, and you will see an error in advance.
The topology section also has such an important parameter as the leader of each replication group. Usually, this is the instance that accepts the writes. The rest are most often read-only, although there may be exceptions. Sometimes brave developers are not afraid of conflicts and can write data to several replicas at the same time. Nevertheless, some operations should not be performed twice. That's why we have a leader.

Role Lifecycle
For a project architecture to contain abstract roles, the framework must somehow be able to manage them. Naturally, the roles are managed without restarting the Tarantool process. There are four callbacks designed for role management. Cartridge itself calls them depending on the information from the distributed configuration, thereby applying the configuration to the specific roles.
function init()
function validate_config()
function apply_config()
function stop()Each role has an
init function. It is called once: either when the role is enabled, or when Tarantool restarts. Here it is convenient, for example, to initialize box.space.create, or the scheduler can run some background fiber that would complete the task at regular intervals.The
init function alone may not be enough. Cartridge allows the roles to access the distributed configuration used for storing the topology. In the same configuration, we can declare a new section and store a part of the business configuration there. In my example, this could be a data scheme or schedule settings for the scheduler role.The cluster calls
validate_config and apply_config every time the distributed configuration changes. When a configuration is applied in a two-phase commit, the cluster verifies that each role on each server is ready to accept this new configuration and, if necessary, reports an error to the user. When everyone agrees with the configuration, apply_config is called.Roles also support a
stop method for cleaning the garbage. If we say that there is no need for the scheduler on this server, it can stop the fibers that it started using init.Roles can interact with each other. We are used to writing Lua function calls, but the process might not have the necessary role. To facilitate network access, we use an auxiliary module called rpc (remote procedure call), which is built based on the standard Tarantool net.box module. This can be useful, for example, if your gateway wants to ask the scheduler directly to perform the task right now, rather than in a day.
Another important point is ensuring fault tolerance. Cartridge uses the SWIM protocol [4] to monitor health. In short, the processes exchange «rumors» with each other via UDP, that is, every process tells its neighbors the latest news, and they respond. If there is suddenly no answer, Tarantool suspects that something is wrong, and after a while, it declares death and sends this message to everyone.
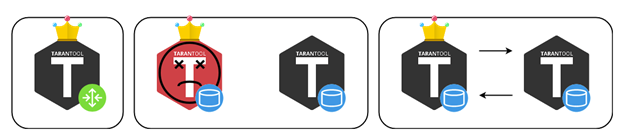
Based on this protocol, Cartridge organizes automatic failover. Each process monitors its environment, and if the leader suddenly stops responding, the replica could claim its role, and Cartridge would configure the running roles accordingly.
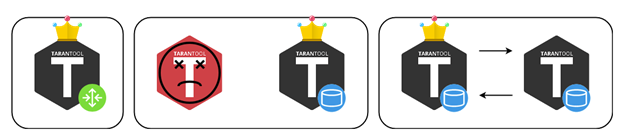
You have to be careful here because frequent switching back and forth can result in data conflicts during replication. Automatic failover most certainly shouldn't be turned on at random. You should have a clear idea of what is going on, and be sure that the replication would not crash when the leader recovers and regains its crown.
From all that has been said, the roles may seem similar to microservices. In a sense, they are but only as modules within Tarantool processes, and there are several fundamental differences. First, all project roles must live in the same code base. And all Tarantool processes should run from the same code base, so that there would be no surprises, like when we try to initialize the scheduler, but there is simply no scheduler. Also, we should not allow differences in the code versions because the system behavior is complicated to predict and debug in such a situation.
Unlike Docker, we cannot just take an «image» of a role, transfer it to another machine and run it there. Our roles are not as isolated as Docker containers. Moreover, we cannot run two identical roles on the same instance. The role is either there or it is not; in a sense, it is a singleton. And thirdly, the roles should be the same within the entire replication group because, otherwise, it would look ridiculous: the data is the same, but the behavior is different.
Deployment Tools
I promised to show you how Cartridge could help to deploy applications. To make life easier, the framework creates RPM packages:
$ cartridge pack rpm myapp # will create ./myapp-0.1.0-1.rpm
$ sudo yum install ./myapp-0.1.0-1.rpmThe installed package contains almost everything you need: both the application and the installed Lua dependencies. Tarantool also comes to the server as an RPM package dependency, and our service is ready to launch. This is all done using systemd, but first, we should do some configuration, at least specify the URI of every process. Three would be enough for our example.
$ sudo tee /etc/tarantool/conf.d/demo.yml <<CONFIG
myapp.router: {"advertise_uri": "localhost:3301", "http_port": 8080}
myapp.storage_A: {"advertise_uri": "localhost:3302", "http_enabled": False}
myapp.storage_B: {"advertise_uri": "localhost:3303", "http_enabled": False}
CONFIGThere is an interesting aspect that should be considered: instead of specifying only the binary protocol port, we specify the public address of the whole process, including hostname. We are doing this because the cluster nodes should know how to connect to each other. It would be a bad idea to use the 0.0.0.0 address as advertise_uri, since it should be an external IP address, rather than a socket bind. Nothing works without it so Cartridge simply would not let the node with the wrong advertise_uri start.
Now that the configuration is ready, we can start the processes. Since a regular systemd unit doesn’t allow starting multiple processes, the so-called instantiated units install the applications on Cartridge:
$ sudo systemctl start myapp@router
$ sudo systemctl start myapp@storage_A
$ sudo systemctl start myapp@storage_BWe've specified the HTTP port for Cartridge web interface in the configuration: 8080. Let's go over there and have a look:
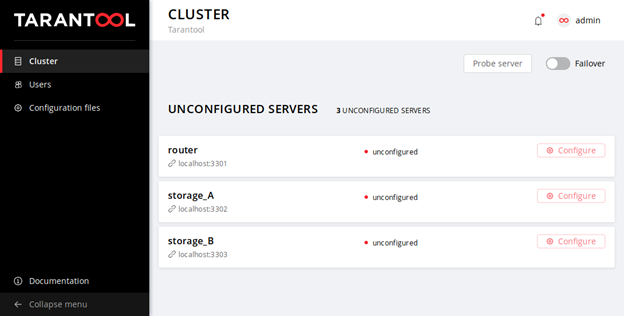
We can see that the processes are not yet configured, although they are already running. Cartridge does not yet know how the replication should be performed and cannot decide on its own, so it is waiting for our actions. We don't have much of choice: the life of a new cluster begins with the configuration of the first node. Then we add other nodes to the cluster, assign roles to them, and the deployment can be considered successfully completed.
Let's pour ourselves a drink and relax after a long working week. The application is ready to use.

Results
What about the results? Please test, use, leave feedback, and create tickets on Github.
References
[1] Tarantool » 2.2 » Reference » Rocks reference » Module vshard
[2] How We Implemented the Core of Alfa-Bank's Investment Business Based on Tarantool
[3] Next Generation Billing Architecture: Transitioning to Tarantool
[4] SWIM — Cluster Building Protocol
[5] GitHub — tarantool/cartridge-cli
[6] GitHub — tarantool/cartridge
