Каждый день мы пишем код в условиях высоких нагрузок, и нередко в таких случаях сталкиваемся с проблемами, связанными с базой данных. Мы в компании используем MySQL, поэтому я расскажу про конфигурирование соединений с этой базой данных. Пройдемся по основным моментам, на которые нужно обращать внимание при работе с MySQL средствами языка Go:
немного затронем основы клиент-серверного протокола MySQL, его базовое устройство и принципы работы;
дальше перейдем к Go части и разберем реализацию пула соединений;
будем двигаться от конфигурирования соединений к выполнению запросов, параллельно заглядывая в код драйвера.
Надеюсь каждый для себя найдет что-то полезное.
Клиент-серверный протокол MySQL
Это полудуплексный протокол, другими словами, он — синхронный. А это значит, что в любой момент времени мы либо отправляем запрос, либо его принимаем.
После отправки команды на сервер, клиент должен дождаться от него ответа, прежде чем отправить что-то еще. При этом он должен получить сообщение целиком — клиент не может остановиться на полуслове, если только не оборвется соединение.
Все передаваемые по протоколу данные упаковываются в пакеты. На стороне сервера и на стороне клиента существуют свои предопределенные типы пакетов, которыми они могут обмениваться.
Как правило, клиент отправляет запрос, упакованный в один пакет, тогда как сервер может ответить несколькими. И даже если клиенту нужна лишь часть пакетов, он все равно должен получить все.
Транспортом в этом протоколе является TCP, поверх которого клиент и сервер обмениваются этими самыми пакетами в бинарном виде.
MySQL-протокол разделяют на две основные фазы:
Фаза соединения
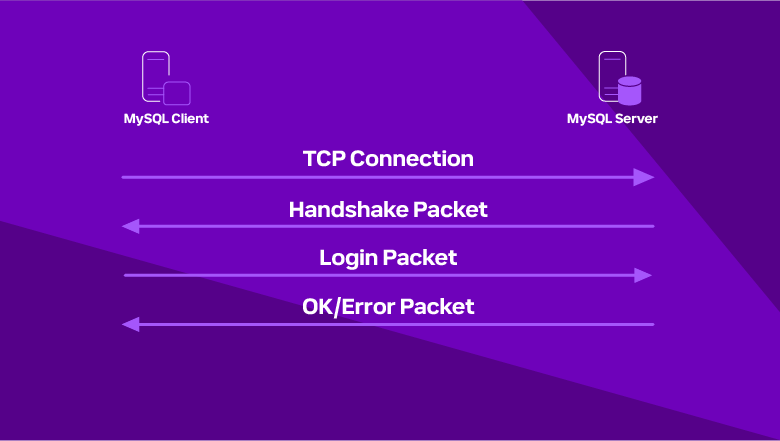
устанавливается TCP-коннект, после чего сервер MySQL отправляет клиенту пакет с хендшейком и происходит обмен параметров. Например, клиент может запросить SSL соединение, и в итоге отправить серверу ответный пакет на хендшейк.
После успешной первой фазы протокол входит в режим командной фазы.
Командная фаза

В этой фазе инициативу на себя берет клиент и отправляет серверу командные пакеты. В них входят запросы, подготовленные выражения, хранимые процедуры и команды репликации. Сервер обрабатывает запросы клиента и отвечает результатом.
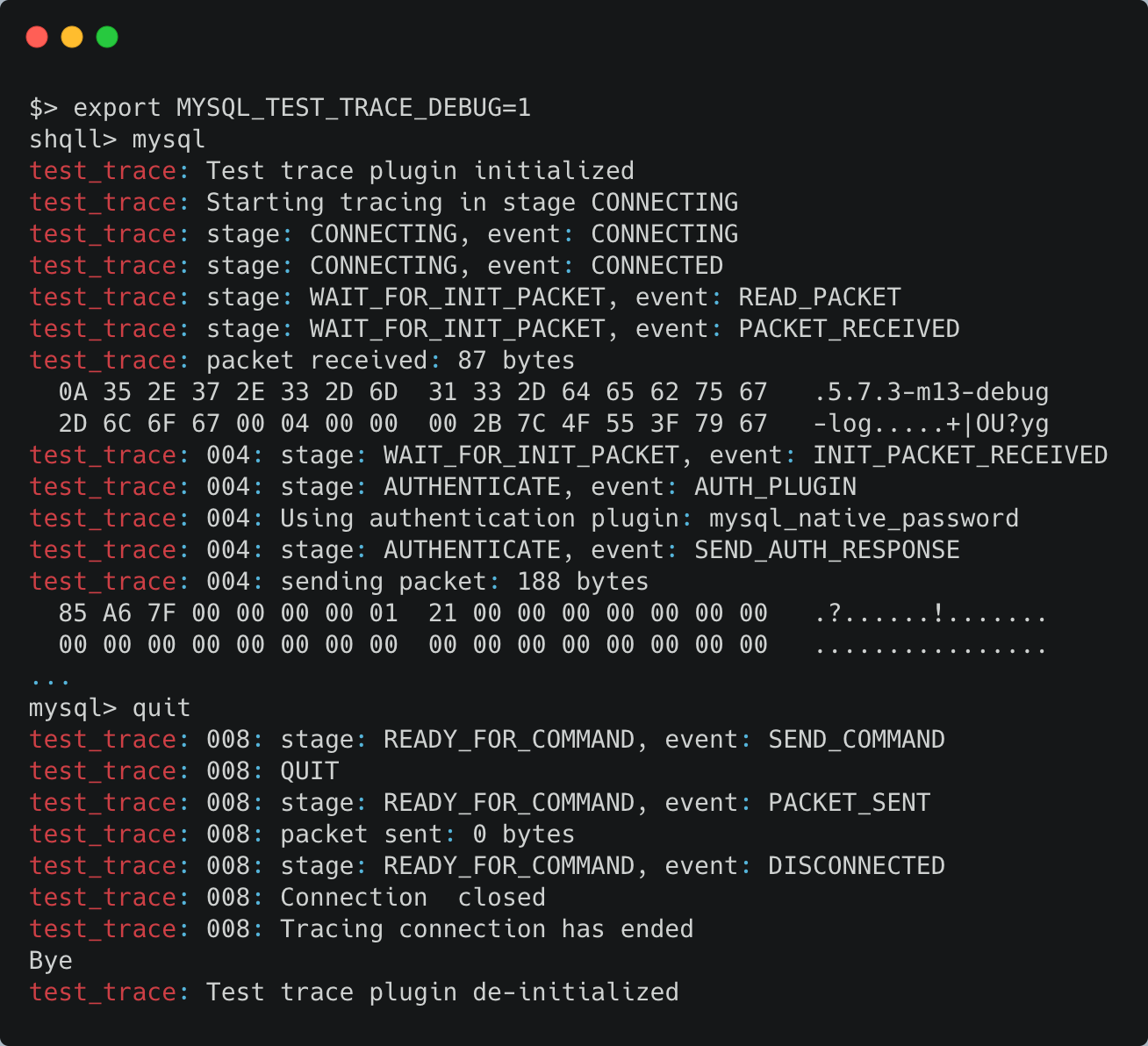
На протокол MySQL можно посмотреть. Для этого у базы данных есть плагин, который выводит трэйс. Его удобно использовать для тестирования (не продакшн решений), поэтому по умолчанию он в выключенном состоянии. Чтобы его включить, нужно собрать сервер базы данных с опцией WITH_TEST_TRACE_PLUGIN.
Вы можете наблюдать вывод трэйса в терминале после подключения к серверу. Вот как это выглядит.
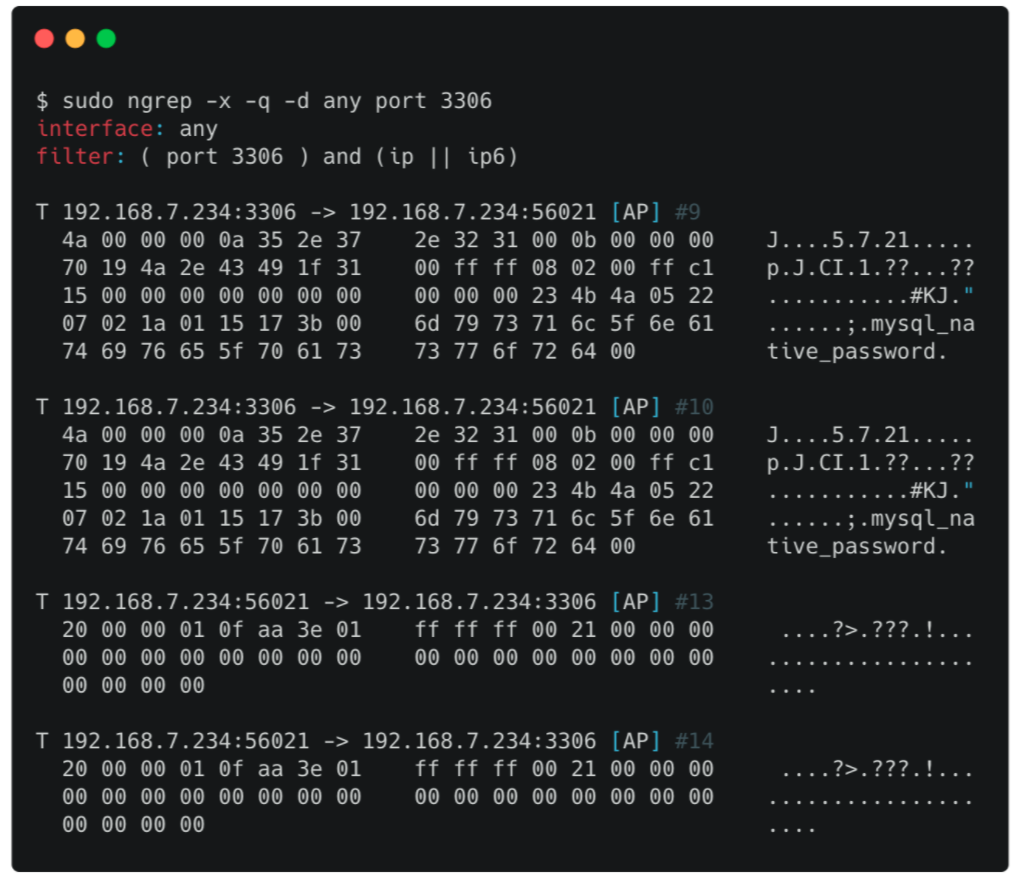
Другой способ посмотреть на передаваемые данные — воспользоваться утилитой ngrep на клиенте:
sudo ngrep -x -q -d any port 3306Вывод данных между клиентом и сервером будет выглядеть так:
Библиотеки для GO
В стандартной библиотеке языка присутствует лишь основной интерфейс — database/sql для всех sql или sql-like баз данных. Реализацию протоколов для конкретных баз данных мейнтейнеры языка оставили на совести сторонних разработчиков. Поэтому для соединения с MySQL мы будем использовать их официальный драйвер go-mysql, который сам по себе является отдельным пакетом.
В стандартном пакете sql интерфейса используется пул соединений для подключений к базам данных. Потому что , в протоколе MySQL все запросы происходят синхронно — каждый клиент может выполнить следующий запрос, только после того, как завершит предыдущий.
Но есть ли другие варианты?
Одно соединение
Самое первое, что может прийти в голову — использовать одно глобальное соединение для всего сервиса. Понятно, что в результате все новые запросы будут ждать, пока соединение не освободится. Это станет узким местом, и наш сервис может надолго зависнуть.
Соединение на каждый запрос
Можно создавать новое соединение при каждом запросе, закрывая его при завершении.

Это решает основной вопрос с ожиданием соединения, но появляются другие проблемы.
Во-первых, мы не сможем контролировать рост соединений в нашу базу. Количество наших соединений будет напрямую зависеть от количества запросов — сколько запросов придет, столько соединений откроет сервис. A для базы данных это плохо. В штатном режиме у нас может не быть проблем, но в моменты пиковых нагрузок можно дойти до максимально возможного количества соединений со стороны базы данных — и она просто перестанет отвечать. Мы получим ошибки при соединении с базой и в нашем сервисе, и во всех других, которые ее используют.
Во-вторых, мы каждый раз будем вынуждены проходить первую фазу соединения с сервером MySQL, в которой устанавливается TCP коннект, хендшейк и авторизация. Эта фаза, по сравнению с командной, более затратная по времени, и мы будем тратить дополнительное время, создавая каждый раз новый коннект.
Тогда как пул соединений в той или иной мере решает все эти проблемы.
Пул соединений
С пулом мы можем контролировать общее количество соединений, по которым сервис может ходить в базу. Тем самым, мы можем обезопасить и базу, и минимизировать число прохождений первой фазы соединения. Потому что в пуле у нас лежат, как правило, подготовленные в командной фазе соединения, с уже пройденной первой фазой коннекта.
Инициализация пула
Начнем с инициализации нашего пула и посмотрим что происходит в коде прямо из документации пакета go-sql-driver.
import (
"database/sql"
"time"
_ "github.com/go-sql-driver/mysql"
)
// ...
db, err := sql.Open("mysql", "user:password@/dbname")
if err != nil {
panic(err)
}
// See "Important settings" section.
db.SetConnMaxLifetime(time.Minute * 3)
db.SetMaxOpenConns(10)
db.SetMaxIdleConns(10)В самом начале, при импорте go-sql драйвера, происходит регистрация протокола mysql:
func init() {
sql.Register("mysql", &MySQLDriver{})
}
func Register(name string, driver driver.Driver) {
driversMu.Lock()
defer driversMu.Unlock()
if driver == nil {
panic("sql: Register driver is nil")
}
if _, dup := drivers[name]; dup {
panic("sql: Register called twice for driver " + name)
}
drivers[name] = driver
}
И дальше, при вызове метода Open, мы говорим, что хотим открыть пул, который будет использовать при соединении протокол с названием ‘mysql’ (первый параметр), реализованный в пакете go-sql-driver, с переданными конфигурациями во втором параметре. После чего вызываются методы конфигурирования нашего пула, о них поговорим чуть позже.
Представление пула
type DB struct {
waitDuration int64 // Total time waited for new connections.
connector driver.Connector
numClosed uint64
mu sync.Mutex // protects following fields
freeConn []*driverConn
connRequests map[uint64]chan connRequest
nextRequest uint64 // Next key to use in connRequests.
numOpen int // number of opened and pending open connections
openerCh chan struct{}
closed bool
dep map[finalCloser]depSet
lastPut map[*driverConn]string // stacktrace of last conn's put; debug only
maxIdleCount int // zero means defaultMaxIdleConns; negative means 0
maxOpen int // <= 0 means unlimited
maxLifetime time.Duration // maximum amount of time a connection may be reused
maxIdleTime time.Duration // maximum amount of time a connection may be idle before being closed
cleanerCh chan struct{}
waitCount int64 // Total number of connections waited for.
maxIdleClosed int64 // Total number of connections closed due to idle count.
maxIdleTimeClosed int64 // Total number of connections closed due to idle time.
maxLifetimeClosed int64 // Total number of connections closed due to max connection lifetime limit.
stop func() // stop cancels the connection opener.
}Эта структура — своего рода абстракция над нашим соединением. Вы можете видеть различные поля структуры, необходимые для конфигураций. Например, поле freeConn, которое представляет собой слайс из ссылок на соединения по нашему выбранному протоколу (собственно говоря этим полем представлен сам набор наших свободных соединений). Или, например, поле connRequests, которое служит для того, чтобы запросить новое соединение и т.д.
Вызов метода Open приводит к созданию новой структуры DB.
Создание пустого пула
Внутри него вызывается метод OpenDB, в котором инициализируется структура с начальными данными.
func OpenDB(c driver.Connector) *DB {
ctx, cancel := context.WithCancel(context.Background())
db := &DB{
connector: c,
openerCh: make(chan struct{}, connectionRequestQueueSize),
lastPut: make(map[*driverConn]string),
connRequests: make(map[uint64]chan connRequest),
stop: cancel,
}
go db.connectionOpener(ctx)
return db
}
func (db *DB) connectionOpener(ctx context.Context) {
for {
select {
case <-ctx.Done():
return
case <-db.openerCh:
db.openNewConnection(ctx)
}
}
}Как видно из приведенного кода, пул инициализируется пустой. Это значит, что на данном этапе никакого соединения к базе мы еще не установили. Поэтому, если у вас есть неверные данные в конфигурации — например, неверный логин или вы ошиблись с паролем — то при вызове метода Open вы об этом еще не узнаете.
Итак, мы создали пул, и после этого его нужно обязательно настроить.
Конфигурирование пула
Для настройки пула в основном используются следующие методы:
Остановимся на каждом из них подробнее.
Максимальное количество соединений
Методом SetMaxOpenConns() мы устанавливаем максимально возможное количество открытых соединений до БД из нашего пула. Будьте внимательны — по умолчанию это значение равно 0, что означает безлимитное количество соединений. Это может привести к ситуации, о которой мы говорили выше, когда при каждом запросе в ваш сервис будет открываться новое соединение.
Когда же создаются соединения? Обычно, после инициализации пула вызывают метод пинг, который создает соединение к базе. Тут же, кстати можно и проверить что наш конфиг верен:
err = db.Ping()Стратегии создания соединений
Перед каждым выполнением запроса, наш пул пытается получить соединение путем вызова метода conn(ctx context.Context, strategy connReuseStrategy)
В методе реализовано 2 стратегии создания подключения. AlwaysNewConn всегда создает новый коннект, а cachedOrNewConn сначала пытается взять свободное соединение из пула, если оно есть.
Если соединений в пуле нет, то метод создаст новое. Если создать новое невозможно в силу установленных нами лимитов на количество открытых соединений, то он создаст запрос на открытие нового соединения и будет ждать его исполнения.
Соединение, полученное этим методом, сразу переходит в использование и помечается как занятое — мы готовы выполнять свои запросы. После того, как мы освободим это соединение, оно попытается вернуться в пул.
Ограничение размера пула
Методом SetMaxIdleConns() мы регулируем максимальное количество свободных соединений, которые могут храниться в пуле и ждать пока их используют. По умолчанию в пул можно положить до двух соединений.
func (db *DB) query(ctx context.Context, query string, args []interface{}, strategy connReuseStrategy) (*Rows, error) {
dc, err := db.conn(ctx, strategy)
if err != nil {
return nil, err
}
return db.queryDC(ctx, nil, dc, dc.releaseConn, query, args)
}Метод query — это один из самых часто вызываемых методов для выполнения запросов, в котором соединение после использования освобождается и происходит попытка положить его обратно в пул свободных коннектов. В приведенном коде за это отвечает функция dc.releaseConn. Если в пуле уже максимальное количество соединений, то освободившееся соединение закроется.
Но соединения еще закрываются по времени. Это тоже настраивается.
Время жизни соединения
Метод SetConnMaxLifetime() отвечает за определение срока жизни соединения в пуле с момента его создания.
func (db *DB) startCleanerLocked() {
if (db.maxLifetime > 0 || db.maxIdleTime > 0) && db.numOpen > 0 && db.cleanerCh == nil {
db.cleanerCh = make(chan struct{}, 1)
go db.connectionCleaner(db.shortestIdleTimeLocked())
}
}Проверка на возраст осуществляется при каждой попытке достать коннект из пула. Также за возрастом следит connectionCleaner. Он просто закрывает просроченные коннекты, перебирая их в цикле и проверяя срок жизни.
Но это еще не все. Начиная с Go версии 1.15 для соединения можно указать срок ожидания.
Время ожидания в пуле
Метод SetConnMaxIdleTime() настраивает максимальное количество времени, в течении которого соединение может находиться в пуле в режиме ожидания. Эта настройка очень похожа на предыдущую, но существенное отличие в том, что время жизни соединения отсчитывается от даты его создания, а время ожидания в пуле считается с того момента времени, когда это соединение вернулось в пул.
После истечения этого времени соединение также закрывается.
Возврат соединения в пул
Как мы говорили, при выполнении запроса соединение берется из пула или создается, если в пуле ничего нет, после чего помечается как занятое. После выполнения запросов мы должны его освобождать.
Когда мы получаем данные по нашему запросу, нам возвращается структура с результатами Rows, в которой также находится наше соединение.
var (
id int
title string
)
// ...
rows, err := db.QueryContext(ctx, "SELECT id, title FROM articles WHERE author_id = ?", 1)
if err != nil {
log.Fatal(err)
}
for rows.Next() {
err := rows.Scan(&id, &title)
if err != nil {
log.Fatal(err)
}
log.Println(id, title)
}
// ...При вызове метода Close() происходит освобождение соединения и попытка положить его в пул или закрыть, если в пуле нет места. Поэтому писать код, как в примере выше — плохо. Обязательно вызывайте Close, как минимум, в defer.
// ...
rows, err := db.QueryContext(ctx, "SELECT id, title FROM articles WHERE author_id = ?", 1)
if err != nil {
log.Fatal(err)
}
defer rows.Close()
for rows.Next() {
err := rows.Scan(&id, &title)
if err != nil {
log.Fatal(err)
}
log.Println(id, title)
}
// ...Если не освобождать соединения, то они будут просто висеть в статусе «занятые», расходовать память и забивать количество открытых соединений. В итоге мы можем получить пустой пул, так как все соединения будут считаться занятыми, но при этом новое соединение мы создать не сможем, потому что достигли лимита максимально открытых соединений. Все это приведет к ситуации, при которой мы не можем ни создать новые соединения, ни воспользоваться имеющимися.
Но еще лучше делать таким образом:
// ...
rows, err := db.QueryContext(ctx, "SELECT id, title FROM articles WHERE author_id = ?", 1)
if err != nil {
log.Fatal(err)
}
defer rows.Close()
for rows.Next() {
err := rows.Scan(&id, &title)
if err != nil {
log.Fatal(err)
}
log.Println(id, title)
}
err = rows.Close()
if err != nil {
log.Fatal(err)
}
// ...Дело в том, что когда происходит Scan(), Go пытается конвертировать байты, которые пришли из MySQL к типам данных переданных в параметрах. И обратите внимание, что метод выполнения запроса завязан на контексте. Если в процессе выполнения Scan() произойдет обнуление контекста, то данные могут получиться поврежденными. Об этой проблеме довольно подробно написано в данной статье в разделе «The race».
Отловить эту ошибку можно только в явном вызове метода Close и проверке на ошибку. А в defer мы оставляем Close для уверенности, что если произойдут какие-то паники, то коннект вернется в пул.
Дальше я на синтетических примерах покажу, как все это влияет на реальные запросы в базу данных. Но перед этим давайте посмотрим еще на один интересный нюанс, который влияет на наши запросы.
Интерполяция параметров
Как правило, для выполнения запросов с параметрами используются плейсхолдеры, чтобы избежать возможных sql инъекций:
db.QueryRow(“SELECT * FROM client WHERE id=?”, id)Но данный способ выполнения запросов может работать по-разному, в зависимости от настроек.
В качестве конфигурирования соединения с MySQL также поддерживается параметр interpolateParams=true/false. По умолчанию его значение равно false, что равносильно непереданному параметру.
В случае false для выполнения приведенного запроса сначала на сервер БД отправляется команда для подготовки выражения (Prepared Statements), после чего будет отправлена новая команда на выполнение подготовленного выражения.
Когда у нас большой и сложный запрос с многочисленными плейсхолдерами, который будет выполняться в методе несколько раз (например мы что-то выполняем батчами), то подготовленные выражения ускоряют нашу работу. Выполнив один раз подготовку на сервере MySQL, дальше мы используем готовый запрос, не тратя каждый раз ресурсы на его парсинг.
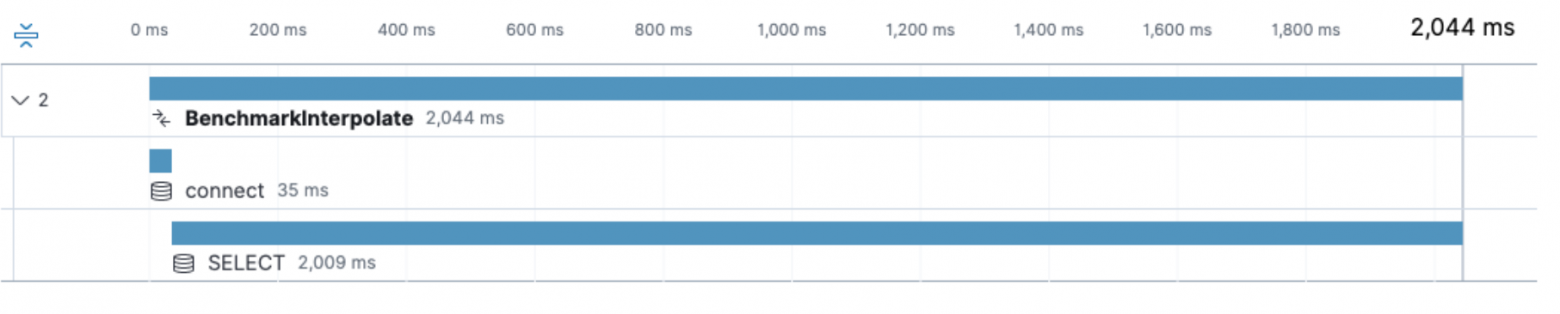
При включенной интерполяции, то есть в значении true, замена плейсхолдеров на значения выполняется в коде библиотеки go. Но если не включить интерполяцию параметров для обычных разовых запросов, мы получим по два TCP запроса к серверу MySQL вместо одного (не считая само соединение).
Запрос с параметром interpolateParams=false

тот же запрос, с interpolateParams=true
Пул на практике
Давайте посмотрим несколько примеров конфигурации пула в действии. Я буду выполнять в цикле запрос SELECT SLEEP(2); в базу данных MySQL и смотреть, что происходит с соединениями. В приведенном коде есть пауза в одну секунду после каждого запроса, чтобы соединения не успевали переиспользоваться и мы увидели более наглядную картину:
func BenchmarkPool(b *testing.B) {
ctx := context.Background()
maxLifeTime := time.Second * 0
maxOpenConns := 0
maxIdleConns := 0
db := NewPool(maxLifeTime, maxOpenConns,maxIdleConns)
tx := apm.DefaultTracer.StartTransaction("BenchmarkPool", "request")
ctx = apm.ContextWithTransaction(ctx, tx)
for i := 0; i < 5; i++ {
db.wg.Add(1)
go db.selectSleep(ctx)
time.Sleep(1 * time.Second)
}
db.wg.Wait()
tx.End()
apm.DefaultTracer.Flush(nil)
}
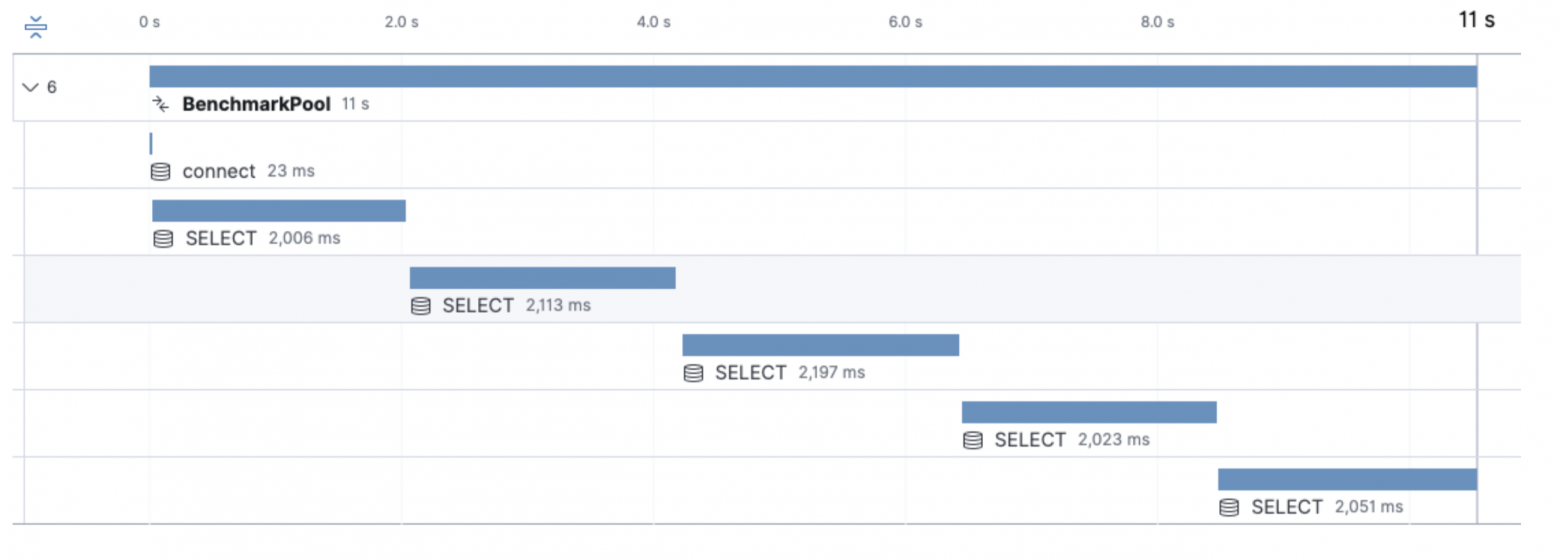
В первом кейсе посмотрим на вариант с maxOpenConns = 1 и maxIdleConns = 0:
maxLifeTime := time.Second * 10
maxOpenConns := 1
maxIdleConns := 0
db := NewPool(maxLifeTime, maxOpenConns,maxIdleConns)Это нас приведет к ситуации, о которой мы говорили выше. Когда каждый вызов нашего метода будет блокировать на себя соединение, а остальные запросы будут ждать, пока соединение не освободится. Обратите внимание на то, что потребовалось 11 секунд:
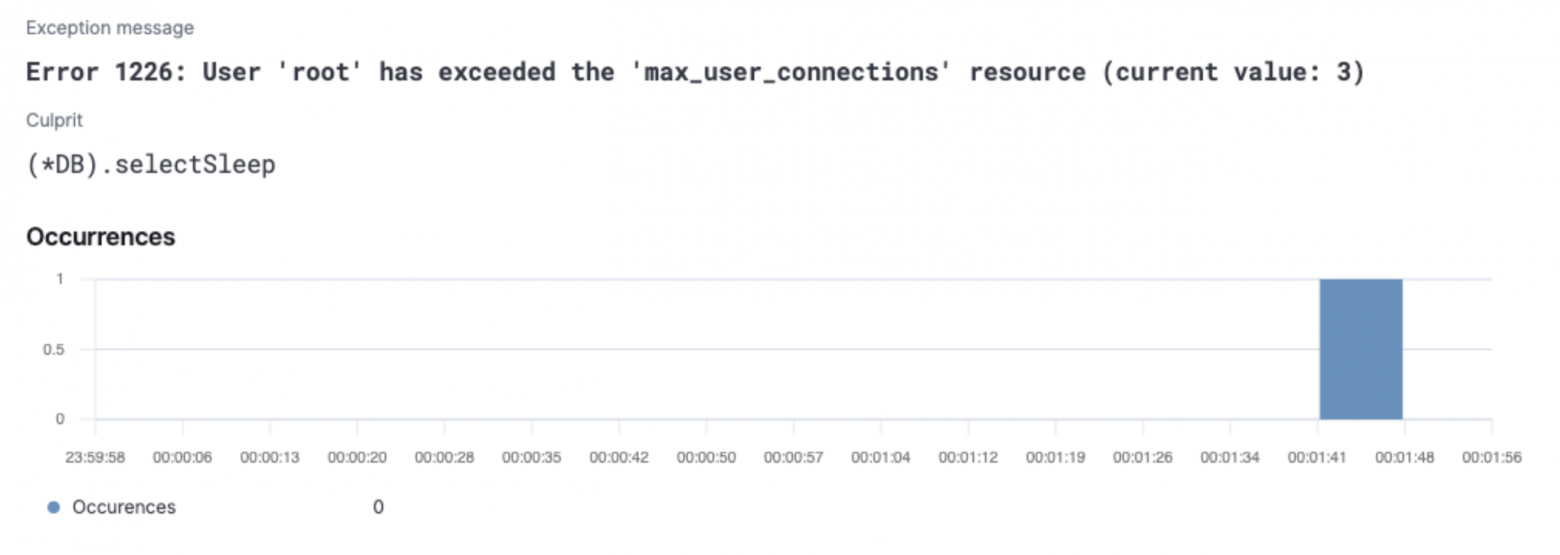
Дальше я изменю maxOpenConns := 0:
maxLifeTime := time.Second * 10
maxOpenConns := 0
maxIdleConns := 0
db := NewPool(maxLifeTime, maxOpenConns,maxIdleConns)Это приведет ко второму нашему случаю, когда каждый запрос будет создавать новое соединение к базе. В итоге мы будем получать ошибку при попытке соединения, так как на стороне базы данных установлены ограничения на количество подключений:
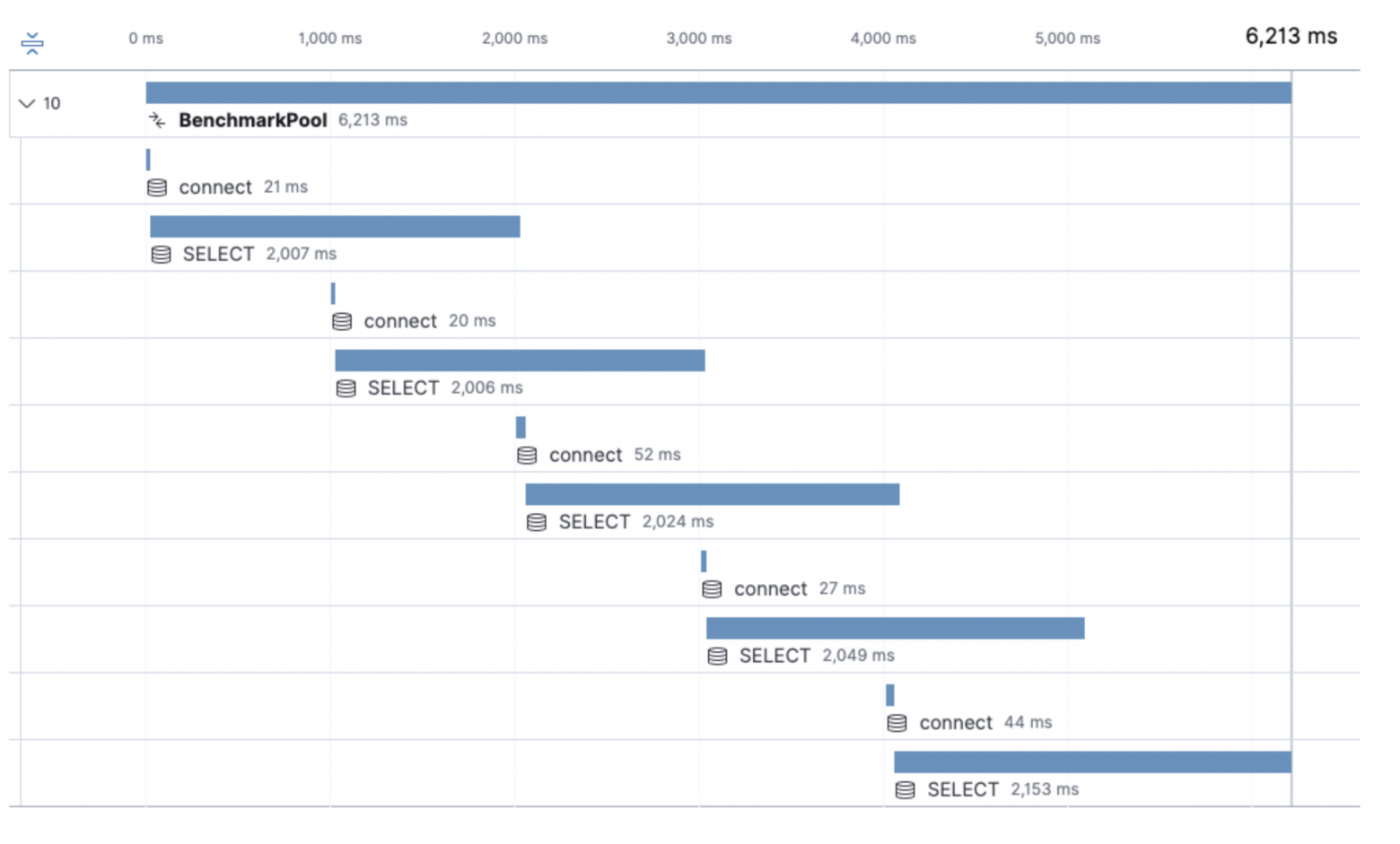
Теперь выставим maxOpenConns=3 так как у нас есть ограничения:
maxLifeTime := time.Second * 10
maxOpenConns := 3
maxIdleConns := 0
db := NewPool(maxLifeTime, maxOpenConns,maxIdleConns)В данном случае у нас уже есть возможность открыть три соединения, которые могут работать параллельно. И те же пять запросов заняли 6.2 секунды вместо 11, как в первом случае. Но при этом видим, что на каждый запрос мы заново проходим этап соединения с базой.
Сконфигурируем пул так, чтобы минимизировать соединения. Установим maxIdleConns=3:
maxLifeTime := time.Second * 10
maxOpenConns := 3
maxIdleConns := 3
db := NewPool(maxLifeTime, maxOpenConns,maxIdleConns)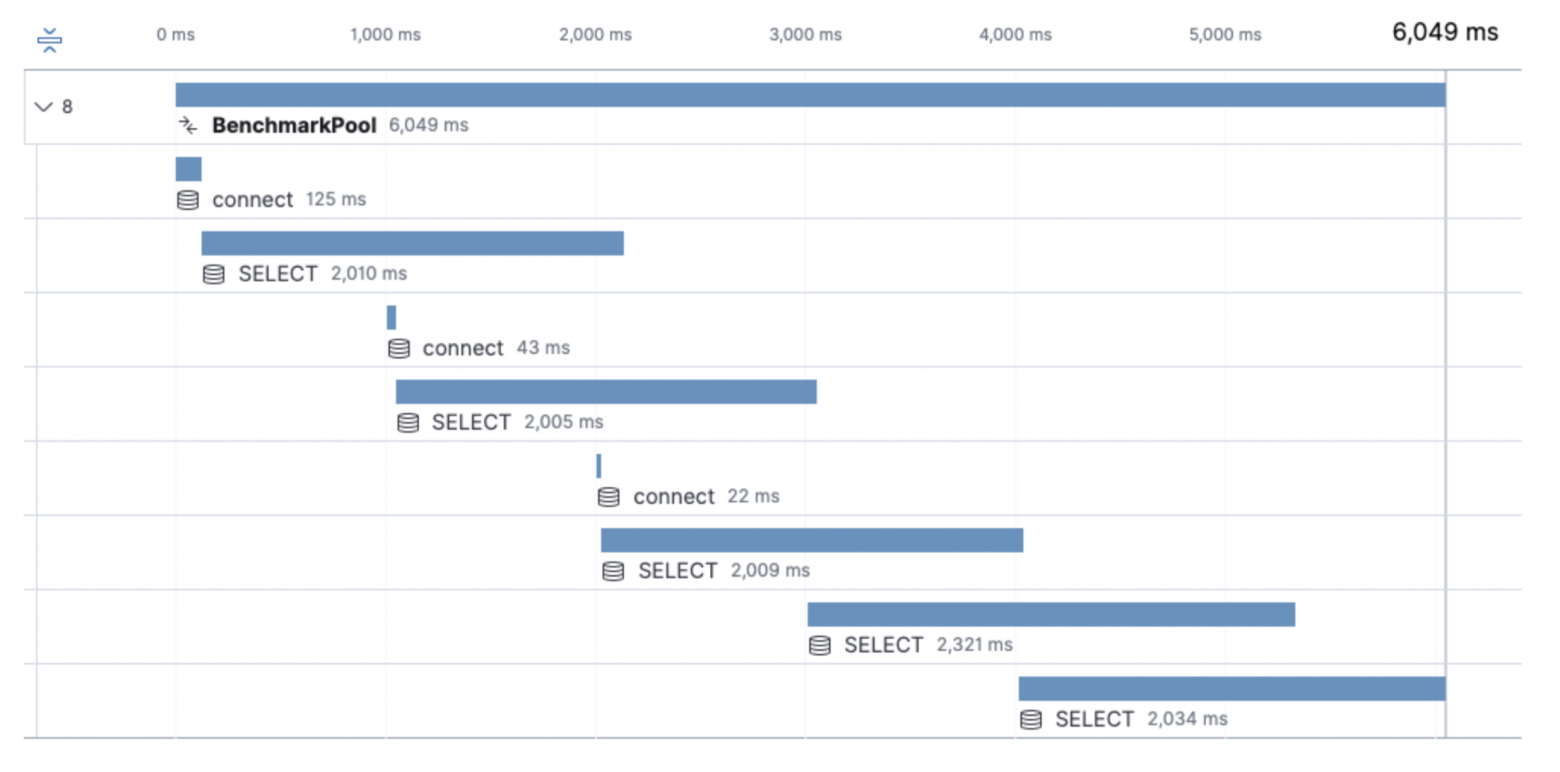
В результате мы проходим этап соединения всего 3 раза и помещаем подготовленные коннекты в пул. При последующих запросах в базу данных они берутся из пула с уже пройденной фазой авторизации и остается просто отправить команду. И в целом запросы выполняются быстрее.
Подводим итоги
Никогда не оставляйте настройки пула соединений по умолчанию, его всегда нужно настраивать под ваши нужды;
Устанавливайте
maxOpenConnsниже настроенных лимитов соединений на стороне базы данных;maxOpenConns = 0означает неограниченное количество соединений;Если на вашем сервере MySQL настроены таймауты для неактивных соединений и закрываются они на стороне базы данных, то нет необходимости в использовании
maxLifeTime, так как go драйвер сам обнаружит обрыв и пересоздаст соединение;Подбирайте значение
maxLifeTimeтак, чтобы минимизировать создание соединений при пиковых нагрузках на ваш сервис, а когда нагрузка падает - соединения не должны долго висеть без дела;Не забывайте про метод
SetConnMaxIdleTime(с go 1.15). С его помощью вы сможете сократить время ожидания соединения в пуле, удаляя его, если им никто не пользуется. Так вы сэкономите на количестве открытых соединений в базе данных и уменьшите расход памяти в сервисе.Всегда освобождайте соединение после запроса (
rows.Close()). Некоторые методы делают это сами, но ничего страшного, если вы повторите вызовClose()для надежности;Если вы используете несколько пулов для одной базы данных (например пул для чтения и пул для записи), то суммарное количество
maxOpenConnsэтих двух пулов должно быть меньше настроенных лимитов соединений на стороне базы данных;Если вы масштабируете свой сервис, то не забывайте что открытые соединения также увеличатся. Если добавляете три инстанса, то следите, чтобы сумма
maxOpenConnsвсех трех была меньше настроенных лимитов соединений на стороне базы данных;Не забывайте про различные прокси, которые со своими таймаутами и ограничениями могут стоять между вами и вашей базой данных. Учитывайте настройки посредников тоже;
Учитывайте особенности своего сервиса. Принимайте во внимание характер нагрузки и корректируйте настройки пула;
Не забывайте про мониторинги, за пулом тоже нужно следить.
Спасибо, что дочитали до конца! Если остались вопросы, пишите в комментариях, буду рад помочь.
UPD:
Дополнение по комментарию @AterCattus
Если производительности "стандартного" пакета MySQL недостаточно, то можно взять альтернативу - https://github.com/go-mysql-org/go-mysql/. Данный пакет не совсем совместим с database/sql, но позволяет пропускать через себя значительно больше запросов за счет минимизации абстракций и аллокаций.
UPD 2:
Дополнение о подготовленных выражениях по вопросу из комментариев.
Для общего понимания, определим как происходит подготовка запроса:
Клиент отправляет команду серверу на подготовку запроса с плейсхолдерами;
Сервер обрабатывает запрос и возвращает идентификатор подготовленного выражения;
Клиент выполняет запрос отправляя серверу идентификатор подготовленного выражения и параметры, с которыми должен выполниться запрос.
Для подготовки выражения мы можем воспользоваться методом (*DB).Prepare(), который после выполнения подготовки вернет нам ссылку на структуру *Stmt. Метод (*DB).Prepare() никак не учитывает настройку interpolateParams, он просто отправляет команду mysql серверу.
Чтобы выполнить запрос с подготовленным выражением нужно воспользоваться методом (*Stmt) Query(), замечу, что это другой метод, отличный от метода (*DB) Query() , и он тоже не учитывает interpolateParams . Мы явно просим библиотеку выполнить подготовку на сервере и потом отправляем вторую команду на выполнение запроса для подготовленного выражения.
Подготовленное выражение по методу (*DB).Prepare() завязывается на соединение. Если при выполнении (*Stmt) Query() соединение, с которым выполнялась подготовка, недоступно (занято или вовсе закрылось), то будет создано (взято из пула) новое соединение и снова выполнится команда подготовки выражения, и только потом уже сам запрос. Это может привести к лишним подготовкам одних и тех же запросов. Метод (*Stmt) Close() при этом закрывает выражение и выполнение запросов после этого приведет к ошибке sql: statement is closed.
