
Мы уже поговорили о некоторых блокировках на уровне объектов (в частности — о блокировках отношений), а также о блокировках на уровне строк, их связи с блокировками объектов и об очереди ожидания, не всегда честной.
Сегодня у нас сборная солянка. Начнем с взаимоблокировок (вообще-то я собирался рассказать о них еще в прошлый раз, но та статья и так получилась неприлично длинной), затем пробежимся по оставшимся блокировкам объектов, и в заключение поговорим про предикатные блокировки.
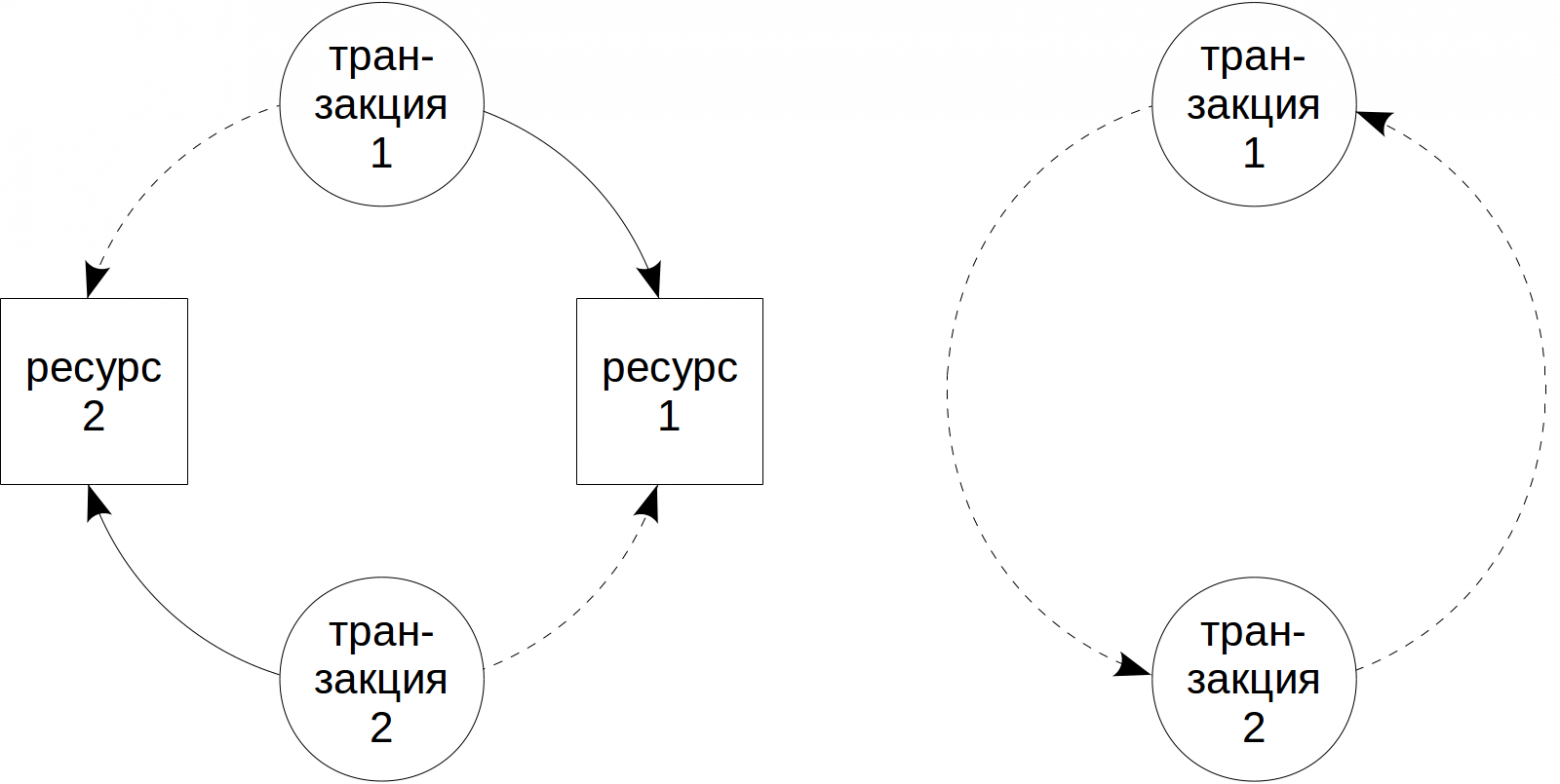
При использовании блокировок возможна ситуация взаимоблокировки (или тупика). Она возникает, когда одна транзакция пытается захватить ресурс, уже захваченные другой транзакцией, в то время как другая транзакция пытается захватить ресурс, захваченный первой. Это проиллюстрировано на левом рисунке ниже: сплошные стрелки показывают захваченные ресурсы, пунктирные — попытки захватить уже занятый ресурс.
Визуально взаимоблокировку удобно представлять, построив граф ожиданий. Для этого мы убираем конкретные ресурсы и оставляем только транзакции, отмечая, какая транзакция какую ожидает. Если в графе есть контур (из вершины можно по стрелкам добраться до нее же самой) — это взаимоблокировка.
Конечно, взаимоблокировка возможна не только для двух транзакций, но и для любого большего числа.
Если взаимоблокировка возникла, участвующие в ней транзакции не могут ничего с этим сделать — они будут ждать бесконечно. Поэтому все СУБД, и PostgreSQL тоже, автоматически отслеживают взаимоблокировки.
Однако проверка требует определенных усилий, которые не хочется прилагать всякий раз, когда запрашивается новая блокировка (все-таки взаимоблокировки достаточно редки). Поэтому когда процесс пытается захватить блокировку и не может, он встает в очередь и засыпает, но взводит таймер на значение, указанное в параметре deadlock_timeout (по умолчанию — 1 секунда). Если ресурс освобождается раньше, то и хорошо, мы сэкономили на проверке. А вот если по истечении deadlock_timeout ожидание продолжается, тогда ожидающий процесс будет разбужен и инициирует проверку.
Если проверка (которая состоит в построении графа ожиданий и поиска в нем контуров) не выявила взаимоблокировок, то процесс продолжает спать — теперь уже до победного конца.
Если же взаимоблокировка выявлена, то одна из транзакций (в большинстве случаев — та, которая инициировала проверку) принудительно обрывается. При этом освобождаются захваченные ей блокировки и остальные транзакции могут продолжать работу.
Взаимоблокировки обычно означают, что приложение спроектировано неправильно. Обнаружить такие ситуации можно двумя способами: во-первых, будут появляться сообщения в журнале сервера, и во-вторых, будет увеличиваться значение pg_stat_database.deadlocks.
Обычная причина возникновения взаимоблокировок — разный порядок блокирования строк таблиц.
Простой пример. Первая транзакция намерена перенести 100 рублей с первого счета на второй. Для этого она сначала уменьшает первый счет:
В это же время вторая транзакция намерена перенести 10 рублей со второго счета на первый. Она начинает с того, что уменьшает второй счет:
Теперь первая транзакция пытается увеличить второй счет, но обнаруживает, что строка заблокирована.
Затем вторая транзакция пытается увеличить первый счет, но тоже блокируется.
Возникает циклическое ожидание, которое никогда не завершится само по себе. Через секунду первая транзакция, не получив доступ к ресурсу, инициирует проверку взаимоблокировки и обрывается сервером.
Теперь вторая транзакция может продолжить работу.
Правильный способ выполнения таких операций — блокирование ресурсов в одном и том же порядке. Например, в данном случае можно блокировать счета в порядке возрастания их номеров.
Иногда можно получить взаимоблокировку там, где, казалось бы, ее быть никак не должно. Например, удобно и привычно воспринимать команды SQL как атомарные, но возьмем UPDATE — эта команда блокирует строки по мере их обновления. Это происходит не одномоментно. Поэтому если одна команда будет обновлять строки в одном порядке, а другая — в другом, они могут взаимозаблокироваться.
Получить такую ситуацию маловероятно, но тем не менее она может встретиться. Для воспроизведения мы создадим индекс по столбцу amount, построенный по убыванию суммы:
Чтобы успеть увидеть происходящее, напишем функцию, увеличивающую переданное значение, но мееедленно-мееедленно, целую секунду:
Еще нам понадобится расширение pgrowlocks.
Первая команда UPDATE будет обновлять всю таблицу. План выполнения очевиден — последовательный просмотр:
Поскольку версии строк на странице нашей таблицы лежат в порядке возрастания суммы (ровно так, как мы их добавляли), они и обновляться будут в том же порядке. Запускаем обновление работать.
А в это время в другом сеансе мы запретим использование последовательного сканирования:
В этом случае для следующего оператора UPDATE планировщик решает использовать сканирование индекса:
Под условие попадают вторая и третья строки, а, поскольку индекс построен по убыванию суммы, строки будут обновляться в обратном порядке.
Запускаем следующее обновление.
Быстрый взгляд в табличную страницу показывает, что первый оператор уже успел обновить первую строку (0,1), а второй — последнюю (0,3):
Проходит еще секунда. Первый оператор обновил вторую строку, а второй хотел бы это сделать, но не может.
Теперь первый оператор хотел бы обновить последнюю строку таблицы, но она уже заблокирована вторым. Вот и взаимоблокировка.
Одна из транзакций прерывается:
А другая завершает выполнение:
На этом про взаимоблокировки все, а мы приступаем к оставшимся блокировкам объектов.
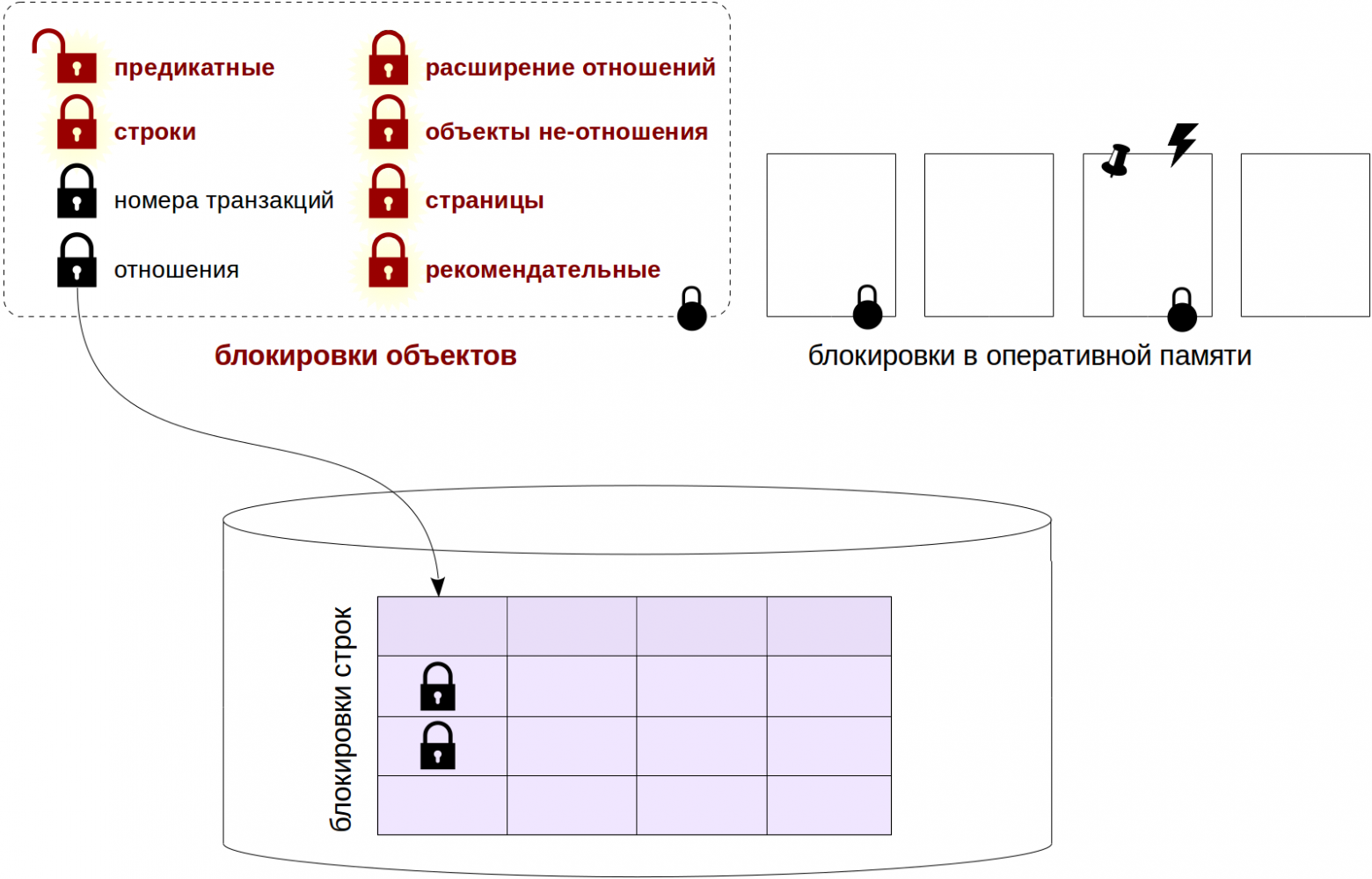
Когда требуется заблокировать ресурс, не являющийся отношением в понимании PostgreSQL, используются блокировки типа object. Таким ресурсом может быть почти все, что угодно: табличные пространства, подписки, схемы, роли, перечислимые типы данных… Грубо говоря все, что только можно найти в системном каталоге.
Посмотрим на простом примере. Начинаем транзакцию и создаем в ней таблицу:
Теперь посмотрим, какие блокировки типа object появились в pg_locks:
Чтобы разобраться, что именно тут блокируется, надо смотреть на три поля: database, classid и objid. Начнем с первой строки.
Database — это OID базы данных, к которой относится блокируемый ресурс. В нашем случае в этом столбце ноль. Это означает, что мы имеем дело с глобальным объектом, который не принадлежит к какой-либо конкретной базе.
Classid содержит OID из pg_class, который соответствует имени таблицы системного каталога, которая и определяет тип ресурса. В нашем случае — pg_authid, то есть ресурсом является роль (пользователь).
Objid содержит OID из той таблицы системного каталога, которую нам указал classid.
Таким образом, заблокирована роль student, из-под которой мы работаем.
Теперь разберемся со второй строкой. База данных указана, и это база test, к которой мы подключены.
Classid указывает на таблицу pg_namespace, которая содержит схемы.
Таким образом, заблокирована схема public.
Итак, мы увидели, что при создании объекта блокируются (в разделяемом режиме) роль-владелец и схема, в которой создается объект. Что и логично: иначе кто-нибудь мог бы удалить роль или схему, пока транзакция еще не завершена.
Когда число строк в отношении (то есть в таблице, индексе, материализованном представлении) растет, PostgreSQL может использовать для вставки свободное место в имеющихся страницах, но, очевидно, в какой-то момент приходится добавлять и новые страницы. Физически они добавляются в конец соответствующего файла. Это и понимается под расширением отношения.
Чтобы два процесса не кинулись добавлять страницы одновременно, этот процесс защищен специальной блокировкой с типом extend. Та же блокировка используется и при очистке индексов, чтобы другие процессы не могли добавлять страницы во время сканирования.
Конечно, эта блокировка снимается, не дожидаясь конца транзакции.
Блокировка с типом page на уровне страницы применяется в единственном случае (если не считать предикатных блокировок, о которых позже).
GIN-индексы позволяют ускорять поиск в составных значениях, например, слов в текстовых документах (или элементов в массивах). Такие индексы в первом приближении можно представить как обычное B-дерево, в котором хранятся не сами документы, а отдельные слова этих документов. Поэтому при добавлении нового документа индекс приходится перестраивать довольно сильно, внося в него каждое слово, входящее в документ.
Чтобы улучшить производительность, GIN-индексы обладают возможностью отложенной вставки, которая включается параметром хранения fastupdate. Новые слова сначала по-быстрому добавляются в неупорядоченный список ожидания (pending list), а спустя какое-то время все накопившееся перемещается в основную индексную структуру. Экономия происходит за счет того, что разные документы с большой вероятностью содержат повторяющиеся слова.
Чтобы исключить перемещение из списка ожидания в основной индекс одновременно несколькими процессами, на время переноса метастраница индекса блокируется в исключительном режиме. Это не мешает использованию индекса в обычном режиме.
В отличие от других блокировок (таких, как блокировки отношений), рекомендательные блокировки (advisory locks) никогда не устанавливаются автоматически, ими управляет разработчик приложения. Их удобно использовать, например, если приложению для каких-то целей требуется логика блокирования, не вписывающаяся в стандартную логику обычных блокировок.
Допустим, у нас есть условный ресурс, не соответствующий никакому объекту базы данных (который мы могли бы заблокировать командами типа SELECT FOR или LOCK TABLE). Нужно придумать для него числовой идентификатор. Если у ресурса есть уникальное имя, то простой вариант — взять от него хеш-код:
Вот таким образом мы захватываем блокировку:
Как обычно, информация о блокировках доступна в pg_locks:
Чтобы блокирование действительно работало, другие процессы также должны получать его блокировку, прежде чем обращаться к ресурсу. Соблюдение этого правила, очевидно, должно обеспечиваться приложением.
В приведенном примере блокировка действует до конца сеанса, а не транзакции, как обычно.
Ее нужно освобождать явно:
Существуют большой набор функций для работы с рекомендательными блокировками на все случаи жизни:
Набор try-функций представляет еще один способ не ждать блокировку, в дополнение к перечисленным в прошлой статье.
Термин предикатная блокировка появился давно, при первых попытках реализовать полную изоляцию на основе блокировок в ранних СУБД (уровень Serializable, хотя стандарта SQL в те времена еще не существовало). Проблема, с которой тогда столкнулись, состояла в том, что даже блокировка всех прочитанных и измененных строк не дает полной изоляции: в таблице могут появиться новые строки, попадающие под те же условия отбора, что приводит к появлению фантомов (см. статью про изоляцию).
Идея предикатных блокировок состояла в блокировке не строк, а предикатов. Если при выполнении запроса с условием a > 10 заблокировать предикат a > 10, это не даст добавить в таблицу новые строки, попадающие под условие и позволит избежать фантомов. Проблема в том, что в общем случае это вычислительно сложная задача; на практике ее можно решить только для предикатов, имеющих очень простой вид.
В PostgreSQL уровень Serializable реализован иначе, поверх существующей изоляции на основе снимков данных. Термин предикатная блокировка остался, но смысл его в корне изменился. Фактически такие «блокировки» ничего не блокируют, а используются для отслеживания зависимостей по данным между транзакциями.
Доказано, что изоляция на основе снимков допускает аномалию несогласованной записи и аномалию только читающей транзакции, но никакие другие аномалии невозможны. Чтобы понять, что мы имеем дело с одной из двух перечисленных аномалией, мы можем анализировать зависимости между транзакциями и находить в них определенные закономерности.
Нас интересуют зависимости двух видов:
WR-зависимости можно отследить, используя уже имеющиеся обычные блокировки, а вот RW-зависимости как раз приходится отслеживать дополнительно.
Еще раз повторюсь: несмотря на название, предикатные блокировки ничего не блокируют. Вместо этого при фиксации транзакции выполняется проверка и, если обнаруживается «нехорошая» последовательность зависимостей, которая может свидетельствовать об аномалии, транзакция обрывается.
Давайте посмотрим, как происходит установка предикатных блокировок. Для этого создадим таблицу с достаточно большим числом строк и индекс на ней.
Если запрос выполняется с помощью последовательного сканирования всей таблицы, то предикатная блокировка устанавливается на всю таблицу (даже если под условия фильтрации попадают не все строки).
Любые предикатные блокировки всегда захватываются в одном специальном режиме SIReadLock (Serializable Isolation Read):
А вот если запрос выполняется с помощью индексного сканирования, ситуация меняется в лучшую сторону. Если говорить о B-дереве, то достаточно установить блокировку на прочитанные табличные строки и на просмотренные листовые страницы индекса — тем самым мы блокируем не только конкретные значения, но и весь прочитанный диапазон.
Можно заметить несколько сложностей.
Во-первых, на каждую прочитанную версию строки создается отдельная блокировка, но потенциально таких версий может быть очень много. Общее число предикатных блокировок в системе ограничено произведением значений параметров max_pred_locks_per_transaction × max_connections (значения по умолчанию — 64 и 100 соответственно). Память под такие блокировки отводится при запуске сервера; попытка превысить это число будет приводить к ошибкам.
Поэтому для предикатных блокировок (и только для них!) используется повышение уровня. До версии PostgreSQL 10 действовали жестко зашитые в код ограничения, а начиная с нее повышением уровня можно управлять параметрами. Если число блокировок версий строк, относящихся к одной странице, превышает max_pred_locks_per_page, такие блокировки заменяются на одну блокировку уровня страницы. Вот пример:
Вместо трех блокировок типа tuple видим одну типа page:
Аналогично, если число блокировок страниц, относящихся к одному отношению, превышает max_pred_locks_per_relation, такие блокировки заменяются на одну блокировку уровня отношения.
Других уровней не бывает: предикатные блокировки захватываются только для отношений, страниц или версий строк, и всегда с режимом SIReadLock.
Конечно, повышение уровня блокировок неизбежно приводит к тому, что большее число транзакций будет ложно завершаться ошибкой сериализации и в итоге пропускная способность системы будет снижаться. Здесь нужно искать баланс между расходом оперативной памяти и производительностью.
Вторая сложность состоит в том, что при различных операциях с индексом (например, из-за расщепления индексных страниц при вставке новых строк) число листовых страниц, покрывающих прочитанный диапазон, может измениться. Но реализация это учитывает:
К слову, предикатные блокировки не всегда снимаются сразу по завершению транзакции, ведь они нужны, чтобы отслеживать зависимости между несколькими транзакциями. Но в любом случае управление ими происходит автоматически.
Далеко не все типы индексов в PostgreSQL поддерживают предикатные блокировки. Раньше этим могли похвастать только B-деревья, но в версии PostgreSQL 11 ситуация улучшилась: к списку добавились хеш-индексы, GiST и GIN. Если используется индексный доступ, а индекс не работает с предикатными блокировками, то блокировка накладывается на весь индекс целиком. Конечно, это тоже увеличивает число ложных обрывов транзакций.
В заключение отмечу, что именно с использованием предикатных блокировок связано ограничение, что для гарантий полной изоляции все транзакции должны работать на уровне Serializable. Если какая-либо транзакция будет использовать другой уровень, она просто не будет устанавливать (и проверять) предикатные блокировки.
Продолжение.
Сегодня у нас сборная солянка. Начнем с взаимоблокировок (вообще-то я собирался рассказать о них еще в прошлый раз, но та статья и так получилась неприлично длинной), затем пробежимся по оставшимся блокировкам объектов, и в заключение поговорим про предикатные блокировки.
Взаимоблокировки
При использовании блокировок возможна ситуация взаимоблокировки (или тупика). Она возникает, когда одна транзакция пытается захватить ресурс, уже захваченные другой транзакцией, в то время как другая транзакция пытается захватить ресурс, захваченный первой. Это проиллюстрировано на левом рисунке ниже: сплошные стрелки показывают захваченные ресурсы, пунктирные — попытки захватить уже занятый ресурс.
Визуально взаимоблокировку удобно представлять, построив граф ожиданий. Для этого мы убираем конкретные ресурсы и оставляем только транзакции, отмечая, какая транзакция какую ожидает. Если в графе есть контур (из вершины можно по стрелкам добраться до нее же самой) — это взаимоблокировка.
Конечно, взаимоблокировка возможна не только для двух транзакций, но и для любого большего числа.
Если взаимоблокировка возникла, участвующие в ней транзакции не могут ничего с этим сделать — они будут ждать бесконечно. Поэтому все СУБД, и PostgreSQL тоже, автоматически отслеживают взаимоблокировки.
Однако проверка требует определенных усилий, которые не хочется прилагать всякий раз, когда запрашивается новая блокировка (все-таки взаимоблокировки достаточно редки). Поэтому когда процесс пытается захватить блокировку и не может, он встает в очередь и засыпает, но взводит таймер на значение, указанное в параметре deadlock_timeout (по умолчанию — 1 секунда). Если ресурс освобождается раньше, то и хорошо, мы сэкономили на проверке. А вот если по истечении deadlock_timeout ожидание продолжается, тогда ожидающий процесс будет разбужен и инициирует проверку.
Если проверка (которая состоит в построении графа ожиданий и поиска в нем контуров) не выявила взаимоблокировок, то процесс продолжает спать — теперь уже до победного конца.
Ранее в комментариях меня справедливо упрекнули в том, что я ничего не сказал про параметр lock_timeout, который действует на любой оператор и позволяет избежать неопределенно долгого ожидания: если блокировку не удалось получить за указанное время, оператор завершается с ошибкой lock_not_available. Его не стоит путать с параметром statement_timeout, который ограничивает общее время выполнения оператора, неважно, ожидает ли он блокировку или просто выполняет работу.
Если же взаимоблокировка выявлена, то одна из транзакций (в большинстве случаев — та, которая инициировала проверку) принудительно обрывается. При этом освобождаются захваченные ей блокировки и остальные транзакции могут продолжать работу.
Взаимоблокировки обычно означают, что приложение спроектировано неправильно. Обнаружить такие ситуации можно двумя способами: во-первых, будут появляться сообщения в журнале сервера, и во-вторых, будет увеличиваться значение pg_stat_database.deadlocks.
Пример взаимоблокировки
Обычная причина возникновения взаимоблокировок — разный порядок блокирования строк таблиц.
Простой пример. Первая транзакция намерена перенести 100 рублей с первого счета на второй. Для этого она сначала уменьшает первый счет:
=> BEGIN;
=> UPDATE accounts SET amount = amount - 100.00 WHERE acc_no = 1;
UPDATE 1
В это же время вторая транзакция намерена перенести 10 рублей со второго счета на первый. Она начинает с того, что уменьшает второй счет:
| => BEGIN;
| => UPDATE accounts SET amount = amount - 10.00 WHERE acc_no = 2;
| UPDATE 1
Теперь первая транзакция пытается увеличить второй счет, но обнаруживает, что строка заблокирована.
=> UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 2;
Затем вторая транзакция пытается увеличить первый счет, но тоже блокируется.
| => UPDATE accounts SET amount = amount + 10.00 WHERE acc_no = 1;
Возникает циклическое ожидание, которое никогда не завершится само по себе. Через секунду первая транзакция, не получив доступ к ресурсу, инициирует проверку взаимоблокировки и обрывается сервером.
ERROR: deadlock detected
DETAIL: Process 16477 waits for ShareLock on transaction 530695; blocked by process 16513.
Process 16513 waits for ShareLock on transaction 530694; blocked by process 16477.
HINT: See server log for query details.
CONTEXT: while updating tuple (0,2) in relation "accounts"
Теперь вторая транзакция может продолжить работу.
| UPDATE 1
| => ROLLBACK;
=> ROLLBACK;
Правильный способ выполнения таких операций — блокирование ресурсов в одном и том же порядке. Например, в данном случае можно блокировать счета в порядке возрастания их номеров.
Взаимоблокировка двух команд UPDATE
Иногда можно получить взаимоблокировку там, где, казалось бы, ее быть никак не должно. Например, удобно и привычно воспринимать команды SQL как атомарные, но возьмем UPDATE — эта команда блокирует строки по мере их обновления. Это происходит не одномоментно. Поэтому если одна команда будет обновлять строки в одном порядке, а другая — в другом, они могут взаимозаблокироваться.
Получить такую ситуацию маловероятно, но тем не менее она может встретиться. Для воспроизведения мы создадим индекс по столбцу amount, построенный по убыванию суммы:
=> CREATE INDEX ON accounts(amount DESC);
Чтобы успеть увидеть происходящее, напишем функцию, увеличивающую переданное значение, но мееедленно-мееедленно, целую секунду:
=> CREATE FUNCTION inc_slow(n numeric) RETURNS numeric AS $$
SELECT pg_sleep(1);
SELECT n + 100.00;
$$ LANGUAGE SQL;
Еще нам понадобится расширение pgrowlocks.
=> CREATE EXTENSION pgrowlocks;
Первая команда UPDATE будет обновлять всю таблицу. План выполнения очевиден — последовательный просмотр:
| => EXPLAIN (costs off)
| UPDATE accounts SET amount = inc_slow(amount);
| QUERY PLAN
| ----------------------------
| Update on accounts
| -> Seq Scan on accounts
| (2 rows)
Поскольку версии строк на странице нашей таблицы лежат в порядке возрастания суммы (ровно так, как мы их добавляли), они и обновляться будут в том же порядке. Запускаем обновление работать.
| => UPDATE accounts SET amount = inc_slow(amount);
А в это время в другом сеансе мы запретим использование последовательного сканирования:
|| => SET enable_seqscan = off;
В этом случае для следующего оператора UPDATE планировщик решает использовать сканирование индекса:
|| => EXPLAIN (costs off)
|| UPDATE accounts SET amount = inc_slow(amount) WHERE amount > 100.00;
|| QUERY PLAN
|| --------------------------------------------------------
|| Update on accounts
|| -> Index Scan using accounts_amount_idx on accounts
|| Index Cond: (amount > 100.00)
|| (3 rows)
Под условие попадают вторая и третья строки, а, поскольку индекс построен по убыванию суммы, строки будут обновляться в обратном порядке.
Запускаем следующее обновление.
|| => UPDATE accounts SET amount = inc_slow(amount) WHERE amount > 100.00;
Быстрый взгляд в табличную страницу показывает, что первый оператор уже успел обновить первую строку (0,1), а второй — последнюю (0,3):
=> SELECT * FROM pgrowlocks('accounts') \gx
-[ RECORD 1 ]-----------------
locked_row | (0,1)
locker | 530699 <- первый
multi | f
xids | {530699}
modes | {"No Key Update"}
pids | {16513}
-[ RECORD 2 ]-----------------
locked_row | (0,3)
locker | 530700 <- второй
multi | f
xids | {530700}
modes | {"No Key Update"}
pids | {16549}
Проходит еще секунда. Первый оператор обновил вторую строку, а второй хотел бы это сделать, но не может.
=> SELECT * FROM pgrowlocks('accounts') \gx
-[ RECORD 1 ]-----------------
locked_row | (0,1)
locker | 530699 <- первый
multi | f
xids | {530699}
modes | {"No Key Update"}
pids | {16513}
-[ RECORD 2 ]-----------------
locked_row | (0,2)
locker | 530699 <- первый успел раньше
multi | f
xids | {530699}
modes | {"No Key Update"}
pids | {16513}
-[ RECORD 3 ]-----------------
locked_row | (0,3)
locker | 530700 <- второй
multi | f
xids | {530700}
modes | {"No Key Update"}
pids | {16549}
Теперь первый оператор хотел бы обновить последнюю строку таблицы, но она уже заблокирована вторым. Вот и взаимоблокировка.
Одна из транзакций прерывается:
|| ERROR: deadlock detected
|| DETAIL: Process 16549 waits for ShareLock on transaction 530699; blocked by process 16513.
|| Process 16513 waits for ShareLock on transaction 530700; blocked by process 16549.
|| HINT: See server log for query details.
|| CONTEXT: while updating tuple (0,2) in relation "accounts"
А другая завершает выполнение:
| UPDATE 3
Занимательные подробности об обнаружении и предотвращении взаимоблокировок можно почерпнуть из README менеджера блокировок.
На этом про взаимоблокировки все, а мы приступаем к оставшимся блокировкам объектов.
Блокировки не-отношений
Когда требуется заблокировать ресурс, не являющийся отношением в понимании PostgreSQL, используются блокировки типа object. Таким ресурсом может быть почти все, что угодно: табличные пространства, подписки, схемы, роли, перечислимые типы данных… Грубо говоря все, что только можно найти в системном каталоге.
Посмотрим на простом примере. Начинаем транзакцию и создаем в ней таблицу:
=> BEGIN;
=> CREATE TABLE example(n integer);
Теперь посмотрим, какие блокировки типа object появились в pg_locks:
=> SELECT
database,
(SELECT datname FROM pg_database WHERE oid = l.database) AS dbname,
classid,
(SELECT relname FROM pg_class WHERE oid = l.classid) AS classname,
objid,
mode,
granted
FROM pg_locks l
WHERE l.locktype = 'object' AND l.pid = pg_backend_pid();
database | dbname | classid | classname | objid | mode | granted
----------+--------+---------+--------------+-------+-----------------+---------
0 | | 1260 | pg_authid | 16384 | AccessShareLock | t
16386 | test | 2615 | pg_namespace | 2200 | AccessShareLock | t
(2 rows)
Чтобы разобраться, что именно тут блокируется, надо смотреть на три поля: database, classid и objid. Начнем с первой строки.
Database — это OID базы данных, к которой относится блокируемый ресурс. В нашем случае в этом столбце ноль. Это означает, что мы имеем дело с глобальным объектом, который не принадлежит к какой-либо конкретной базе.
Classid содержит OID из pg_class, который соответствует имени таблицы системного каталога, которая и определяет тип ресурса. В нашем случае — pg_authid, то есть ресурсом является роль (пользователь).
Objid содержит OID из той таблицы системного каталога, которую нам указал classid.
=> SELECT rolname FROM pg_authid WHERE oid = 16384;
rolname
---------
student
(1 row)
Таким образом, заблокирована роль student, из-под которой мы работаем.
Теперь разберемся со второй строкой. База данных указана, и это база test, к которой мы подключены.
Classid указывает на таблицу pg_namespace, которая содержит схемы.
=> SELECT nspname FROM pg_namespace WHERE oid = 2200;
nspname
---------
public
(1 row)
Таким образом, заблокирована схема public.
Итак, мы увидели, что при создании объекта блокируются (в разделяемом режиме) роль-владелец и схема, в которой создается объект. Что и логично: иначе кто-нибудь мог бы удалить роль или схему, пока транзакция еще не завершена.
=> ROLLBACK;
Блокировка расширения отношения
Когда число строк в отношении (то есть в таблице, индексе, материализованном представлении) растет, PostgreSQL может использовать для вставки свободное место в имеющихся страницах, но, очевидно, в какой-то момент приходится добавлять и новые страницы. Физически они добавляются в конец соответствующего файла. Это и понимается под расширением отношения.
Чтобы два процесса не кинулись добавлять страницы одновременно, этот процесс защищен специальной блокировкой с типом extend. Та же блокировка используется и при очистке индексов, чтобы другие процессы не могли добавлять страницы во время сканирования.
Конечно, эта блокировка снимается, не дожидаясь конца транзакции.
Раньше таблицы расширялись только на одну страницу за раз. Это вызывало проблемы при одновременной вставке строк несколькими процессами, поэтому в версии PostgreSQL 9.6 сделали так, чтобы к таблицам добавлялось сразу несколько страниц (пропорционально числу ожидающих блокировку процессов, но не более 512).
Блокировка страниц
Блокировка с типом page на уровне страницы применяется в единственном случае (если не считать предикатных блокировок, о которых позже).
GIN-индексы позволяют ускорять поиск в составных значениях, например, слов в текстовых документах (или элементов в массивах). Такие индексы в первом приближении можно представить как обычное B-дерево, в котором хранятся не сами документы, а отдельные слова этих документов. Поэтому при добавлении нового документа индекс приходится перестраивать довольно сильно, внося в него каждое слово, входящее в документ.
Чтобы улучшить производительность, GIN-индексы обладают возможностью отложенной вставки, которая включается параметром хранения fastupdate. Новые слова сначала по-быстрому добавляются в неупорядоченный список ожидания (pending list), а спустя какое-то время все накопившееся перемещается в основную индексную структуру. Экономия происходит за счет того, что разные документы с большой вероятностью содержат повторяющиеся слова.
Чтобы исключить перемещение из списка ожидания в основной индекс одновременно несколькими процессами, на время переноса метастраница индекса блокируется в исключительном режиме. Это не мешает использованию индекса в обычном режиме.
Рекомендательные блокировки
В отличие от других блокировок (таких, как блокировки отношений), рекомендательные блокировки (advisory locks) никогда не устанавливаются автоматически, ими управляет разработчик приложения. Их удобно использовать, например, если приложению для каких-то целей требуется логика блокирования, не вписывающаяся в стандартную логику обычных блокировок.
Допустим, у нас есть условный ресурс, не соответствующий никакому объекту базы данных (который мы могли бы заблокировать командами типа SELECT FOR или LOCK TABLE). Нужно придумать для него числовой идентификатор. Если у ресурса есть уникальное имя, то простой вариант — взять от него хеш-код:
=> SELECT hashtext('ресурс1');
hashtext
-----------
243773337
(1 row)
Вот таким образом мы захватываем блокировку:
=> BEGIN;
=> SELECT pg_advisory_lock(hashtext('ресурс1'));
Как обычно, информация о блокировках доступна в pg_locks:
=> SELECT locktype, objid, mode, granted
FROM pg_locks WHERE locktype = 'advisory' AND pid = pg_backend_pid();
locktype | objid | mode | granted
----------+-----------+---------------+---------
advisory | 243773337 | ExclusiveLock | t
(1 row)
Чтобы блокирование действительно работало, другие процессы также должны получать его блокировку, прежде чем обращаться к ресурсу. Соблюдение этого правила, очевидно, должно обеспечиваться приложением.
В приведенном примере блокировка действует до конца сеанса, а не транзакции, как обычно.
=> COMMIT;
=> SELECT locktype, objid, mode, granted
FROM pg_locks WHERE locktype = 'advisory' AND pid = pg_backend_pid();
locktype | objid | mode | granted
----------+-----------+---------------+---------
advisory | 243773337 | ExclusiveLock | t
(1 row)
Ее нужно освобождать явно:
=> SELECT pg_advisory_unlock(hashtext('ресурс1'));
Существуют большой набор функций для работы с рекомендательными блокировками на все случаи жизни:
- pg_advisory_lock_shared получает разделяемую блокировку,
- pg_advisory_xact_lock (и pg_advisory_xact_lock_shared) получает блокировку до конца транзакции,
- pg_try_advisory_lock (а также pg_try_advisory_xact_lock и pg_try_advisory_xact_lock_shared) не ожидает получения блокировки, а возвращает ложное значение, если блокировку не удалось получить немедленно.
Набор try-функций представляет еще один способ не ждать блокировку, в дополнение к перечисленным в прошлой статье.
Предикатные блокировки
Термин предикатная блокировка появился давно, при первых попытках реализовать полную изоляцию на основе блокировок в ранних СУБД (уровень Serializable, хотя стандарта SQL в те времена еще не существовало). Проблема, с которой тогда столкнулись, состояла в том, что даже блокировка всех прочитанных и измененных строк не дает полной изоляции: в таблице могут появиться новые строки, попадающие под те же условия отбора, что приводит к появлению фантомов (см. статью про изоляцию).
Идея предикатных блокировок состояла в блокировке не строк, а предикатов. Если при выполнении запроса с условием a > 10 заблокировать предикат a > 10, это не даст добавить в таблицу новые строки, попадающие под условие и позволит избежать фантомов. Проблема в том, что в общем случае это вычислительно сложная задача; на практике ее можно решить только для предикатов, имеющих очень простой вид.
В PostgreSQL уровень Serializable реализован иначе, поверх существующей изоляции на основе снимков данных. Термин предикатная блокировка остался, но смысл его в корне изменился. Фактически такие «блокировки» ничего не блокируют, а используются для отслеживания зависимостей по данным между транзакциями.
Доказано, что изоляция на основе снимков допускает аномалию несогласованной записи и аномалию только читающей транзакции, но никакие другие аномалии невозможны. Чтобы понять, что мы имеем дело с одной из двух перечисленных аномалией, мы можем анализировать зависимости между транзакциями и находить в них определенные закономерности.
Нас интересуют зависимости двух видов:
- одна транзакция читает строку, которая затем изменяется другой транзакцией (RW-зависимость),
- одна транзакция изменяет строку, которую затем читает другая транзакция (WR-зависимость).
WR-зависимости можно отследить, используя уже имеющиеся обычные блокировки, а вот RW-зависимости как раз приходится отслеживать дополнительно.
Еще раз повторюсь: несмотря на название, предикатные блокировки ничего не блокируют. Вместо этого при фиксации транзакции выполняется проверка и, если обнаруживается «нехорошая» последовательность зависимостей, которая может свидетельствовать об аномалии, транзакция обрывается.
Давайте посмотрим, как происходит установка предикатных блокировок. Для этого создадим таблицу с достаточно большим числом строк и индекс на ней.
=> CREATE TABLE pred(n integer);
=> INSERT INTO pred(n) SELECT g.n FROM generate_series(1,10000) g(n);
=> CREATE INDEX ON pred(n) WITH (fillfactor = 10);
=> ANALYZE pred;
Если запрос выполняется с помощью последовательного сканирования всей таблицы, то предикатная блокировка устанавливается на всю таблицу (даже если под условия фильтрации попадают не все строки).
| => SELECT pg_backend_pid();
| pg_backend_pid
| ----------------
| 12763
| (1 row)
| => BEGIN ISOLATION LEVEL SERIALIZABLE;
| => EXPLAIN (analyze, costs off)
| SELECT * FROM pred WHERE n > 100;
| QUERY PLAN
| ----------------------------------------------------------------
| Seq Scan on pred (actual time=0.047..12.709 rows=9900 loops=1)
| Filter: (n > 100)
| Rows Removed by Filter: 100
| Planning Time: 0.190 ms
| Execution Time: 15.244 ms
| (5 rows)
Любые предикатные блокировки всегда захватываются в одном специальном режиме SIReadLock (Serializable Isolation Read):
=> SELECT locktype, relation::regclass, page, tuple
FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;
locktype | relation | page | tuple
----------+----------+------+-------
relation | pred | |
(1 row)
| => ROLLBACK;
А вот если запрос выполняется с помощью индексного сканирования, ситуация меняется в лучшую сторону. Если говорить о B-дереве, то достаточно установить блокировку на прочитанные табличные строки и на просмотренные листовые страницы индекса — тем самым мы блокируем не только конкретные значения, но и весь прочитанный диапазон.
| => BEGIN ISOLATION LEVEL SERIALIZABLE;
| => EXPLAIN (analyze, costs off)
| SELECT * FROM pred WHERE n BETWEEN 1000 AND 1001;
| QUERY PLAN
| ------------------------------------------------------------------------------------
| Index Only Scan using pred_n_idx on pred (actual time=0.122..0.131 rows=2 loops=1)
| Index Cond: ((n >= 1000) AND (n <= 1001))
| Heap Fetches: 2
| Planning Time: 0.096 ms
| Execution Time: 0.153 ms
| (5 rows)
=> SELECT locktype, relation::regclass, page, tuple
FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;
locktype | relation | page | tuple
----------+------------+------+-------
tuple | pred | 3 | 236
tuple | pred | 3 | 235
page | pred_n_idx | 22 |
(3 rows)
Можно заметить несколько сложностей.
Во-первых, на каждую прочитанную версию строки создается отдельная блокировка, но потенциально таких версий может быть очень много. Общее число предикатных блокировок в системе ограничено произведением значений параметров max_pred_locks_per_transaction × max_connections (значения по умолчанию — 64 и 100 соответственно). Память под такие блокировки отводится при запуске сервера; попытка превысить это число будет приводить к ошибкам.
Поэтому для предикатных блокировок (и только для них!) используется повышение уровня. До версии PostgreSQL 10 действовали жестко зашитые в код ограничения, а начиная с нее повышением уровня можно управлять параметрами. Если число блокировок версий строк, относящихся к одной странице, превышает max_pred_locks_per_page, такие блокировки заменяются на одну блокировку уровня страницы. Вот пример:
=> SHOW max_pred_locks_per_page;
max_pred_locks_per_page
-------------------------
2
(1 row)
| => EXPLAIN (analyze, costs off)
| SELECT * FROM pred WHERE n BETWEEN 1000 AND 1002;
| QUERY PLAN
| ------------------------------------------------------------------------------------
| Index Only Scan using pred_n_idx on pred (actual time=0.019..0.039 rows=3 loops=1)
| Index Cond: ((n >= 1000) AND (n <= 1002))
| Heap Fetches: 3
| Planning Time: 0.069 ms
| Execution Time: 0.057 ms
| (5 rows)
Вместо трех блокировок типа tuple видим одну типа page:
=> SELECT locktype, relation::regclass, page, tuple
FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;
locktype | relation | page | tuple
----------+------------+------+-------
page | pred | 3 |
page | pred_n_idx | 22 |
(2 rows)
Аналогично, если число блокировок страниц, относящихся к одному отношению, превышает max_pred_locks_per_relation, такие блокировки заменяются на одну блокировку уровня отношения.
Других уровней не бывает: предикатные блокировки захватываются только для отношений, страниц или версий строк, и всегда с режимом SIReadLock.
Конечно, повышение уровня блокировок неизбежно приводит к тому, что большее число транзакций будет ложно завершаться ошибкой сериализации и в итоге пропускная способность системы будет снижаться. Здесь нужно искать баланс между расходом оперативной памяти и производительностью.
Вторая сложность состоит в том, что при различных операциях с индексом (например, из-за расщепления индексных страниц при вставке новых строк) число листовых страниц, покрывающих прочитанный диапазон, может измениться. Но реализация это учитывает:
=> INSERT INTO pred SELECT 1001 FROM generate_series(1,1000);
=> SELECT locktype, relation::regclass, page, tuple
FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;
locktype | relation | page | tuple
----------+------------+------+-------
page | pred | 3 |
page | pred_n_idx | 211 |
page | pred_n_idx | 212 |
page | pred_n_idx | 22 |
(4 rows)
| => ROLLBACK;
К слову, предикатные блокировки не всегда снимаются сразу по завершению транзакции, ведь они нужны, чтобы отслеживать зависимости между несколькими транзакциями. Но в любом случае управление ими происходит автоматически.
Далеко не все типы индексов в PostgreSQL поддерживают предикатные блокировки. Раньше этим могли похвастать только B-деревья, но в версии PostgreSQL 11 ситуация улучшилась: к списку добавились хеш-индексы, GiST и GIN. Если используется индексный доступ, а индекс не работает с предикатными блокировками, то блокировка накладывается на весь индекс целиком. Конечно, это тоже увеличивает число ложных обрывов транзакций.
В заключение отмечу, что именно с использованием предикатных блокировок связано ограничение, что для гарантий полной изоляции все транзакции должны работать на уровне Serializable. Если какая-либо транзакция будет использовать другой уровень, она просто не будет устанавливать (и проверять) предикатные блокировки.
По традиции оставлю ссылку на README по предикатным блокировкам, с которого можно начинать изучение исходного кода.
Продолжение.
