
Привет! Меня зовут Алексей Озерицкий. В Яндексе я работаю в разработке технологий и инфраструктуры. Не только тем нашим сервисам, которыми пользуются миллионы людей, важно уметь работать с действительно большими объемами данных без сбоев. Один из наших ключевых внутренних инструментов — Я.Статистика, информация в котором предназначена только для сотрудников Яндекса и более того — является коммерческой тайной. Статистика занимается сбором, хранением и обработкой информации (в первую очередь логов) от сервисов Яндекса. Результатом нашей работы с ней являются статистические расчеты для дальнейшей аналитики и принятия продуктовых решений.

Один из ключевых компонентов Статистики – Logbroker, распределенное многодатацентровое решение по сбору и поставке данных. Ключевые особенности системы – возможность переживать отключение дата-центра, поддержка семантики exactly once на доставку сообщений и поддержка потоков реального времени (секунды задержки от возникновения события на источнике до получения на приемнике).
В ядре системы лежит Apache Kafka. Logbroker с помощью API изолирует пользователя от сырых потоков Apache Kafka, реализует процессы восстановления после сбоев (в том числе семантику exactly once) и сервисные процессы (междатацентровая репликация, раздача данных на кластеры расчета: YT, YaMR...).
Изначально для расчета отчетов Я.Статистика использовала Oracle. Данные скачивались с серверов и записывались в Oracle. Раз в сутки с помощью SQL-запросов по данным строились отчеты.
Объемы данных росли ежегодно в 2,5 раза, поэтому к 2010 году такая схема начала давать сбои. База данных перестала справляться с нагрузкой, и расчет отчетов замедлился. Расчет отчетов из базы данных перенесли в YaMR, а в качестве долговременного хранилища логов стали использовать самописное решение, которое представляло собой распределенное хранилище, где каждый кусок данных выступал в виде отдельного файла. Решение называлось просто – Архив.
Архив имел многие черты текущего Logbroker. В частности, он умел принимать данные и раздавать данные на различные кластеры YaMR и внешним потребителям. Также Архив хранил метаданные и позволял получать выборки по различным параметрам (время, имя файла, имя сервера, тип лога…). В случае сбоя или потерь данных на YaMR можно было восстановить произвольный кусок данных из Архива.
Мы по-прежнему обходили сервера, скачивали данные и сохраняли их в Архив. В начале 2011 года такой подход начал буксовать. Кроме очевидной проблемы с безопасностью (серверы статистики имеют доступ ко всем серверам Яндекса), он имел проблемы с масштабируемостью и производительностью. В результате был написан клиент, который устанавливался на серверы и отгружал логи напрямую в Архив. Клиент (внутреннее название продукта push-client) – это легкая программа на C, которая не использует никаких внешних зависимостей и поддерживает различные варианты Linux, FreeBSD и даже Windows. В процессе работы клиент следит за обновлением файлов с данными (логов) и отсылает новые данные по протоколу http(s).
Архив обладал некоторыми недостатками. Он не переживал отключение дата-центра, из-за файловой организации имел ограниченные возможности по масштабированию и принципиально не поддерживал получение/отдачу данных в режиме реального времени. Перед отправкой данных в архив нужно было накапливать буфер интервалом не менее минуты, в то время как наши потребители хотели секундных задержек поставки.
Было решено написать новый архив, взяв за основу одно из имеющихся NoSQL-решений для отказоустойчивого хранения.
Мы рассматривали HBase, Cassandra, Elliptics. HBase не подошла из-за проблем с междатацентровой репликацией. Cassandra и Elliptics не подошли из-за существенного проседания производительности во время дефрагментации базы и при добавлении новых машин в кластер. В принципе, ограничения на добавление новых машин еще можно было бы пережить, так как это нечастая операция, а вот ограничение на дефрагментацию оказалось существенным: каждый день в архив записывается суточный набор данных, при этом старые данные за N суток назад удаляются, то есть дефрагментацию надо было бы выполнять постоянно.
В итоге мы решили пересмотреть нашу архитектуру поставки. Вместо долгосрочного хранилища – Архива с полным набором метаданных и возможность построения всевозможных срезов мы решили написать легкое и быстрое краткосрочное хранилище с минимальным функционалом по построению выборок.
За основу реализации взяли Apache Kafka.
Kafka реализует персистентную очередь сообщений. Персистентность означает, что данные отправленные в Kafka продолжают существовать после перезапуска процессов или машин. Каждый поток однотипных сообщений в Kafka представляется сущностью под названием топик. Топик делится на партиции, что обеспечивает параллельность записи и чтения топика. Kafka очень легко масштабируется: при увеличении объема потоков можно увеличить число партиций топика и число обслуживающих их машин.
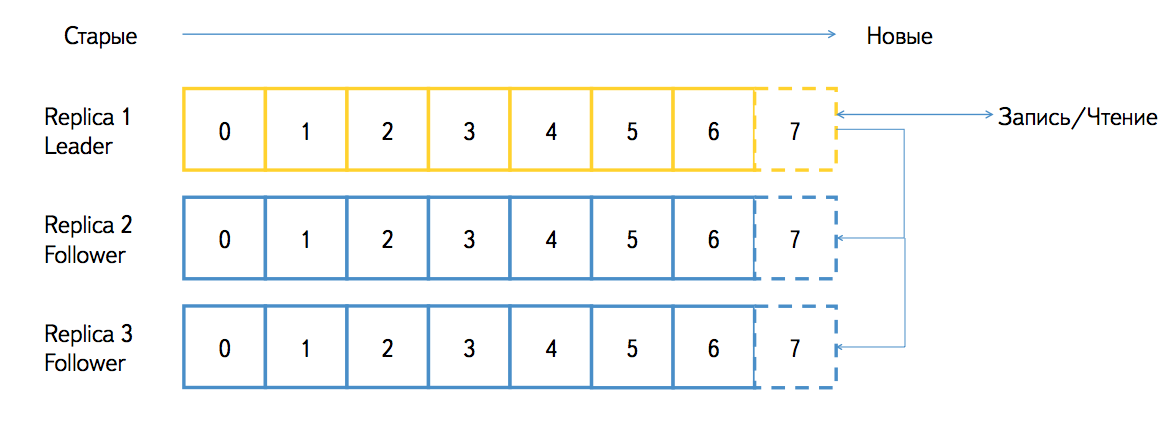
Партиция может существовать в нескольких репликах и обслуживаться различными узлами (брокерами в терминах Kafka). Реплики бывают двух видов: лидер и фоловер. Реплика-лидер принимает все запросы на запись и чтение данных, реплика-фоловер принимает и сохраняет поток от реплики-лидера. Kafka гарантирует идентичность всех реплик байт в байт. Если один из брокеров станет недоступен, то все реплики-лидеры автоматически переедут на других брокеров и партицию всё равно можно будет писать и читать. При поднятии брокера все реплики, которые он обслуживал, автоматически становятся фоловерами и нагоняют накопившееся отставание с реплик-лидеров. Время от времени в Kafka может запускаться процесс балансировки лидеров, поэтому в нормальной ситуации не будет такого, что какой-то брокер перегружен запросами, а какой-то – недогружен.

Запись в кластер Kafka осуществляет сущность под названием Продьюсер, а чтение – Консьюмер.
Топик – это очередь однотипных сообщений. Например, если мы пишем в Kafka access-логи web-серверов, то в один топик можно помещать записи лога nginx, а в другой – лога apache. Для каждого топика Kafka хранит партицированный лог, который выглядит следующим образом:
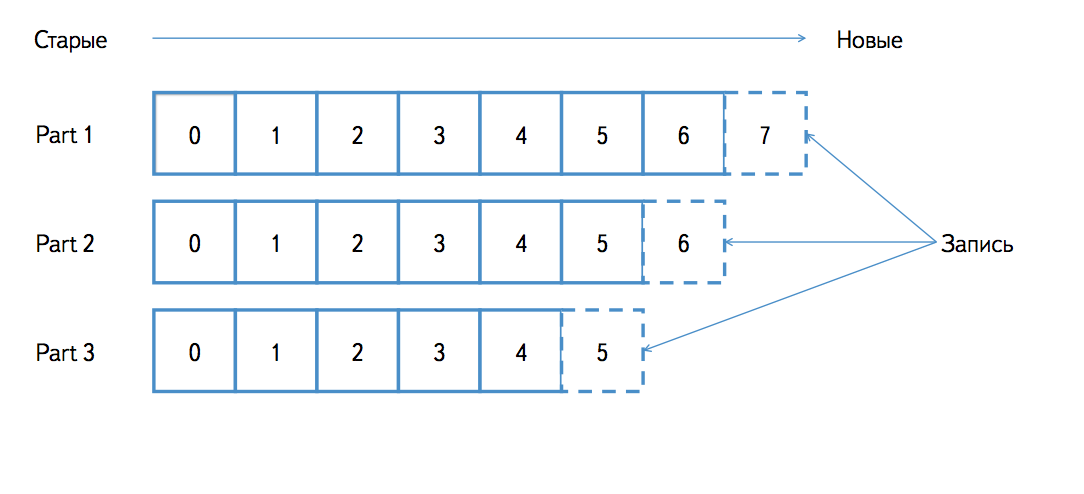
Каждая партиция – это упорядоченная последовательность сообщений, порядок элементов в которой не меняется; при поступлении нового сообщения оно добавляется в конец. Каждое сообщение в очереди имеет уникальный идентификатор (оффсет в терминах Kafka). Сообщения нумеруются по порядку (1, 2, 3, …).
Периодически Kafka сама удаляет старые сообщения. Это очень дешевая операция, так как физически партиция на диске представлена набором файлов-сегментов. Каждый сегмент содержит непрерывную часть последовательности. Например, могут быть сегменты с сообщениями, имеющими идентификаторы 1, 2, 3 и 4, 5, 6, но не может быть сегментов с сообщениями, имеющими идентификаторы 1, 3, 4 и 2, 5, 6. При удалении старых сообщений просто удаляется самый старый файл-сегмент.
Существуют различные семантики на доставку сообщения: at most once – будет доставлено не более одного сообщения, at least once – будет доставлено не менее одного сообщения, exactly once – будет доставлено ровно одно сообщение. Kafka обеспечивает семантику at least once на доставку. Дублирование сообщений может происходить как при записи, так и при чтении. Стандартный продьюсер Kafka в случае возникновения проблем (разрыв соединения до получения ответа, тайм-аут на отправке и т. п.) произведет переотправку сообщения, что во многих случаях приведет к появлению дубликатов. При чтении сообщений тоже может быть дублирование, если фиксация идентификаторов сообщений происходит после обработки данных и между этими двумя событиями возникает ошибка. Но в случае с чтением дело обстоит проще, так как читатель полностью контролирует процесс и может фиксировать одновременно завершение обработки данных и идентификаторы (например, делать это в одной транзакции в случае записи в базу данных).
Logbroker:
Изначально мы сделали сервис Logbroker полностью совместимым по API со старым Архивом, поэтому при переезде наши клиенты не заметили никакой разницы.
Старый API имел следующие методы для записи:
Данный API почти обеспечивает exactly-once-семантику поставки данных. Как это выглядит на стороне Kafka.
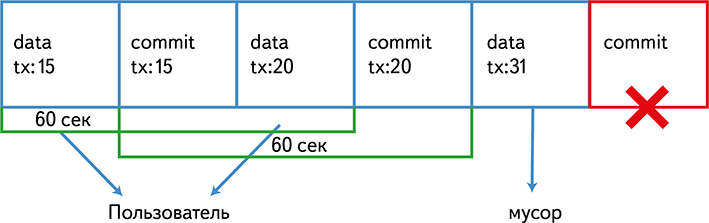
На запрос /store мы сохраняем кусок данных в локальный файл во временное хранилище. На запрос /commit_request мы пишем этот файл в Kafka, причем файлу ставится в соответствие transaction_id. На запрос /commit мы пишем в Kafka специальное небольшое commit-сообщение, которое говорит, что файл с данным transaction_id записан.
Консьюмер читает данный поток из Kafka с окном в 60 секунд. Все сообщения для transaction_id, для которых найдено специальное commit-сообщение, мы отдаем пользователю, остальное пропускаем.
Тайм-аут на запись клиента – 30 секунд, поэтому вероятность того, что клиент записал и отправил commit-сообщение, но потом Консьюмер это сообщение пропустил, равна нулю. Так как commit-сообщение небольшое, вероятность зависнуть на его записи близка к нулю.
После успешного запуска нам захотелось сделать потоковую realtime-поставку со строгой exactly-once-семантикой.
Терминология нового (rt) протокола:
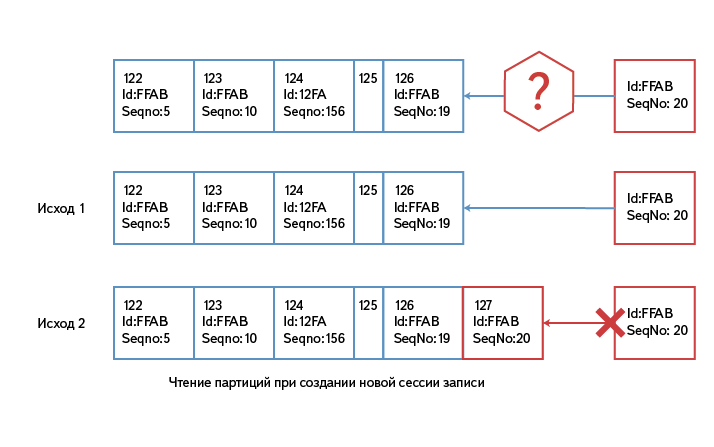
Клиент устанавливает соединение с Logbroker один раз на каждый sourceId и шлет данные небольшими чанками. Logbroker записывает в сообщение для Kafka sourceId и seqno. При этом каждый sourceId всегда гарантированно пишется в одну и ту же партицию Kafka.
Если вдруг по каким-то причинам соединение разорвалось, клиент создает его заново (возможно уже с другим хостом), при этом Logbroker читает партицию, относящуюся к данному sourceId, и определяет, какой seqno был записан последним. Если от клиента приходят чанки с seqno <= записанному, то они пропускаются.
Из-за чтения партиции сессия на запись данных может создаваться ощутимое время, в нашем случае – до 10 секунд. Так как это нечастая операция, на отставание поставки это не влияет. Мы проводили замеры цикла поставки запись/чтение: 88% чанков от создания до чтения потребителем укладываются в одну секунду, 99% – в пять секунд.
Мы не стали использовать зеркальщик из поставки Kafka и написали свой. Основные отличия:
Физически процессы Logbroker и Kafka работают на одних и тех же машинах. Зеркалирующий процесс работает только с партициями, реплики которых являются лидерами на данной машине. Если лидеры на машине сменились, то зеркалирующий процесс автоматически это определяет и начинает зеркалировать другие партиции.
Как именно мы определяем, что и куда зеркалировать?
Пусть у нас имеется два кластера Kafka в дата-центрах с именами dc1 и dc2. Когда данные попадают в dc1, мы их пишем в топики с префиксом dc1. Например, dc1.log1. Данные в dc2 пишутся в топики с префиксом dc2. По префиксам мы определяем, какие топики изначально писались в данный дата-центр, и именно их мы зеркалируем в другой дата-центр.
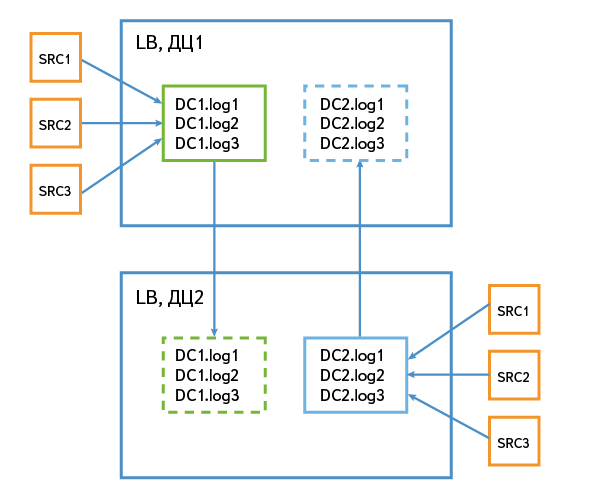
В схеме зеркалирования могут быть варианты, различающиеся нюансами. Например, если Logbroker стоит в дата-центре с несколькими крупными потребителями, то имеет смысл зеркалировать сюда все топики со всех дата-центров. Если Logbroker стоит в дата-центре без крупных потребителей, то он может выступать в качестве локального сборщика данных этого дата-центра, а потом отправлять данные в крупные инсталляции Logbroker.
Данные зеркалируются партиция в партицию. Во время зеркалирования мы раз в 60 секунд сохраняем по каждой партиции два числа: оффсет записи в исходной партиции и оффсет записи в отзеркалированной партиции. Если во время записи происходит сбой, мы читаем сохраненное состояние и реальные размеры в записях исходной и отзеркалированной партиции и по этим числам определяем точно, откуда надо читать исходную партицию.

Источники данных ничего не знают о топологии инсталляции Logbroker. Logbroker сам направляет запись источника на нужную ноду. Если источник находится в дата-центре, где есть инсталляция Logbroker, то данные будут записаны в неё, в другие дата-центры данные попадут с помощью зеркалирования.
Существует несколько сценариев получения данных из Logbroker. Во-первых, у есть разделение по типу поставки: push или pull. То есть Logbroker может сам отправлять данные потребителям (push-поставка), либо потребитель может сам читать данные по http-протоколу (pull-поставка). В обоих случаях мы поддерживаем два сценария получения данных.
Если потребитель находится полностью в одном дата-центре с одним из кластеров Logbroker, то он читает все топики.
Если потребитель находится в дата-центре, в котором Logbroker не представлен, либо если потребитель размазан по нескольким дата-центрам, то из каждого дата-центра он читает только топики с префиксом дата-центра. Например, если читаем из кластера в дата-центре dc1, то читаем только топики с префиксом dc1.
На первый взгляд кажется, что можно читать все топики из одного дата-центра, а в случае его отключения переключаться на чтение тех же топиков в другой дата-центр. На самом деле это не так. Дело в том, что у сообщений в партициях с одним именем на разных кластерах Kafka в разных дата-центрах будут разные офсеты. Связано это с тем, что кластеры могли быть запущены в разное время и запуск зеркалирования проводился в разное время. Наш зеркальщик гарантирует только неизменность порядка сообщений. Читатель из Logbroker оперирует оффсетами партиций, а так как в другом дата-центре они будут другими, то при переключении читатель либо получит дубликаты, либо недополучит данные.
На самом деле во многих случаях такое переключение чтения будет бесполезно. Например, мы читали в дата-центре dc1 топик с префиксом dc1. Вдруг дата-центр dc1 упал, и мы хотим переключиться на dc2, чтобы продолжить читать топик с префиксом dc1. Но так как дата-центр dc1 упал, то и топик с данным префиксом не пишется и новых данных в дата-центре dc2 просто не будет.
Logbroker существенно упрощает схему поставки данных. В его отсутствие пришлось бы делать сложный клиент, который умел бы отправлять данные сразу в несколько мест. Сложный клиент приходилось бы постоянно обновлять для исправления багов и добавления поддержки новых потребителей. Сейчас мы имеем очень простой легкий клиент, написанный на C. Этот клиент очень редко обновляется. Например, на некоторых наших источниках до сих пор стоят старые сборки 2012 года, которые раньше работали с Архивом, а сейчас работают с Logbroker.
Централизованная поставка также существенно экономит междатацентровый трафик:
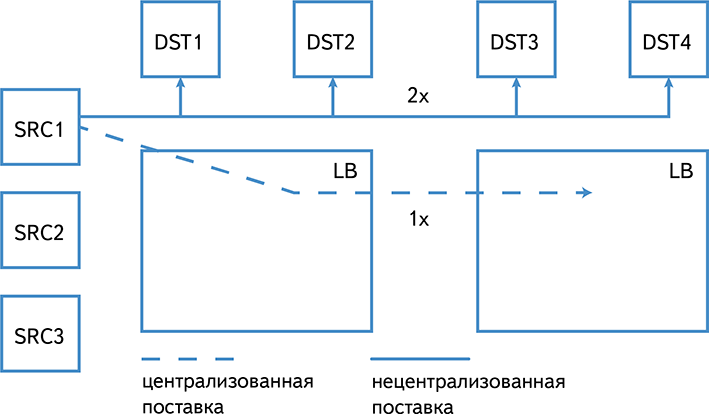
В случае сбоев на кластерах-приемниках мы можем быстро и эффективно дозалить недостающие данные Logbroker. Делать ту же операцию на самих источниках было бы существенно сложнее.
Сейчас Logbroker используется для поставки логов с серверов. Общий объем входящего трафика в среднем 60 терабайт в день. Исходящего – в 3-4 раза больше (зависит от конкретного дата-центра). Потребителями логов являются в основном кластеры Статистики и Поиска. Также имеется ряд более мелких потребителей, которые получают небольшой поток только нужных им логов.
Сейчас мы ведем работу по внедрению Logbroker в качестве транспортной шины внутри компании для прокачивания не только логов, но и бинарных данных.
В процессе разработки мы сталкивались с трудностями, связанными в основном с сыростью Kafka. В частности, очень сырым оказался клиентский код. Высокоуровневая библиотека для записи и чтения данных могла залипнуть на какое-то время, а также заблокировать процесс. Изначально мы запустились с таким кодом, но потом в процессе разработки написали свой асинхронный клиент для Kafka. Сейчас думаем об оформлении этого клиента в виде opensource-библиотеки.
В отличие от клиентской, серверная часть Kafka написана очень качественно и используется нами практически без изменений. Мы применяем небольшие патчи, которые время от времени стараемся отослать разработчикам.
Один из ключевых компонентов Статистики – Logbroker, распределенное многодатацентровое решение по сбору и поставке данных. Ключевые особенности системы – возможность переживать отключение дата-центра, поддержка семантики exactly once на доставку сообщений и поддержка потоков реального времени (секунды задержки от возникновения события на источнике до получения на приемнике).
В ядре системы лежит Apache Kafka. Logbroker с помощью API изолирует пользователя от сырых потоков Apache Kafka, реализует процессы восстановления после сбоев (в том числе семантику exactly once) и сервисные процессы (междатацентровая репликация, раздача данных на кластеры расчета: YT, YaMR...).
История
Изначально для расчета отчетов Я.Статистика использовала Oracle. Данные скачивались с серверов и записывались в Oracle. Раз в сутки с помощью SQL-запросов по данным строились отчеты.
Объемы данных росли ежегодно в 2,5 раза, поэтому к 2010 году такая схема начала давать сбои. База данных перестала справляться с нагрузкой, и расчет отчетов замедлился. Расчет отчетов из базы данных перенесли в YaMR, а в качестве долговременного хранилища логов стали использовать самописное решение, которое представляло собой распределенное хранилище, где каждый кусок данных выступал в виде отдельного файла. Решение называлось просто – Архив.
Архив имел многие черты текущего Logbroker. В частности, он умел принимать данные и раздавать данные на различные кластеры YaMR и внешним потребителям. Также Архив хранил метаданные и позволял получать выборки по различным параметрам (время, имя файла, имя сервера, тип лога…). В случае сбоя или потерь данных на YaMR можно было восстановить произвольный кусок данных из Архива.
Мы по-прежнему обходили сервера, скачивали данные и сохраняли их в Архив. В начале 2011 года такой подход начал буксовать. Кроме очевидной проблемы с безопасностью (серверы статистики имеют доступ ко всем серверам Яндекса), он имел проблемы с масштабируемостью и производительностью. В результате был написан клиент, который устанавливался на серверы и отгружал логи напрямую в Архив. Клиент (внутреннее название продукта push-client) – это легкая программа на C, которая не использует никаких внешних зависимостей и поддерживает различные варианты Linux, FreeBSD и даже Windows. В процессе работы клиент следит за обновлением файлов с данными (логов) и отсылает новые данные по протоколу http(s).
Архив обладал некоторыми недостатками. Он не переживал отключение дата-центра, из-за файловой организации имел ограниченные возможности по масштабированию и принципиально не поддерживал получение/отдачу данных в режиме реального времени. Перед отправкой данных в архив нужно было накапливать буфер интервалом не менее минуты, в то время как наши потребители хотели секундных задержек поставки.
Было решено написать новый архив, взяв за основу одно из имеющихся NoSQL-решений для отказоустойчивого хранения.
Мы рассматривали HBase, Cassandra, Elliptics. HBase не подошла из-за проблем с междатацентровой репликацией. Cassandra и Elliptics не подошли из-за существенного проседания производительности во время дефрагментации базы и при добавлении новых машин в кластер. В принципе, ограничения на добавление новых машин еще можно было бы пережить, так как это нечастая операция, а вот ограничение на дефрагментацию оказалось существенным: каждый день в архив записывается суточный набор данных, при этом старые данные за N суток назад удаляются, то есть дефрагментацию надо было бы выполнять постоянно.
В итоге мы решили пересмотреть нашу архитектуру поставки. Вместо долгосрочного хранилища – Архива с полным набором метаданных и возможность построения всевозможных срезов мы решили написать легкое и быстрое краткосрочное хранилище с минимальным функционалом по построению выборок.
За основу реализации взяли Apache Kafka.
Технические детали
Kafka реализует персистентную очередь сообщений. Персистентность означает, что данные отправленные в Kafka продолжают существовать после перезапуска процессов или машин. Каждый поток однотипных сообщений в Kafka представляется сущностью под названием топик. Топик делится на партиции, что обеспечивает параллельность записи и чтения топика. Kafka очень легко масштабируется: при увеличении объема потоков можно увеличить число партиций топика и число обслуживающих их машин.
Партиция может существовать в нескольких репликах и обслуживаться различными узлами (брокерами в терминах Kafka). Реплики бывают двух видов: лидер и фоловер. Реплика-лидер принимает все запросы на запись и чтение данных, реплика-фоловер принимает и сохраняет поток от реплики-лидера. Kafka гарантирует идентичность всех реплик байт в байт. Если один из брокеров станет недоступен, то все реплики-лидеры автоматически переедут на других брокеров и партицию всё равно можно будет писать и читать. При поднятии брокера все реплики, которые он обслуживал, автоматически становятся фоловерами и нагоняют накопившееся отставание с реплик-лидеров. Время от времени в Kafka может запускаться процесс балансировки лидеров, поэтому в нормальной ситуации не будет такого, что какой-то брокер перегружен запросами, а какой-то – недогружен.
Запись в кластер Kafka осуществляет сущность под названием Продьюсер, а чтение – Консьюмер.
Топик – это очередь однотипных сообщений. Например, если мы пишем в Kafka access-логи web-серверов, то в один топик можно помещать записи лога nginx, а в другой – лога apache. Для каждого топика Kafka хранит партицированный лог, который выглядит следующим образом:
Каждая партиция – это упорядоченная последовательность сообщений, порядок элементов в которой не меняется; при поступлении нового сообщения оно добавляется в конец. Каждое сообщение в очереди имеет уникальный идентификатор (оффсет в терминах Kafka). Сообщения нумеруются по порядку (1, 2, 3, …).
Периодически Kafka сама удаляет старые сообщения. Это очень дешевая операция, так как физически партиция на диске представлена набором файлов-сегментов. Каждый сегмент содержит непрерывную часть последовательности. Например, могут быть сегменты с сообщениями, имеющими идентификаторы 1, 2, 3 и 4, 5, 6, но не может быть сегментов с сообщениями, имеющими идентификаторы 1, 3, 4 и 2, 5, 6. При удалении старых сообщений просто удаляется самый старый файл-сегмент.
Существуют различные семантики на доставку сообщения: at most once – будет доставлено не более одного сообщения, at least once – будет доставлено не менее одного сообщения, exactly once – будет доставлено ровно одно сообщение. Kafka обеспечивает семантику at least once на доставку. Дублирование сообщений может происходить как при записи, так и при чтении. Стандартный продьюсер Kafka в случае возникновения проблем (разрыв соединения до получения ответа, тайм-аут на отправке и т. п.) произведет переотправку сообщения, что во многих случаях приведет к появлению дубликатов. При чтении сообщений тоже может быть дублирование, если фиксация идентификаторов сообщений происходит после обработки данных и между этими двумя событиями возникает ошибка. Но в случае с чтением дело обстоит проще, так как читатель полностью контролирует процесс и может фиксировать одновременно завершение обработки данных и идентификаторы (например, делать это в одной транзакции в случае записи в базу данных).
Связь Logbroker с Kafka
Logbroker:
- Изолирует от пользователя внутреннюю кухню Kafka:
- превращает поток данных от клиента в сообщения Kafka;
- добавляет в сообщения всю необходимую нам метаинформацию (имя сервера, имя файла, тип лога…);
- выбирает наиболее подходящее имя топика.
- Предоставляет http API для записи и чтения данных.
- Предоставляет сервис по автоматической заливке новых данных на кластеры YT и YaMR.
- Предоставляет сервис по междатацентровой репликации данных между кластерами Kafka.
- Предоставляет настроенную вокруг Kafka инфраструктуру:
- сервис конфигурирования (watchdog, отстрел дисков, перебалансировку дисков, форсированное удаление сегментов);
- метрики, интеграцию с graphite (http://graphite.wikidot.com/);
- скрипты для мониторинга.
Изначально мы сделали сервис Logbroker полностью совместимым по API со старым Архивом, поэтому при переезде наши клиенты не заметили никакой разницы.
Старый API имел следующие методы для записи:
- /store (запись данных),
- /commit_request (запрос на коммит транзакции),
- /commit (коммит).
Данный API почти обеспечивает exactly-once-семантику поставки данных. Как это выглядит на стороне Kafka.
На запрос /store мы сохраняем кусок данных в локальный файл во временное хранилище. На запрос /commit_request мы пишем этот файл в Kafka, причем файлу ставится в соответствие transaction_id. На запрос /commit мы пишем в Kafka специальное небольшое commit-сообщение, которое говорит, что файл с данным transaction_id записан.
Консьюмер читает данный поток из Kafka с окном в 60 секунд. Все сообщения для transaction_id, для которых найдено специальное commit-сообщение, мы отдаем пользователю, остальное пропускаем.
Тайм-аут на запись клиента – 30 секунд, поэтому вероятность того, что клиент записал и отправил commit-сообщение, но потом Консьюмер это сообщение пропустил, равна нулю. Так как commit-сообщение небольшое, вероятность зависнуть на его записи близка к нулю.
После успешного запуска нам захотелось сделать потоковую realtime-поставку со строгой exactly-once-семантикой.
Терминология нового (rt) протокола:
- sourceId – уникальный идентификатор источника (например, может соответствовать файлу на конкретном хосте);
- seqno – уникальный (в пределах sourceId) идентификатор чанка, постоянно увеличивается (например, может соответствовать офсету в файле).
Клиент устанавливает соединение с Logbroker один раз на каждый sourceId и шлет данные небольшими чанками. Logbroker записывает в сообщение для Kafka sourceId и seqno. При этом каждый sourceId всегда гарантированно пишется в одну и ту же партицию Kafka.
Если вдруг по каким-то причинам соединение разорвалось, клиент создает его заново (возможно уже с другим хостом), при этом Logbroker читает партицию, относящуюся к данному sourceId, и определяет, какой seqno был записан последним. Если от клиента приходят чанки с seqno <= записанному, то они пропускаются.
Из-за чтения партиции сессия на запись данных может создаваться ощутимое время, в нашем случае – до 10 секунд. Так как это нечастая операция, на отставание поставки это не влияет. Мы проводили замеры цикла поставки запись/чтение: 88% чанков от создания до чтения потребителем укладываются в одну секунду, 99% – в пять секунд.
Как работает междатацентровое зеркалирование
Мы не стали использовать зеркальщик из поставки Kafka и написали свой. Основные отличия:
- не создается большого количества буферов чтения и отправки, в результате мы потребляем существенно меньше памяти и можем работать с большим числом партиций (в нашем продакшене сейчас может быть до 10 000);
- партиция гарантированно зеркалируется один в один, и сообщения не перемешиваются;
- зеркалирование гарантирует exactly-once-семантику: нет дублей и потерь сообщений.
Физически процессы Logbroker и Kafka работают на одних и тех же машинах. Зеркалирующий процесс работает только с партициями, реплики которых являются лидерами на данной машине. Если лидеры на машине сменились, то зеркалирующий процесс автоматически это определяет и начинает зеркалировать другие партиции.
Как именно мы определяем, что и куда зеркалировать?
Пусть у нас имеется два кластера Kafka в дата-центрах с именами dc1 и dc2. Когда данные попадают в dc1, мы их пишем в топики с префиксом dc1. Например, dc1.log1. Данные в dc2 пишутся в топики с префиксом dc2. По префиксам мы определяем, какие топики изначально писались в данный дата-центр, и именно их мы зеркалируем в другой дата-центр.
В схеме зеркалирования могут быть варианты, различающиеся нюансами. Например, если Logbroker стоит в дата-центре с несколькими крупными потребителями, то имеет смысл зеркалировать сюда все топики со всех дата-центров. Если Logbroker стоит в дата-центре без крупных потребителей, то он может выступать в качестве локального сборщика данных этого дата-центра, а потом отправлять данные в крупные инсталляции Logbroker.
Как мы обеспечиваем exactly-once-семантику при зеркалировании?
Данные зеркалируются партиция в партицию. Во время зеркалирования мы раз в 60 секунд сохраняем по каждой партиции два числа: оффсет записи в исходной партиции и оффсет записи в отзеркалированной партиции. Если во время записи происходит сбой, мы читаем сохраненное состояние и реальные размеры в записях исходной и отзеркалированной партиции и по этим числам определяем точно, откуда надо читать исходную партицию.
Архитектура поставки данных с учетом междатацентровости
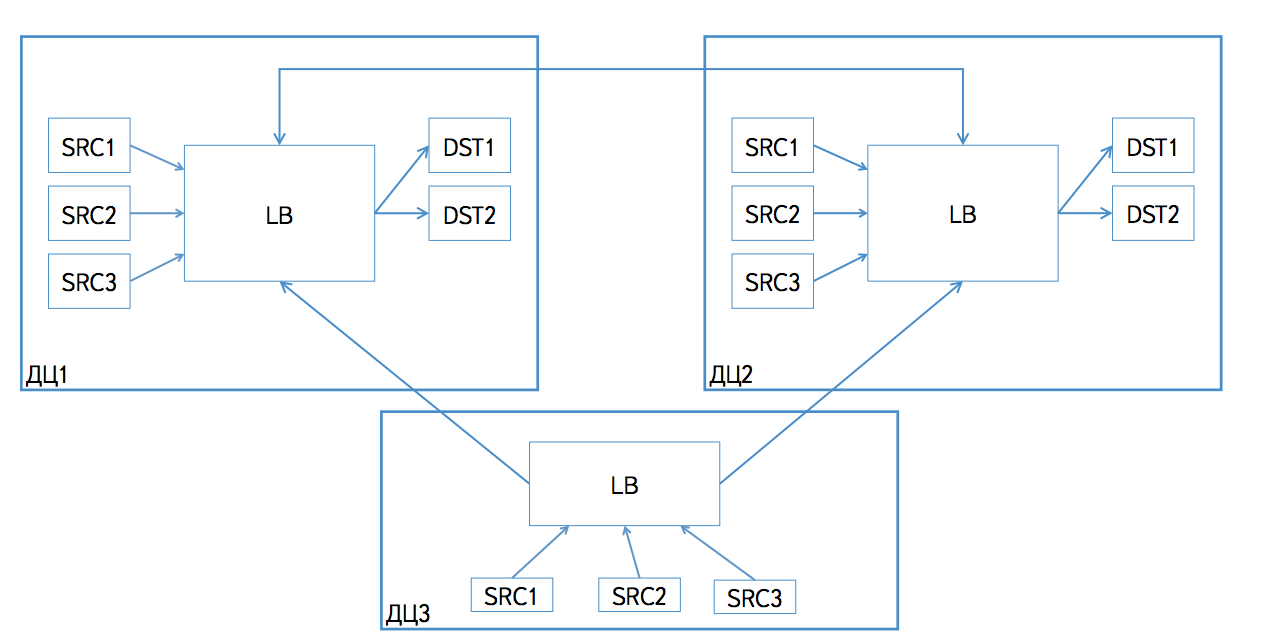
Источники данных ничего не знают о топологии инсталляции Logbroker. Logbroker сам направляет запись источника на нужную ноду. Если источник находится в дата-центре, где есть инсталляция Logbroker, то данные будут записаны в неё, в другие дата-центры данные попадут с помощью зеркалирования.
Существует несколько сценариев получения данных из Logbroker. Во-первых, у есть разделение по типу поставки: push или pull. То есть Logbroker может сам отправлять данные потребителям (push-поставка), либо потребитель может сам читать данные по http-протоколу (pull-поставка). В обоих случаях мы поддерживаем два сценария получения данных.
Если потребитель находится полностью в одном дата-центре с одним из кластеров Logbroker, то он читает все топики.
Если потребитель находится в дата-центре, в котором Logbroker не представлен, либо если потребитель размазан по нескольким дата-центрам, то из каждого дата-центра он читает только топики с префиксом дата-центра. Например, если читаем из кластера в дата-центре dc1, то читаем только топики с префиксом dc1.
На первый взгляд кажется, что можно читать все топики из одного дата-центра, а в случае его отключения переключаться на чтение тех же топиков в другой дата-центр. На самом деле это не так. Дело в том, что у сообщений в партициях с одним именем на разных кластерах Kafka в разных дата-центрах будут разные офсеты. Связано это с тем, что кластеры могли быть запущены в разное время и запуск зеркалирования проводился в разное время. Наш зеркальщик гарантирует только неизменность порядка сообщений. Читатель из Logbroker оперирует оффсетами партиций, а так как в другом дата-центре они будут другими, то при переключении читатель либо получит дубликаты, либо недополучит данные.
На самом деле во многих случаях такое переключение чтения будет бесполезно. Например, мы читали в дата-центре dc1 топик с префиксом dc1. Вдруг дата-центр dc1 упал, и мы хотим переключиться на dc2, чтобы продолжить читать топик с префиксом dc1. Но так как дата-центр dc1 упал, то и топик с данным префиксом не пишется и новых данных в дата-центре dc2 просто не будет.
Зачем вообще нужна такая сущность, как Logbroker? Почему нельзя сразу с источников рассылать данные всем потребителям?
Logbroker существенно упрощает схему поставки данных. В его отсутствие пришлось бы делать сложный клиент, который умел бы отправлять данные сразу в несколько мест. Сложный клиент приходилось бы постоянно обновлять для исправления багов и добавления поддержки новых потребителей. Сейчас мы имеем очень простой легкий клиент, написанный на C. Этот клиент очень редко обновляется. Например, на некоторых наших источниках до сих пор стоят старые сборки 2012 года, которые раньше работали с Архивом, а сейчас работают с Logbroker.
Централизованная поставка также существенно экономит междатацентровый трафик:
В случае сбоев на кластерах-приемниках мы можем быстро и эффективно дозалить недостающие данные Logbroker. Делать ту же операцию на самих источниках было бы существенно сложнее.
Где сейчас в Яндексе используется Logbroker
Сейчас Logbroker используется для поставки логов с серверов. Общий объем входящего трафика в среднем 60 терабайт в день. Исходящего – в 3-4 раза больше (зависит от конкретного дата-центра). Потребителями логов являются в основном кластеры Статистики и Поиска. Также имеется ряд более мелких потребителей, которые получают небольшой поток только нужных им логов.
Сейчас мы ведем работу по внедрению Logbroker в качестве транспортной шины внутри компании для прокачивания не только логов, но и бинарных данных.
В процессе разработки мы сталкивались с трудностями, связанными в основном с сыростью Kafka. В частности, очень сырым оказался клиентский код. Высокоуровневая библиотека для записи и чтения данных могла залипнуть на какое-то время, а также заблокировать процесс. Изначально мы запустились с таким кодом, но потом в процессе разработки написали свой асинхронный клиент для Kafka. Сейчас думаем об оформлении этого клиента в виде opensource-библиотеки.
В отличие от клиентской, серверная часть Kafka написана очень качественно и используется нами практически без изменений. Мы применяем небольшие патчи, которые время от времени стараемся отослать разработчикам.
