OpenStack нужна не одна «шляпа»
6 мин
Автор: Ник Чейс
Похоже, становится модным ругать OpenStack. Это естественно, каждая технология испытывает болезнь роста, когда она уже достаточно продвинутая, чтобы люди захотели ее использовать, но не настолько продвинутая, чтобы оправдать 100% ожиданий всех и каждого.
Похоже, становится модным ругать OpenStack. Это естественно, каждая технология испытывает болезнь роста, когда она уже достаточно продвинутая, чтобы люди захотели ее использовать, но не настолько продвинутая, чтобы оправдать 100% ожиданий всех и каждого.

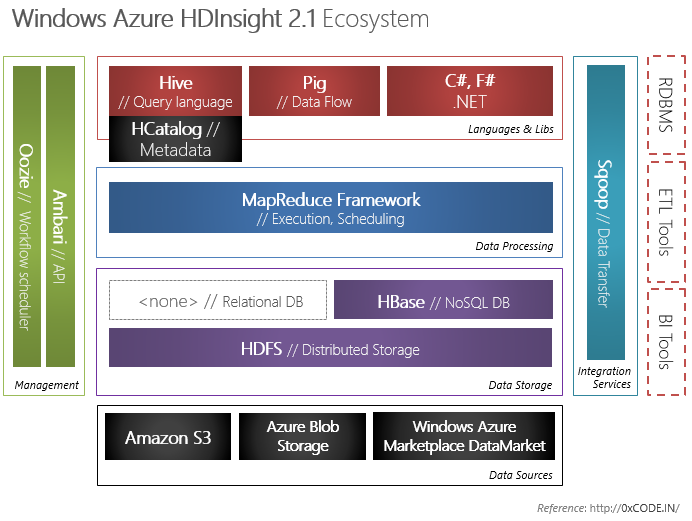
 Сегодня в компаниях информация выстраивается и хранится, как правило, несколькими способами и на нескольких платформах. Данные существуют в неструктурированном, неоптимизированном виде, что не позволяет извлекать из них информацию, необходимую для принятия стратегически важных решений. Роль Больших данных в этом сценарии заключается в возможности собирать такую информацию из различных входных данных, структурировать ее и выдавать данные для использования при анализе, при принятии решений и при работе со средствами предиктивной аналитики.
Сегодня в компаниях информация выстраивается и хранится, как правило, несколькими способами и на нескольких платформах. Данные существуют в неструктурированном, неоптимизированном виде, что не позволяет извлекать из них информацию, необходимую для принятия стратегически важных решений. Роль Больших данных в этом сценарии заключается в возможности собирать такую информацию из различных входных данных, структурировать ее и выдавать данные для использования при анализе, при принятии решений и при работе со средствами предиктивной аналитики.