
Генетический алгоритм. Просто о сложном. Рассказ Марка Андреева
7 мин

В последнее время все больше «ходят» разговоры про новомодные алгоритмы, такие как нейронные сети и генетический алгоритм. Сегодня я расскажу про генетические алгоритмы, но давайте на этот раз постараемся обойтись без заумных определений и сложных терминах.
Как сказал один из великих ученных: «Если вы не можете объяснить свою теорию своей жене, ваша теория ничего не стоит!» Так давайте попытаемся во всем разобраться по порядку.
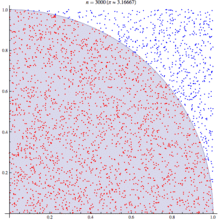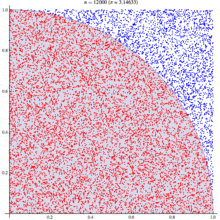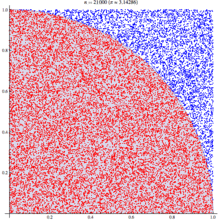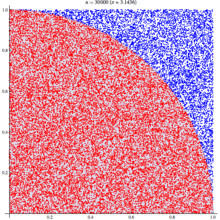



 Иногда возникают такие ситуации, когда нужно прочитать QR код, а смартфона под рукой нет. Что же делать? В голову приходит лишь попробовать прочитать вручную. Если кто-нибудь сталкивался с такими ситуациями или кому просто интересно как же читается QR код машинами, то данная статья поможет вам разобраться в этой проблеме.
Иногда возникают такие ситуации, когда нужно прочитать QR код, а смартфона под рукой нет. Что же делать? В голову приходит лишь попробовать прочитать вручную. Если кто-нибудь сталкивался с такими ситуациями или кому просто интересно как же читается QR код машинами, то данная статья поможет вам разобраться в этой проблеме.  . Видите? :) Тогда она же, увеличенная в 10 раз:
. Видите? :) Тогда она же, увеличенная в 10 раз:
