
Победителем в конкурсе чатботов 2010 года и обладателем
премии Лёбнера стал чатбот
Suzette. Как всегда, соревнование проходило в формате стандартного текстового теста Тьюринга. Судьи должны были вести беседу, не видя собеседников, а затем огласить своё мнение: кто из них является чатботом, а кто — человеком, а также проставить оценки каждой программе.
В этом году лучший чатбот даже смог обмануть одного судью, который принял его за человека.
Судя по всему, качество чатботов улучшается с каждым годом. Например, трёхкратный победитель прошлых лет
A.L.I.C.E уже не особо конкурентоспособен. По
словам автора программы Suzette, его чатбот победил в квалификации с большим отрывом (11 баллов против 7,5 у ближайшего конкурента).

 Оцифровка человеческого мозга, — это, прежде всего, мечта всех и каждого, это панацея от всех проблем человечества, ведь где копия сознания, там и ИИ, а тут на горизонте уже маячит телепортация, отказ от войн, а любой, самый совершенный и гениальный ум можно будет просто копировать и даже не в одном экземпляре. Пожалуй, в этом посте я опущу морально-этические и религиозные вопросы типа существования и сохранности человеческой души при подобных манипуляциях над человеческим же сознанием, а напишу о российском проекте, направленном как раз на создание копии сознания.
Оцифровка человеческого мозга, — это, прежде всего, мечта всех и каждого, это панацея от всех проблем человечества, ведь где копия сознания, там и ИИ, а тут на горизонте уже маячит телепортация, отказ от войн, а любой, самый совершенный и гениальный ум можно будет просто копировать и даже не в одном экземпляре. Пожалуй, в этом посте я опущу морально-этические и религиозные вопросы типа существования и сохранности человеческой души при подобных манипуляциях над человеческим же сознанием, а напишу о российском проекте, направленном как раз на создание копии сознания.
 Jeopardy! — популярное на американском телевидении квиз-шоу (или, по-русски, викторина), в которой участникам необходимо отвечать на вопросы из абсолютно разных областей — точных наук, поп-культуры, истории, литературы и так далее.
Jeopardy! — популярное на американском телевидении квиз-шоу (или, по-русски, викторина), в которой участникам необходимо отвечать на вопросы из абсолютно разных областей — точных наук, поп-культуры, истории, литературы и так далее. 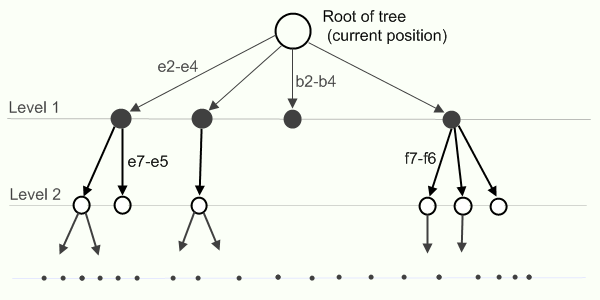
 Многим знакомы фильмы, в которых искуственный интеллект, порожденный человеком, покушался на жизнь или контроль над своим создателем. Данный вывод может быть абсолютно закономерен для ИИ. Мало того, создание ИИ, подобного человеку, невозможно, а точнее сказать глупо, потому как это будет подобно созданию велосипеда на квадратных колесах, взамен известному классическому. Каким именно образом и почему такое возможно, и хочу вам рассказать. А также вы узнаете, почему человечество такое, какое есть.
Многим знакомы фильмы, в которых искуственный интеллект, порожденный человеком, покушался на жизнь или контроль над своим создателем. Данный вывод может быть абсолютно закономерен для ИИ. Мало того, создание ИИ, подобного человеку, невозможно, а точнее сказать глупо, потому как это будет подобно созданию велосипеда на квадратных колесах, взамен известному классическому. Каким именно образом и почему такое возможно, и хочу вам рассказать. А также вы узнаете, почему человечество такое, какое есть.