Scala Moscow User Group, встреча 14 марта 2014
1 мин
В прошлый раз мы провели ознакомительную встречу. Собралось около 25 человек, мы узнали кто в Москве занимается разработкой на Scala и какие есть интересные проекты. Главной темой выбрали курс по реактивному программированию на Coursera, который как раз тогда подходил к концу.
В этот раз мы соберёмся послушать и обсудить два доклада:
Доклады будут отнюдь не вводные, чуть глубже затронут тему функционального программирования и предназначены на подготовленных слушателей. После за чаем обсудим доклады, интересующие темы, а также планы на будущее.

В этот раз мы соберёмся послушать и обсудить два доклада:
- Алексей Иванов приедет из Питера и расскажет доклад «Monadic Bakery with Spray and Scalaz»,
про то почему Spray и ScalaZ — не страшные звери, а хорошие друзья; - Владимир Успенский расскажет про теорию типов и тем, как она связана с обычной разработкой в докладе:
«Теория типов, или как мы занимаемся математикой, программируя на Scala».
Доклады будут отнюдь не вводные, чуть глубже затронут тему функционального программирования и предназначены на подготовленных слушателей. После за чаем обсудим доклады, интересующие темы, а также планы на будущее.

 Доброй ночи, Хабр! Мы продолжаем изучение Erlang для самых маленьких.
Доброй ночи, Хабр! Мы продолжаем изучение Erlang для самых маленьких.  А сейчас нужно обязательно дунуть, потому что если не дунуть, то ничего не получится.
А сейчас нужно обязательно дунуть, потому что если не дунуть, то ничего не получится.

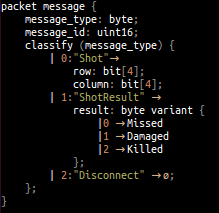 Всем программистам рано или поздно приходится передавать данные. Ни для кого не секрет, что библиотек сериализации в Java существует примерно >9000, а в C++ они вроде и есть, а вроде их и нет. К счастью для большинства, несколько лет назад появился Google Protobuf, который принёс достаточно удобный способ определять структуры данных и быстро завоевал всенародную любовь. Это была фактически первая, доступная широким массам библиотека, позволяющая гонять по сети готовые структуры данных, не связываясь при этом с чем-то вроде XML. На дворе был 2008 год.
Всем программистам рано или поздно приходится передавать данные. Ни для кого не секрет, что библиотек сериализации в Java существует примерно >9000, а в C++ они вроде и есть, а вроде их и нет. К счастью для большинства, несколько лет назад появился Google Protobuf, который принёс достаточно удобный способ определять структуры данных и быстро завоевал всенародную любовь. Это была фактически первая, доступная широким массам библиотека, позволяющая гонять по сети готовые структуры данных, не связываясь при этом с чем-то вроде XML. На дворе был 2008 год. Добрый день, сегодня хотелось бы рассказать, как наша команда работает с базами данных. У нас в компании в основном используется Oracle и в нашей команде много людей, кто умеет хорошо его готовить. Нам изначально хотелось получить полный доступ к его возможностям: иерархическим запросам, аналитическим функциям, передаче объектов и коллекций, как параметров запросов, и, может быть, если не будет другого способа — хинтам. Модель у нас не очень сложная, поэтому сознательно отказались от ORM.
Добрый день, сегодня хотелось бы рассказать, как наша команда работает с базами данных. У нас в компании в основном используется Oracle и в нашей команде много людей, кто умеет хорошо его готовить. Нам изначально хотелось получить полный доступ к его возможностям: иерархическим запросам, аналитическим функциям, передаче объектов и коллекций, как параметров запросов, и, может быть, если не будет другого способа — хинтам. Модель у нас не очень сложная, поэтому сознательно отказались от ORM.