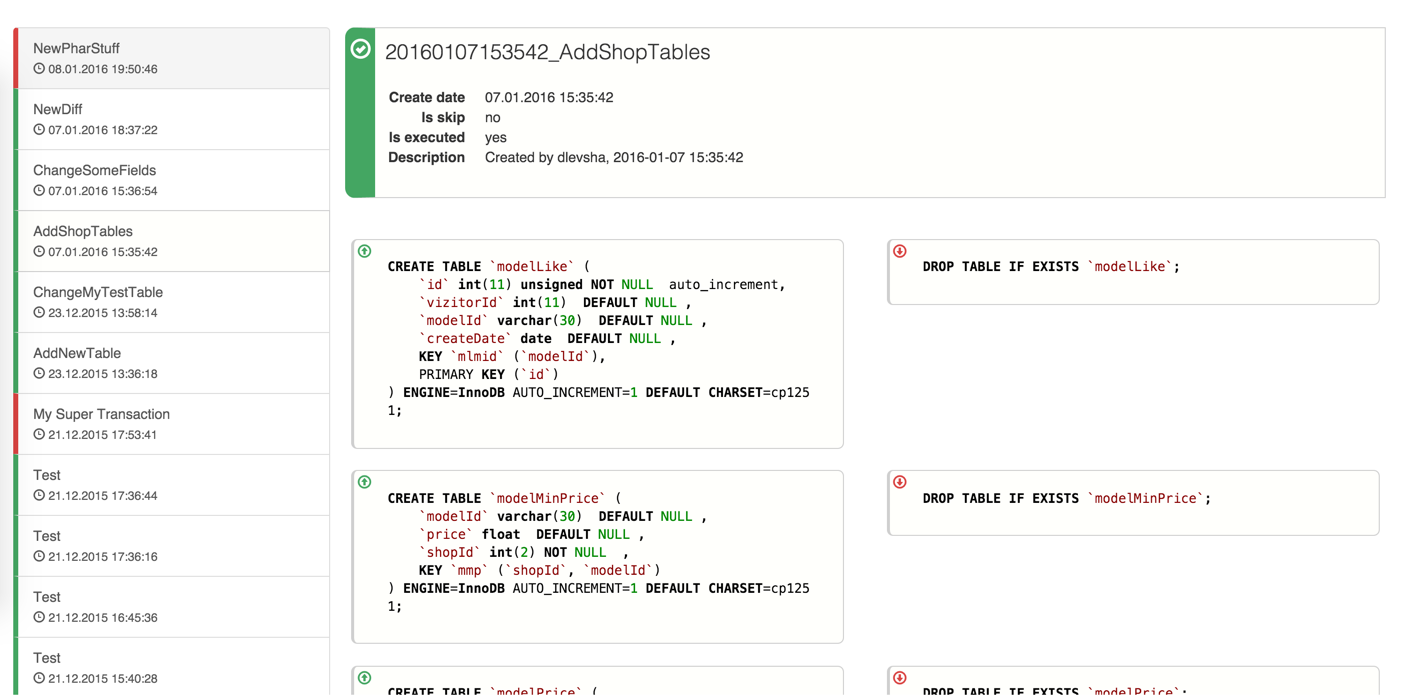
Здравствуйте. В этой статье хотел бы разобрать кейс создания резервных копий. Я опишу свои методы, и прошу Вас поделиться опытом о том, как Вы решали данные задачи. Я опишу самые простые технологии, но они эффективны и выполняют поставленную задачу…
В основном статья будет полезна начинающим системным администраторам (и, конечно, не только в вузах), но прошу опытных специалистов поправить меня, если есть неточности, а может подскажете другие более лучшие решения. Буду благодарен всем, кто проявит интерес к статье.
Но начну с такой информации…
Статья 274 УК РФ. Нарушение правил эксплуатации средств хранения, обработки или передачи компьютерной информации и информационно‑телекоммуникационных сетей
1. Нарушение правил эксплуатации средств хранения, обработки или передачи охраняемой компьютерной информации либо информационно‑телекоммуникационных сетей и оконечного оборудования, а также правил доступа к информационно‑телекоммуникационным сетям, повлекшее уничтожение, блокирование, модификацию либо копирование компьютерной информации, причинившее крупный ущерб, — наказывается штрафом в размере до пятисот тысяч рублей или в размере заработной платы или иного дохода, осужденного за период до восемнадцати месяцев, либо исправительными работами на срок от шести месяцев до одного года, либо ограничением свободы на срок до двух лет, либо принудительными работами на срок до двух лет, либо лишением свободы на тот же срок.
2. Деяние, предусмотренное частью первой настоящей статьи, если оно повлекло тяжкие последствия или создало угрозу их наступления, — наказывается принудительными работами на срок до пяти лет либо лишением свободы на тот же срок.