«Идеальный» кластер. Часть 3.1 Внедрение MySQL Multi-Master кластера
16 мин
Туториал
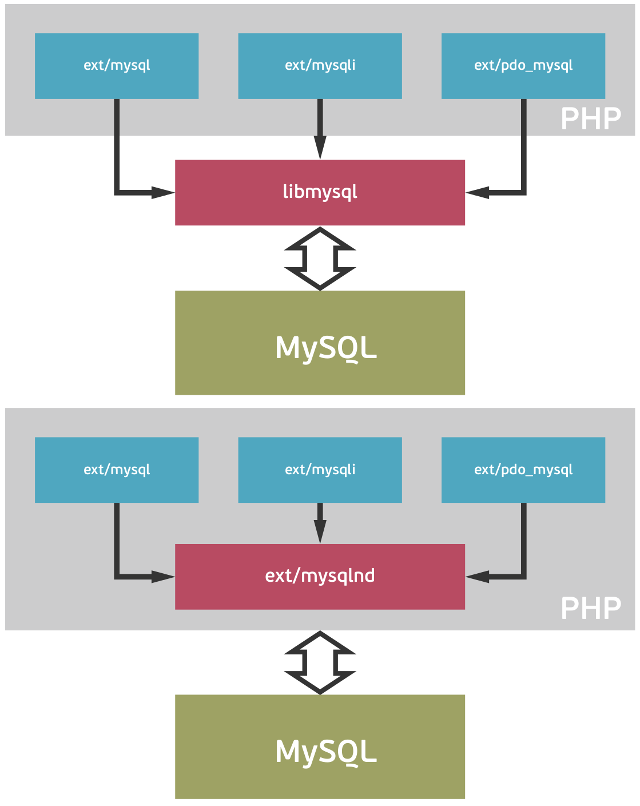
В продолжение цикла статей об «Идеальном» кластере хочу поделиться моим опытом развертывания и настройки Multi-Master кластеров MySQL.

mysqld_safe --defaults-file=...my2.cnf... &


mysql> CREATE TABLE enums(a ENUM('c', 'a', 'b'), b INT, KEY(a));
Query OK, 0 rows affected (0.36 sec)
mysql> INSERT INTO enums VALUES('a', 1), ('b', 1), ('c', 1);
Query OK, 3 rows affected (0.05 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> SELECT MIN(a), MAX(a) FROM enums;
+--------+--------+
| MIN(a) | MAX(a) |
+--------+--------+
| c | b |
+--------+--------+
1 row in set (0.00 sec)
mysql> SELECT MIN(a), MAX(a) FROM enums WHERE b = 1;
+--------+--------+
| MIN(a) | MAX(a) |
+--------+--------+
| a | c |
+--------+--------+
1 row in set (0.00 sec)
mysql> (SELECT * FROM moo LIMIT 1) LIMIT 2;
+------+
| a |
+------+
| 1 |
| 2 |
+------+
2 rows in set (0.00 sec)
mysql> (SELECT * FROM moo UNION ALL SELECT * FROM hru) LIMIT 2;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'UNION ALL SELECT * FROM hru) LIMIT 2' at line 1

 Введение в HandlerSocket: описание протокола и расширения php-handlersocket; То, что вы хотели знать о HandlerSocket, но не смогли нагуглить;
Введение в HandlerSocket: описание протокола и расширения php-handlersocket; То, что вы хотели знать о HandlerSocket, но не смогли нагуглить; Первый опыт работы с Handler Socket & php_handlersocket.
Первый опыт работы с Handler Socket & php_handlersocket.
example.com/index.asp?language=[lang_name]#[чтотоеще]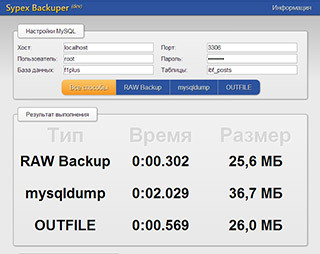 Бэкапы MySQL бывают 2 основных разновидностей это:
Бэкапы MySQL бывают 2 основных разновидностей это: