Масштабируя до 100 миллионов: архитектура, определяемая уровнем сервиса
4 мин
Это третья часть цикла «Масштабирование Wix до 100 миллионов пользователей». Вступление и второй пост.
Wix начинался с одного сервера, который обеспечивал весь функционал: регистрацию пользователей, редактирование веб-сайтов, обслуживание опубликованных веб-сайтов и загрузку изображений. В свое время этот единственный сервер был правильным решением, поскольку он позволил нам быстро расти и применять гибкие методы разработки. Однако к 2008 году начались периодически повторяющиеся проблемы с развертыванием, которые вели к незапланированным простоям как в создании новых сайтов, так и в обслуживании уже созданных.
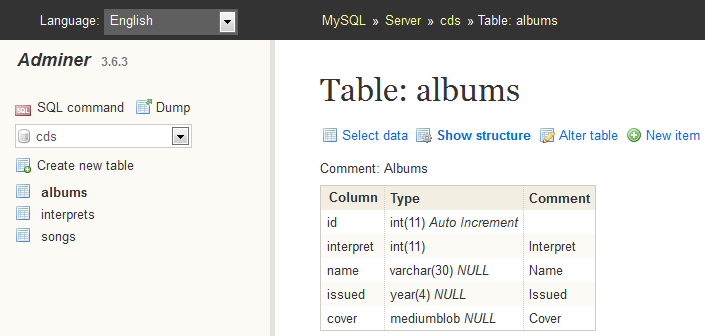
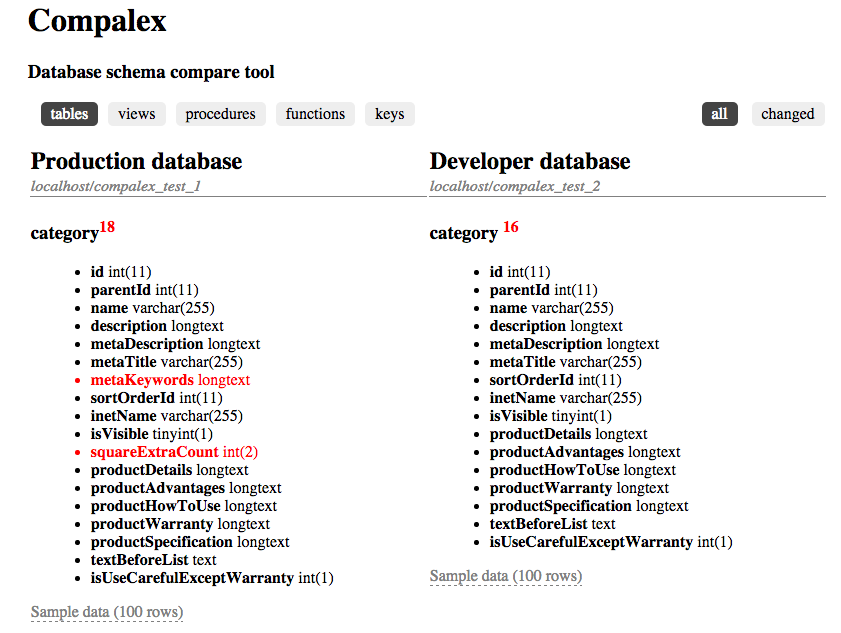
Развертывание новой версии нашей системы в некоторых случаях требовало изменения схемы MySQL. Поскольку Hibernate не прощает несовпадений между ожидаемой им схемой и реальной схемой базы данных (БД), мы использовали общую практику развертывания программного обеспечения: плановая двухчасовая остановка в период наименьшего трафика (полночь в США на выходных). За время этой плановой остановки мы должны были остановить сервис, выключить сервер, внести изменения в схему MySQL, развернуть новую версию и перезапустить сервер.
Эта плановая двухчасовая остановка часто превращалась в нечто более сложное из-за проблем, которые могли случаться при развертывании. В некоторых случаях внесение изменений в схему MySQL занимало заметно больше времени, чем планировалось (изменение больших таблиц, перестройка индексов, отмена ограничений на миграцию данных и т.д.). Иногда после изменения схемы и попытки перезапустить сервер он не запускался из-за каких-то непредусмотренных проблем с развертыванием, конфигурацией или схемой, которые не давали ему работать. А в некоторых случаях новая версия нашего программного обеспечения оказывалась неработоспособной, поэтому для восстановления сервиса нам приходилось снова менять схему MySQL (чтобы привести ее в соответствие с предыдущей версией) и вновь разворачивать предыдущую версию системы.
Wix начинался с одного сервера, который обеспечивал весь функционал: регистрацию пользователей, редактирование веб-сайтов, обслуживание опубликованных веб-сайтов и загрузку изображений. В свое время этот единственный сервер был правильным решением, поскольку он позволил нам быстро расти и применять гибкие методы разработки. Однако к 2008 году начались периодически повторяющиеся проблемы с развертыванием, которые вели к незапланированным простоям как в создании новых сайтов, так и в обслуживании уже созданных.
Развертывание новой версии нашей системы в некоторых случаях требовало изменения схемы MySQL. Поскольку Hibernate не прощает несовпадений между ожидаемой им схемой и реальной схемой базы данных (БД), мы использовали общую практику развертывания программного обеспечения: плановая двухчасовая остановка в период наименьшего трафика (полночь в США на выходных). За время этой плановой остановки мы должны были остановить сервис, выключить сервер, внести изменения в схему MySQL, развернуть новую версию и перезапустить сервер.
Эта плановая двухчасовая остановка часто превращалась в нечто более сложное из-за проблем, которые могли случаться при развертывании. В некоторых случаях внесение изменений в схему MySQL занимало заметно больше времени, чем планировалось (изменение больших таблиц, перестройка индексов, отмена ограничений на миграцию данных и т.д.). Иногда после изменения схемы и попытки перезапустить сервер он не запускался из-за каких-то непредусмотренных проблем с развертыванием, конфигурацией или схемой, которые не давали ему работать. А в некоторых случаях новая версия нашего программного обеспечения оказывалась неработоспособной, поэтому для восстановления сервиса нам приходилось снова менять схему MySQL (чтобы привести ее в соответствие с предыдущей версией) и вновь разворачивать предыдущую версию системы.