Как получить оффер в день собеседования. Часть вторая, для PHP-разработчика
4 мин

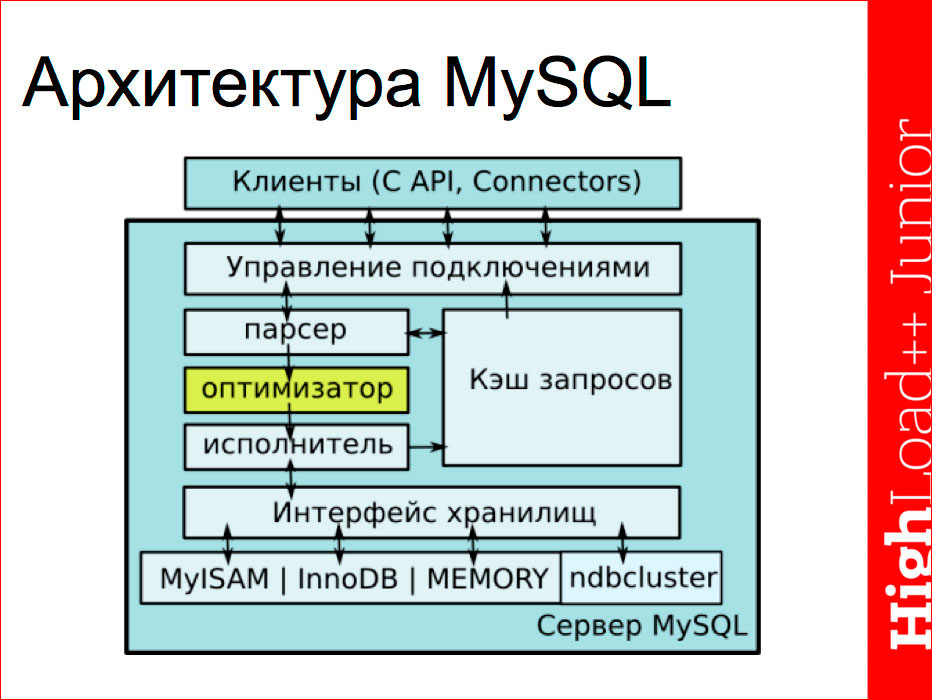
Привет, Хабр! Меня зовут Павел Мурзаков, я – PHP-тимлид в Badoo, и сегодня я расскажу вам о новой возможности получить предложение по работе в Лондоне за один день. Как вы, возможно, знаете, недавно в Москве прошло рекрутинговое мероприятие Badoo по поиску мобильных разработчиков. Оно оказалось очень успешным – мы предложили работу в Лондоне восьми ребятам и надеемся скоро увидеть их в составе нашей мобильной команды.
И, чтобы не отставать от наших iOS- и Android-команд (ведь их теперь на восемь человек больше!), мы решили ответить достойно и провести аналогичное мероприятие, на котором рассчитываем найти server-side-коллег нашим новым мобильным разработчикам!
 17 июня в Москве, Измайлово пройдет конференция
17 июня в Москве, Измайлово пройдет конференция 

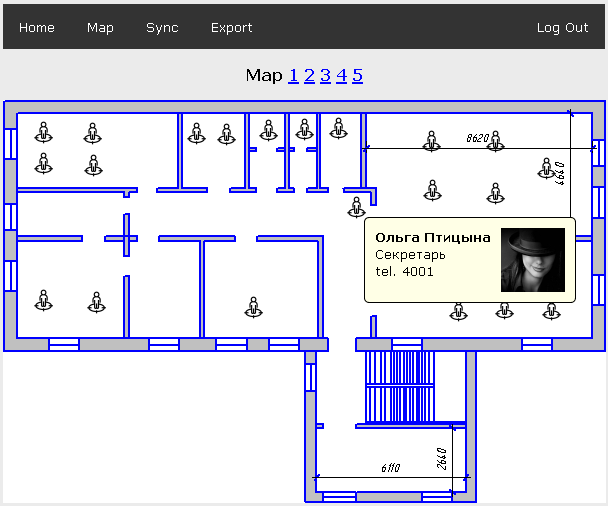
 В этой статье мы рассмотрим способы создания поиска по базе туров (тур из себя представляет набор из отеля и перелета) и рассмотрим две опции —
В этой статье мы рассмотрим способы создания поиска по базе туров (тур из себя представляет набор из отеля и перелета) и рассмотрим две опции —  В далекие времена, до фейсбука и гугла, когда 32 мегабайта RAM было дофига как много, security была тоже… немножко наивной. Вирусы выдвигали лоток CD-ROM-а и играли Янки Дудль. Статья «Smashing the stack for fun and profit» уже была задумана, но еще не написана. Все пользовались telnet и ftp, и только особо продвинутые параноики знали про ssh.
В далекие времена, до фейсбука и гугла, когда 32 мегабайта RAM было дофига как много, security была тоже… немножко наивной. Вирусы выдвигали лоток CD-ROM-а и играли Янки Дудль. Статья «Smashing the stack for fun and profit» уже была задумана, но еще не написана. Все пользовались telnet и ftp, и только особо продвинутые параноики знали про ssh.
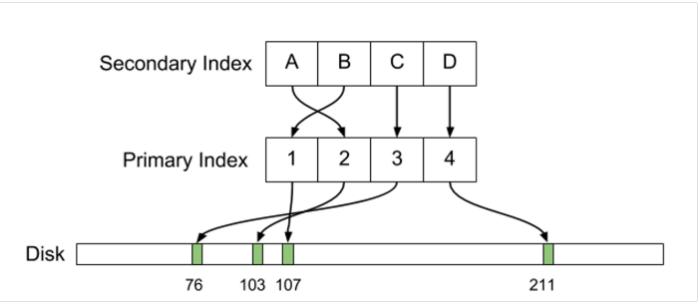




 В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.
В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.