
SQL-доступ к NoSQL-данным: реализация SQL-процедуры в Caché с динамическим определением возвращаемых метаданных
13 мин
Как известно, Caché можно использовать как реляционную СУБД, в том числе через JDBC/ODBC драйверы, с возможностью исполнения произвольных SQL-запросов и вызова SQL-процедур.
Известно также, что все данные в Caché хранятся в многомерных разреженных массивах — глобалах. Это позволяет в случае недостаточной производительности отдельно взятой SQL-процедуры не использовать стандартный CachéSQL-движок, а переписать ее код исполнения на языке серверной бизнес-логики Caché ObjectScript (COS), в котором можно реализовать оптимальный алгоритм выполнения SQL-процедуры, часто используя более оптимальные NoSQL-структуры данных (глобалы).
Однако в стандартной библиотеке классов Caché существует одно ограничение: для SQL-процедур, в которых отбор выполняется самописным COS-кодом, необходимо определять набор возвращаемых полей на этапе компиляции — т.е. нет возможности динамически задать метаданные для SQL-процедуры, работающей с NoSQL структурами.
О том, как снять это ограничение, рассказано под катом.
Известно также, что все данные в Caché хранятся в многомерных разреженных массивах — глобалах. Это позволяет в случае недостаточной производительности отдельно взятой SQL-процедуры не использовать стандартный CachéSQL-движок, а переписать ее код исполнения на языке серверной бизнес-логики Caché ObjectScript (COS), в котором можно реализовать оптимальный алгоритм выполнения SQL-процедуры, часто используя более оптимальные NoSQL-структуры данных (глобалы).
Однако в стандартной библиотеке классов Caché существует одно ограничение: для SQL-процедур, в которых отбор выполняется самописным COS-кодом, необходимо определять набор возвращаемых полей на этапе компиляции — т.е. нет возможности динамически задать метаданные для SQL-процедуры, работающей с NoSQL структурами.
О том, как снять это ограничение, рассказано под катом.


 MongoDB — замечательная база данных, которая становится все популярнее в последнее время. Все больше людей с SQL опытом начинают её использовать, и один и первых вопросов, который у них возникает:
MongoDB — замечательная база данных, которая становится все популярнее в последнее время. Все больше людей с SQL опытом начинают её использовать, и один и первых вопросов, который у них возникает: 

 В википедии написано, что ZooKeeper — распределенный сервис конфигурирования и синхронизации, не знаю как вам, но мне данное определение мало что раскрывает. Оглядываясь на свой опыт, могу дать альтернативное определение ZooKeeper, это распределенное key/value хранилище со следующими свойствами:
В википедии написано, что ZooKeeper — распределенный сервис конфигурирования и синхронизации, не знаю как вам, но мне данное определение мало что раскрывает. Оглядываясь на свой опыт, могу дать альтернативное определение ZooKeeper, это распределенное key/value хранилище со следующими свойствами:
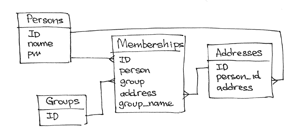 Одна из самых разрекламированных фич MongoDB — это гибкость. Я сам не раз подчеркивал это в бесчисленных разговорах о MongoDB. Однако, гибкость — это палка о двух концах: большая гибкость подразумевает более широкий выбор решений для моделирования данных. Тем не менее, мне нравится гибкость, которую предоставляет MongoDB, просто нужно иметь ввиду некоторые рекомендации, прежде чем начать разрабатывать модель данных.
Одна из самых разрекламированных фич MongoDB — это гибкость. Я сам не раз подчеркивал это в бесчисленных разговорах о MongoDB. Однако, гибкость — это палка о двух концах: большая гибкость подразумевает более широкий выбор решений для моделирования данных. Тем не менее, мне нравится гибкость, которую предоставляет MongoDB, просто нужно иметь ввиду некоторые рекомендации, прежде чем начать разрабатывать модель данных.