
Что такое CouchDB для вас? Вероятно любой, кто хоть немного интересуется популярной нынче темой NoSQL, прекрасно знает общие детали: это такая симпатичная игрушка с map/reduce-запросами, которые пишутся на JavaScript, с которой можно работать, гоняя JSON по HTTP-протоколу, а также не исключено, что слышали, что она fault-tolerant, тобишь не ломается вообще. Дальше этого обычно дело не идёт, в результате CouchDB отправляется в delicious в общую кучу со всякими MongoDB, Cassandra, Hadoop и т.п.
Примерно такого мнения придерживался и я вплоть до недавнего времени, пока не возникла острая необходимость переосмыслить архитектуру текущего проекта (упёршегося лбом в свою реляционную БД) и пересесть на документную базу данных, которая бы умела map/reduce. После того, как более пристально взгялнул на CouchDB, я понял, что он уникален в своём классе, его не следует ставить в один ряд с упомянутыми продуктами. Идеи, которые заложены в CouchDB настолько концептуальны, что способны в корне перевернуть представление о разработке веб-приложений.
О том, что же меня так впечатлило, постараюсь рассказать под катом.

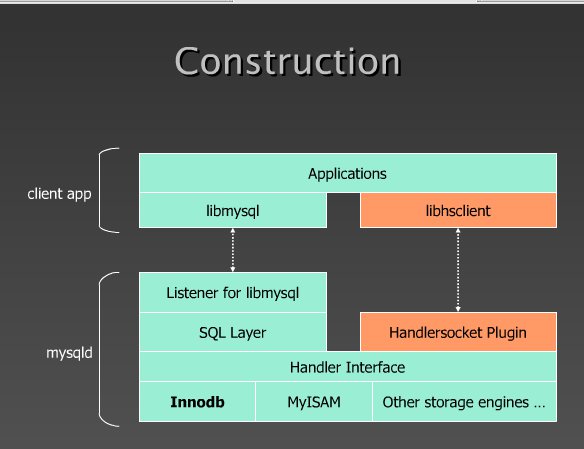

 Про MongoDb было рассказано не так много, но относительно полно, например
Про MongoDb было рассказано не так много, но относительно полно, например