– А ларчик просто открывался.
И.А. Крылов
О чём эта статья
В настоящей работе описываются способы автоматической организации нумерованных объектов при написании статей, рефератов, докладов, диссертаций и пр. При написании подобного рода материалов неизбежно возникает необходимость нумеровать те или иные объекты, например, формулы или пункты в списке используемой литературы. При этом многие авторы пользуются при написании текстовым редактором Microsoft Word.
В случае тривиальной «ручной» организации, при которой каждый номер прописывается непосредственно руками (обычно, в самом конце, когда текст полностью готов), автор работы может ошибиться в каком-либо номере, и все дальнейшие номера окажутся неверными. Более того, после рецензии те или иные части работы могут быть вставлены в текст или убраны из него. Последнее, зачастую, требует полной перенумерации объектов в документе. Таким образом, цель настоящей статьи состоит в доведении до читателя способов автоматической организации нумерации объектов, позволяющих избежать вышеописанные ситуации.
Предупреждение: в данную статью вошли лишь те приёмы, с которыми автор столкнулся при написании кандидатской диссертации. Описываемые способы организации нумерованных объектов не претендуют на единственность, полноту и оптимальность. Имеются другие интересные способы,
например, в TeX. Несомненно, читатель сможет найти и иные способы достижения сформулированной цели. В любом случае, ознакомиться с подходами автора (хотя бы на досуге) следует любому заинтересованному читателю.
Основы работы с полями MS Word
В данном разделе описываются основные поля текстового редактора MS Word, необходимые для организации списков и ссылок на них, а также методы работы с ними.
Поле MS Word – это объект, принимающий то или иное значение в зависимости от ключевых слов и параметров этого поля. Для вставки поля в текст необходимо нажать сочетание клавиш Ctrl + F9 или выбрать соответствующее меню на ленте.
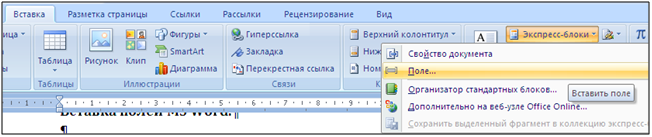
После вставки поля в тексте появятся
серые фигурные скобки.