Сегодня пришла новость о том, что SAP приобретает Sybase за 5.8 миллиардов долларов (новость
на Хабре, статья на
Yahoo Finance, оригинальный пресс-релиз
тут).
Это достаточно знаковая сделка, хотя на первый взгляд может показаться не так — Sybase, по различным оценкам, владеет 2-3% рынка баз данных, за что отдавать 6 миллиардов (тем более в текущей экономической ситуации)? Конечно, статистика о долях рынка вообще вещь лукавая, но факт есть факт — сейчас не лучшие времена Sybase.
В то же время, Sybase является носителем того самого «сокровенного» знания о реляционных базах данных. Основы реляционных СУБД и практические удачные реализации устоялись за последние 20 лет, и основные изменения в СУБД за последнее десятилетие связаны с попытками по максимуму использовать вычислительные мощности и решить, наконец, проблему горизонтального масштабирования.
Основы же были и остаются неизменными, и Sybase обладает большим опытом в развитии ядра.
Уместно вспомнить, что именно на кодовой базе Sybase были основаны первые версии MSSQL, и что именно Sybase одним из первых начал активно продвигать идею хранилищ данных.
И сейчас мы видим, как компания, производящая ERP, приобретает компанию, производящую СУБД и средства data warehousing. Ранее эта же компания приобрела Business Objects, производителя Crystal Reports.
Что же за этим стоит?

 В продолжение сегодняшнего топика
В продолжение сегодняшнего топика 
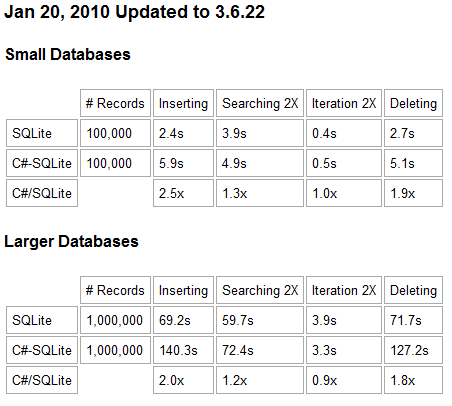
 Как-то в поисках бесплатного редактора для работы с SQL Server'ом наткнулся я на неплохую с моей точки зрения программу DBOctopus. Проект не так давно появился на свет, поэтому я не ожидал увидеть нечто сверхъестественное. Но надо сказать, я был приятно удивлен. Конечно многого еще не хватает, кое-что неудобно, но из плюсов значительных для меня могу отметить упомянутое в теме интелектуальное завершение кода.
Как-то в поисках бесплатного редактора для работы с SQL Server'ом наткнулся я на неплохую с моей точки зрения программу DBOctopus. Проект не так давно появился на свет, поэтому я не ожидал увидеть нечто сверхъестественное. Но надо сказать, я был приятно удивлен. Конечно многого еще не хватает, кое-что неудобно, но из плюсов значительных для меня могу отметить упомянутое в теме интелектуальное завершение кода. 

")

