Базы данных изображений могут быть очень большими и содержат сотни тысяч и даже миллионы изображений. В большинстве случаев эти базы проиндексированы только по ключевым словам. Эти ключевые слова вносит в базу оператор, который также распределяет все изображения по категориям. Но изображения могут быть найдены в базе и на основе собственного содержания. Под содержанием мы можем понимать цвета и их распределение, объекты на изображении и их пространственное положение и т.д. В настоящее время алгоритмы сегментации и распознавания развиты недостаточно хорошо, тем не менее, сейчас уже существует несколько систем (в том числе коммерческих) для поиска изображений на основе их содержания.
Для работы с базой изображений желательно иметь некоторый способ поиска изображений, который был бы удобнее и эффективнее, чем непосредственный просмотр всей базы. Большинство компаний выполняет всего два этапа обработки: отбор изображений, для включения в базу и классификация изображений посредством назначения им ключевых слов. Интернет-поисковики обычно получают ключевые слова автоматически из подписей к картинкам. С помощью обычных баз данных изображения можно находить на основе их текстовых атрибутов. При обычном поиске этими атрибутами могут быть категории, имена присутствующих на изображении людей, а также дата создания изображения. Для ускорения поиска содержимое базы может быть проиндексировано по всем этим полям. Тогда для поиска изображений можно будет воспользоваться языком SQL. Например, запрос:
SELECT * FROM IMAGEBD
WHERE CATEGORY=”МЭИ”
мог бы найти и вернуть все изображения из базы на которых изображён МЭИ. Но на самом деле всё не так просто. Такой тип поиска имеет ряд серьёзных ограничений. Назначение ключевых слов человеком является трудоёмкой задачей. Но, что гораздо хуже, эта задача допускает неоднозначное выполнение. Из-за этого некоторые из найденных изображений могут весьма и весьма сильно отличаться от ожиданий пользователя. На рисунке показана выдача google по запросу «МЭИ».

Приняв, как факт, что использование ключевых слов не обеспечивает достаточной эффективности, мы рассмотрим ряд других методов поиска изображений.
Начнём с поиска по образцу. Вместо того, чтобы указывать ключевые слова, пользователь мог бы предъявить системе образец изображения, или нарисовать эскиз. Затем наша система поиска должна найти похожие изображения или изображения, содержащие требуемые объекты. Для простоты будем считать, что пользователь представляет системе грубый эскиз ожидаемого изображения и некоторый набор ограничений. Если пользователем предоставлен пустой эскиз, то система должна вернуть все изображения, удовлетворяющие ограничениям. Ограничения же логичней всего задавать в виде ключевых слов и различных логических условий, объединяющих их. В самом общем случае, запрос содержит какое-то изображение, которое сравнивается с изображениями из базы согласно применяемой мере расстояния. Если расстояние равно 0, то считается, что изображение точно соответствует запросу. Значения больше 0 соответствуют различной степени сходства рассматриваемого изображения с запросом. Поисковая система должна возвращать изображения, отсортированные по значению расстояния от эскиза.
На рисунке показаны поиска в системе QBIC с применением меры расстояния на основе цветового макета.

Для определения сходства изображения из базы данных с изображением, указанным в запросе, обычно применяется некоторая мера расстояния или характеристики, с помощью которых можно получить численную оценку сходства изображений. Характеристики сходства изображений можно разделить на четыре основные группы:
1. Цветовое сходство
2. Текстурное сходство
3. Сходство формы
4. Сходство объектов и отношений между объектами
Для простоты мы рассмотрим только методы цветового сходства. Характеристики цветового сходства часто выбираются очень простыми. Они позволяют сравнить цветовое содержание одного изображения с цветовым содержанием другого изображения или с параметрами, заданными в запросе. Например, в системе QBIC пользователь может указать процентное соотношение цветов в искомых изображениях. На рисунке показан набор изображений, полученных в результате выполнения запроса с указанием 40% красного, 30% жёлтого и 10% чёрного цвета. Хотя найденные изображения содержат очень похожие цвета, но смысловое содержание этих изображений существенно отличается.

Похожий способ поиска основан на сопоставлении цветовых гистограмм. Меры расстояния на основе цветовой гистограммы должны предусматривать оценку сходства двух различных цветов. Система QBIC определяет расстояние следующим образом:

где h(I), h(Q) – гистограммы изображений I,Q, A – матрица сходства. В матрице сходства элементы, значения которых близки к 1, соответствуют похожим цветам, близкие 0 соответствуют сильно различающимся цветам. Ещё одна возможная мера расстоянии основана на цветовом макете. При формировании запроса пользователю обычно предъявляется пустая сетка. Для каждой клетки пользователь может указать цвет из таблицы.
Характеристики сходства на основе цветового макета, в которых используется закрашенная сетка, требуют меры, которая учитывала бы содержание двух закрашенных сеток. Эта мера должна обеспечивать сравнение каждой клетки сетки, указанной в запросе, соответствующей клеткой сетки произвольного изображения из базы данных. Результаты сравнения всех клеток комбинируются для получения значения расстояния между изображениями:

где C^I (g),C^Q (g) — это цвета клетки g в изображениях I,Q соответственно.
Поиск на основе текстурного сходства, а тем более на основе сходства формы гораздо сложнее, но, стоит сказать, что уже сделаны первые шаги в этом направлении. Например, в системе ART MUSEUM хранятся цветные изображения многих картин. Эти цветные изображения подвергаются обработке для получения промежуточного представления. Предварительная обработка состоит из трёх этапов:
1. Уменьшение изображения до заданного размера и удаление шумов с помощью медианного фильтра.
2. Обнаружение границ. Во-первых, с помощью глобального порога, затем с помощью локального порога. В результате получается очищенное контурное изображение.
3. На очищенном контурном изображении удаляются избыточные контуры. Полученное изображение ещё раз очищается от шумов, и мы получаем требуемое абстрактное представление.
Когда пользователь представляет системе эскиз, над ним производятся такие же операции обработки, и мы получаем линейный эскиз. Алгоритм сопоставления имеет корелляционный характер: изображение делится на клетки, и для каждой клетки вычисляется корреляция с аналогичной клеткой изображения из базы данных. Для надёжности эта процедура выполняется несколько раз для разных значений сдвига линейного эскиза. В большинстве случаев этот метод позволяет успешно находить требуемые изображения.
Осталось только дождаться внедрения таких систем в привычные нам интернет-поисковики, и можно будет сказать, что проблема поиска картинок стала не такой уж и проблемой.
Для работы с базой изображений желательно иметь некоторый способ поиска изображений, который был бы удобнее и эффективнее, чем непосредственный просмотр всей базы. Большинство компаний выполняет всего два этапа обработки: отбор изображений, для включения в базу и классификация изображений посредством назначения им ключевых слов. Интернет-поисковики обычно получают ключевые слова автоматически из подписей к картинкам. С помощью обычных баз данных изображения можно находить на основе их текстовых атрибутов. При обычном поиске этими атрибутами могут быть категории, имена присутствующих на изображении людей, а также дата создания изображения. Для ускорения поиска содержимое базы может быть проиндексировано по всем этим полям. Тогда для поиска изображений можно будет воспользоваться языком SQL. Например, запрос:
SELECT * FROM IMAGEBD
WHERE CATEGORY=”МЭИ”
мог бы найти и вернуть все изображения из базы на которых изображён МЭИ. Но на самом деле всё не так просто. Такой тип поиска имеет ряд серьёзных ограничений. Назначение ключевых слов человеком является трудоёмкой задачей. Но, что гораздо хуже, эта задача допускает неоднозначное выполнение. Из-за этого некоторые из найденных изображений могут весьма и весьма сильно отличаться от ожиданий пользователя. На рисунке показана выдача google по запросу «МЭИ».

Приняв, как факт, что использование ключевых слов не обеспечивает достаточной эффективности, мы рассмотрим ряд других методов поиска изображений.
Начнём с поиска по образцу. Вместо того, чтобы указывать ключевые слова, пользователь мог бы предъявить системе образец изображения, или нарисовать эскиз. Затем наша система поиска должна найти похожие изображения или изображения, содержащие требуемые объекты. Для простоты будем считать, что пользователь представляет системе грубый эскиз ожидаемого изображения и некоторый набор ограничений. Если пользователем предоставлен пустой эскиз, то система должна вернуть все изображения, удовлетворяющие ограничениям. Ограничения же логичней всего задавать в виде ключевых слов и различных логических условий, объединяющих их. В самом общем случае, запрос содержит какое-то изображение, которое сравнивается с изображениями из базы согласно применяемой мере расстояния. Если расстояние равно 0, то считается, что изображение точно соответствует запросу. Значения больше 0 соответствуют различной степени сходства рассматриваемого изображения с запросом. Поисковая система должна возвращать изображения, отсортированные по значению расстояния от эскиза.
На рисунке показаны поиска в системе QBIC с применением меры расстояния на основе цветового макета.

Для определения сходства изображения из базы данных с изображением, указанным в запросе, обычно применяется некоторая мера расстояния или характеристики, с помощью которых можно получить численную оценку сходства изображений. Характеристики сходства изображений можно разделить на четыре основные группы:
1. Цветовое сходство
2. Текстурное сходство
3. Сходство формы
4. Сходство объектов и отношений между объектами
Для простоты мы рассмотрим только методы цветового сходства. Характеристики цветового сходства часто выбираются очень простыми. Они позволяют сравнить цветовое содержание одного изображения с цветовым содержанием другого изображения или с параметрами, заданными в запросе. Например, в системе QBIC пользователь может указать процентное соотношение цветов в искомых изображениях. На рисунке показан набор изображений, полученных в результате выполнения запроса с указанием 40% красного, 30% жёлтого и 10% чёрного цвета. Хотя найденные изображения содержат очень похожие цвета, но смысловое содержание этих изображений существенно отличается.

Похожий способ поиска основан на сопоставлении цветовых гистограмм. Меры расстояния на основе цветовой гистограммы должны предусматривать оценку сходства двух различных цветов. Система QBIC определяет расстояние следующим образом:
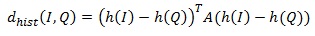
где h(I), h(Q) – гистограммы изображений I,Q, A – матрица сходства. В матрице сходства элементы, значения которых близки к 1, соответствуют похожим цветам, близкие 0 соответствуют сильно различающимся цветам. Ещё одна возможная мера расстоянии основана на цветовом макете. При формировании запроса пользователю обычно предъявляется пустая сетка. Для каждой клетки пользователь может указать цвет из таблицы.
Характеристики сходства на основе цветового макета, в которых используется закрашенная сетка, требуют меры, которая учитывала бы содержание двух закрашенных сеток. Эта мера должна обеспечивать сравнение каждой клетки сетки, указанной в запросе, соответствующей клеткой сетки произвольного изображения из базы данных. Результаты сравнения всех клеток комбинируются для получения значения расстояния между изображениями:
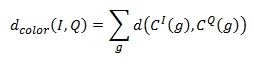
где C^I (g),C^Q (g) — это цвета клетки g в изображениях I,Q соответственно.
Поиск на основе текстурного сходства, а тем более на основе сходства формы гораздо сложнее, но, стоит сказать, что уже сделаны первые шаги в этом направлении. Например, в системе ART MUSEUM хранятся цветные изображения многих картин. Эти цветные изображения подвергаются обработке для получения промежуточного представления. Предварительная обработка состоит из трёх этапов:
1. Уменьшение изображения до заданного размера и удаление шумов с помощью медианного фильтра.
2. Обнаружение границ. Во-первых, с помощью глобального порога, затем с помощью локального порога. В результате получается очищенное контурное изображение.
3. На очищенном контурном изображении удаляются избыточные контуры. Полученное изображение ещё раз очищается от шумов, и мы получаем требуемое абстрактное представление.
Когда пользователь представляет системе эскиз, над ним производятся такие же операции обработки, и мы получаем линейный эскиз. Алгоритм сопоставления имеет корелляционный характер: изображение делится на клетки, и для каждой клетки вычисляется корреляция с аналогичной клеткой изображения из базы данных. Для надёжности эта процедура выполняется несколько раз для разных значений сдвига линейного эскиза. В большинстве случаев этот метод позволяет успешно находить требуемые изображения.
Осталось только дождаться внедрения таких систем в привычные нам интернет-поисковики, и можно будет сказать, что проблема поиска картинок стала не такой уж и проблемой.

