Добрый день!
В данной статье я хочу рассказать о проблеме классификации данных методом опорных векторов (Support Vector Machine, SVM). Такая классификация имеет довольно широкое применение: от распознавания образов или создания спам-фильтров до вычисления распределения горячих аллюминиевых частиц в ракетных выхлопах.
Сначала несколько слов об исходной задаче. Задача классификации состоит в определении к какому классу из, как минимум, двух изначально известных относится данный объект. Обычно таким объектом является вектор в n-мерном вещественном пространстве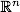 . Координаты вектора описывают отдельные аттрибуты объекта. Например, цвет c, заданный в модели RGB, является вектором в трехмерном пространстве: c=(red, green, blue).
. Координаты вектора описывают отдельные аттрибуты объекта. Например, цвет c, заданный в модели RGB, является вектором в трехмерном пространстве: c=(red, green, blue).
Если классов всего два («спам / не спам», «давать кредит / не давать кредит», «красное / черное»), то задача называется бинарной классификацией. Если классов несколько — многоклассовая (мультиклассовая) классификация. Также могут иметься образцы каждого класса — объекты, про которые заранее известно к какому классу они принадлежат. Такие задачи называют обучением с учителем, а известные данные называются обучающей выборкой. (Примечание: если классы изначально не заданы, то перед нами задача кластеризации.)
Метод опорных векторов, рассматриваемый в данной статье, относится к обучению с учителем.
Итак, математическая формулировка задачи классификации такова: пусть X — пространство объектов (например,), Y — наши классы (например, Y = {-1,1}). Дана обучающая выборка: 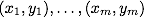 . Требуется построить функцию
. Требуется построить функцию 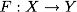 (классификатор), сопоставляющий класс y произвольному объекту x.
(классификатор), сопоставляющий класс y произвольному объекту x.
Данный метод изначально относится к бинарным классификаторам, хотя существуют способы заставить его работать и для задач мультиклассификации.
Идею метода удобно проиллюстрировать на следующем простом примере: даны точки на плоскости, разбитые на два класса (рис. 1). Проведем линию, разделяющую эти два класса (красная линия на рис. 1). Далее, все новые точки (не из обучающей выборки) автоматически классифицируются следующим образом:
точка выше прямой попадает в класс A,
точка ниже прямой — в класс B.
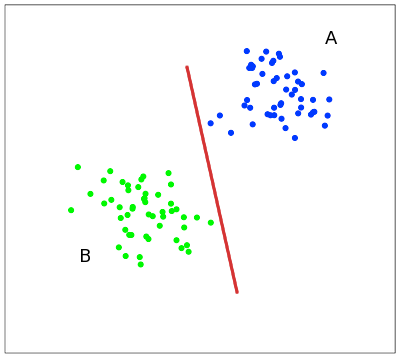
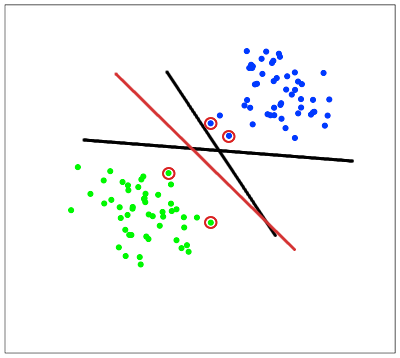
Такую прямую назовем разделяющей прямой. Однако, в пространствах высоких размерностей прямая уже не будет разделять наши классы, так как понятие «ниже прямой» или «выше прямой» теряет всякий смысл. Поэтому вместо прямых необходимо рассматривать гиперплоскости — пространства, размерность которых на единицу меньше, чем размерность исходного пространства. В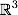 , например, гиперплоскость — это обычная двумерная плоскость.
, например, гиперплоскость — это обычная двумерная плоскость.
В нашем примере существует несколько прямых, разделяющих два класса (рис. 2):
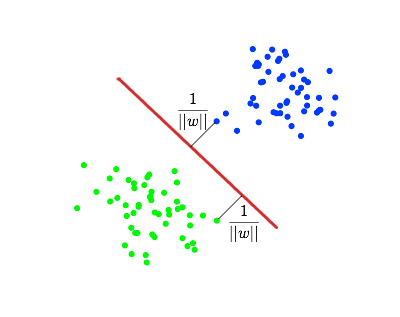
С точки зрения точности классификации лучше всего выбрать прямую, расстояние от которой до каждого класса максимально. Другими словами, выберем ту прямую, которая разделяет классы наилучшим образом (красная прямая на рис.2). Такая прямая, а в общем случае — гиперплоскость, называется оптимальной разделяющей гиперплоскостью.
Вектора, лежащие ближе всех к разделяющей гиперплоскости, называются опорными векторами (support vectors). На рисунке 2 они помечены красным.
Пусть имеется обучающая выборка: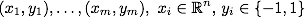 .
.
Метод опорных векторов строит классифицирующую функцию F в виде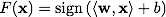 ,
,
где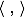 — скалярное произведение, w — нормальный вектор к разделяющей гиперплоскости,b — вспомогательный параметр. Те объекты, для которых F(x) = 1 попадают в один класс, а объекты с F(x) = -1 — в другой. Выбор именно такой функции неслучаен: любая гиперплоскость может быть задана в виде
— скалярное произведение, w — нормальный вектор к разделяющей гиперплоскости,b — вспомогательный параметр. Те объекты, для которых F(x) = 1 попадают в один класс, а объекты с F(x) = -1 — в другой. Выбор именно такой функции неслучаен: любая гиперплоскость может быть задана в виде 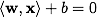 для некоторых w и b.
для некоторых w и b.
Далее, мы хотим выбрать такие w и b которые максимизируют расстояние до каждого класса. Можно подсчитать, что данное расстояние равно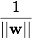 . Проблема нахождения максимума эквивалентна проблеме нахождения минимума
. Проблема нахождения максимума эквивалентна проблеме нахождения минимума  . Запишем все это в виде задачи оптимизации:
. Запишем все это в виде задачи оптимизации:
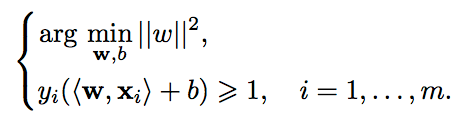
которая является стандартной задачей квадратичного программирования и решается с помощью множителей Лагранжа. Описание данного метода можно найти в Википедии.
На практике случаи, когда данные можно разделить гиперплоскостью, или, как еще говорят, линейно, довольно редки. Пример линейной неразделимости можно видеть на рисунке 3:
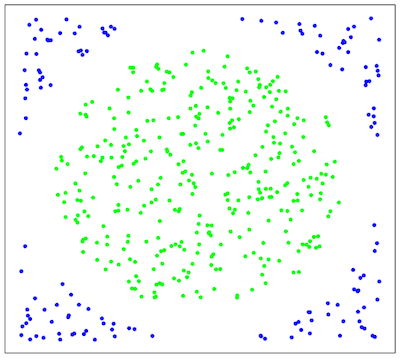
В этом случае поступают так: все элементы обучающей выборки вкладываются в пространство X более высокой размерности с помощью специального отображения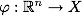 . При этом отображение
. При этом отображение 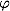 выбирается так, чтобы в новом пространстве X выборка была линейно разделима.
выбирается так, чтобы в новом пространстве X выборка была линейно разделима.
Классифицирующая функция F принимает вид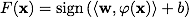 . Выражение
. Выражение 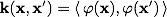 называется ядром классификатора. С математической точки зрения ядром может служить любая положительно определенная симметричная функция двух переменных. Положительная определенность необходимо для того, чтобы соответствующая функция Лагранжа в задаче оптимизации была ограничена снизу, т.е. задача оптимизации была бы корректно определена.
называется ядром классификатора. С математической точки зрения ядром может служить любая положительно определенная симметричная функция двух переменных. Положительная определенность необходимо для того, чтобы соответствующая функция Лагранжа в задаче оптимизации была ограничена снизу, т.е. задача оптимизации была бы корректно определена.
Точность классификатора зависит, в частности, от выбора ядра. На видео можно увидеть иллюстрирацию классификации при помощи полиномиального ядра:
Чаще всего на практике встречаются следующие ядра:
Полиномиальное: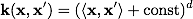
Радиальная базисная функция: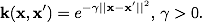
Гауссова радиальная базисная функция: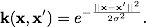
Сигмоид:
Среди других классификаторов хочу отметить также метод релевантных векторов (Relevance Vector Machine, RVM). В отличие от SVM данный метод дает вероятности, с которыми объект принадлежит данному классу. Т.е. если SVM говорит "x принадлежит классу А", то RVM скажет "x принадлежит классу А с вероятностью p и классу B с вероятностью 1-p".
1. Christopher M. Bishop. Pattern recognition and machine learning, 2006.
2. К. В. Воронцов. Лекции по методу опорных векторов.
В данной статье я хочу рассказать о проблеме классификации данных методом опорных векторов (Support Vector Machine, SVM). Такая классификация имеет довольно широкое применение: от распознавания образов или создания спам-фильтров до вычисления распределения горячих аллюминиевых частиц в ракетных выхлопах.
Сначала несколько слов об исходной задаче. Задача классификации состоит в определении к какому классу из, как минимум, двух изначально известных относится данный объект. Обычно таким объектом является вектор в n-мерном вещественном пространстве
. Координаты вектора описывают отдельные аттрибуты объекта. Например, цвет c, заданный в модели RGB, является вектором в трехмерном пространстве: c=(red, green, blue). Если классов всего два («спам / не спам», «давать кредит / не давать кредит», «красное / черное»), то задача называется бинарной классификацией. Если классов несколько — многоклассовая (мультиклассовая) классификация. Также могут иметься образцы каждого класса — объекты, про которые заранее известно к какому классу они принадлежат. Такие задачи называют обучением с учителем, а известные данные называются обучающей выборкой. (Примечание: если классы изначально не заданы, то перед нами задача кластеризации.)
Метод опорных векторов, рассматриваемый в данной статье, относится к обучению с учителем.
Итак, математическая формулировка задачи классификации такова: пусть X — пространство объектов (например,
), Y — наши классы (например, Y = {-1,1}). Дана обучающая выборка: . Требуется построить функцию (классификатор), сопоставляющий класс y произвольному объекту x.Метод опорных векторов
Данный метод изначально относится к бинарным классификаторам, хотя существуют способы заставить его работать и для задач мультиклассификации.
Идея метода
Идею метода удобно проиллюстрировать на следующем простом примере: даны точки на плоскости, разбитые на два класса (рис. 1). Проведем линию, разделяющую эти два класса (красная линия на рис. 1). Далее, все новые точки (не из обучающей выборки) автоматически классифицируются следующим образом:
точка выше прямой попадает в класс A,
точка ниже прямой — в класс B.
Такую прямую назовем разделяющей прямой. Однако, в пространствах высоких размерностей прямая уже не будет разделять наши классы, так как понятие «ниже прямой» или «выше прямой» теряет всякий смысл. Поэтому вместо прямых необходимо рассматривать гиперплоскости — пространства, размерность которых на единицу меньше, чем размерность исходного пространства. В
, например, гиперплоскость — это обычная двумерная плоскость.В нашем примере существует несколько прямых, разделяющих два класса (рис. 2):
С точки зрения точности классификации лучше всего выбрать прямую, расстояние от которой до каждого класса максимально. Другими словами, выберем ту прямую, которая разделяет классы наилучшим образом (красная прямая на рис.2). Такая прямая, а в общем случае — гиперплоскость, называется оптимальной разделяющей гиперплоскостью.
Вектора, лежащие ближе всех к разделяющей гиперплоскости, называются опорными векторами (support vectors). На рисунке 2 они помечены красным.
Немного математики
Пусть имеется обучающая выборка:
.Метод опорных векторов строит классифицирующую функцию F в виде
,где
— скалярное произведение, w — нормальный вектор к разделяющей гиперплоскости,b — вспомогательный параметр. Те объекты, для которых F(x) = 1 попадают в один класс, а объекты с F(x) = -1 — в другой. Выбор именно такой функции неслучаен: любая гиперплоскость может быть задана в виде для некоторых w и b.Далее, мы хотим выбрать такие w и b которые максимизируют расстояние до каждого класса. Можно подсчитать, что данное расстояние равно
. Проблема нахождения максимума эквивалентна проблеме нахождения минимума . Запишем все это в виде задачи оптимизации:которая является стандартной задачей квадратичного программирования и решается с помощью множителей Лагранжа. Описание данного метода можно найти в Википедии.
Линейная неразделимость
На практике случаи, когда данные можно разделить гиперплоскостью, или, как еще говорят, линейно, довольно редки. Пример линейной неразделимости можно видеть на рисунке 3:
В этом случае поступают так: все элементы обучающей выборки вкладываются в пространство X более высокой размерности с помощью специального отображения
. При этом отображение выбирается так, чтобы в новом пространстве X выборка была линейно разделима.Классифицирующая функция F принимает вид
. Выражение называется ядром классификатора. С математической точки зрения ядром может служить любая положительно определенная симметричная функция двух переменных. Положительная определенность необходимо для того, чтобы соответствующая функция Лагранжа в задаче оптимизации была ограничена снизу, т.е. задача оптимизации была бы корректно определена.Точность классификатора зависит, в частности, от выбора ядра. На видео можно увидеть иллюстрирацию классификации при помощи полиномиального ядра:
Чаще всего на практике встречаются следующие ядра:
Полиномиальное:
Радиальная базисная функция:
Гауссова радиальная базисная функция:
Сигмоид:
Заключение и литература
Среди других классификаторов хочу отметить также метод релевантных векторов (Relevance Vector Machine, RVM). В отличие от SVM данный метод дает вероятности, с которыми объект принадлежит данному классу. Т.е. если SVM говорит "x принадлежит классу А", то RVM скажет "x принадлежит классу А с вероятностью p и классу B с вероятностью 1-p".
1. Christopher M. Bishop. Pattern recognition and machine learning, 2006.
2. К. В. Воронцов. Лекции по методу опорных векторов.

