
Редакционное расстояние, или расстояние Левенштейна — метрика, позволяющая определить «схожесть» двух строк — минимальное количество операций вставки одного символа, удаления одного символа и замены одного символа на другой, необходимых для превращения одной строки в другую. В статье излагается метод вычисления редакционного расстояния при использовании небольшого объема памяти, без существенной потери скорости. Данный подход может быть применен для больших строк (порядка 105 символов, т.е. фактически для текстов) при получении не только оценки «схожести», но и последовательности изменений для перевода одной строки в другую.
Небольшая формализация
Пусть имеется две строки S1 и S2. Мы хотим перевести одну в другую (пусть первую во вторую, легко показать, что операции симметричны), используя следующие операции:
- I: Вставка символа в произвольное место;
- D: Удаление символа с произвольной позиции;
- R: Замена символа на другой.
Тогда d(S1,S2) — минимальное количество операций I/D/R для перевода S1 в S2, а редакционное предписание — перечисление операций для перевода с их параметрами.
Задача легко решается алгоритмом Вагнера — Фишера, однако для восстановления редакционного предписания потребуется O(|S1|*|S2|) ячеек памяти. Вкратце излагаю сам алгоритм, так как «оптимизация» основывается на нем.
Алгоритм Вагнера — Фишера
Искомое расстояние формируется через вспомогательную функцию D(M,N), находящую редакционное расстояние для подстрок S1[0..M] и S2[0..N]. Тогда полное редакционное расстояние будет равно расстоянию для подстрок полной длины: d(S1,S2) = DS1,S2(M,N).
Самоочевидным фактом, является то, что:
D(0,0) = 0.
Действительно, пустые строки и так совпадают.
Также, ясны значения для:
D(i, 0) = i;
D(0, j) = j.
Действительно, любая строка может получиться из пустой, добавлением нужного количества нужных символов, любые другие операции будут только увеличивать оценку.
В общем случае чуть сложнее:
D(i,j) = D(i-1,j-1), если S1[i] = S2[j],
иначе D(i,j) = min( D(i-1,j), D(i,j-1), D(i-1,j-1) ) + 1.
В данном случае, мы выбираем, что выгоднее: удалить символ (D(i-1,j)), добавить (D(i,j-1)), или заменить (D(i-1,j-1)).
Нетрудно понять, что алгоритму получения оценки не требуется памяти больше чем два столбца, текущий (D(i,*)) и предыдущий (D(i-1,*)). Однако в полном объеме матрица нужна для восстановления редакционного предписания. Начиная из правого нижнего угла матрицы (M,N) мы идем в левый верхний, на каждом шаге ища минимальное из трёх значений:
- если минимально (D(i-1, j) + 1), добавляем удаление символа S1[i] и идём в (i-1, j);
- если минимально (D(i, j-1) + 1), добавляем вставку символа S1[i] и идём в (i, j-1);
- если минимально (D(i-1, j-1) + m), где m = 1, если S1[i] != S2[j], иначе m = 0; после чего идём в (i-1, j-1) и добавляем замену если m = 1.
В итоге потребуется O(|S1|*|S2|) времени и O(|S1|*|S2|) памяти.
Общие доводы
Предпосылкой создания данного метода является простой факт: в условиях реальных систем память дороже времени. Действительно, для строк длиной в 216 символов нужно порядка 232 вычислительных операций (что при современных мощностях ляжет в пределах десяти секунд вычислений) и 232 же памяти, что в большинстве случаев уже больше размера физической памяти машины.
Идея, как использовать линейный объем памяти (2*|S1|) для оценки расстояния лежит на поверхности, осталось грамотно перенести ее на вычисление редакционного предписания.
Метод встречного расчета (алгоритм Хиршберга)
Будем применять рекурсию для разбиения задачи на подзадачи, каждая из которых не потребует много памяти. Для дальнейших зарисовок возьмем какие-нибудь начальные значения строк.
S1 = ACGTACGTACGT,
S2 = AGTACCTACCGT.
Похожи, не правда ли? Но и переписать одну в другую «на глаз» не так очевидно. Буквы, кстати, выбраны не случайно — это азотистые основания (A,T,G,C), компоненты ДНК: метод оценки редакционного расстояния активно применяется в биологии для оценки мутаций.
Тогда исходная не заполненная матрица будет выглядеть (именно выглядеть, хранить мы будем только необходимые данные) следующим образом:

В каждой клетке должно стоять значение редакционного расстояния.
Поделим исходную задачу на подзадачу, поделив вторую строку на две равные (или почти равные) части, запомним место разбиения, и начнем заполнять матрицу ровно так же, как делали в Вагнера — Фишера:

При заполнении мы не будем хранить предыдущие столбцы, двигаясь слева направо, сверху вниз, по мере вычисления значений D(i,j) значения D(i-1,j) можно удалять:

Аналогично, заполним правую часть разбиения. Здесь будем двигаться справа налево, сверху вниз:
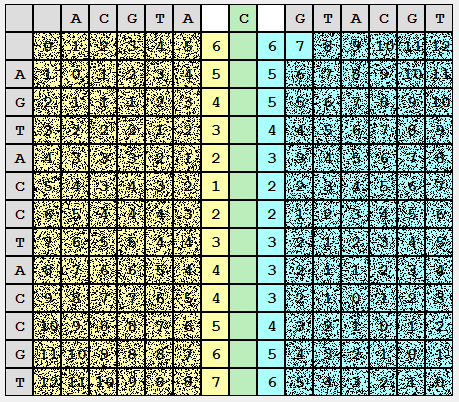
Вот мы и встретились. Теперь можно получить часть решения общей задачи, совместив частные. Просуммируем получившиеся в левых и правых столбцах значения и выберем минимум.
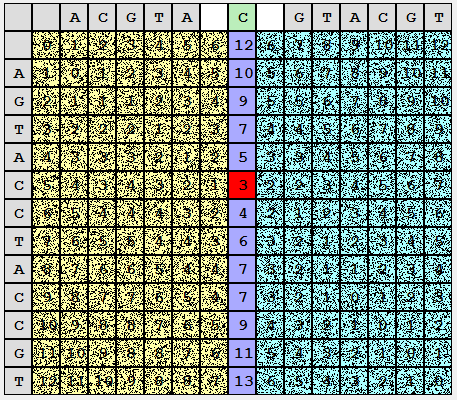
Что означает это совмещение? Мы попытались совместить первую строку с первой половиной второй строки, затем первую строку с второй половиной строки. Сумма позволяет получить количество операций изменения первой строки, чтобы привести ее к конкатенации первой и второй половины второй строки (то есть к второй строке)… это значит что мы получили значение редакционного расстояния! Но, рано радоваться, ибо этого результата можно было достичь и проще (вышеописанный метод).
Однако, посмотрев на картинку под другим углом (буквально), мы получили еще один существенный факт: теперь мы знаем как «разрезать» первую строку на две половины, чтобы соответствующие пары дали нам редакционное расстояние: d(S11,S21) + d(S12,S22) = d(S1,S2). Строка (в матрице), в которой расположен минимум и есть искомое разбиение S1, и это разбиение отправляется в выдачу редакционного предписания.
Аналогично будем делить задачу уже для получившихся подстрок S11 и S21 (и вторую пару тоже не забудем):

Завершим подразделение когда не останется ни одной подстроки S1 длины больше 1.

Получим список разбиений, где каждая подстрока S1 (смотреть по вертикали) дает минимальную оценку изменений относительно соответствующей подстроки S2 (по горизонтали).

Для удобства я раскрасил отметки цветами: зеленый означает посимвольное совпадение строк в выбранных позициях, синим необходимость замены, а красным — удаления или добавления. Нетрудно заметить, что «красные» кружки находятся в той же строке/столбце (задачка внимательным: объяснить из чего это следует).
В более удобной форме результат может быть записан так (красные штрихи — соответствие символов, сдвиги обозначены черными горизонтальными):

Анализ алгоритма
Память: для каждого шага потребуется запоминать не более чем один столбец d(i,*) и набор разбиений S1. Итого O(|S1| + |S2|). То есть вместо квадратичного объема мы получаем линейный.
Время: каждое разбиение S[0..N] по столбцу t порождает обработку подстрок S[0..t] и S[t..N]. Всего разбиений N. При обработке каждого разбиения (S1[i..j], S1[k..n]) требуется (j — i) x (n — k) операций. Суммируя оценку худших случаев для подстрок получаем в итоге 2 * |S1| * |S2| операций. Время работы алгоритма осталось квадратичным, хоть и изменилась мультипликативная константа.
Итак, мы решили задачу, используя линейное количество памяти и незначительно потеряли в скорости, что в данном случае можно считать успехом.
[*] Википедия: алгоритм Хиршберга.

